【软件分析与挖掘】ELBlocker: Predicting blocking bugs with ensemble imbalance learning
摘要:
提出一种方法——ELBlocker,用于自动检测出Blocking Bugs(prevent other bugs from being fixed)。
难度在于这些Blocking Bugs仅占很小的比例( the class imbalance phenomenon)。
方法:给定一个训练集,ELBlocker首先把将训练数据划分为多个互斥的集合。对每个集合建立一个分类器,然后根据混合分类器的结果,设定一个阈值(决策边界),把 blocking bugs from non-blocking bugs分开。
S1 Introduction
ELBloker有两个度量指标:
a.精确度和召回率;F1-Score
F1-Measurea是一个评价指标,经常在信息检索和自然语言处理中使用。
F1-Measure是根据准确率Precision和召回率Recall二者给出的一个综合的评价指标,具体定义如下:
F1 = 2rp / ( r +p )
其中r为recall,p为precision.
b.性能指标;Cost effectiveness
S2 Preliminaries & motivation 初步材料和动机
2.1 实验表明,blocking bug需要很久才能被发现
2.2 两个问题:
a.由子集构造出的分类器性能是否优于由全集构造出的分类器?
实验:(实验时,k取10,9个作为训练集,1个作为测试集)
Ⅰ.训练集分为k个相异的大小相同的子集;
Ⅱ.每个子集建立一个分类器; 同时建立一个分类器基于全集
Ⅲ.使用相同的测试集,让k个分类器去分类; 同时还建立一个随机分类预测;
Ⅳ.用随机森林去构造分类器。
实验结果:
大致趋势可以看出,F1指标随着k增大而增大。
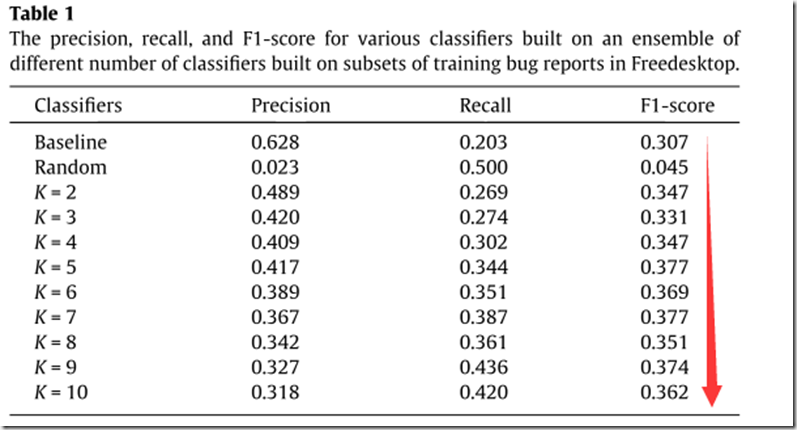
结论:对每个子集建立多个分类器并做预测的结果优于对全集建立一个分类器的结果;
b.不同的决策边界(阈值)是否会导致决策性能的显著性差异?
实验:
Ⅰ.基于全集建立一个分类器;
Ⅱ.对一个新的测试集进行分类,分类度量值与阈值进行比较,观察不同的阈值,F1-score变化。
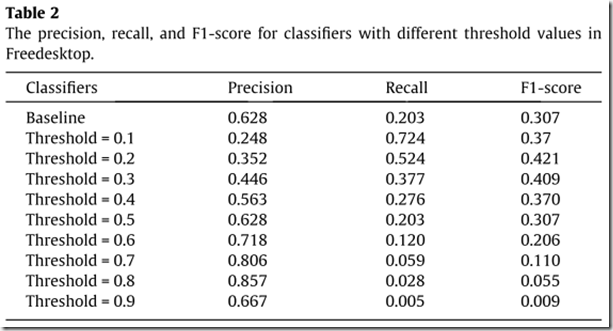
结论:阈值不同,F1-Score不同。
S3 ELBlocker 架构
model building phase and prediction phase.
