使用百度NLP接口对搜狐新闻做分类
一、简介
本文主要是要利用百度提供的NLP接口对搜狐的新闻做分类,百度对NLP接口有提供免费的额度可以拿来练习,主要是利用了NLP里面有个文章分类的功能,可以顺便测试看看百度NLP分类做的准不准。详细功能与使用方式可以上(http://ai.baidu.com/tech/nlp/topictagger)观看。
二、建立爬虫
首先要先写一个可以快速爬取所有文章内容的爬虫程序,关于爬虫的原理可以看我之前写的介绍(https://www.cnblogs.com/yenpaul/p/9968015.html),这边就直接附上代码
def all_url():
url = 'http://news.sohu.com/'
data = requests.get(url).text
s = etree.HTML(data)
print('\n')
urls0 = s.xpath('/html/body/div[*]/div[*]/div[1]/div/div[*]/div[*]/div[*]/ul/li[*]/a/@href')
urls1 = s.xpath('/html/body/div[*]/div[*]/div[1]/div/div[*]/div[*]/div/div[*]/div[*]/ul/li[*]/a/@href')
urls2 = s.xpath('/html/body/div[*]/div[*]/div[1]/div[*]/div[*]/ul/li[*]/a/@href')
urls3 = s.xpath('/html/body/div[*]/div[*]/div[1]/div/div[*]/div[*]/ul/li[*]/a/@href')
urls_all = urls0+urls1+urls2+urls3
f = open('urllist.txt','a')
for url in urls_all:
f.write(url)
f.write("\n")
f.close()
先把搜狐首页的新闻链接全部抓下来放在“urllist.txt”的文件里面
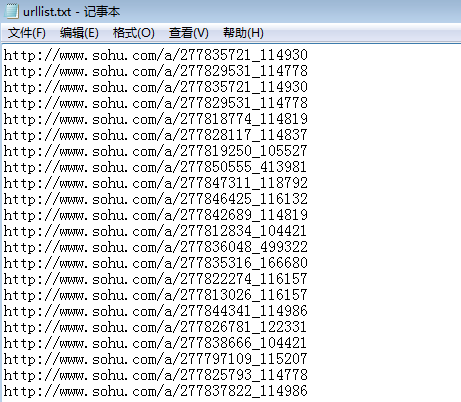
可以看到这边都是新闻的链接,也就是我接下来要去爬取得网页
三、申请接口权限
由于是要利用百度的接口,必须要先在百度注册账号然后登陆,然后需要先创建一个项目,创建完会得到一组APP_ID,APP_KEY,APP_SECRECT,是用在接下来的接口鉴权上的,创建完再查看百度AI的API文档,python的可以看这边(http://ai.baidu.com/docs#/NLP-Python-SDK/top)
然后下拉到文章分类的接口

可以看到他需要两个参数,分别是文章的标题和文章的内容,再看返回参数的格式

我们只需要知道分类的这个tag放哪里就好
四、抓取资料,提供数据给接口
接着就是要去抓取资料,我们需要去抓“标题”和“内文”传给这个接口,并将返回的结果写入“xinwen.txt”这个记事本,下面是代码
def get_content():
f = open('urllist.txt')
u = 0
for url in f:
u = u+1
print(u)
head = {}
head['User-Agent'] = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
req = request.Request(url, headers=head)
response = request.urlopen(req)
data = response.read().decode('utf-8')
s = etree.HTML(data)
title = s.xpath('//*[@id="article-container"]/div[2]/div[1]/div[1]/h1/text()')
content = s.xpath('//*[@id="mp-editor"]/p/text()')
content_text = ''.join(content)
type = client.topic(title, content)
f = open('xinwen.txt','a')
f.write('##')
f.write(type['item']['lv1_tag_list'][0]['tag'])
f.write('##')
f.write(title[0])
f.write('\n')
f.close()
由于搜狐也是有反爬虫,需要伪装user-agent,下面就是输出到文件的结果
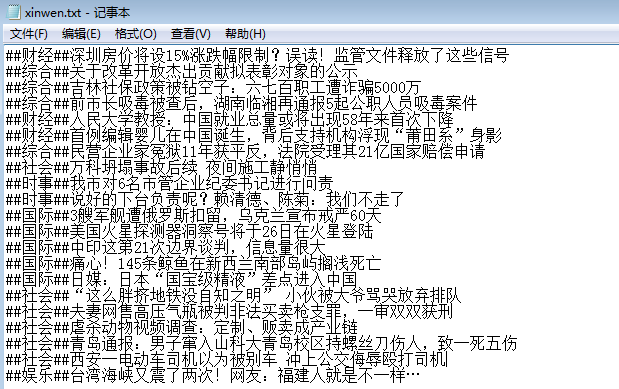
可以看到百度分类的还算可以,不过没有分的很细,像是时事跟综合这两个的范围也太广了,大部分的新闻分这两个几乎不会错,然后也是有几个新闻分类错,例如最后一个明显不是娱乐新闻。
使用百度NLP接口对搜狐新闻做分类的更多相关文章
- 基于jieba,TfidfVectorizer,LogisticRegression进行搜狐新闻文本分类
一.简介 此文是对利用jieba,word2vec,LR进行搜狐新闻文本分类的准确性的提升,数据集和分词过程一样,这里就不在叙述,读者可参考前面的处理过程 经过jieba分词,产生24000条分词结果 ...
