Python之模块(一)
模块
在计算机程序的开发过程中,随着程序代码越写越多,在一个文件里代码就会越来越长,越来越不容易维护。为了编写可维护的代码,我们把很多函数分组,分别放到不同的文件里,这样,每个文件包含的代码就相对较少,很多编程语言都采用这种组织代码的方式。在Python中,一个.py文件就称之为一个模块(Module)。
使用模块有什么好处?
1.最大的好处是大大提高了代码的可维护性。其次,编写代码不必从零开始。当一个模块编写完毕,就可以被其他地方引用。我们在编写程序的时候,也经常引用其他模块,包括Python内置的模块和来自第三方的模块。
2.使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中,因此,我们自己在编写模块时,不必考虑名字会与其他模块冲突。但是也要注意,尽量不要与内置函数名字冲突。
分类
模块分为三种:
- 自定义模块
- 内置标准模块(又称标准库)
- 开源模块
常用模块
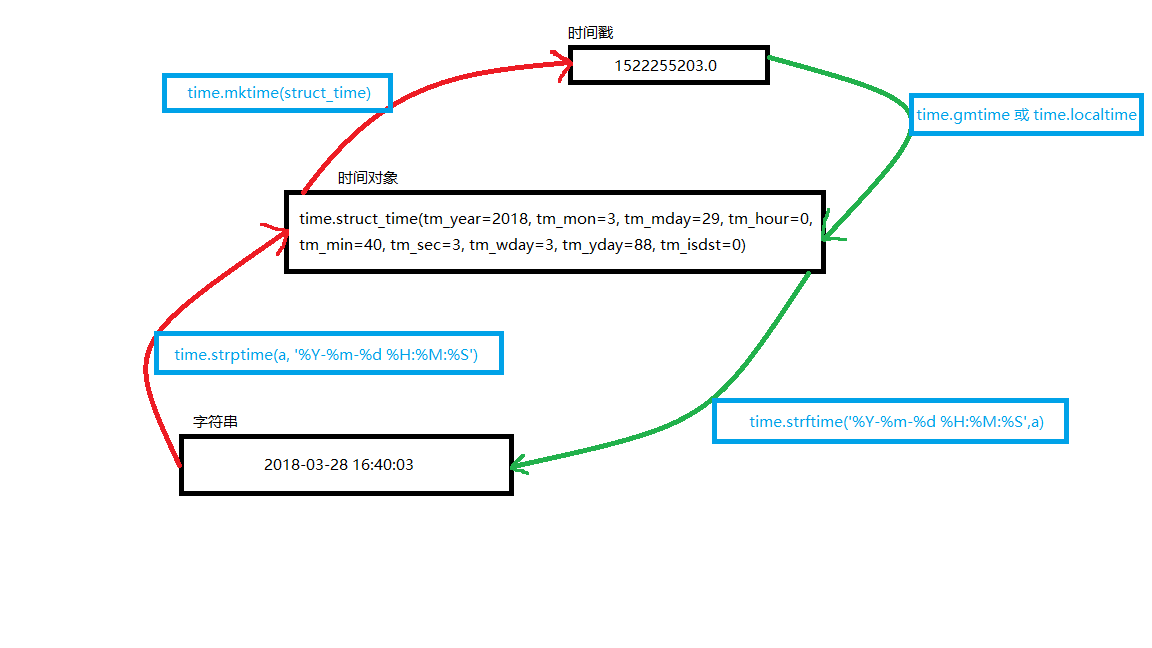
1.time模块——time的三种表现形式及相互转化
import time
# print(time.altzone) #返回与utc时间的时间差,以秒计算\
# print(time.asctime()) #返回时间格式"Fri Aug 19 11:14:16 2016",
# print(time.localtime()) #返回本地时间 的struct time对象格式
# print(time.gmtime(time.time()-800000)) #返回utc时间的struc时间对象格式 # print(time.asctime(time.localtime())) #返回时间格式"Fri Aug 19 11:14:16 2016",
#print(time.ctime()) #返回Fri Aug 19 12:38:29 2016 格式, 同上 # 日期字符串 转成 时间戳
# string_2_struct = time.strptime("2016/05/22","%Y/%m/%d") #将 日期字符串 转成 struct时间对象格式
# print(string_2_struct)
# #
# struct_2_stamp = time.mktime(string_2_struct) #将struct时间对象转成时间戳
# print(struct_2_stamp) #将时间戳转为字符串格式
# print(time.gmtime(time.time()-86640)) #将utc时间戳转换成struct_time格式
# print(time.strftime("%Y-%m-%d %H:%M:%S",time.gmtime()) ) #将utc struct_time格式转成指定的字符串格式
2.datetime模块——相比于time模块,datetime模块的接口更直观,更容易调用
#时间加减 datetime.timedelta()
import datetime
print(datetime.datetime.now()) #返回 2016-08-19 12:47:03.941925
print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19
print(datetime.datetime.now() )
print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天
print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天
print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时
print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分 #时间替换 replace()
c_time = datetime.datetime.now()
print(c_time.replace(minute=3,hour=2))
3.random模块
- random.randomint(x,y):在x~y之间返回随机值,包涵y。
