Hadoop学习
Hadoop: 大数据里面的公认的解决方案标准
链接推荐:http://www.powerxing.com/install-hadoop/
第一天 Hadoop的基本概念 伪分布式集群安装 hdfs mapreduce 演示
第二天 hdfs原理和使用操作
第三天 mapreduce 的原理和编程
第四天 常见mr算法实现和shuffle的机制
第五天 Hadoop2.x种HA机制的原理和全分布式集群安装部署及维护
第六天 hbase hive
第七天 strom+kafka
第八天 实战项目
What is Apache Hadoop?
The Apache Hadoop project develops open-source software for reliable, scalable, distributed computing.
Hadoop 来源
解决问题:
1.海量数据的存储 HDFS
2.海量数据的分析MapReduce
3.资源管理调度 YARN
作者:Doug Cutting
受Google三篇论文的启发(GFS、MapReduce、BigTable)
处理海量数据
面临着公共问题:任务调度、节点存活精度、数据共享、中间节点传递。。。
需要框架的出现,减少开发的工作量
标准框架Hadoop
1.解决特定领域的公共问题:海量集数据的处理
2.Hadoop不是数据库、是有好多框架组成的生态系统。
3.导出文本文件,不是放到数据库中。几十个T放不到MySQL中
4.根本就不是数据库的搞法,但是Hadoop包含有数据库NoSQl
5.直接对文本文件进行处理(写逻辑使用Java或者C++编程),然后分发到集群上进行运行,这就是MapReduce
6.几十个T的文件存储方式:使用HDFS存储,分布式集群,不是存储在一台机器上面,存储在很多的机器上。
7.海量数据的存储以及海量数据的分析 组成狭义的Hadoop
Hadoop 0.20~2.5.x发展:
从1.x到2.x多了YARN这部分。
将jar包分发到各个机器上,然后分配一定的资源以及进程资源。这些工作和自己所写的代码的逻辑没有关系。因此这部分的逻辑处理封装为YARN (资源管理调度),MapReduce只管逻辑不管资源分配了。
实时的逻辑计算。。。
Lucene 建立索引

把运算分布到分布的机器上进行运行
作者 Doug Cutting
GFS 存储数据
MapReduce
BigTable 就是一个数据库

解决存储的问题!!!
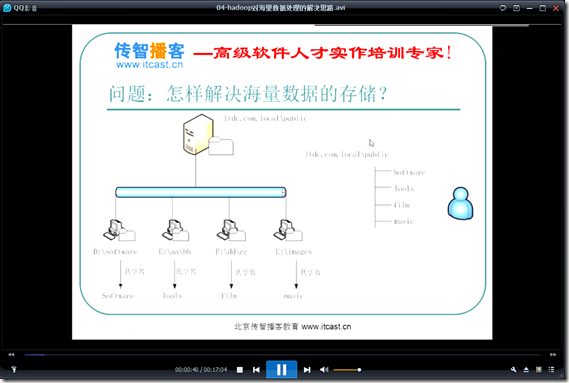
某些机器负载就会特别大,而其他的机器负载很小!!!
某些机器坏了,这样就会导致文件的丢失!!!
更加可靠更加复杂
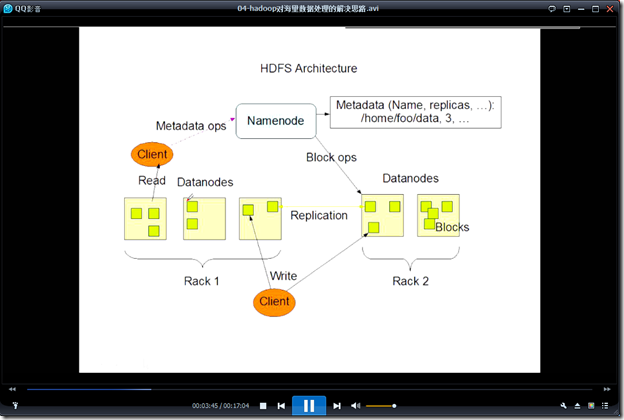
存储多个副本 即使宕机也没有关系,没有性能下降
文件所在的路径以及存储文件的路径应当有一个对应的关系,这个关系使用NameNode进行映射存储。

多个整数数字进行排序。!!!
能够并发运行的分开,分组并发
写两个程序:Map程序 在每个节点并发进行
Reduce程序 选择几个节点进行运行

安装-部署-开发-维护
2.4.1
2.5最新版本

最多解出的Cloudera CDH5 和Hadoop的版本号不是一致的
Aparche原生原汁原味
2.4.1
CenOS

搭建Hadoop
测试Hadoop
主机名zpfbuaa
端口219.142.245.200
修改hosts文件
# 219.142.245.200 zpfbuaa
219.142.245.200 zpfbuaa
向hadoop中put数据
1.hadoop fs -put 文件名 hdfs://zpfbuaa:9000/
在hadoop中创建文件夹
1.hadoop fs -mkdir /wordcount/
测试hadoop自带的jar包
1.在share文件夹下
进入hadoop
进入mapreduce
hadoop-mapreduce-examples-2.4.1.jar 包含示例程序
2.运行示例程序
a.hadoop jar hadoop-mapreduce-examples-2.4.1.jar pi 5 5
其中pi表示该程序用来计算pi的值 后面的5 5越大计算的pi的结果越精确
b.hadoop jar hadoop-mapreduce-examples-2.4.1.jar wordcount 文件所在目录 输出结果保存目录
可以先建立输出结果的保存目录,然后运行wordcount(计数程序)
配置文件
1.core-site-xml
修改
<property>
<name>fs.defaultFS</name>
<value>hdfs://zpfbuaa:9000/</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/app/hadoop-2.4.1/data/</value>
</property>
2.hdfs-site.xml
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
3.mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
4. yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>zpfbuaa</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
5.slaves
修改为zpfbuaa
测试网络是否连通
使用指令 ping zpfbuaa
查看网页 zpfbuaa:8088

