推荐系统之隐语义模型(LFM)
LFM(latent factor model)隐语义模型,这也是在推荐系统中应用相当普遍的一种模型。那这种模型跟ItemCF或UserCF的不同在于:
- 对于UserCF,我们可以先计算和目标用户兴趣相似的用户,之后再根据计算出来的用户喜欢的物品给目标用户推荐物品。
- 而ItemCF,我们可以根据目标用户喜欢的物品,寻找和这些物品相似的物品,再推荐给用户。
- 我们还有一种方法,先对所有的物品进行分类,再根据用户的兴趣分类给用户推荐该分类中的物品,LFM就是用来实现这种方法。
如果要实现最后一种方法,需要解决以下的问题:
- 给物品分类
- 确定用户兴趣属于哪些类及感兴趣程度
- 对于用户感兴趣的类,如何推荐物品给用户
对分类,很容易想到人工对物品进行分类,但是人工分类是一种很主观的事情,比如一部电影用户可能因为这是喜剧片去看了,但也可能因为他是周星驰主演的看了,也有可能因为这是一部属于西游类型的电影,不同的人可以得到不同的分类。
而且对于物品分类的粒度很难控制,究竟需要把物品细分到个程度,比如一本线性代数,可以分类到数学中,也可以分类到高等数学,甚至根据线性代数主要适用的领域再一次细分,但对于非专业领域的人来说,想要对这样的物品进行小粒度细分无疑是一件费力不讨好的事情。
而且一个物品属于某个类,但是这个物品相比其他物品,是否更加符合这个类呢?这也是很难人工确定的事情。解决这个问题,就需要隐语义模型。隐语义模型,可以基于用户的行为自动进行聚类,并且这个类的数量,即粒度完全由可控。
对于某个物品是否属与一个类,完全由用户的行为确定,我们假设两个物品同时被许多用户喜欢,那么这两个物品就有很大的几率属于同一个类。而某个物品在类所占的权重,也完全可以由计算得出。
以下公式便是隐语义模型计算用户u对物品i兴趣的公式:

其中,pu,k度量了用户u的兴趣和第k个隐类的关系,而qi,k度量了第k个隐类和物品i之间的关系
接下的问题便是如何计算这两个参数p和q了,对于这种线性模型的计算方法,这里使用的是梯度下降法。大概的思路便是使用一个数据集,包括用户喜欢的物品和不喜欢的物品,根据这个数据集来计算p和q。
如果没有负样本,则对于一个用户,从他没有过行为的物品采样出一些物品作为负样本,但采样时,保证每个用户的正负样本数目相当。
下面给出公式,对于正样本,我们规定r=1,负样本r=0,需要优化如下损失函数来找到最合适的参数p和参数q:
损失函数里边有两组参数puk和qik,随机梯度下降法,需要对他们分别求偏导数,可得:
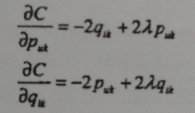
然后,根据随机梯度下降法,需要将参数沿着最速下降方向前进,因此可以得到如下递推公式:

其中α是学习速率,它的选取需要通过反复试验获得。
后面的lambda是为了防止过拟合的正则化项,下面给出Python代码。
from multiprocessing import Pool, Manager
from math import exp
import pandas as pd
import numpy as np
import pickle
import time def getResource(csvPath):
'''
获取原始数据
:param csvPath: csv原始数据路径
:return: frame
'''
frame = pd.read_csv(csvPath)
return frame def getUserNegativeItem(frame, userID):
'''
获取用户负反馈物品:热门但是用户没有进行过评分 与正反馈数量相等
:param frame: ratings数据
:param userID:用户ID
:return: 负反馈物品
'''
userItemlist = list(set(frame[frame['UserID'] == userID]['MovieID'])) #用户评分过的物品
otherItemList = [item for item in set(frame['MovieID'].values) if item not in userItemlist] #用户没有评分的物品
itemCount = [len(frame[frame['MovieID'] == item]['UserID']) for item in otherItemList] #物品热门程度
series = pd.Series(itemCount, index=otherItemList)
series = series.sort_values(ascending=False)[:len(userItemlist)] #获取正反馈物品数量的负反馈物品
negativeItemList = list(series.index)
return negativeItemList def getUserPositiveItem(frame, userID):
'''
获取用户正反馈物品:用户评分过的物品
:param frame: ratings数据
:param userID: 用户ID
:return: 正反馈物品
'''
series = frame[frame['UserID'] == userID]['MovieID']
positiveItemList = list(series.values)
return positiveItemList def initUserItem(frame, userID=1):
'''
初始化用户正负反馈物品,正反馈标签为1,负反馈为0
:param frame: ratings数据
:param userID: 用户ID
:return: 正负反馈物品字典
'''
positiveItem = getUserPositiveItem(frame, userID)
negativeItem = getUserNegativeItem(frame, userID)
itemDict = {}
for item in positiveItem: itemDict[item] = 1
for item in negativeItem: itemDict[item] = 0
return itemDict def initPara(userID, itemID, classCount):
'''
初始化参数q,p矩阵, 随机
:param userCount:用户ID
:param itemCount:物品ID
:param classCount: 隐类数量
:return: 参数p,q
'''