- random.randomrange(x,y):在x~y之间返回随机值,不包涵y。
- random.random():返回一个随机浮点数
- random.choice():返回给定数据集合中的随机字符
- random.sample():从多个字符中返回特定数量的字符
#生成随机字符串(验证码):
import random,string
a = string.digits + string.ascii_letters
''.join(random.sample(a,4)
运行结果:
'XGS0'
#洗牌
b = [0,1,2,3,4,5]
random.shuffle(b)
运行结果:
[0, 5, 2, 4, 3, 1]
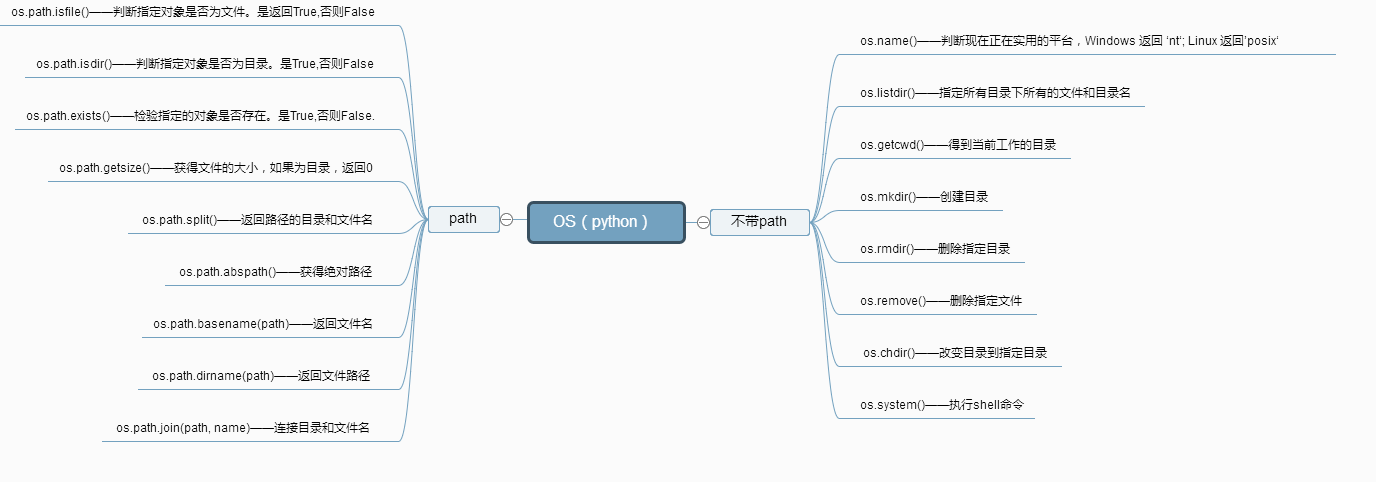
4.os模块
得到当前工作目录,即当前Python脚本工作的目录路径: os.getcwd()
返回指定目录下的所有文件和目录名:os.listdir()
函数用来删除一个文件:os.remove()
删除多个目录:os.removedirs(r“c:\python”)
检验给出的路径是否是一个文件:os.path.isfile()
检验给出的路径是否是一个目录:os.path.isdir()
判断是否是绝对路径:os.path.isabs()
检验给出的路径是否真地存:os.path.exists()
返回一个路径的目录名和文件名:os.path.split() e.g os.path.split('/home/swaroop/byte/code/poem.txt') 结果:('/home/swaroop/byte/code', 'poem.txt')
分离扩展名:os.path.splitext() e.g os.path.splitext('/usr/local/test.py') 结果:('/usr/local/test', '.py')
获取路径名:os.path.dirname()
获得绝对路径: os.path.abspath()
获取文件名:os.path.basename()
运行shell命令: os.system()
读取操作系统环境变量HOME的值:os.getenv("HOME")
返回操作系统所有的环境变量: os.environ
设置系统环境变量,仅程序运行时有效:os.environ.setdefault('HOME','/home/alex')
给出当前平台使用的行终止符:os.linesep Windows使用'\r\n',Linux and MAC使用'\n'
指示你正在使用的平台:os.name 对于Windows,它是'nt',而对于Linux/Unix用户,它是'posix'
重命名:os.rename(old, new)
创建多级目录:os.makedirs(r“c:\python\test”)
创建单个目录:os.mkdir(“test”)
获取文件属性:os.stat(file)
修改文件权限与时间戳:os.chmod(file)
获取文件大小:os.path.getsize(filename)
结合目录名与文件名:os.path.join(dir,filename)
改变工作目录到dirname: os.chdir(dirname)
获取当前终端的大小: os.get_terminal_size()
杀死进程: os.kill(10884,signal.SIGKILL)
5.sys模块
sys.argv 命令行参数List,第一个元素是程序本身路径 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取Python解释程序的版本信息 sys.maxint 最大的Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称 sys.stdout.write('please:') #标准输出 , 引出进度条的例子, 注,在py3上不行,可以用print代替 val = sys.stdin.readline()[:-1] #标准输入 sys.getrecursionlimit() #获取最大递归层数 sys.setrecursionlimit(1200) #设置最大递归层数 sys.getdefaultencoding() #获取解释器默认编码 sys.getfilesystemencoding #获取内存数据存到文件里的默认编码