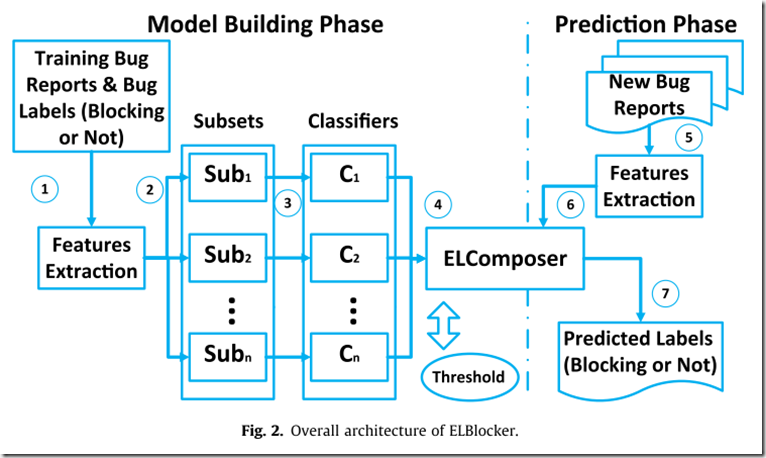
model building phase:基于已标记(blocking or non-blocking)的漏洞日志建立混合模型
prediction phase:分类预测是否为blocking bug
S4 ELBlocker approach
4.1 Subset scores的定义
对于每一个测试集,每一个分类器都会对其进行分类,并给出一个似然值作为Sub(bri)。采用随机森林算法利用训练阶段的数据构造出大量的决策树。在分类决策阶段,通过大多数分类器的结果作为最终的分类标准。
4.2 ELComposer分类器
这里对于ELComposer的值的计算还是比较简单,直接取平均。然后再和阈值比大小。

比较适合的阈值如何自动生成?——贪婪算法,其实我理解中也不是什么贪心,就是每个都算一遍,然后取最大,更像是在枚举。

S5 Experiments and results
5.1 为了比较,采用相同的实验环境,即相同的数据集等等。
6个开源的软件项目: Freedesktop,Chromium,Mozilla,NetBeans,OpenOffice,Eclipse.
其中,Mozilla, Eclipse, Freedesktop and NetBeans使用Bugzilla作为issue tracking system;
OpenOffice使用IssueTracker作为issue tracking system;
Chromium使用Google code作为issue tracking system。
这些issue tracking system的 bug report中都有一个叫“Blocks”的域,这个域可以用于判断这个block是否被屏蔽。
测试时采用10折交叉验证,进行100次。每次交叉验证随机分成10份。
关于 the imbalance class phenomenon(类不平衡现象), Garcia and Shihab等人采用重采样(re-sampling)的方式,利用随机森林的方法进行重新采样取得了不错的效果,而且作者也这么做了。对于类不平衡算法,文中采用了SMOTE和one-sided selection (OSS)两种算法,其中:
SMOTE是属于重采样技术中的一种, SMOTE算法的特点是不按照随机过采样方法简单的复制样例,而是增加新的并不存在的样例,因此在一定程度上可以避免分类器过度拟合。
one-sided selection (OSS) is proposed by Rule Kubat and Matwin attempts to intelligently under-sample(欠采样) the majority class by removing majority class examples that are considered either redundant or noisy.
此外,还采用了bagging算法:bagging是一种用来提高学习算法准确度的方法,这种方法通过构造一个预测函数系列,然后以一定的方式将它们组合成一个预测函数。
1.给定一个弱学习算法,和一个训练集;
2.单个弱学习算法准确率不高;
3.将该学习算法使用多次,得出预测函数序列,进行投票;
4.最后结果准确率将得到提高.
5.2 度量指标
5.2.1 F1-Score(前面已经提过了)
blocking bug 看成 blocking bug的概率:TP
blocking bug 看成 non-blocking bug的概率:FN
non-blocking bug 看成 blocking bug 的概率:FP
non-blocking 看成 non-blocking的概率:TN


5.2.2. Cost effectiveness
we use EffectivenessRatio@20% (ER@20%) as the default cost effectiveness metric.
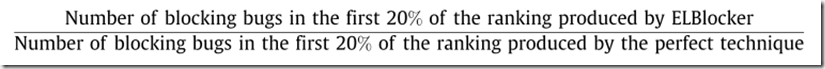
通过ELBlocker找到的前20%的(所有)bug中,blocking bugs的数量 / 通过perfect technique找到的前20%的(所有)bug中,blocking bugs的数量
5.3 研究的问题
RQ1:ELBlocker的性能如何?比最先进的技术可提高多少?
利用F1-Score和ER@20 为指标,
同时计算5种方法:ELBlocker , Garcia and Shihab’s method, SMOTE, OSS, Bagging.
