CSIC_716_20191107【深拷贝、文件的编码解码、文件的打开模式】
深拷贝和浅拷贝
列表的拷贝,用copy方法浅拷贝,新列表和被拷贝列表的id是不一样的。
list1 = [1, 'ss', (5, 6), ['p', 'w','M'], {'key1': 'value1', 'key2':'value2'}]
print('list1', id(list1)) # list1 1964077175880
list2 = list1.copy()
print('list2', id(list2)) # list2 1964333005960
浅拷贝之后,如果在新的列表中改变可变元素,会同步影响被拷贝列表中对应的元素,两者联动
如果在新列表中改变不可变元素,新老列表不会同步变化
list1 = [1, 'ss', (5, 6), ['p', 'w','M']]
print('list1', id(list1)) # list1 2443199403080
list2 = list1.copy()
print('list2', id(list2)) # list2 2443455166280
list2[3][1] = 'qqqqqq' # 对list2中第四个元素进行修改
list2[2] = ('x', 'y')
print('list1第四个元素id', id(list1[3])) # list1第四个元素id 2443199402568
print('list1第一个元素id', id(list1[0])) # list1第一个元素id 140729573994768
print(list1) # [1, 'ss', (5, 6), ['p', 'qqqqqq', 'M']]
print('list2第四个元素id', id(list2[3])) # list2第四个元素id 2443199402568
print('list2第一个元素id', id(list2[0])) # list2第一个元素id 140729573994768
print(list2) # [1, 'ss', ('x', 'y'), ['p', 'qqqqqq', 'M']]
深拷贝需要import copy的包,使用其中的deepcopy函数
深拷贝之后,新旧列表毫无瓜葛,就是完全不相关的两个列表。
深拷贝之后,列表中可变元素的id不一样,不可变元素的id是一样的。
import copy
list1 = [1, 'ss', (5, 6), ['p', 'w','M']]
list2 = copy.deepcopy(list1)
print('list1', id(list1)) # list1 1665335972936
print('list2', id(list2)) # list2 1665620498440
list2[3][1] = 'qqqqqq'
print(list1) # [1, 'ss', (5, 6), ['p', 'w', 'M']]
print(list2) # [1, 'ss', (5, 6), ['p', 'qqqqqq', 'M']]
print('list1第四个元素id', id(list1[3])) # list1第四个元素id 1665335972424
print('list2第四个元素id', id(list2[3])) # list2第四个元素id 1665365546952
文件的编码
在电脑中执行程序的过程
1、硬盘的内容加载到内存
2、CPU去内存中取数据,执行程序。
3、执行生成的数据,优先存入内存。
python解释器在计算机中的运行过程
1、python解释器代码由硬盘加载到内存
2、文件从硬盘加载到内存
3、解释器读取文件内容
4、识别python语法,执行操作
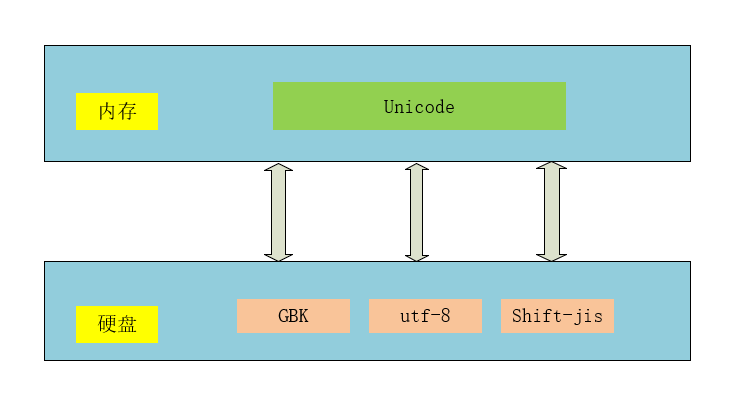
ASCII码 一个字节代表一个英文字母
GBK码 两个字节代表一个中文
utf-8码 一个字节代表英文,3个字节代表汉字
utf-8只和Unicode做映射,其他编码必须先转成unicode,才可以转成utf-8
目前,计算机内存中均是Unicode,硬盘中均是utf-8
字节byte,一个字节由8个bit组成。
编码的过程,由字符转为字节流 encode
解码的过程,由字节流转为字符 decode
用什么格式编码,就要用什么格式解码
unicode(内存) ---> 编码encode---> utf-8(硬盘)
utf-8(硬盘)---> 解码decode---> unicode (内存)
打开文件的三种模式
1、 r模式,
只读,如果文件不存在的话会报错
2、w模式
只写,如果文件不存在,则创建一个文件,将内容写入
如果文件存在,则会先将文件里的内容清空,再将内容写进去
3、a模式
如果文件存在,则再内容后面追加内容
如果文件不存在,则创建一个文件,将内容写入
打开文件的语法格式:
with open(r‘带后缀的文件名’,mode=‘打开模式’,encoding='文件的编码格式')as f :
r : 用来转义‘带后缀的文件名’路径中的转义字符
带后缀的文件名 :可以是绝对路径,也可以是相对路径
文件编码格式 : 与打开的文件编码模式一致即可
f :文件对象的建成,便于后面使用
举例说明:
with open(r'RECORD.txt', 'w', encoding='utf-8') as wf:
wf.write('AAAAAAA') # AAAAAAA
with open(r'RECORD.txt', 'a', encoding='utf-8')as af:
af.write('BBBBB') # AAAAAAABBBBB
也可以同时打开两个文本文件,一个只读一个只写
with open(r'RECORD.txt', 'r', encoding='utf-8') as rf, \ #r默认的时rt,读文本文件的
open(r'newRecord.py', 'w', encoding='utf-8')as wf:
a = rf.read() # 打开RECORD.txt文件
wf.write(a) # 将RECORD.txt文件写入newRecord.py
打开图片等非文本文件,拷贝的时候不要指定encoding参数。
with open(r'th.jpg', 'rb') as rf, open(r'newPhoto.png', 'wb')as wf: #rb用于读byte文件的
sss = rf.read()
wf.write(sss)
CSIC_716_20191107【深拷贝、文件的编码解码、文件的打开模式】的更多相关文章
- WebP 文件及其编码解码工具(WebPconv)
1. webp 文件 与JPEG相同,WebP 是一种有损压缩利用预测编码技术. WebP 是 Google 新推出的影像技术,它可让网页图档有效进行压缩,同时在质量相同的情况下,WebP 格式图像的 ...