查看网页 zpfbuaa:50070

关闭linux防火墙
指令 service iptables stop
Hadoop学习的更多相关文章
- Hadoop学习之旅二:HDFS
本文基于Hadoop1.X 概述 分布式文件系统主要用来解决如下几个问题: 读写大文件 加速运算 对于某些体积巨大的文件,比如其大小超过了计算机文件系统所能存放的最大限制或者是其大小甚至超过了计算机整 ...
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习之旅三:MapReduce
MapReduce编程模型 在Google的一篇重要的论文MapReduce: Simplified Data Processing on Large Clusters中提到,Google公司有大量的 ...
- [Hadoop] Hadoop学习历程 [持续更新中…]
1. Hadoop FS Shell Hadoop之所以可以实现分布式计算,主要的原因之一是因为其背后的分布式文件系统(HDFS).所以,对于Hadoop的文件操作需要有一套全新的shell指令来完成 ...
- Hadoop学习笔记—2.不怕故障的海量存储:HDFS基础入门
一.HDFS出现的背景 随着社会的进步,需要处理数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是却不方便管理和维护—>因此,迫切需要一种系统来管理多 ...
- Hadoop学习路线图
Hadoop家族产品,常用的项目包括Hadoop, Hive, Pig, HBase, Sqoop, Mahout, Zookeeper, Avro, Ambari, Chukwa,新增加的项目包括, ...
- Hadoop学习(5)-- Hadoop2
在Hadoop1(版本<=0.22)中,由于NameNode和JobTracker存在单点中,这制约了hadoop的发展,当集群规模超过2000台时,NameNode和JobTracker已经不 ...
- Hadoop学习总结之五:Hadoop的运行痕迹
Hadoop学习总结之五:Hadoop的运行痕迹 Hadoop 学习总结之一:HDFS简介 Hadoop学习总结之二:HDFS读写过程解析 Hadoop学习总结之三:Map-Reduce入门 Ha ...
- Hadoop学习笔记(7) ——高级编程
Hadoop学习笔记(7) ——高级编程 从前面的学习中,我们了解到了MapReduce整个过程需要经过以下几个步骤: 1.输入(input):将输入数据分成一个个split,并将split进一步拆成 ...
- Hadoop学习笔记(6) ——重新认识Hadoop
Hadoop学习笔记(6) ——重新认识Hadoop 之前,我们把hadoop从下载包部署到编写了helloworld,看到了结果.现是得开始稍微更深入地了解hadoop了. Hadoop包含了两大功 ...
随机推荐
- 在ubuntu上面配置nginx实现反向代理和负载均衡
上一篇文章(http://www.cnblogs.com/chenxizhang/p/4684260.html),我做了一个实验,就是利用Visual Studio,基于Nancy框架,开发了一个自托 ...
- LTP随笔——本地调用ltp之ltp4j
关于ltp本地调用的相关参考请见LTP的Git项目:https://github.com/HIT-SCIR 以下以/home/lion/Desktop路径为例下面教程中出现的具体路径以你实际配置的为准 ...
- hdu4831 Scenic Popularity(线段树)
题目地址:http://acm.hdu.edu.cn/showproblem.php?pid=4831 题目大概意思就是有多个风景区和休息区,每个风景区有热度,休息区的热度与最接近的分景区的热度相同, ...
- HuffmanTree的浅析和在C#中的算法实现
无论是在我们的开发项目中,还是在我们的日常生活中,都会较多的涉及到文件压缩.谈到文件压缩,可能会有人想问文件压缩到底是怎么实现的,实现的原理是什么,对于开发人员来说,怎么实现这样一个压缩的功能. 接下 ...
- Win8.1 安装Express 框架
1.安装Windows Node.js客户端 2.安装Express框架 我本机是Win8.1的,使用命令npm install -g express安装Express,安装完成后显示一些安装明细,刚 ...
- CSS清除浮动
今天看到一篇文章关于清除浮动的,突然间脑袋短路了,咦?为什么要清除浮动?原谅我的无知,搜了下原来是这样,又倒腾出原来的笔记,唉,本来就有记录啊,而且也会经常用到,用的久了连原理都忘了.恩,防止自己再犯 ...
- Windows 10 密钥分享
Windows 10 Technical Preview for Enterprise:KEY:PBHCJ-Q2NYD-2PX34-T2TD6-233PKhttp://technet.microsof ...
- 使用toggle()方法进行显示隐藏
这是一个示例: <html> <head> <script type="text/javascript" src="http://keley ...
- 离线安装swashbuckle(webapi自动文档及测试工具)
1.找到已经成功安装过的项目根目录的packages文件夹拷贝到新的项目的根目录 2.vs设置nuget程序包源 将源:地址改为新项目的packages文件夹 3.重新编译并修改代码 右键项目-> ...
- 分布式系统设计权衡之CAP
写在最前: 1.为什么学习并记录分布式设计理念一系列相关的东西 在日常工作中系统设计评审的时候,经常会有一些同事抛出一些概念,高可用性,一致性等等字眼,他们用这些最基本的概念去反驳系统最初的设计,但是 ...