在6个项目上。
同时采用10折交叉验证。
采用Wilcoxon signed-rank方法来测试ELBlocker所带来的提高是否具有统计意义
此外,还利用 Cliff’s delta 来量化两个组之间的差异。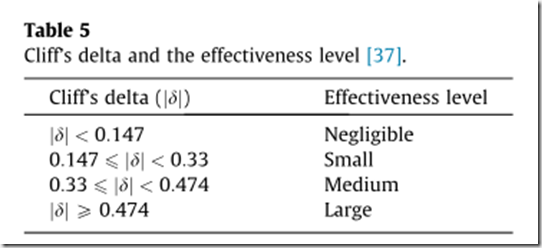
RQ1实验结果:
To summarize, on average ELBlocker improves the F1-scores over Garcia and Shihab’s method, SMOTE, OSS, and Bagging by 14.69%, 23.36%, 30.98%, and 171.65%, respectively. Also, on average ELBlocker improves the ER@20% over Garcia and Shihab’s method, SMOTE, OSS, and Bagging by 8.99%, 15.76%, 22.64%, and 56.82%, respectively. Using the Wilcoxon signed-rank test, we find that the improvements provided by ELBlocker are statistically significantly and have a large effect size.
RQ2:当取不同比例的bug report的时候,ELBlocker和baseline methods的性能区别有多少?即effectiveness at different K
之前是采用ER@20% ,而现在采用ER@K%,也就是说使用不同干的K值去计算性能。
RQ2实验结果:
We notice ELBlocker is better than the baseline methods for a wide range K values.
RQ3:当取不同的子集数量的时候,ELBlocker的性能区别有多少?
之前是默认采用10个子集 ,而现在采用2~20个子集,构造相应的分类器。
RQ3实验结果:
the performance of ELBlocker is generally stable across various numbers of subset classifiers.
RQ4:ELBlocker的时间复杂度?
与其他方法进行运行时间比较。重在比较model building and prediction time
RQ4实验结果:
在可接受的范围内。
S6 讨论
6.1 ELBlocker的有效性
compare ELBlocker with random prediction
结论:To summarize,in most cases (except for Chromium) ELBlocker achieves a much better performance compared to random prediction。
6.2 ELBlocker vs. Bagging + Random Forest
ELBlocker improves the F1-score and ER@20 of Bagging + RA by 175.05% and 12.83%, respectively.
6.3 有效性风险(Threats to validity)
internal validity( relates to errors in our code andexperiment bias) : To reduce training set selection bias, we run 10-fold cross-validation 100 times, and record the average performance.
external validity( relates to the generalizability ofour results.): we plan to reduce this threat further by analyzing even more bug reports from additional software projects.
construct validity( refers to the suitability of our evaluation measures. ): use F1-score and cost effectiveness which are also used by past studies to evaluate the effectiveness of various automated software engineering techniques
S7 相关工作
7.1 Blocking bug prediction
这个问题由Garcia and Shihab最先提出,作者在这个问题上做了更深一步的研究,并证实了自己的方法更好。
7.2. Other studies on bug report management
7.3. Imbalanced learning and ensemble learning
Imbalanced learning:类不平衡学习
欠采样(under-sampling):OSS
重采样(over-sampling):SMOTE
ensemble learning:
本文方法与Bagging很像,Bagging也是对子集构建分类器,不同的是:
To determine the label of an instance, Bagging uses a majority voting mechanism. Our ELBlocker is different from Bagging since we do not use bootstrap sampling to select the subsets, rather we randomly divide the training set into multiple disjoint subsets, and we build a classifier on each of these subsets. Moreover,after we build multiple classifiers, we automatically detect an appropriate imbalanced decision threshold; Bagging does not consider a threshold.
S8 Conclusion and future work
1 将ELBlocker应用在更多的Projects上;
2 利用一些其他的方法(如文本挖掘,数据检索)去提高ELBlocker的效率;
3 开发一个工具去告诉开发人员,不仅仅是一个bug是不是blocking bug,还能告诉他们哪些bug被blocking了。
【软件分析与挖掘】ELBlocker: Predicting blocking bugs with ensemble imbalance learning的更多相关文章
- 【软件分析与挖掘】An Empirical Study of Bugs in Build Process
摘要 对软件构建过程中所产生的错误(build process bugs)进行实证研究. 5个开源项目:CXF, Camel, Felix,Struts, and Tuscany. 把build pr ...
- 【软件分析与挖掘】Vision of Software Clone Management: Past, Present, and Future (Keynote Paper)
abstract: 代码克隆的综述 S1 INTRODUCTION AND MOTIVATION 代码克隆的利弊: 利:可以有效地去耦合,避免其他一些可能的错误: 弊:当被复制的那段code中带 ...
