词袋和 TF-IDF 模型
做文本分类等问题的时,需要从大量语料中提取特征,并将这些文本特征变换为数值特征。常用的有词袋模型和TF-IDF 模型
1.词袋模型
词袋模型是最原始的一类特征集,忽略掉了文本的语法和语序,用一组无序的单词序列来表达一段文字或者一个文档。可以这样理解,把整个文档集的所有出现的词都丢进袋子里面,然后无序的排出来(去掉重复的)。对每一个文档,按照词语出现的次数来表示文档。
句子1:我/有/一个/苹果
句子2:我/明天/去/一个/地方
把所有词丢进一个袋子:我,有,一个,苹果,明天,去,地方。
现在我们建立一个无序列表:我,有,一个,苹果,明天,去,地方并根据每个句子中词语出现的次数来表示每个句子。

- 句子 1 特征: ( 1 , 1 , 1 , 1 , 0 , 0 , 0 )
- 句子 2 特征: ( 1 , 0 , 1 , 0 , 1 , 1 , 1 )
这样的一种特征表示,我们就称之为词袋模型的特征。
2.TF-IDF 模型
这种模型主要是用词汇的统计特征来作为特征集。TF-IDF 由两部分组成:TF(Term frequency,词频),IDF(Inverse document frequency,逆文档频率)两部分组成。IDF反映的是一个词能将当前文本与其它文本区分开的能力
TF:
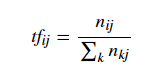
其中分子 nij表示词 ii在文档 j 中出现的频次。分母则是所有词频次的总和,也就是所有词的个数。
举个例子:
句子1:上帝/是/一个/女孩
句子2:桌子/上/有/一个/苹果
每个句子中词语的 TF :

IDF:
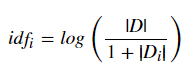
其中 |D|代表文档的总数,分母部分 |Di|则是代表文档集中含有 i 词的文档数。原始公式是分母没有 +1 的,这里 +1 是采用了拉普拉斯平滑,避免了有部分新的词没有在语料库中出现而导致分母为零的情况出现。
最后,把 TF 和 IDF 两个值相乘就可以得到 TF-IDF 的值。即:
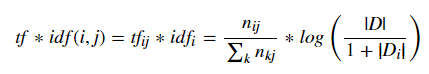
把每个句子中每个词的 TF-IDF 值 添加到向量表示出来就是每个句子的 TF-IDF 特征。
在 Python 当中,我们可以通过 scikit-learn 来分别实现词袋模型以及 TF-IDF 模型。并且,使用 scikit-learn 库将会非常简单。这里要用到 CountVectorizer() 类以及 TfidfVectorizer() 类。
看一下两个类的参数:
#词袋
sklearn.featur_extraction.text.CountVectorizer(min_df=1, ngram_range=(1,1))min_df:忽略掉词频严格低于定阈值的词ngram_range:将 text 分成 n1,n1+1,……,n2个不同的词组。比如比如'Python is useful'中ngram_range(1,3)之后可得到 'Python' , 'is' , 'useful' , 'Python is' , 'is useful' , 'Python is useful'。如果是ngram_range (1,1) 则只能得到单个单词'Python' , 'is' , 'useful'。
#Tf-idf
sklearn.feature_extraction.text.TfidfVectorizer(min_df=1,norm='l2',smooth_idf=True,use_idf=True,ngram_range=(1,1))min_df: 忽略掉词频严格低于定阈值的词。norm:标准化词条向量所用的规范。smooth_idf:添加一个平滑 idf 权重,即 idf 的分母是否使用平滑,防止0权重的出现。use_idf: 启用 idf 逆文档频率重新加权。ngram_range:同词袋模型
python代码实现:
词袋:
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(min_df=1, ngram_range=(1, 1))
#建立文本库
corpus = ['This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?']
#训练数据 corpus 获得词袋特征
a = vectorizer.fit_transform(corpus)
#查看词的排列形式
vectorizer.get_feature_names()
a.toarray()
tf-idf
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer(
min_df=1, norm='l2', smooth_idf=True, use_idf=True, ngram_range=(1, 1))
#用 TF-IDF 类去训练上面同一个 corpus
b = vectorizer.fit_transform(corpus)
需要注意的是 b 这个特征矩阵是以稀疏矩阵的形式存在的,使用 Compressed Row Storage 格式存储,也就是这个特征矩阵的信息是被压缩了。
为什么要这么做呢?因为在实际运用是文本数据量是非常大的,如果完整的存储会消耗大量的内存,因此会将其压缩存储。但是仍然可以像 numpy 数组一样取特征矩阵中的数据。
词袋和 TF-IDF 模型的更多相关文章
- 25.TF&IDF算法以及向量空间模型算法
主要知识点: boolean model IF/IDF vector space model 一.boolean model 在es做各种搜索进行打分排序时,会先用boolean mo ...