6.shutil模块——高级的文件、文件夹、压缩包处理模块shutil.coopyfileobj() 将文件内容拷贝到另一个文件中
f1 = open('file.txt', 'r')
f2 = open('file2.txt', 'w')
shutil.copyfileobj(f1, f2, length)
- shutil.copyfile() 拷贝文件
shutil.copy('file.txt', 'file2.txt')
- shutil.copymode() 仅拷贝权限。内容、组、用户均不变
shutil.copymode('f1.log', 'f2.log') #目标文件必须存在
- shutil.copystat() 仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
shutil.copystat('f1.log', 'f2.log') #目标文件必须存在
- shutil.copy() 拷贝文件和权限(copyfile + copymode)
- shutil.copy2 拷贝文件和状态信息(copyfile + copystat)
shutil.copy('file.txt', 'file2.txt')
shutil.copy2('file.txt', 'file2.txt')
- shutil.ignore_patterns(*patterns)
- shutil.copytree(src, dst, symlinks=False, ignore=None)
- 递归的去拷贝文件夹
shutil.copytree('folder1', 'folder2', ignore=shutil.ignore_patterns('*.pyc', 'tmp*')) #目标目录不能存在,注意对folder2目录父级目录要有可写权限,ignore的意思是排除
- shutil.rmtree() 递归的去删除文件
shutil.rmtree('folder1')
- shutil.move() 递归的去移动文件,它类似mv命令,其实就是重命名。
shutil.move('folder1', 'folder3')
- shutil.make_archive(base_name, format,...)
创建压缩包并返回文件路径,例如:zip、tar
创建压缩包并返回文件路径,例如:zip、tar
base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如 data_bak =>保存至当前路径
如:/tmp/data_bak =>保存至/tmp/
- format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
- root_dir: 要压缩的文件夹路径(默认当前目录)
- owner: 用户,默认当前用户
- group: 组,默认当前组
- logger: 用于记录日志,通常是logging.Logger对象
#将 /data 下的文件打包放置当前程序目录
import shutil
ret = shutil.make_archive("data_bak", 'gztar', root_dir='/data') #将 /data下的文件打包放置 /tmp/目录
import shutil
ret = shutil.make_archive("/tmp/data_bak", 'gztar', root_dir='/data')
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的,详细:
1.zipfile压缩&解压缩
import zipfile # 压缩
z = zipfile.ZipFile('laxi.zip', 'w')
z.write('a.log')
z.write('data.data')
z.close() # 解压
z = zipfile.ZipFile('laxi.zip', 'r')
z.extractall(path='.')