- 【软件分析与挖掘】Multiple kernel ensemble learning for software defect prediction
摘要: 利用软件中的历史缺陷数据来建立分类器,进行软件缺陷的检测. 多核学习(Multiple kernel learning):把历史缺陷数据映射到高维特征空间,使得数据能够更好地表达: 集成学习( ...
- 【软件分析与挖掘】BOAT: An Experimental Platform for Researchers to Comparatively and Reproducibly Evaluate Bug Localization Techniques
摘要: 目前有许多的bug定位技术,但是,由于他们基于不同的数据集,而且有些数据集还不是公开的,甚至有些技术只应用于小数据集,不具有通用性,因此,不好比较这些技术之间的优劣. 因此,BOAT应运而生. ...
- 【软件分析与挖掘】A Comparative Study of Supervised Learning Algorithms for Re-opened Bug Prediction
摘要: 本文主要是评估多种监督机器学习算法的有效性,这些算法用于判断一个错误报告是否是reopened的,算法如下: 7种监督学习算法:kNN,SVM, SimpleLogistic,Bayesian ...
- 第二次作业-Steam软件分析
1 .介绍产品相关信息 随着电子音频游戏产业的发展以及正版意识的崛起,Steam已经成为大部分游戏爱好者必备的一款游戏下载平台.这款软件也使得Valve公司从一个游戏制作公司成功扩展业务到一个承揽众多 ...
- 使用AES加密的勒索类软件分析报告
报告名称: 某勒索类软件分析报告 作者: 李东 报告更新日期: 样本发现日期: 样本类型: 样本文件大小/被感染文件变化长度: 样本文件MD5 校验值: da4ab5e31793 ...
- [软件逆向]实战Mac系统下的软件分析+Mac QQ和微信的防撤回
0x00 一点废话 最近因为Mac软件收费的比较多,所以买了几款正版软件,但是有的软件卖的有点贵,买了感觉不值,不买吧,又觉得不方便,用别人的吧,又怕不安全.于是我就买了正版的Hopper Di ...
- 必应词典手机版(IOS版)与有道词典(IOS版)之软件分析【功能篇】【用户体验篇】
1.序言: 随着手机功能的不断更新和推广,手机应用市场的竞争变得愈发激烈.这次我们选择必应词典和有道词典的苹果客户端作对比,进一步分析这两款词典的客户端在功能和用户体验方面的利弊.这次测评的主要评测人 ...
随机推荐
- JDBC WHERE子句条件实例
在本教程将演示如何在JDBC应用程序中,从数据库表中查询数据记录, 在查询选择记录时使用WHERE子句添加其他条件. 在执行以下示例之前,请确保您已经准备好以下操作: 具有数据库管理员权限,以在给定模 ...
- c# 正则表达式 首字母转大写
class Program { static void Main(string[] args) { // Input strings. const string s1 = "samuel a ...
- (转)YUV420、YUV422、RGB24转换
//平面YUV422转平面RGB24static void YUV422p_to_RGB24(unsigned char *yuv422[3], unsigned char *rgb24, int w ...
- (转)谈谈RTP传输中的负载类型和时间戳
原创作品,允许转载,转载时请务必以超链接形式标明文章 原始出处 .作者信息和本声明.否则将追究法律责任.http://ticktick.blog.51cto.com/823160/350142 最近被 ...
- java Object类源代码详解 及native (转自 http://blog.csdn.net/sjw890821sjw/article/details/8058843)
package java.lang; public class Object { /* 一个本地方法,具体是用C(C++)在DLL中实现的,然后通过JNI调用.*/ private static na ...
- Castle.Windsor依赖注入的高级应用_Castle.Windsor.3.1.0
[转]Castle.Windsor依赖注入的高级应用_Castle.Windsor.3.1.0 1. 使用代码方式进行组件注册[依赖服务类] using System; using System.Co ...
- php脚本超时 结束执行代码
函数:stream_context_create ,file_get_content 创建并返回一个文本数据流并应用各种选项,可用于fopen(),file_get_contents()等过程的超时设 ...
- linux nginx配置新项目加域名
找到nginx的配置文件 nginx/nginx.conf 第一种方,法直接在nginx.com里面配置 user www www; worker_processes auto; error_log ...
- glibc中fork系统调用传参
因为想跟踪下在新建进程时,如何处理新建进程的vruntime,所以跟踪了下fork. 以glic-2.17中ARM为例(unicore架构的没找到),实际上通过寄存器向系统调用传递的参数为: r7: ...
- 为npm设置代理
npm全称为Node Packaged Modules.它是一个用于管理基于node.js编写的package的命令行工具.其本身就是基于node.js写的,这有点像gem与ruby的关系. 在我们的 ...