arrayp = np.random.rand(len(userID), classCount)
arrayq = np.random.rand(classCount, len(itemID))
p = pd.DataFrame(arrayp, columns=range(0,classCount), index=userID)
q = pd.DataFrame(arrayq, columns=itemID, index=range(0,classCount))
return p,q def work(id, queue):
'''
多进程slave函数
:param id: 用户ID
:param queue: 队列
'''
print(id)
itemDict = initUserItem(frame, userID=id)
queue.put({id:itemDict}) def initUserItemPool(userID):
'''
初始化目标用户样本
:param userID:目标用户
:return:
'''
pool = Pool()
userItem = []
queue = Manager().Queue()
for id in userID: pool.apply_async(work, args=(id,queue))
pool.close()
pool.join()
while not queue.empty(): userItem.append(queue.get())
return userItem def initModel(frame, classCount):
'''
初始化模型:参数p,q,样本数据
:param frame: 源数据
:param classCount: 隐类数量
:return:
'''
userID = list(set(frame['UserID'].values))
itemID = list(set(frame['MovieID'].values))
p, q = initPara(userID, itemID, classCount)
userItem = initUserItemPool(userID)
return p, q, userItem def sigmod(x):
'''
单位阶跃函数,将兴趣度限定在[0,1]范围内
:param x: 兴趣度
:return: 兴趣度
'''
y = 1.0/(1+exp(-x))
return y def lfmPredict(p, q, userID, itemID):
'''
利用参数p,q预测目标用户对目标物品的兴趣度
:param p: 用户兴趣和隐类的关系
:param q: 隐类和物品的关系
:param userID: 目标用户
:param itemID: 目标物品
:return: 预测兴趣度
'''
p = np.mat(p.ix[userID].values)
q = np.mat(q[itemID].values).T
r = (p * q).sum()
r = sigmod(r)
return r def latenFactorModel(frame, classCount, iterCount, alpha, lamda):
'''
隐语义模型计算参数p,q
:param frame: 源数据
:param classCount: 隐类数量
:param iterCount: 迭代次数
:param alpha: 步长
:param lamda: 正则化参数
:return: 参数p,q
'''
p, q, userItem = initModel(frame, classCount)
for step in range(0, iterCount):
for user in userItem:
for userID, samples in user.items():
for itemID, rui in samples.items():
eui = rui - lfmPredict(p, q, userID, itemID)
for f in range(0, classCount):
print('step %d user %d class %d' % (step, userID, f))
p[f][userID] += alpha * (eui * q[itemID][f] - lamda * p[f][userID])
q[itemID][f] += alpha * (eui * p[f][userID] - lamda * q[itemID][f])
alpha *= 0.9
return p, q def recommend(frame, userID, p, q, TopN=10):
'''
推荐TopN个物品给目标用户
:param frame: 源数据
:param userID: 目标用户
:param p: 用户兴趣和隐类的关系
:param q: 隐类和物品的关系
:param TopN: 推荐数量
:return: 推荐物品
'''
userItemlist = list(set(frame[frame['UserID'] == userID]['MovieID']))
otherItemList = [item for item in set(frame['MovieID'].values) if item not in userItemlist]
predictList = [lfmPredict(p, q, userID, itemID) for itemID in otherItemList]
series = pd.Series(predictList, index=otherItemList)
series = series.sort_values(ascending=False)[:TopN]
return series if __name__ == '__main__':
frame = getResource('ratings.csv')
p, q = latenFactorModel(frame, 5, 10, 0.02, 0.01)
l = recommend(frame, 1, p, q)
print(l)
推荐系统之隐语义模型(LFM)的更多相关文章
- 推荐系统之隐语义模型LFM
LFM(latent factor model)隐语义模型,这也是在推荐系统中应用相当普遍的一种模型.那这种模型跟ItemCF或UserCF的不同在于: 对于UserCF,我们可以先计算和目标用户兴趣 ...
