DOM基础+domReady+元素节点类型判断
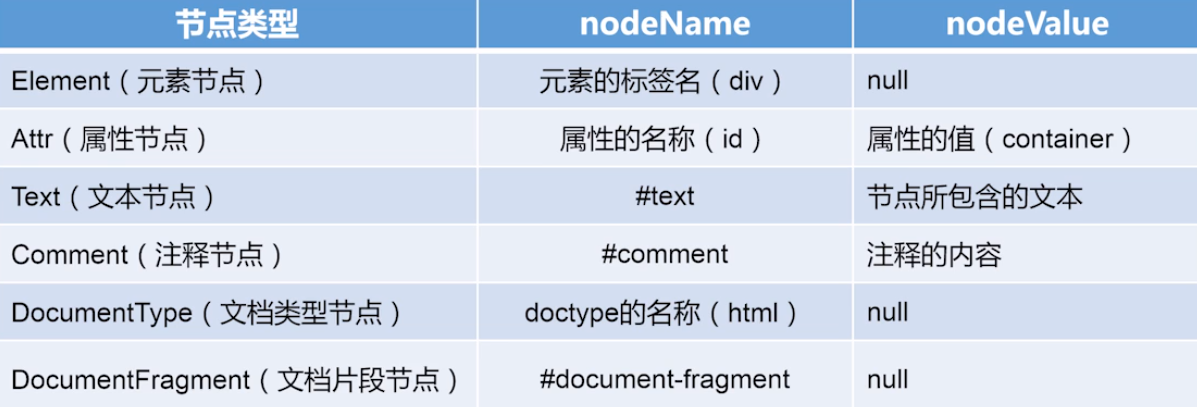
DOM节点类型 nodeType
element 1 Node.ELEMENT_NODE 元素节点
attr 2 Node.ATTRIBUTE_NODE 属性节点
text 3 Node.TEXT_NODE 文本节点(标签之间的空白区域也属于文本节点)
comment 8 Node.COMMENT_NODE 注释节点
document 9 Node.DOCUMENT_NODE 文档节点(所有文档之上,即一个页面中最最前面的位置,在文档定义的前面)
documentType 10 Node.DOCUMENT_TYPE_NODE 文档类型节点(DOCTYPE)
documentFragment 11 Node.DOCUMENT_FRAGMENT_NODE 文档片段节点(不属于文档树,是最小片段,可以作为临时占位符,将它插入文档时,只会插入它的子孙元素,而不是它本身)
注意:IE8及以下没有node,使用常量来判断nodeType会报错:“Node”未定义
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style> </head>
<body>
<div id="container"></div>
<script>
window.onload=function(){ var container=document.getElementById("container");
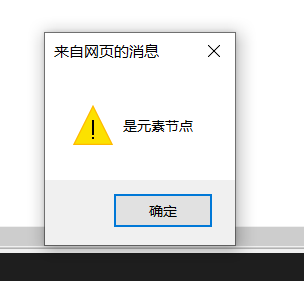
if(container.nodeType==Node.ELEMENT_NODE){
alert("是元素节点");
}
}
</script>
</body>
</html>
因此不建议使用常量来判断,建议使用数值
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style> </head>
<body>
<div id="container"></div>
<script>
window.onload=function(){ var container=document.getElementById("container");
// if(container.nodeType==Node.ELEMENT_NODE){
// alert("是元素节点");
// }
if(container.nodeType==1){
alert("是元素节点");
}
}
</script>
</body>
</html>
nodeName 节点名称
nodeValue 节点值
.attributes 保存元素的所有属性,可以使用数组下标访问某一个具体的属性
.chilsNodes 获取元素的所有子节点,可以使用数组下标访问某一个具体的属性
document.doctype 获取文档类型节点
document.createDocumentFlagment() 创建文档片段
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style> </head>
<body>
<!-- 这是一段注释哈 -->
<div id="container">这是里面的文本鸭</div>
<script>
window.onload=function(){ var container=document.getElementById("container");
console.log("元素节点:"+container.nodeName+"/"+container.nodeValue);//元素节点:DIV/null
var attr=container.attributes[0];//获取元素的第一个属性
console.log("属性节点:"+attr.nodeName+"/"+attr.nodeValue);//属性节点:id/container
var text=container.childNodes[0];//获取元素的第一个子元素节点
console.log("文本节点:"+text.nodeName+"/"+text.nodeValue);//文本节点:#text/这是里面的文本鸭
var comment=document.body.childNodes[1];//获取body元素的第二个子元素节点(第一个子元素节点是空白文本节点)
console.log("注释节点:"+comment.nodeName+"/"+comment.nodeValue);//注释节点:#comment/ 这是一段注释哈
var doctype=document.doctype;//获取body元素的第二个子元素节点(第一个子元素节点是空白文本节点)