z.close()
2.tarfile压缩&解压缩
import tarfile # 压缩
>>> t=tarfile.open('/tmp/egon.tar','w')
>>> t.add('/test1/a.py',arcname='a.bak')
>>> t.add('/test1/b.py',arcname='b.bak')
>>> t.close() # 解压
>>> t=tarfile.open('/tmp/egon.tar','r')
>>> t.extractall('/egon')
>>> t.close()
7.json & pickle模块——序列化模块,指把内存里的数据类型转变成字符串,以使其能存储到硬盘或通过网络传输到远程,因为硬盘或网络传输时只能接受bytes。
把内存转化成字符,叫序列化;把字符转化成内存,叫反序列化。
序列化的两个模块
- json,用于字符串 和 python数据类型间进行转换
- pickle,用于python特有的类型 和 python的数据类型间进行转换
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
json:(本例中menu为一个字典)
- dumps:
d = json.dumps(menu) # 转化为二进制字符串
print(d, type(d))
运行结果:

- dump:
f = open('test.json', 'w')
json.dump(menu, f) # 自动以二进制字符串存入文件
运行结果:

- loads:
d2 = json.loads(d) # 将二进制字符串转化回来
print(d2, type(d2))
运行结果:

- load:
f = open('test.json', 'r')
data = json.load(f) # 将文件内容读取
print(data, type(data))
运行结果:

PS:dump多次会将数据都转化后存入文件,但是!load操作无法多次执行,Python无法识别dump多次后的数据结构。
pickle:(本例中menu为一个字典)
- dumps:
d = pickle.dumps(menu) # 转化为二进制
print(d, '\n', type(d))
运行结果:

- dump:
f = open('test.pkl', 'wb')
json.dump(menu, f) # 以二进制存入文件,打开方式应为wb
运行结果:

- loads:
d2 = pickle.loads(d) # 将二进制字符串转化回来
print(d2,'\n', type(d2))
运行结果:

- load:
f = open('test.pkl', 'rb')
data = pickle.load(f) # 将文件内容读取,文件打开形式为rb
print(data,'\n', type(data))
运行结果:

json & pickle
- json:
- 只支持str,int,tuple,list,dict数据类型
- 数据以str(二进制字符串)形式存储
- pickle:
- 支持python里所有的数据类型
- 只能在python里使用
- 数据以bytes(二进制)形式存储
!shelve模块——对pickle模块进行封装,可以存多个数据结构
序列化:
import shelve
f = shelve.open('shelve_test')
names = [1, 2, 3, 4, 5, 6, 7, 8, 9]
info = {'name': 'Alex', 'age': 22} f['name'] = names # 序列化
f['info_dic'] = info
f.close()
完成以上操作后,windows系统下会生成单个文件

接下来还可以对shelve文件进行多种操作(反序列化):
f = shelve.open('D:\\Python\\Python 3.6.4\\PythonLearning\\练习\\shelve_test') # 此处不用具体到某个文件,只用打开通用的文件名
list(f.keys()) # 查找key值
>>>['name', 'info_dic']
list(f.items()) # 查找各个key-value对
>>>[('name', [1, 2, 3, 4, 5, 6, 7, 8, 9]), ('info_dic', {'name': 'Alex', 'age': 22})]
f.get('name') # 查找固定键的值
[1, 2, 3, 4, 5, 6, 7, 8, 9]
del f['name'] # 删除键-值对
f['goal'] = [1, 2, 3, 4, 5, 6, 7, 8, 9] # 添加键-值对
list(f.items())
结果如下:

8.xml模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,在json还没诞生的年代,大家只能选择用xml,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
<?xml version="1.0"?>
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
xml协议在各个语言里的都 是支持的,在python中可以用以下模块操作xml:
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
print(root.tag)
#遍历xml文档
for child in root:
print(child.tag, child.attrib)
for i in child:
print(i.tag,i.text)
#只遍历year 节点
for node in root.iter('year'):
print(node.tag,node.text)
修改和删除xml文档内容
import xml.etree.ElementTree as ET
tree = ET.parse("xmltest.xml")
root = tree.getroot()
#修改
for node in root.iter('year'):
new_year = int(node.text) + 1
node.text = str(new_year)
node.set("updated","yes")