- 推荐系统第5周--- 基于内容的推荐,隐语义模型LFM
基于内容的推荐
- 推荐系统--隐语义模型LFM
主要介绍 隐语义模型 LFM(latent factor model). 隐语义模型最早在文本挖掘领域被提出,用于找到文本的隐含语义,相关名词有 LSI.pLSA.LDA 等.在推荐领域,隐语义模型也 ...
- 海量数据挖掘MMDS week4: 推荐系统之隐语义模型latent semantic analysis
http://blog.csdn.net/pipisorry/article/details/49256457 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 隐语义模型LFM
隐语义模型是通过隐含特征,联系用户和物品,基于用户的特征对物品进行自动聚类,然后在用户感兴趣的类中选择物品推荐给用户. 对于推荐系统,常用的算法: USER-CF:给用户推荐和他兴趣相似的用户喜欢 ...
- 隐语义模型LFM(latent factor model)
对于某个用户,首先得到他的兴趣分类,然后从分类中挑选他可能喜欢的物品.总结一下,这个基于兴趣分类的方法大概需要解决3个问题. 如何给物品进行分类? 如何确定用户对哪些类的物品感兴趣,以及感兴趣的程度? ...
- 【转载】使用LFM(Latent factor model)隐语义模型进行Top-N推荐
最近在拜读项亮博士的<推荐系统实践>,系统的学习一下推荐系统的相关知识.今天学习了其中的隐语义模型在Top-N推荐中的应用,在此做一个总结. 隐语义模型LFM和LSI,LDA,Topic ...
- 使用LFM(Latent factor model)隐语义模型进行Top-N推荐
最近在拜读项亮博士的<推荐系统实践>,系统的学习一下推荐系统的相关知识.今天学习了其中的隐语义模型在Top-N推荐中的应用,在此做一个总结. 隐语义模型LFM和LSI,LDA,Topic ...
- RS:关于协同过滤,矩阵分解,LFM隐语义模型三者的区别
项亮老师在其所著的<推荐系统实战>中写道: 第2章 利用用户行为数据 2.2.2 用户活跃度和物品流行度的关系 [仅仅基于用户行为数据设计的推荐算法一般称为协同过滤算法.学术界对协同过滤算 ...
随机推荐
- e822. 监听JScrollPane的滚动
A scrollbar in a scroll pane fires adjustment events whenever its value changes. // Create a scrolla ...
- adv7180驱动
http://download.csdn.net/download/u013308744/9945184 http://www.ebaina.com/bbs/thread-10121-1-1.html ...
- (原)SDL调试心得
今天在项目中用到SDL2.0的库做视频显示用,在其中出现不少问题,这里一一记录下来,并作为以后的参考. 同一个窗口句柄在多次使用SDL_CreateWindowFrom和SDL_DestroyWind ...
- 回想sql语句中的各种连接
1. 内连接(Inner Join) 内连接是最常见的一种连接,它页被称为普通连接,而E.FCodd最早称之为自然连接. 以下是ANSI SQL-92标准 select * from t_ins ...
- C# where用法解析
where 子句用于指定类型约束,这些约束可以作为泛型声明中定义的类型参数的变量.1.接口约束.例如,可以声明一个泛型类 MyGenericClass,这样,类型参数 T 就可以实现 ICompara ...
- linux中iptables的用法
iptables基本操作笔记 一.基本操作 #启动防火墙 service iptables start #停止防火墙 service iptables stop #重启防火墙 service ipta ...
- sp_replication_agent_checkup
Transact-SQL 参考sp_replication_agent_checkup 检查每个分发数据库的复制代理程序,这些复制代理程序正在运行但在指定的心跳信号间隔内没有历史记录.此存储过程在分发 ...
- UNIX环境编程学习笔记(8)——文件I/O之校验当前登录用户对文件的访问权限
lienhua342014-09-03 通过前面一篇随笔(文件访问权限与进程访问控制),我们知道内核校验文件的访问权限使用的是进程的有效用户 ID 和有效组 ID.但有时我们需要知道当前登录用户对某个 ...
- 文件传输协议(FTP,SFTP,SCP)(修改中)
FTP(File Transfer Protocol):是TCP/IP网络上两台计算机传送文件的协议,FTP是在TCP/IP网络和INTERNET上最早使用的协议之一,它属于网络协议组的应用层.FTP ...
- Django系列之form渲染表单后css样式丢失
最通用的form写法 我们经常看各大网站上写这样的form写法 class SYSAdminPhysicalForm(forms.ModelForm): ''' this form for idc's ...