- 利用jieba,word2vec,LR进行搜狐新闻文本分类
一.简介 1)jieba 中文叫做结巴,是一款中文分词工具,https://github.com/fxsjy/jieba 2)word2vec 单词向量化工具,https://radimrehurek ...
- sohu_news搜狐新闻类型分类
数据获取 数据是从搜狐新闻开放的新闻xml数据,经过一系列的处理之后,生成的一个excel文件 该xml文件的处理有单独的处理过程,就是用pandas处理,该过程在此省略 import numpy a ...
- 【NLP】3000篇搜狐新闻语料数据预处理器的python实现
3000篇搜狐新闻语料数据预处理器的python实现 白宁超 2017年5月5日17:20:04 摘要: 关于自然语言处理模型训练亦或是数据挖掘.文本处理等等,均离不开数据清洗,数据预处理的工作.这里 ...
- 搜狐新闻APP是如何使用HUAWEI DevEco IDE快速集成HUAWEI HiAI Engine
6月12日,搜狐新闻APP最新版本在华为应用市场正式上线啦! 那么,这一版本的搜狐新闻APP有什么亮点呢? 先抛个图,来直接感受下—— 模糊图片,瞬间清晰! 效果杠杠的吧. 而藏在这项神操作背后的 ...
- 世界更清晰,搜狐新闻客户端集成HUAWEI HiAI 亮相荣耀Play发布会!
6月6日,搭载有“很吓人”技术的荣耀Play正式发布,来自各个领域的大咖纷纷为新机搭载的惊艳技术站台打call,其中,搜狐公司董事局主席兼首席执行官张朝阳揭秘:华为和搜狐新闻客户端在硬件AI方面做 ...
- 搜狗输入法弹出搜狐新闻的解决办法(sohunews.exe)
狗输入法弹出搜狐新闻的解决办法(sohunews.exe) 1.找到搜狗输入法的安装目录(一般是C:\program files\sougou input\版本号\)2.右键点击sohunews.ex ...
- 利用搜狐新闻语料库训练100维的word2vec——使用python中的gensim模块
关于word2vec的原理知识参考文章https://www.cnblogs.com/Micang/p/10235783.html 语料数据来自搜狐新闻2012年6月—7月期间国内,国际,体育,社会, ...
- 利用朴素贝叶斯分类算法对搜狐新闻进行分类(python)
数据来源 https://www.sogou.com/labs/resource/cs.php介绍:来自搜狐新闻2012年6月—7月期间国内,国际,体育,社会,娱乐等18个频道的新闻数据,提供URL ...
随机推荐
- 给博客添加rss订阅
如果是自己搭建博客,有一个问题是如何写一篇新的文章就可以告诉读者,你写了一篇新的?一个简单方法是使用 rss ,RSS订阅是站点用来和其他站点之间共享内容的一种简易方式,即Really Simple ...
- @noi.ac - 506@ 强连通分量
目录 @description@ @solution@ @accepted code@ @details@ @description@ 有一天你学了一个叫能求出有向图中所有的强连通分量的算法,你决定将 ...
- 2018年NOIP普及组复赛题解
题目涉及算法: 标题统计:字符串入门题: 龙虎斗:数学题: 摆渡车:动态规划: 对称二叉树:搜索. 标题统计 题目链接:https://www.luogu.org/problem/P5015 这道题目 ...
- 一个div居于另一个div底部
一个div如何与另一个div底部对齐,方法有很多,比如使用绝对定位 <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional/ ...
- 使用openssl 工具进行双向认证测试
1,双向认证测试(需要根证书,客户证书,服务器证书以及各自的私钥)(验证通信双方的身份) openssl s_server -accept -key certs/server.key -cert ce ...
- Oracle - @和@@、&与&& 的区别
2018-01-15 15:36:17 袭冷 阅读数 4783更多 分类专栏: DB 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接 ...
- hdu 1358 Period (KMP求循环次数)
Problem - 1358 KMP求循环节次数.题意是,给出一个长度为n的字符串,要求求出循环节数大于1的所有前缀.可以直接用KMP的方法判断是否有完整的k个循环节,同时计算出当前前缀的循环节的个数 ...
- SELinux: Could not downgrade policy file
在配置nfs服务器,设定selinux时,碰到了SELinux: Could not downgrade policy file的错误提示,下文是其解决方案. 一.故障现象 [root@system1 ...
- H3C 高级ACL
- 整理了一下react16.7.0的webpack模板
基本上react需要方法和依赖的库都引配好了.github地址:https://github.com/qianxiaoning/demo-react16.7.0 欢迎大家star或者fork呀~ te ...