(一)Lucene简介以及索引demo
一、百度百科
- Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆
二、索引过程
索引过程是Lucene提供的核心功能之一。下图说明了索引过程和使用的类

三、demo
3.1 创建文档
- 从一个文件中获取lucene文档
- 创建各种类型的是含有键作为名称和值作为内容被编入索引键值对字段。
- 新创建的字段添加到文档对象并返回给调用者的方法
/**
* 从文件中获取文档
*
* @param file
* @return
* @throws IOException
*/
private Document getDocument(File file) throws IOException {
Document document = new Document(); Field contentField = new TextField("fileContents", new FileReader(file));
/**
* Field.Store.YES表示把该Field的值存放到索引文件中,提高效率,一般用于文件的标题和路径等常用且小内容小的。
*/
Field fileNameField = new TextField("fileName", file.getName(), Field.Store.YES);
Field filePathField = new TextField("filePath", file.getCanonicalPath(), Field.Store.YES); document.add(contentField);
document.add(fileNameField);
document.add(filePathField); return document;
}
3.2 创建IndexWriter
IndexWriter 类作为它创建/在索引过程中更新指标的核心组成部分
创建一个 IndexWriter 对象
创建其应指向位置,其中索引是存储一个lucene的目录
初始化索引目录,有标准的分析版本信息和其他所需/可选参数创建 IndexWriter 对象
// 写索引
private IndexWriter indexWriter; /**
* 实例化写索引
*
* @param dir
* 保存索引的目录
* @throws IOException
*/
public Indexer(String dir) throws IOException {
Directory indexDir = new SimpleFSDirectory(Paths.get(dir)); /**
* IndexWriterConfig实例化该类的时候如果是空的构造方法,那么默认 public IndexWriterConfig() { this(new
* StandardAnalyzer()); }
*/Analyzer analyzer=new StandardAnalyzer(); //分词器
IndexWriterConfig conf = new IndexWriterConfig(analyzer);
}
3.3 开始索引过程
/**
* 索引文件
*/ public void index(File file) throws Exception {
System.out.println("被索引的文件为:" + file.getCanonicalPath());
Document document = getDocument(file);
indexWriter.addDocument(document); }
.txt 文件过滤器
public class FileFilter implements java.io.FileFilter{
public boolean accept(File pathname) {
return pathname.getName().toLowerCase().endsWith(".txt");
}
}
- Indexer类以及测试
package com.shyroke.lucene; import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.nio.file.Paths; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexableFieldType;
import org.apache.lucene.queries.function.valuesource.DualFloatFunction;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.SimpleFSDirectory; public class Indexer {
// 写索引
private IndexWriter indexWriter; /**
* 实例化写索引
*
* @param dir
* 保存索引的目录
* @throws IOException
*/
public Indexer(String dir) throws IOException {
Directory indexDir = new SimpleFSDirectory(Paths.get(dir)); /**
* IndexWriterConfig实例化该类的时候如果是空的构造方法,那么默认 public IndexWriterConfig() { this(new
* StandardAnalyzer()); }
*/ Analyzer analyzer=new StandardAnalyzer(); //分词器
IndexWriterConfig conf = new IndexWriterConfig(analyzer); indexWriter = new IndexWriter(indexDir, conf);
} /**
* 索引文件
*/ public void index(File file) throws Exception {
System.out.println("被索引的文件为:" + file.getCanonicalPath());
Document document = getDocument(file);
indexWriter.addDocument(document); } /**
* 从文件中获取文档
*
* @param file
* @return
* @throws IOException
*/
private Document getDocument(File file) throws IOException {
