Python版GPA计算器
最近在网申投简历时遇到一个需要计算GPA的问题,想起自己在上学时写的Excel公式版GPA计算器略显low,而且操作也比较复杂,于是一时兴起,写了个Python版的,在此分享给大家!
准备工作:
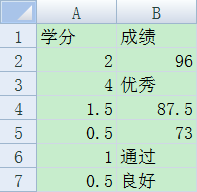
用户事先准备好如下图所示的Excel表格,其中A列为每门课程的学分,B列为每门课程的成绩。成绩可以有三种合法的表示方式:
- 百分制:支持0-100的整数或浮点数
- 五分制:默认支持'优', '良', '中', '差', '优秀', '良好', '中等', '及格', '不及格'的表示方式,可自行定义five_list变量
- 二分制:默认支持'通过', '不通过'的表示方式,可自行定义two_list变量
"""
GPA计算器
"""
import numpy as np
import pandas as pd
# 用户定义参数
path = r'成绩单.xls' # 用户Excel文件路径
# 系统预置参数
method_list = ['STA4.0','MOD4.0_v1','MOD4.0_v2','PKU4.0'] # GPA计算方法代号列表
method_name_list = ['标准4.0方法','改进4.0方法v1','改进4.0方法v2','北大4.0方法'] # GPA计算方法名称列表
five_list = ['优', '良', '中', '差', '优秀', '良好', '中等', '及格', '不及格'] # 合法的五分制成绩
two_list = ['通过', '不通过'] # 合法的二分制成绩
# 百分制转换为4.0分制
def convert_100_4(n, method):
"""
百分制转换为4.0分制
:param n: int或float类型的百分制分数
:param method: str格式,使用的方法,应为method_list中的一个元素
:return: float类型的4.0分制分数
"""
# 标准4.0方法
if method == 'STA4.0':
if 90 <= n <= 100:
return 4.0
elif 80 <= n < 90:
return 3.0
elif 70 <= n < 80:
return 2.0
elif 60 <= n < 70:
return 1.0
elif 0 <= n < 60:
return 0.0
# 改进4.0方法v1
elif method == 'MOD4.0_v1':
if 85 <= n <= 100:
return 4.0
elif 70 <= n < 85:
return 3.0
elif 60 <= n < 70:
return 2.0
elif 0 <= n < 60:
return 0.0
# 改进4.0方法v2
elif method == 'MOD4.0_v2':
if 85 <= n <= 100:
return 4.0
elif 75 <= n < 85:
return 3.0
elif 60 <= n < 75:
return 2.0
elif 0 <= n < 60:
return 0.0
# 北大4.0方法
elif method == 'PKU4.0':
if 90 <= n <= 100:
return 4.0
elif 85 <= n < 90:
return 3.7
elif 82 <= n < 85:
return 3.3
elif 78 <= n < 82:
return 3.0
elif 75 <= n < 78:
return 2.7
elif 72 <= n < 75:
return 2.3
elif 68 <= n < 72:
return 2.0
elif 64 <= n < 68:
return 1.5
elif 60 <= n < 64:
return 1.0
elif 0 <= n < 60:
return 0
# 五分制转换为4.0分制
def convert_5_4(n):
"""
五分制转换为4.0分制
:param n: str类型的五分制分数
:return: float类型的4.0分制分数
"""
if n == '优秀' or n == '优':
return 4.0
elif n == '良好' or n == '良':
return 3.0
elif n == '中等' or n == '中':
return 2.0
elif n == '及格':
return 1.0
elif n == '不及格' or n == '差':
return 0.0
# 二分制转换为4.0分制
def convert_2_4(n):
"""
二分制转换为4.0分制
:param n: str类型的二分制分数
:return: float类型的4.0分制分数
"""
if n == '通过':
return 1.0
elif n == '不通过':
return 0.0
# 主程序
def run():
# 定义初始值
sum = 0 # 用来累加每行的学分
sumpro = [0 for i in range(len(method_list))] # 用来累加method_list中每种方法下的学分*4.0分制成绩
# 使用pandas读取为DataFrame(数字将自动转换格式)
data = pd.read_excel(path, index_col=None, header=0)
# 逐行校验合法性并累加计算
for i in range(len(data)):
credit = data.iloc[i, 0] # 学分
score = data.iloc[i, 1] # 成绩
# 校验学分合法性
if isinstance(credit, str):
print('Excel表中的A' + str(i + 2) + '单元格数值不合法!学分应为非负整数或浮点数!程序异常终止!')
break
elif credit<0:
print('Excel表中的A' + str(i + 2) + '单元格数值不合法!学分应为非负整数或浮点数!程序异常终止!')
break
# 校验成绩合法性并计算GPA
if isinstance(score, str):
if score in five_list:
sum += credit
sumpro = [sumpro[i] + credit * convert_5_4(score) for i in range(len(method_list))]
elif score in two_list:
sum += credit
sumpro = [sumpro[i] + credit * convert_2_4(score) for i in range(len(method_list))]
else:
print('Excel表中的B' + str(i + 2) + '单元格数值不合法!未定义的文字型成绩!程序异常终止!')
break
elif score < 0 or score > 100:
print('Excel表中的B' + str(i + 2) + '单元格数值不合法!百分制分数应在0-100之间!程序异常终止!')
