RabbitMQ-2 工作队列
参考:http://rabbitmq.mr-ping.com/
工作队列
(使用pika 0.9.5 Python客户端)

在第一篇教程中,我们已经写了一个从已知队列中发送和获取消息的程序。在这篇教程中,我们将创建一个工作队列(Work Queue),它会发送一些耗时的任务给多个工作者(Worker)。
工作队列(又称:任务队列——Task Queues)是为了避免等待一些占用大量资源、时间的操作。当我们把任务(Task)当作消息发送到队列中,一个运行在后台的工作者(worker)进程就会取出任务然后处理。当你运行多个工作者(workers),任务就会在它们之间共享。
这个概念在网络应用中是非常有用的,它可以在短暂的HTTP请求中处理一些复杂的任务。
准备
秒钟。比如"Hello..."就会耗时3秒钟。
我们对之前教程的send.py做些简单的调整,以便可以发送随意的消息。这个程序会按照计划发送任务到我们的工作队列中。我们把它命名为new_task.py:
import sys
message = ' '.join(sys.argv[1:]) or
"Hello World!"
channel.basic_publish(exchange='',
routing_key='hello',
body=message)
print
" [x] Sent %r" % (message,)
秒钟的操作。它会从队列中获取消息并执行,我们把它命名为worker.py:
import time
def
callback(ch, method, properties, body):
print
" [x] Received %r" % (body,)
time.sleep( body.count('.') )
print
" [x] Done"
循环调度:
使用工作队列的一个好处就是它能够并行的处理队列。如果堆积了很多任务,我们只需要添加更多的工作者(workers)就可以了,扩展很简单。
首先,我们先同时运行两个worker.py脚本,它们都会从队列中获取消息,到底是不是这样呢?我们看看。
你需要打开三个终端,两个用来运行worker.py脚本,这两个终端就是我们的两个消费者(consumers)—— C1 和 C2。
shell1$ python worker.py
[*] Waiting for messages. To exit press CTRL+C
shell2$ python worker.py
[*] Waiting for messages. To exit press CTRL+C
第三个终端,我们用来发布新任务。你可以发送一些消息给消费者(consumers):
shell3$ python new_task.py First message.
shell3$ python new_task.py Second message..
shell3$ python new_task.py Third message...
shell3$ python new_task.py Fourth message....
shell3$ python new_task.py Fifth message.....
看看到底发送了什么给我们的工作者(workers):
shell1$ python worker.py
[*] Waiting for messages. To exit press CTRL+C
[x] Received 'First message.'
[x] Received 'Third message...'
[x] Received 'Fifth message.....'
shell2$ python worker.py
[*] Waiting for messages. To exit press CTRL+C
[x] Received 'Second message..'
[x] Received 'Fourth message....'
默认来说,RabbitMQ会按顺序得把消息发送给每个消费者(consumer)。平均每个消费者都会收到同等数量得消息。这种发送消息得方式叫做——轮询(round-robin)。试着添加三个或更多得工作者(workers)。
消息确认
当处理一个比较耗时得任务的时候,你也许想知道消费者(consumers)是否运行到一半就挂掉。当前的代码中,当消息被RabbitMQ发送给消费者(consumers)之后,马上就会在内存中移除。这种情况,你只要把一个工作者(worker)停止,正在处理的消息就会丢失。同时,所有发送到这个工作者的还没有处理的消息都会丢失。
我们不想丢失任何任务消息。如果一个工作者(worker)挂掉了,我们希望任务会重新发送给其他的工作者(worker)。
为了防止消息丢失,RabbitMQ提供了消息响应(acknowledgments)。消费者会通过一个ack(响应),告诉RabbitMQ已经收到并处理了某条消息,然后RabbitMQ就会释放并删除这条消息。
如果消费者(consumer)挂掉了,没有发送响应,RabbitMQ就会认为消息没有被完全处理,然后重新发送给其他消费者(consumer)。这样,及时工作者(workers)偶尔的挂掉,也不会丢失消息。
消息是没有超时这个概念的;当工作者与它断开连的时候,RabbitMQ会重新发送消息。这样在处理一个耗时非常长的消息任务的时候就不会出问题了。
消息响应默认是开启的。之前的例子中我们可以使用no_ack=True标识把它关闭。是时候移除这个标识了,当工作者(worker)完成了任务,就发送一个响应。
def
callback(ch, method, properties, body):
print
" [x] Received %r" % (body,)
time.sleep( body.count('.') )
print
" [x] Done"
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_consume(callback,
queue='hello')
运行上面的代码,我们发现即使使用CTRL+C杀掉了一个工作者(worker)进程,消息也不会丢失。当工作者(worker)挂掉这后,所有没有响应的消息都会重新发送。
忘记确认
一个很容易犯的错误就是忘了basic_ack,后果很严重。消息在你的程序退出之后就会重新发送,如果它不能够释放没响应的消息,RabbitMQ就会占用越来越多的内存。
为了排除这种错误,你可以使用rabbitmqctl命令,输出messages_unacknowledged字段:
$ sudo rabbitmqctl list_queues name messages_ready messages_unacknowledged
Listing queues ...
hello 0 0
...done.