- 文本分类学习(三) 特征权重(TF/IDF)和特征提取
上一篇中,主要说的就是词袋模型.回顾一下,在进行文本分类之前,我们需要把待分类文本先用词袋模型进行文本表示.首先是将训练集中的所有单词经过去停用词之后组合成一个词袋,或者叫做字典,实际上一个维度很大的 ...
- NLP从词袋到Word2Vec的文本表示
在NLP(自然语言处理)领域,文本表示是第一步,也是很重要的一步,通俗来说就是把人类的语言符号转化为机器能够进行计算的数字,因为普通的文本语言机器是看不懂的,必须通过转化来表征对应文本.早期是基于规则 ...
- 使用Gensim库对文本进行词袋、TF-IDF和n-gram方法向量化处理
Gensim库简介 机器学习算法需要使用向量化后的数据进行预测,对于文本数据来说,因为算法执行的是关于矩形的数学运算,这意味着我们必须将字符串转换为向量.从数学的角度看,向量是具有大小和方向的几何对象 ...
- TF/IDF(term frequency/inverse document frequency)
TF/IDF(term frequency/inverse document frequency) 的概念被公认为信息检索中最重要的发明. 一. TF/IDF描述单个term与特定document的相 ...
- TF/IDF计算方法
FROM:http://blog.csdn.net/pennyliang/article/details/1231028 我们已经谈过了如何自动下载网页.如何建立索引.如何衡量网页的质量(Page R ...
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- 信息检索中的TF/IDF概念与算法的解释
https://blog.csdn.net/class_brick/article/details/79135909 概念 TF-IDF(term frequency–inverse document ...
随机推荐
- OpenCASCADE 7.4.0 Released
Open Cascade is pleased to announce a new public release of Open CASCADE Technology (version 7.4.0). ...
- vue 使用QRcode生成二维码或在线生成二维码
参考:https://blog.csdn.net/zhuswy/article/details/80267748 1.安装qrcode.js npm install qrcodejs2 --save ...
- codeforces600E. Lomsat gelral(dsu on tree)
dsu on tree先分轻重儿子先处理轻边,再处理重儿子再加上轻儿子的答案 #include<iostream> #include<cstdio> #include<q ...
- Android Studio && NDK开发
Android Studio下载安装网址:http://www.android-studio.org/index.php/download/hisversion 在下载界面可以查看安装包内是否包含SD ...
- Python3.5 安装 & hello world
1.下载安装python https://www.python.org/downloads/release/python-364/ 2.安装成功运行 python shell 3.或者cmd => ...
- PHP7中标量类型declare的用法详解
这篇文章主要介绍了PHP7标量类型declare用法,结合实例形式分析了PHP7中标量类型declare的功能.特性与相关使用技巧,需要的朋友可以参考下 本文实例讲述了PHP7标量类型declare用 ...
- V8:V8(Javascript引擎)
ylbtech-V8:V8(Javascript引擎) Lars Bak是这个项目的组长,目前该JavaScript引擎已用于其它项目的开发.第一个版本随着第一个版本的Chrome于2008年9月2日 ...
- JEECMS的几个细节
最近想自己写一些标签,看了一下JEECMS,感觉有些标签还是很值得学习的. 1.图片新闻:可以实现类似于flash切换图片的那种效果 效果: 代码: [@cms.ArtiList chnlId='' ...
- 【DM642】H.264源代码在DM642上的移植
TI公司提供了用于C语言开发的CCS(Code Composer Studio),该平台包括了优化的ANSI编译器,使之可以使用C语言开发DSP程序.这种方法不仅使DSP开发的速度大大加快,而且DSP ...
- 你真的会用Action的模型绑定吗?
在QQ群或者一些程序的交流平台,经常会有人问:我怎么传一个数组在Action中接收.我传的数组为什么Action的model中接收不到.或者我在ajax的data中设置了一些数组,为什么后台还是接收不 ...