tree.write("xmltest.xml")
#删除node
for country in root.findall('country'):
rank = int(country.find('rank').text)
if rank > 50:
root.remove(country)
tree.write('output.xml')
自己创建xml文档
import xml.etree.ElementTree as ET
root = ET.Element('namelist')
name = ET.SubElement(root, 'name',attrib={'enrolled': 'yes'})
age = ET.SubElement(name, 'age', attrib={'checked': 'no'})
sex = ET.SubElement(name, 'sex')
sex.text = 'male'
et = ET.ElementTree(root) # 生成文档对象
et.write('test.xml', encoding='utf-8', xml_declaration=True
运行结果:

9.ConfigParser模块
此模块用于生成和修改常见配置文档,来看一个好多软件的常见配置文件格式如下:
[DEFAULT]
ServerAliveInterval = 45
Compression = yes
CompressionLevel = 9
ForwardX11 = yes [bitbucket.org]
User = hg [topsecret.server.com]
Port = 50022
ForwardX11 = no
解析配置文件:
>>> import configparser
>>> config = configparser.ConfigParser()
>>> config.sections()
[]
>>> config.read('example.ini')
['example.ini']
>>> config.sections()
['bitbucket.org', 'topsecret.server.com']
>>> 'bitbucket.org' in config
True
>>> 'bytebong.com' in config
False
>>> config['bitbucket.org']['User']
'hg'
>>> config['DEFAULT']['Compression']
'yes'
>>> topsecret = config['topsecret.server.com']
>>> topsecret['ForwardX11']
'no'
>>> topsecret['Port']
''
>>> for key in config['bitbucket.org']: print(key)
...
user
compressionlevel
serveraliveinterval
compression
forwardx11
>>> config['bitbucket.org']['ForwardX11']
'yes'
其它增删改查语法
########## 读 ##########
secs = config.sections()
print secs
options = config.options('group2')
print options item_list = config.items('group2')
print item_list val = config.get('group1','key')
val = config.getint('group1','key') ########## 改写 ##########
sec = config.remove_section('group1')
config.write(open('i.cfg', "w")) sec = config.has_section('wupeiqi')
sec = config.add_section('wupeiqi')
config.write(open('i.cfg', "w")) config.set('group2','k1',11111)
config.write(open('i.cfg', "w")) config.remove_option('group2','age')
config.write(open('i.cfg', "w"))
10.hashlib模块
加密算法介绍
HASH
Hash,一般翻译做“散列”,也有直接音译为”哈希”的,就是把任意长度的输入(又叫做预映射,pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,而不可能从散列值来唯一的确定输入值。
简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数。
HASH主要用于信息安全领域中加密算法,他把一些不同长度的信息转化成杂乱的128位的编码里,叫做HASH值.也可以说,hash就是找到一种数据内容和数据存放地址之间的映射关系
MD5
什么是MD5算法
MD5讯息摘要演算法(英语:MD5 Message-Digest Algorithm),一种被广泛使用的密码杂凑函数,可以产生出一个128位的散列值(hash value),用于确保信息传输完整一致。MD5的前身有MD2、MD3和MD4。
MD5功能
输入任意长度的信息,经过处理,输出为128位的信息(数字指纹);
不同的输入得到的不同的结果(唯一性);
MD5算法的特点
- 压缩性:任意长度的数据,算出的MD5值的长度都是固定的
- 容易计算:从原数据计算出MD5值很容易
- 抗修改性:对原数据进行任何改动,修改一个字节生成的MD5值区别也会很大
- 强抗碰撞:已知原数据和MD5,想找到一个具有相同MD5值的数据(即伪造数据)是非常困难的。
MD5算法是否可逆?
MD5不可逆的原因是其是一种散列函数,使用的是hash算法,在计算过程中原文的部分信息是丢失了的。
MD5用途
防止被篡改:
比如发送一个电子文档,发送前,我先得到MD5的输出结果a。然后在对方收到电子文档后,对方也得到一个MD5的输出结果b。如果a与b一样就代表中途未被篡改。
比如我提供文件下载,为了防止不法分子在安装程序中添加木马,我可以在网站上公布由安装文件得到的MD5输出结果。
SVN在检测文件是否在CheckOut后被修改过,也是用到了MD5.