消息持久化
如果你没有特意告诉RabbitMQ,那么在它退出或者崩溃的时候,将会丢失所有队列和消息。为了确保信息不会丢失,有两个事情是需要注意的:我们必须把"队列"和"消息"设为持久化。
首先,为了不让队列消失,需要把队列声明为持久化(durable):
channel.queue_declare(queue='hello', durable=True)
尽管这行代码本身是正确的,但是仍然不会正确运行。因为我们已经定义过一个叫hello的非持久化队列。RabbitMq不允许你使用不同的参数重新定义一个队列,它会返回一个错误。但我们现在使用一个快捷的解决方法——用不同的名字,例如task_queue。
channel.queue_declare(queue='task_queue', durable=True)
这个queue_declare必须在生产者(producer)和消费者(consumer)对应的代码中修改。
。
channel.basic_publish(exchange='',
routing_key="task_queue",
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
注意:消息持久化
将消息设为持久化并不能完全保证不会丢失。以上代码只是告诉了RabbitMq要把消息存到硬盘,但从RabbitMq收到消息到保存之间还是有一个很小的间隔时间。因为RabbitMq并不是所有的消息都使用fsync(2)——它有可能只是保存到缓存中,并不一定会写到硬盘中。并不能保证真正的持久化,但已经足够应付我们的简单工作队列。如果你一定要保证持久化,你需要改写你的代码来支持事务(transaction)。
公平调度
你应该已经发现,它仍旧没有按照我们期望的那样进行分发。比如有两个工作者(workers),处理奇数消息的比较繁忙,处理偶数消息的比较轻松。然而RabbitMQ并不知道这些,它仍然一如既往的派发消息。
这时因为RabbitMQ只管分发进入队列的消息,不会关心有多少消费者(consumer)没有作出响应。它盲目的把第n-th条消息发给第n-th个消费者。
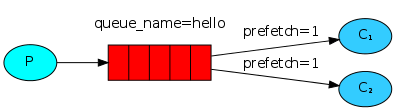
条消息给一个工作者(worker),直到它已经处理了上一条消息并且作出了响应。这样,RabbitMQ就会把消息分发给下一个空闲的工作者(worker)。
channel.basic_qos(prefetch_count=1)
关于队列大小
如果所有的工作者都处理繁忙状态,你的队列就会被填满。你需要留意这个问题,要么添加更多的工作者(workers),要么使用其他策略。
整合代码
new_task.py的完整代码:
#!/usr/bin/env python
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
message = ' '.join(sys.argv[1:]) or
"Hello World!"
channel.basic_publish(exchange='',
routing_key='task_queue',
body=message,
properties=pika.BasicProperties(
delivery_mode = 2, # make message persistent
))
print
" [x] Sent %r" % (message,)
connection.close()
(new_task.py源码)
我们的worker:
#!/usr/bin/env python
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='task_queue', durable=True)
print
' [*] Waiting for messages. To exit press CTRL+C'
def
callback(ch, method, properties, body):
print
" [x] Received %r" % (body,)
time.sleep( body.count('.') )
print
" [x] Done"
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1)
channel.basic_consume(callback,
queue='task_queue')
channel.start_consuming()
(worker.py source)
使用消息响应和prefetch_count你就可以搭建起一个工作队列了。这些持久化的选项使得在RabbitMQ重启之后仍然能够恢复。
学习如何发送相同的消息给多个消费者(consumers)。
RabbitMQ-2 工作队列的更多相关文章
- 【译】RabbitMQ:工作队列(Work Queue)
在第一篇我们写了两个程序通过一个命名的队列分别发送和接收消息.在这一篇,我们将创建一个工作队列在多个工作线程间分发耗时的工作任务. 工作队列的核心思想是避免立刻处理资源密集型任务导致必须等待其执行完成 ...
- RabbitMQ的工作队列和路由
工作队列:Working Queue 工作队列这个概念与简单的发送/接收消息的区别就是:接收方接收到消息后,可能需要花费更长的时间来处理消息,这个过程就叫一个Work/Task. 几个概念 分 ...
