Python版GPA计算器
最近在网申投简历时遇到一个需要计算GPA的问题,想起自己在上学时写的Excel公式版GPA计算器略显low,而且操作也比较复杂,于是一时兴起,写了个Python版的,在此分享给大家!
准备工作:
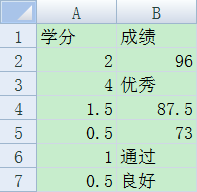
用户事先准备好如下图所示的Excel表格,其中A列为每门课程的学分,B列为每门课程的成绩。成绩可以有三种合法的表示方式:
- 百分制:支持0-100的整数或浮点数
- 五分制:默认支持'优', '良', '中', '差', '优秀', '良好', '中等', '及格', '不及格'的表示方式,可自行定义five_list变量
- 二分制:默认支持'通过', '不通过'的表示方式,可自行定义two_list变量
"""
GPA计算器
"""
import numpy as np
import pandas as pd
# 用户定义参数
path = r'成绩单.xls' # 用户Excel文件路径
# 系统预置参数
method_list = ['STA4.0','MOD4.0_v1','MOD4.0_v2','PKU4.0'] # GPA计算方法代号列表
method_name_list = ['标准4.0方法','改进4.0方法v1','改进4.0方法v2','北大4.0方法'] # GPA计算方法名称列表
five_list = ['优', '良', '中', '差', '优秀', '良好', '中等', '及格', '不及格'] # 合法的五分制成绩
two_list = ['通过', '不通过'] # 合法的二分制成绩
# 百分制转换为4.0分制
def convert_100_4(n, method):
"""
百分制转换为4.0分制
:param n: int或float类型的百分制分数
:param method: str格式,使用的方法,应为method_list中的一个元素
:return: float类型的4.0分制分数
"""
# 标准4.0方法
if method == 'STA4.0':
if 90 <= n <= 100:
return 4.0
elif 80 <= n < 90:
return 3.0
elif 70 <= n < 80:
return 2.0
elif 60 <= n < 70:
return 1.0
elif 0 <= n < 60:
return 0.0
# 改进4.0方法v1
elif method == 'MOD4.0_v1':
if 85 <= n <= 100:
return 4.0
elif 70 <= n < 85:
return 3.0
elif 60 <= n < 70:
return 2.0
elif 0 <= n < 60:
return 0.0
# 改进4.0方法v2
elif method == 'MOD4.0_v2':
if 85 <= n <= 100:
return 4.0
elif 75 <= n < 85:
return 3.0
elif 60 <= n < 75:
return 2.0
elif 0 <= n < 60:
return 0.0
# 北大4.0方法
elif method == 'PKU4.0':
if 90 <= n <= 100:
return 4.0
elif 85 <= n < 90:
return 3.7
elif 82 <= n < 85:
return 3.3
elif 78 <= n < 82:
return 3.0
elif 75 <= n < 78:
return 2.7
elif 72 <= n < 75:
return 2.3
elif 68 <= n < 72:
return 2.0
elif 64 <= n < 68:
return 1.5
elif 60 <= n < 64:
return 1.0
elif 0 <= n < 60:
return 0
# 五分制转换为4.0分制
def convert_5_4(n):
"""
五分制转换为4.0分制
:param n: str类型的五分制分数
:return: float类型的4.0分制分数
"""
if n == '优秀' or n == '优':
return 4.0
elif n == '良好' or n == '良':
return 3.0
elif n == '中等' or n == '中':
return 2.0
elif n == '及格':
return 1.0
elif n == '不及格' or n == '差':
return 0.0
# 二分制转换为4.0分制
def convert_2_4(n):
"""
二分制转换为4.0分制
:param n: str类型的二分制分数
:return: float类型的4.0分制分数
"""
if n == '通过':
return 1.0
elif n == '不通过':
return 0.0
# 主程序
def run():
# 定义初始值
sum = 0 # 用来累加每行的学分
sumpro = [0 for i in range(len(method_list))] # 用来累加method_list中每种方法下的学分*4.0分制成绩
# 使用pandas读取为DataFrame(数字将自动转换格式)
data = pd.read_excel(path, index_col=None, header=0)
# 逐行校验合法性并累加计算
for i in range(len(data)):
credit = data.iloc[i, 0] # 学分
score = data.iloc[i, 1] # 成绩
# 校验学分合法性
if isinstance(credit, str):
print('Excel表中的A' + str(i + 2) + '单元格数值不合法!学分应为非负整数或浮点数!程序异常终止!')
break
elif credit<0:
print('Excel表中的A' + str(i + 2) + '单元格数值不合法!学分应为非负整数或浮点数!程序异常终止!')
break
# 校验成绩合法性并计算GPA
if isinstance(score, str):
if score in five_list:
sum += credit
sumpro = [sumpro[i] + credit * convert_5_4(score) for i in range(len(method_list))]
elif score in two_list:
sum += credit
sumpro = [sumpro[i] + credit * convert_2_4(score) for i in range(len(method_list))]
else:
print('Excel表中的B' + str(i + 2) + '单元格数值不合法!未定义的文字型成绩!程序异常终止!')
break
elif score < 0 or score > 100:
print('Excel表中的B' + str(i + 2) + '单元格数值不合法!百分制分数应在0-100之间!程序异常终止!')