防止直接看到明文:
- 现在很多网站在数据库存储用户的密码的时候都是存储用户密码的MD5值。这样就算不法分子得到数据库的用户密码的MD5值,也无法知道用户的密码。(比如在UNIX系统中用户的密码就是以MD5(或其它类似的算法)经加密后存储在文件系统中。当用户登录的时候,系统把用户输入的密码计算成MD5值,然后再去和保存在文件系统中的MD5值进行比较,进而确定输入的密码是否正确。通过这样的步骤,系统在并不知道用户密码的明码的情况下就可以确定用户登录系统的合法性。这不但可以避免用户的密码被具有系统管理员权限的用户知道,而且还在一定程度上增加了密码被破解的难度。)
防止抵赖(数字签名):
- 这需要一个第三方认证机构。例如A写了一个文件,认证机构对此文件用MD5算法产生摘要信息并做好记录。若以后A说这文件不是他写的,权威机构只需对此文件重新产生摘要信息,然后跟记录在册的摘要信息进行比对,相同的话,就证明是A写的了。这就是所谓的“数字签名”。
SHA-1
安全哈希算法(Secure Hash Algorithm)主要适用于数字签名标准(Digital Signature Standard DSS)里面定义的数字签名算法(Digital Signature Algorithm DSA)。对于长度小于2^64位的消息,SHA1会产生一个160位的消息摘要。当接收到消息的时候,这个消息摘要可以用来验证数据的完整性。
SHA是美国国家安全局设计的,由美国国家标准和技术研究院发布的一系列密码散列函数。
由于MD5和SHA-1于2005年被山东大学的教授王小云破解了,科学家们又推出了SHA224, SHA256, SHA384, SHA512,当然位数越长,破解难度越大,但同时生成加密的消息摘要所耗时间也更长。目前最流行的是加密算法是SHA-256 .
MD5与SHA-1的比较
由于MD5与SHA-1均是从MD4发展而来,它们的结构和强度等特性有很多相似之处,SHA-1与MD5的最大区别在于其摘要比MD5摘要长32 比特。对于强行攻击,产生任何一个报文使之摘要等于给定报文摘要的难度:MD5是2128数量级的操作,SHA-1是2160数量级的操作。产生具有相同摘要的两个报文的难度:MD5是264是数量级的操作,SHA-1 是280数量级的操作。因而,SHA-1对强行攻击的强度更大。但由于SHA-1的循环步骤比MD5多80:64且要处理的缓存大160比特:128比特,SHA-1的运行速度比MD5慢。
Python的 提供的相关模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
import hashlib m = hashlib.md5()
m.update(b"Hello") # 将md5加密后的Hello存入m中
m.update(b"It's me")
print(m.digest())
m.update(b"It's been a long time since last time we ...") print(m.digest()) #2进制格式hash
print(len(m.hexdigest())) #16进制格式hash
'''
def digest(self, *args, **kwargs): # real signature unknown
""" Return the digest value as a string of binary data. """
pass def hexdigest(self, *args, **kwargs): # real signature unknown
""" Return the digest value as a string of hexadecimal digits. """
pass '''
import hashlib # ######## md5 ######## hash = hashlib.md5()
hash.update('admin')
print(hash.hexdigest()) # ######## sha1 ######## hash = hashlib.sha1()
hash.update('admin')
print(hash.hexdigest()) # ######## sha256 ######## hash = hashlib.sha256()
hash.update('admin')
print(hash.hexdigest()) # ######## sha384 ######## hash = hashlib.sha384()
hash.update('admin')
print(hash.hexdigest()) # ######## sha512 ######## hash = hashlib.sha512()
hash.update('admin')
print(hash.hexdigest())
Python之模块(一)的更多相关文章
- Python标准模块--threading
1 模块简介 threading模块在Python1.5.2中首次引入,是低级thread模块的一个增强版.threading模块让线程使用起来更加容易,允许程序同一时间运行多个操作. 不过请注意,P ...
- Python的模块引用和查找路径
模块间相互独立相互引用是任何一种编程语言的基础能力.对于“模块”这个词在各种编程语言中或许是不同的,但我们可以简单认为一个程序文件是一个模块,文件里包含了类或者方法的定义.对于编译型的语言,比如C#中 ...
- Python Logging模块的简单使用
前言 日志是非常重要的,最近有接触到这个,所以系统的看一下Python这个模块的用法.本文即为Logging模块的用法简介,主要参考文章为Python官方文档,链接见参考列表. 另外,Python的H ...