- RabbitMQ 笔记-工作队列
工作队列的主要思想是不用等待资源密集型的任务处理完成, 为了确保消息或者任务不会丢失,rabbitmq 支持消息确信 ACK.ACK机制是消费者端从rabbitmq收到消息并处理完成后,反馈给rabb ...
- RabbitMQ之工作队列
工作队列 工作队列(又称:任务队列Task Queues)是为了避免等待一些占用大量资源.时间的操作,当我们把任务Task当做消息发送队列中,一个运行在后台的工作者worker进程就会取出任务然后处理 ...
- RabbitMQ (四) 工作队列之公平分发
上篇文章讲的轮询分发 : 1个队列,无论多少个消费者,无论消费者处理消息的耗时长短,大家消费的数量都一样. 而公平分发,又叫 : 能者多劳,顾名思义,处理得越快,消费得越多. 生产者 public c ...
- RabbitMQ (三) 工作队列之轮询分发
上一篇讲了简单队列,实际工作中,这种队列应该很少用到,因为生产者发送消息的耗时一般都很短,但是消费者收到消息后,往往伴随着对高消息的业务逻辑处理,是个耗时的过程,这势必会导致大量的消息积压在一个消费者 ...
- RabbitMQ学习笔记(二) 工作队列
什么是工作队列? 工作队列(又名任务队列)是RabbitMQ提供的一种消息分发机制.当一个Consumer实例正在进行资源密集任务的时候,后续的消息处理都需要等待这个实例完成正在执行的任务,这样就导致 ...
- RabbitMQ入门(二)工作队列
在文章RabbitMQ入门(一)之Hello World,我们编写程序通过指定的队列来发送和接受消息.在本文中,我们将会创建工作队列(Work Queue),通过多个workers来分配耗时任务. ...
- .NET Core RabbitMQ探索(1)
RabbitMQ可以被比作一个邮局,当你向邮局寄一封信时,邮局会保证将这封信送达你写的收件人,而RabbitMQ与邮局最主要的区别是,RabbitMQ并不真的处理信件,它处理的是二进制的数据块,它除了 ...
- 消息中间件-RabbitMQ基本使用
RabbitMQ是实现了高级消息队列协议(AMQP)的开源消息代理软件(亦称面向消息的中间件).RabbitMQ服务器是用Erlang语言编写的,而集群和故障转移是构建在开放电信平台框架上的.所有主要 ...
随机推荐
- SpingBoot三——基础架构
◆版权声明:本文出自胖喵~的博客,转载必须注明出处. 转载请注明出处:https://www.cnblogs.com/by-dream/p/10492073.html 继续上一节,为了更好的开发,现将 ...
- <NET CLR via c# 第4版>笔记 第18章 定制特性
18.1 使用定制特性 FCL 中的几个常用定制特性. DllImport 特性应用于方法,告诉 CLR 该方法的实现位于指定 DLL 的非托管代码中. Serializable 特性应用于类型,告诉 ...
- 安装Win8后必做的优化
原版或者精简版的希望都看看安装好Win8后必做的优化:1.关闭家庭组,因为这功能会导致硬盘和CPU处于高负荷状态关闭方法:Win+C – 设置 – 更改电脑设置 – 家庭组 – 离开如果用不到家庭组可 ...
- Beta阶段第1周/共2周 Scrum立会报告+燃尽图 05
作业要求与 [https://edu.cnblogs.com/campus/nenu/2018fall/homework/2284] 相同 版本控制:https://git.coding.net/li ...
- L210 Ebola
Progress in fighting Democratic Republic of the Congo's Ebola outbreak, the second worst ever, will ...
- 子域名爆破&C段查询&调用Bing查询同IP网站
在线子域名爆破 <?php function domainfuzz($domain) { $ip = gethostbyname($domain); preg_match("/\d+\ ...
- Linux:man命令显示颜色
man命令显示颜色 在.bashrc下添加 export LESS_TERMCAP_mb=$'\E[01;31m' export LESS_TERMCAP_md=$'\E[01;31m' export ...
- Android逆向之旅---Native层的Hook神器Cydia Substrate使用详解
一.前言 在之前已经介绍过了Android中一款hook神器Xposed,那个框架使用非常简单,方法也就那几个,其实最主要的是我们如何找到一个想要hook的应用的那个突破点.需要逆向分析app即可.不 ...
- 5.1 socket编程、简单并发服务器
什么是socket? socket可以看成是用户进程与内核网络协议栈的编程接口.是一套api函数. socket不仅可以用于本机的进程间通信,还可以用于网络上不同主机间的进程间通信. 工业上使用的为t ...
- [LeetCode&Python] Problem 693. Binary Number with Alternating Bits
Given a positive integer, check whether it has alternating bits: namely, if two adjacent bits will a ...