- python 对任意文件(jpg,png,mp3,mp4)base64的编码解码
程序是事件驱动的,写博客是什么驱动的?事件? 时间?no,我承认我很懒,甚至不愿意记录总结.哪是什么驱动的? 对! 问题驱动的.遇到了问题解决了问题突然想起来搬到blog上,让遇到相同问题的可以参考下 ...
- Day 07 字符编码,文件操作
今日内容 1.字符编码:人识别的语言与机器识别的语言转换的媒介 2.字符与字节:字符占多少字节,字符串转换 3.文件操作:操作硬盘的一块区域 字符编码 重点:什么是字符编码 人类能识别的字符等高级标识 ...
- C# winform文件批量转编码 选择文件夹
C# winform文件批量转编码 选择文件夹 打开指定目录 private void btnFile_Click(object sender, EventArgs e) { OpenFileDial ...
- 【Python开发】python读写文件,和设置文件的字符编码比如utf-8
一. python打开文件代码如下: f = open("d:\test.txt", "w") 说明: 第一个参数是文件名称,包括路径: 第二个参数是打开的模式 ...
- 编码 解码 python
之前一直对python文件中编码解码糊里糊涂,今天看到一篇文章,觉得把我讲的有点明白了.写个心得吧. 1.编码解码是怎么一回事? Python 里面的编码和解码也就是 unicode 和 str 这两 ...
- [python IO学习篇] 补充.py文件是中文, .ini文件内容是中文
python 代码文件的编码.py文件默认是ASCII编码,中文在显示时会做一个ASCII到系统默认编码的转换,这时就会出错:SyntaxError: Non-ASCII character.需要在代 ...
- day07----字符编码解码、文件操作(1)
字符编码: 什么是字符编码? 字符编码是将人识别的字符转换成计算机能识别的二进制字符(01),转换的规则就是编码表. 人能识别的字符串 与 计算机能识别的二进制字符 两者之间对应关系构成的结构称为 ...
- python基础3之文件操作、字符编码解码、函数介绍
内容概要: 一.文件操作 二.字符编码解码 三.函数介绍 一.文件操作 文件操作流程: 打开文件,得到文件句柄并赋值给一个变量 通过句柄对文件进行操作 关闭文件 基本操作: #/usr/bin/env ...
随机推荐
- ES6篇
ES6新特性你了解了多少呢? 珠峰培训 5月17日 ES6新特性 ES6的特性比较多,在 ES5 发布近 6 年(2009-11 至 2015-6)之后才将其标准化.两个发布版本之间时间跨度很大,所以 ...
- Spring Boot配置随机数
Spring Boot支持在系统加载的时候配置随机数. 添加config/random.properties文件,添加以下内容: #随机32位MD5字符串 user.random.secret=${r ...
- 35-Ubuntu-组管理-01-添加组/删除组/确认组信息
组管理 提示: 创建组/删除组的终端命令都需要sudo执行,标准用户没有权限! 序号 命令 作用 01 sudo groupadd 组名 添加组 02 sudo groupdel 组名 删除组 03 ...
- 2018-2-13-win10-UWP-动画
title author date CreateTime categories win10 UWP 动画 lindexi 2018-2-13 17:23:3 +0800 2018-2-13 17:23 ...
- 【胡策篇】题解 (UOJ 192 + CF938G + SPOJ DIVCNT2)
和泉纱雾与烟花大会 题目来源: UOJ 192 最强跳蚤 (只改了数据范围) 官方题解: 在这里哦~(说的很详细了 我都没啥好说的了) 题目大意: 求树上各边权乘积是完全平方数的路径数量. 这种从\( ...
- Redis缓存数据库简单介绍
\ 1.什么是redis redis是一种基于内存的高性能键值型数据库(key-value),属于NoSQL,和 Memcached 类似: 从内存读取速度为110000次/s,写入内存速度为8100 ...
- loj2000[SDOI2017]数字表格
题意:f为Fibnacci数列.求$\prod_{1<=i<=n,1<=j<=m} f[gcd(i,j)]$. n,m<=1e6. 标程: #include<bit ...
- python 获取年月日时分秒 获取当前时间 datetime函数
import datetime#取当前时间print(datetime.datetime.now())#取年print(datetime.datetime.now().year)#取月print(da ...
- 最小表示法——牛客多校第七场A
脑瘫一样暴力,贪心找最小表示的串,判一个串是否是最小表示法时也是暴力地判.. 但是想不通复杂度是怎么算的.. #include<bits/stdc++.h> using namespace ...
- NX二次开发-UFUN创建图层类别UF_LAYER_create_category
NX11+VS2013 #include <uf.h> #include <uf_layer.h> UF_initialize(); //创建图层类别 UF_LAYER_cat ...