break
else:
sum += credit
sumpro = [sumpro[i] + credit * convert_100_4(score, method_list[i]) for i in range(len(method_list))]
else:
print('计算完毕!使用每种方法计算的GPA分别为:')
for i in range(len(method_list)):
print(method_name_list[i]+'\t '+str(sumpro[i]/sum))
if __name__ == '__main__':
run()
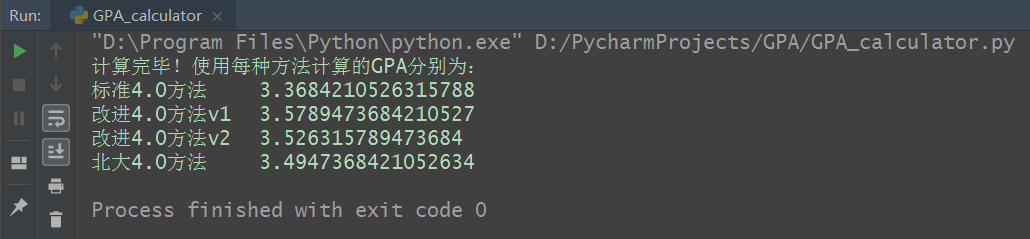
计算完毕后,结果将以屏幕输出的形式展现:
Python版GPA计算器的更多相关文章
- 【Python】《大话设计模式》Python版代码实现
<大话设计模式>Python版代码实现 上一周把<大话设计模式>看完了,对面向对象技术有了新的理解,对于一个在C下写代码比较多.偶尔会用到一些脚本语言写脚本的人来说,很是开阔眼 ...
- 《大话设计模式》Python版代码实现
上一周把<大话设计模式>看完了,对面向对象技术有了新的理解,对于一个在C下写代码比较多.偶尔会用到一些脚本语言写脚本的人来说,很是开阔眼界.<大话设计模式>的代码使用C#写成的 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- 数据结构:顺序表(python版)
顺序表python版的实现(部分功能未实现) #!/usr/bin/env python # -*- coding:utf-8 -*- class SeqList(object): def __ini ...
- python版恶俗古风自动生成器.py
python版恶俗古风自动生成器.py """ python版恶俗古风自动生成器.py 模仿自: http://www.jianshu.com/p/f893291674c ...
- LAMP一键安装包(Python版)
去年有出一个python整的LAMP自动安装,不过比较傻,直接调用的yum 去安装了XXX...不过这次一样有用shell..我也想如何不调用shell 来弄一个LAMP自动安装部署啥啥的..不过尼玛 ...
- 编码的秘密(python版)
编码(python版) 最近在学习python的过程中,被不同的编码搞得有点晕,于是看了前人的留下的文档,加上自己的理解,准备写下来,分享给正在为编码苦苦了挣扎的你. 编码的概念 编码就是将信息从一种 ...
- Zabbix 微信报警Python版(带监控项波动图片)
#!/usr/bin/python # -*- coding: UTF- -*- #Function: 微信报警python版(带波动图) #Environment: python import ur ...
- 豆瓣top250(go版以及python版)
最近学习go,就找了一个例子练习[go语言爬虫]go语言爬取豆瓣电影top250,思路大概就是获取网页,然后根据页面元素,用正则表达式匹配电影名称.评分.评论人数.原文有个地方需要修改下patte ...
随机推荐
- 前端分页神器,jquery grid的使用(前后端联调),让分页变得更简单。
jquery grid 是一款非常好用的前端分页插件,下面来讲讲怎么使用. 首先需要引入jquery grid 的CSS和JS (我们使用的是bootstrap的样式) 下面我们通过一个例子来讲解,需 ...
- Linux之Socket编程
1.什么是Socket? socket起源于Unix,而Unix/Linux基本哲学之一就是“一切皆文件”,都可以用“打开open –> 读写write/read –> 关闭close”模 ...
- if a != None:
>>> x = 1 >>> not x False >>> x = [1] >>> not x False >>&g ...
- linux中卸载mysql以及安装yum
卸载mysql:https://blog.csdn.net/qq_41829904/article/details/92966943 链接2:https://www.cnblogs.com/nickn ...
- 关于mybatis中多参数传值
如果前台单独传递多个参数,并且未进行封装,在mybatis的sql映射文件中需要以下标的形式表示传递的参数,从0开始 即:where name=#{0} and password =#{1}:0表示第 ...
- 数据库程序接口——JDBC——API解读第三篇——处理结果集的核心对象
核心对象 处理结果集的核心对象有ResultSet和RowSet.其中ResultSet指定关系型数据库的结果集,RowSet更为抽象,凡是由行列组成的数据都可以. ResultSet ResultS ...
- Docker - Dockerfile - 常见命令简介
概述 感觉是个 比较重要的东西 有个疑问 我是先讲 docker build 还是 先讲 Dockerfile 穿插讲 docker build 最基本的东西 原理 -t -f docker file ...
- 【C语言】创建一个函数,利用该函数将两个字符串连接起来
代码: #include<stdio.h> ], ]) { int i, j; ; c[i] != '\0'; i++); ; d[j] != '\0'; j++) { c[i++] = ...
- mysql开启远程访问及相关权限控制
开启mysql远程访问: 授予用户user 密码 passwd 所有权限 所有主机IP可访问 授权语句:Grant <权限> on 表名[(列名)] to 用户 With grant op ...
- AppBoxFuture: Sql存储的ORM查询示例
上篇介绍集成第三方Sql数据库时未实现如导航属性.子查询等功能,经过大半个月的努力作者初步实现了这些功能,基本上能满足80%-90%查询需求,特别复杂的查询可以用原生sql来处理,下面分别示例介绍 ...