console.log("文档类型节点:"+doctype.nodeName+"/"+doctype.nodeValue);//文档类型节点:html/null
var docFragment=document.createDocumentFragment();//获取body元素的第二个子元素节点(第一个子元素节点是空白文本节点)
console.log("文档片段节点:"+docFragment.nodeName+"/"+docFragment.nodeValue);//文档片段节点:#document-fragment/null
}
</script>
</body>
</html>

当script脚本在DOM元素之前,会无法获取到DOM元素
因为把js代码放在head中,代码顺序执行,当页面在浏览器中打开时,会先执行js代码,再执行body里面的dom结构。如果js执行时要获取body中的元素,那么就会报错,因为页面的结构还没有加载进来。
可以使用window.onload解决
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style>
<script>
window.onload=function(){ var container=document.getElementById("container");
console.log(container);
}
</script>
</head>
<body>
<!-- 这是一段注释哈 -->
<div id="container">这是里面的文本鸭</div> </body>
</html>
window.onload缺点:等待DOM树的加载和外部资源全部加载完成
如果页面引用了很多外部资源,会导致加载慢,影响用户体验
最佳解决方案,jquery的$(document).ready()
此处使用原生js仿写该方法
DOMContentLoaded 加载完dom树,但还没有开始加载外部资源
IE不支持该方法,使用:document.documentElement.doScroll("left")
监听document的加载状态 document.onreadystatechange
document加载完成 document.readyState=="complete"
arguments.callee 调用函数自身
自己写的DomReady.js
function myReady(fn){
/*
现代浏览器操作
*/
if(document.addEventListener){
//现代浏览器操作
document.addEventListener("DOMContentLoaded",fn,false);//false表示在冒泡阶段捕获
}else{
//IE环境操作
IEContentLoaded(fn);
}
/*
IE环境操作
*/
function IEContentLoaded(fn){
// init()--保证fn只调用一次
var loaded=false;
var init=function(){
if(!loaded){
loaded=true;
fn();
}
}
// 如果DOM树加载还没完成,就不停尝试
(function(){
try{
// 如果DOM树加载还没完成,会抛出异常
document.documentElement.doScroll("left");
}catch(e){
// 尝试失败,则再次尝试
setTimeout(arguments.callee,50);
return;//实现递归
}
//如果没有抛出异常,则立刻执行init()
init();
})();
// DOM树加载完成之后,调用init()方法
document.onreadystatechange=function(){
if(document.readyState=="complete"){
document.onreadystatechange=null;//清除监听事件
init();
}
}
}
}
调用该js
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style>
<script src="DomReady.js"></script>
<script>
myReady(function(){
var container=document.getElementById("container");
console.log(container);
});
</script>
</head>
<body>
<!-- 这是一段注释哈 -->
<div id="container">这是里面的文本鸭</div> </body>
</html>
实现各浏览器都能成功获取到~
下面来真实感受下window.onload 和domReady的区别!!!