break
else:
sum += credit
sumpro = [sumpro[i] + credit * convert_100_4(score, method_list[i]) for i in range(len(method_list))]
else:
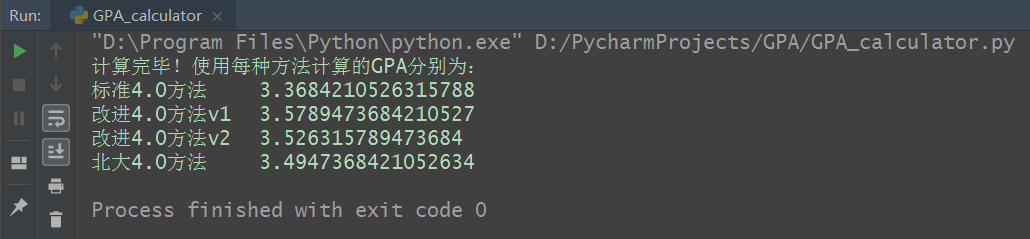
print('计算完毕!使用每种方法计算的GPA分别为:')
for i in range(len(method_list)):
print(method_name_list[i]+'\t '+str(sumpro[i]/sum))
if __name__ == '__main__':
run()
计算完毕后,结果将以屏幕输出的形式展现:
Python版GPA计算器的更多相关文章
- 【Python】《大话设计模式》Python版代码实现
<大话设计模式>Python版代码实现 上一周把<大话设计模式>看完了,对面向对象技术有了新的理解,对于一个在C下写代码比较多.偶尔会用到一些脚本语言写脚本的人来说,很是开阔眼 ...
- 《大话设计模式》Python版代码实现
上一周把<大话设计模式>看完了,对面向对象技术有了新的理解,对于一个在C下写代码比较多.偶尔会用到一些脚本语言写脚本的人来说,很是开阔眼界.<大话设计模式>的代码使用C#写成的 ...
- 【原】Learning Spark (Python版) 学习笔记(三)----工作原理、调优与Spark SQL
周末的任务是更新Learning Spark系列第三篇,以为自己写不完了,但为了改正拖延症,还是得完成给自己定的任务啊 = =.这三章主要讲Spark的运行过程(本地+集群),性能调优以及Spark ...
- 数据结构:顺序表(python版)
顺序表python版的实现(部分功能未实现) #!/usr/bin/env python # -*- coding:utf-8 -*- class SeqList(object): def __ini ...
- python版恶俗古风自动生成器.py
python版恶俗古风自动生成器.py """ python版恶俗古风自动生成器.py 模仿自: http://www.jianshu.com/p/f893291674c ...
- LAMP一键安装包(Python版)
去年有出一个python整的LAMP自动安装,不过比较傻,直接调用的yum 去安装了XXX...不过这次一样有用shell..我也想如何不调用shell 来弄一个LAMP自动安装部署啥啥的..不过尼玛 ...
- 编码的秘密(python版)
编码(python版) 最近在学习python的过程中,被不同的编码搞得有点晕,于是看了前人的留下的文档,加上自己的理解,准备写下来,分享给正在为编码苦苦了挣扎的你. 编码的概念 编码就是将信息从一种 ...
- Zabbix 微信报警Python版(带监控项波动图片)
#!/usr/bin/python # -*- coding: UTF- -*- #Function: 微信报警python版(带波动图) #Environment: python import ur ...
- 豆瓣top250(go版以及python版)
最近学习go,就找了一个例子练习[go语言爬虫]go语言爬取豆瓣电影top250,思路大概就是获取网页,然后根据页面元素,用正则表达式匹配电影名称.评分.评论人数.原文有个地方需要修改下patte ...
随机推荐
- 【New】WoSo_我搜 正式上线
[New]WoSo_我搜 正式上线 一站式搜索平台 聚合多种领域搜索引擎,大大提高搜索效率,使搜索更简单 地址:https://huangenet.github.io/WoSo/
- pycharm2019.3安装以及激活
最近很多的pycharm激活过期的,小伙伴们问我pycharm要怎么激活?这里就分享一下pycharm最新版本的安装以及激活吧!!! 首先先去官网(https://www.jetbrains.com/ ...
- 【转载】SpringMVC框架介绍
转自:http://com-xpp.iteye.com/blog/1604183 SpringMVC框架图 SpringMVC接口解释 DispatcherServlet接口: Spring提 ...
- Spring Security技术栈开发企业级认证与授权(一)环境搭建
本项目是基于慕课网的Spring Security技术栈开发企业级认证与授权,采用IDEA开发,本文章用来记录该项目的学习过程. 慕课网视频:https://coding.imooc.com/clas ...
- bugku 细心
打开链接会看到提醒404 显示不能访问 然后用御剑 扫描一下 然后会发现另一个 网址 然后打开 发现 有一个/result.php然后改一下 网址会发现 另一个网页 然后利用提示 将链接的后缀名改成? ...
- bugku 你必须让他停下
首先打开链接会发现一个不断刷新的网页 然后使用抓包工具burpsuit抓网页 然后右键点击跳转到repeater 然后点击go一直点击 注意黄色区域的变化然后在点击过程中会发现flag 然后拿到答案
- 自己centos7成功的修改了主机名(记录了该改哪些文件)
1.更改/etc/hosts 方法(1)可以直接的去更改这个文件,更改的格式:直接vi编辑器打开,之后直接写上自己想要的主机名字就好,不用写成键值对的形式 [root@localhost etc]# ...
- dbGet(二.一)hinst
hinst hierarchical insts Parent Object bndry,group,hInstTerm,hTerm, inst,ptn,topCell,vCell Child Obj ...
- Shiro&Jwt验证
此篇基于 SpringBoot 整合 Shiro & Jwt 进行鉴权 相关代码编写与解析 首先我们创建 JwtFilter 类 继承自 BasicHttpAuthenticationFilt ...
- web前端技能考核(阿里巴巴)