- Python标准模块--logging
1 logging模块简介 logging模块是Python内置的标准模块,主要用于输出运行日志,可以设置输出日志的等级.日志保存路径.日志文件回滚等:相比print,具备如下优点: 可以通过设置不同 ...
- python基础-模块
一.模块介绍 ...
- python 安装模块
python安装模块的方法很多,在此仅介绍一种,不需要安装其他附带的pip等,python安装完之后,配置环境变量,我由于中英文分号原因,环境变量始终没能配置成功汗. 1:下载模块的压缩文件解压到任意 ...
- python Queue模块
先看一个很简单的例子 #coding:utf8 import Queue #queue是队列的意思 q=Queue.Queue(maxsize=10) #创建一个queue对象 for i in ra ...
- python logging模块可能会令人困惑的地方
python logging模块主要是python提供的通用日志系统,使用的方法其实挺简单的,这块就不多介绍.下面主要会讲到在使用python logging模块的时候,涉及到多个python文件的调 ...
- Python引用模块和查找模块路径
模块间相互独立相互引用是任何一种编程语言的基础能力.对于"模块"这个词在各种编程语言中或许是不同的,但我们可以简单认为一个程序文件是一个模块,文件里包含了类或者方法的定义.对于编译 ...
- Python Paramiko模块与MySQL数据库操作
Paramiko模块批量管理:通过调用ssh协议进行远程机器的批量命令执行. 要使用paramiko模块那就必须先安装这个第三方模块,仅需要在本地上安装相应的软件(python以及PyCrypto), ...
随机推荐
- 服务器购买+建站流程教程——适合新手没有经验的人Chinar总结
服务器购买购买教程 本文提供全图文流程,中文翻译. Chinar 坚持将简单的生活方式,带给世人!(拥有更好的阅读体验 -- 高分辨率用户请根据需求调整网页缩放比例) Chinar -- 心分享.心创 ...
- Unity 3D中 Ulua-UGUI简单的Demo——热更新的具体流程、使用说明
Ulua热更新具体流程.使用说明 本文提供全流程,中文翻译.Chinar坚持将简单的生活方式,带给世人!(拥有更好的阅读体验 -- 高分辨率用户请根据需求调整网页缩放比例) 1 -- 未完 1 -- ...
- jquery中.prev()
☆ 遍历 - .prev()方法:取得一个包含匹配的元素集合中每一个元素紧邻的前一个同辈元素的元素集合.选择性筛选的选择器. (previous:上一个,上一页,前一个,以前的......) 示例: ...
- Comet OJ - Contest #2简要题解
Comet OJ - Contest #2简要题解 前言: 我没有小裙子,我太菜了. A 因自过去而至的残响起舞 https://www.cometoj.com/contest/37/problem/ ...
- SolrCloud6.3 单机、集群、内置jetty、tomcat搭建、对collection操作
参考:https://my.oschina.net/u/1416405/blog/821187 1.Solr 单机 1.1.Solr下载 1.solr官网:http://lucene.apache.o ...
- 如何取出word文档里的图片
在生活当中,Word办公是必不可少的.但是在工作中也会遇到一些麻烦,比如说如何取出word文档里的图片呢?有的人会通过复制粘贴,通过画图保存,可是这种方法未免太繁琐了吧.下面我就来分享一下我的经验. ...
- zz 史上最全--各银行借记卡的年费、小额管理费、转账费等!
史上最全--各银行借记卡的年费.小额管理费.转账费等! 发布时间:2015-01-14 17:28:10 还在迷茫借记卡自费的菜主儿们~菜菜特别整理关于各银行借记卡.存折账户等的年费.小额管理费.转账 ...
- 【转】Ubuntu12.04 LTS下环境变量设置
原文网址:http://blog.chinaunix.net/uid-26963688-id-3221439.html 1.设置当前用户环境变量(对root用户无效) 打开终端输入:light@cha ...
- java中String对象的存储位置
public class Test { public static void main(String args[]) { String s1 = "Java"; String s2 ...
- 打开安装 好的Microsoft Dynamics CRM 4.0 报错误为 Caller does not have enough privilege to set CallerOriginToken to the specified value 的解决办法
If you installed CRM 4.0 on box where you also have SQL and used a domain account as service account ...