使用多张大图图片来模拟加载时长
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style>
<script src="DomReady.js"></script> </head>
<body>
<!-- 这是一段注释哈 -->
<div id="container">这是里面的文本鸭</div>
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg">
<img src="source/cat.jpg"> <script> myReady(function(){
alert("domReady!");
domready=new Date().getTime();
}); window.onload=function(){
alert("windowLoaded!");
windowload=new Date().getTime();
} </script>
</body>
</html>
发现先弹出domReady
等到图片加载完成之后,才弹出windowLoaded
证实windowLoaded耗时比较久
元素节点的类型判断
isElement() 判断是否是元素节点
isHTML() 判断是否是html文档的元素节点
isXML() 判断是否是xml文档的元素节点
contains() 判断元素节点之间是否是包含关系
.nextSibling 获取元素的兄弟节点
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style>
<script src="DomReady.js"></script> </head>
<body> <div id="container">这是里面的文本鸭</div><!-- 这是一段注释哈 --> <script> myReady(function(){ function isElement(el){
return !!el && el.nodeType===1;
} console.log(isElement(container));
console.log(isElement(container.nextSibling));
}); </script>
</body>
</html>
该方法有一个Bug,即如果有一个对象设置了nodeType属性,会导致判断错误
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style>
<script src="DomReady.js"></script> </head>
<body> <div id="container">这是里面的文本鸭</div><!-- 这是一段注释哈 --> <script> myReady(function(){ function isElement(el){
return !!el && el.nodeType===1;
} var obj={
nodeType:1
}
console.log(isElement(obj));//true
}); </script>
</body>
</html>
isXML() 最严谨的写法
.createElement() 创建元素
如果不区分大小写,则为html文档的元素节点;
如果区分大小写,则为xml文档的元素节点
.ownerDocument返回元素自身的文档对象
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style>
<script src="DomReady.js"></script> </head>
<body> <div id="container">这是里面的文本鸭</div><!-- 这是一段注释哈 --> <script> myReady(function(){
// 判断是否是元素节点
function isElement(el){
return !!el && el.nodeType==1;
}
// 判断是否是xml文档
function isXML(el){
return el.createElement("p").nodeName!==el.createElement("P").nodeName;
}
// 判断是否是html文档
function isHTML(el){
return el.createElement("p").nodeName===el.createElement("P").nodeName;
}
// 判断是否是html文档的元素节点
function isHTMLNode(el){
if(isElement(el)){
return isHTML(el.ownerDocument);
}
return false;
}
console.log(isXML(document));//false
console.log(isHTML(document));//true
console.log(isHTMLNode(container));//true
}); </script>
</body>
</html>
.containers 判断某个节点是否包含另一个节点
谷歌浏览器表现正常,而IE浏览器要求两个节点都必须是元素节点
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style>
<script src="DomReady.js"></script> </head>
<body> <div class="parent" id="parent">
<div class="child" id="child">这是文本节点</div>
</div> <script> myReady(function(){
var parent=document.getElementById("parent");
var child=document.getElementById("child");
console.log(parent.contains(child));//true var text=child.childNodes[0];
console.log(parent.contains(text));//谷歌浏览器true,IE浏览器为false
}); </script>
</body>
</html>
接下来给出兼容性写法
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
<style>
body{
width:100%;
height:100%;
}
</style>
<script src="DomReady.js"></script> </head>
<body> <div class="parent" id="parent">
<div class="child" id="child">这是文本节点</div>
</div> <script> myReady(function(){
var parent=document.getElementById("parent");
var child=document.getElementById("child");
console.log(parent.contains(child));//true var text=child.childNodes[0];
console.log(parent.contains(text));//谷歌浏览器true,IE浏览器为false function fixContains(pNode,cNode){
try{
while(cNode=cNode.parentNode){
if(pNode===cNode) return true;
}
return false;
}catch(e){
return false;
}
}
console.log(fixContains(parent,text));//谷歌浏览器true,IE浏览器为true
}); </script>
</body>
</html>
在所有浏览器里都能返回true,哪怕不是元素节点
DOM基础+domReady+元素节点类型判断的更多相关文章
- 第10章 文档对象模型DOM 10.1 Node节点类型
DOM是针对 HTML 和 XML 文档的一个 API(应用程序编程接口) .DOM描绘了一个层次化的节点树,允许开发人员添加.移除和修改页面的某一部分.DOM 脱胎于Netscape 及微软公司创始 ...
- DOM-判断元素节点类型
http://stackoverflow.com/questions/384286/javascript-isdom-how-do-you-check-if-a-javascript-object-i ...
- JS 清除DOM 中空白元素节点
HTML中的空白节点会影响整体的HTML的版面排榜 例如: 制作百度首页时,两个input之间的空白节点将本来是要整合在一起的搜索栏硬是把按钮和搜索框分离出现好丑的间隙 这时我们就可以用js清除这个空 ...
- DOM基础2——元素
1.造元素 document.createElement("标签名") 例:var div_new=document.createElement("div"); ...
- 深入理解DOM节点类型第七篇——文档节点DOCUMENT
× 目录 [1]特征 [2]快捷访问 [3]文档写入 前面的话 文档节点document,隶属于表示浏览器的window对象,它表示网页页面,又被称为根节点.本文将详细介绍文档节点document的内 ...
- DOM节点类型
DOM1级定义了一个Node接口,该接口将由DOM中的所有节点类型实现.这个Node接口在JavaScript中是作为Node类型实现的:除了IE外,在其他所有浏览器中都可以访问到这个类型.JavaS ...
- javascript DOM中的节点层次和节点类型概述
针对JS高级程序设计这本书,主要是理解概念,大部分要点源自书内.写这个主要是当个笔记加总结 存在的问题请大家多多指正! 因为DOM这方面的对象方法操作性都特别强,但是逻辑很简单,所以就没有涉及到实际的 ...
- js文本对象模型[DOM]【续】(Node节点类型)
一.Document类型 document实例1.常用的一些属性documentElement 始终指向HTML页面中的<html>元素.body 直接指向<body>元 ...
- 深入浅出DOM基础——《DOM探索之基础详解篇》学习笔记
来源于:https://github.com/jawil/blog/issues/9 之前通过深入学习DOM的相关知识,看了慕课网DOM探索之基础详解篇这个视频(在最近看第三遍的时候,准备记录一点东西 ...
随机推荐
- Hexo Next 接入 google AdSense 广告
前言 个人网站 www.yanlongwang.net 已经运营近一年,每日的浏览量不断上升,现在维持在两位数,打算承接一点广告赚睡后收入,用来维持网站的日常运营,希望能覆盖网站的服务器和域名开销. ...
- 实现一个简易的RPC
之前写了一些关于RPC原理的文章,但是觉得还得要实现一个.之前看到一句话觉得非常有道理,与大家共勉.不是“不要重复造轮子”,而是“不要发明轮子”,所以能造轮子还是需要造的. 如果大家还有不了解原理的, ...
- virtualbox更新完无法启动的问题(不能为虚拟电脑 Ubuntu 打开一个新任务)
具体错误: 不能为虚拟电脑 Ubuntu 打开一个新任务. VT-x is disabled in the BIOS. (VERR_VMX_MSR_VMXON_DISABLED). 返回 代码: E_ ...
- jsp操作mysql样例
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding= ...
- 设计模式——Adapter Pattern 适配器模式
我第一次接触设计模式,选取了四大类型里面的结构型,这类型的特点是关注类&对象之间的组合(使用继承),我从中选取适配器模式来具体学习. 一.适配器模式(Adapter Pattern)定义: 适 ...
- Codeforces 1178E Archaeology (鸽巢原理)
题意: 给你1e6的字符串,保证只含'a''b''c'三种字符,且相邻两个字符一定不一样 求一个大于等于n/2的回文子序列 思路: 朴素的最长回文子序列是n方的区间dp,这题显然不行,要充分利用题中所 ...
- num14---享元模式
案例:
- centos系统组件优化
CentOS Linux在公司服务器上广泛被使用,本文总结了一些常见的加固方法. 基本原则: 最小的权限+最小的服务=最大的安全 操作之前先备份: 为避免配置错误无法登录主机,请始终保持有一个终端已用 ...
- 万字分享,我是如何一步一步监控公司MySQL的?
整理了一些Java方面的架构.面试资料(微服务.集群.分布式.中间件等),有需要的小伙伴可以关注公众号[程序员内点事],无套路自行领取 更多优选 一口气说出 9种 分布式ID生成方式,面试官有点懵了 ...
- postman之批量数据参数化(文件)
相信小伙伴们在做接口测试时需要导入大量的数据进行测试,Jmeter进行接口测试时可以导入CSV数据文件进行参数化,那么postman又该如何导入数据文件进行测试呢?下面我给大家讲解一下. 第一:创建t ...