Document document = new Document(); Field contentField = new TextField("fileContents", new FileReader(file));
/**
* Field.Store.YES表示把该Field的值存放到索引文件中,提高效率,一般用于文件的标题和路径等常用且小内容小的。
*/
Field fileNameField = new TextField("fileName", file.getName(), Field.Store.YES);
Field filePathField = new TextField("filePath", file.getCanonicalPath(), Field.Store.YES); document.add(contentField);
document.add(fileNameField);
document.add(filePathField); return document;
} /**
* 创建索引
*
* @param dataFile 数据文件所在的目录
* @return 索引文件的数量
* @throws Exception
*/
public int CreateIndex(String dataFile, FileFilter filter) throws Exception { File[] files = new File(dataFile).listFiles(); for (File file : files) {
/**
* 被索引文件必须不能是 1.目录 2.隐藏 3. 不可读 4.不是txt文件,
* 否则不被索引
*/ if (!file.isDirectory() && !file.isHidden() && file.canRead() && filter.accept(file)) {
index(file);
} } return indexWriter.numDocs();
} /**
* 关闭写索引
*
* @throws IOException
*/
public void close() throws IOException {
indexWriter.close(); } /**
* 测试
* @param args
*/
public static void main(String[] args) { String indexDir="E:\\lucene\\index";
String dataDir="E:\\lucene\\data";
int indexFileCount=0;
Indexer indexer=null;
try {
indexer=new Indexer(indexDir);
long startTime=System.currentTimeMillis();
indexFileCount=indexer.CreateIndex(dataDir, new FileFilter());
long endTime=System.currentTimeMillis();
System.out.println("索引文件共花费:"+(endTime-startTime)+" 毫秒");
System.out.println("一共索引了"+indexFileCount+"个文件");
} catch (Exception e) {
e.printStackTrace();
}finally {
try {
indexer.close();
} catch (IOException e) {
e.printStackTrace();
}
} } }
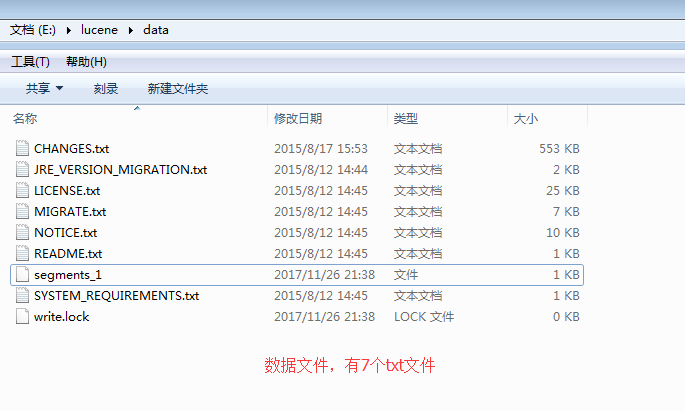
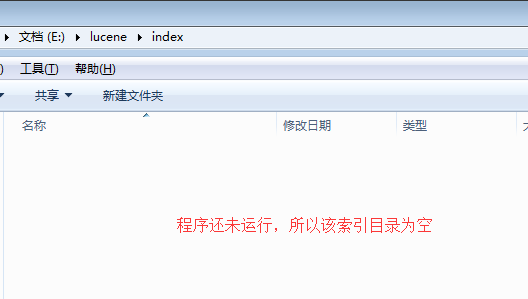
- 结果

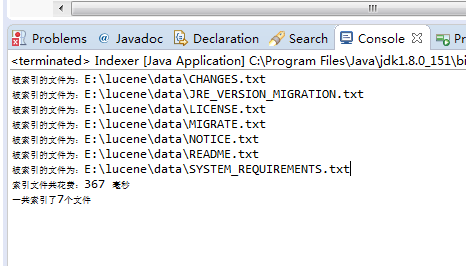
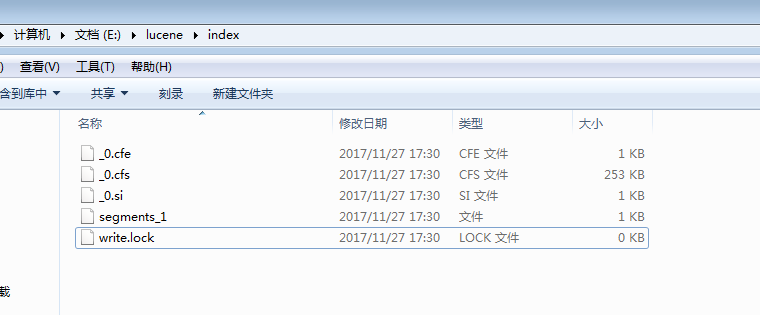
- 程序运行后,对data文件夹中的所有txt文件进行索引,生成的索引文件放于index文件夹中。
(一)Lucene简介以及索引demo的更多相关文章
- lucene简介 创建索引和搜索初步
lucene简介 创建索引和搜索初步 一.什么是Lucene? Lucene最初是由Doug Cutting开发的,2000年3月,发布第一个版本,是一个全文检索引擎的架构,提供了完整的查询引擎和索引 ...
- Lucene底层原理和优化经验分享(1)-Lucene简介和索引原理
Lucene底层原理和优化经验分享(1)-Lucene简介和索引原理 2017年01月04日 08:52:12 阅读数:18366 基于Lucene检索引擎我们开发了自己的全文检索系统,承担起后台PB ...
- 搜索引擎系列 ---lucene简介 创建索引和搜索初步
一.什么是Lucene? Lucene最初是由Doug Cutting开发的,2000年3月,发布第一个版本,是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎 :Lucene得名于Doug妻子 ...
- Lucene简介
1 lucene简介1.1 什么是lucene Lucene是一个全文搜索框架,而不是应用产品.因此它并不像www.baidu.com 或者google Desktop那么拿来就能用,它只是提供 ...
- 学习笔记(二)--Lucene简介
Lucene简介 最受欢迎的java开源全文搜索引擎开发工具包.提供了完整的查询引擎和索引引擎,部分文本分词引擎(英文与德文两种西方语言).Lucene的目的是为软件开发人员提供一个简单易用的工具包, ...
- 1.Lucene简介
1.Lucene简介 Lucene是一个基于Java的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能 Lucene是开源项目,它是可扩展,高性能的库用于索引和搜 ...
- Lucene教程(四) 索引的更新和删除
这篇文章是基于上一篇文章来写的,使用的是IndexUtil类,下面的例子不在贴出整个类的内容,只贴出具体的方法内容. 3.5版本: 先写了一个check()方法来查看索引文件的变化: /** ...
- Lucene的数值索引以及范围查询
对文本搜索引擎的倒排索引(数据结构和算法).评分系统.分词系统都清楚掌握之后,本人对数值索引和搜索一直有很大的兴趣,最近对Lucene对数值索引和范围搜索做了些学习,并将主要内容整理如下: 1. Lu ...
- lucene 简介和实践 分享
之前项目做了搜索的改造,使用lucene,公司内做了相关的技术分享,故先整理下ppt内容,后面会再把项目中的具体做法进行介绍 lucene 简介和实践 分享 搜索改造项目
随机推荐
- 开发WINDOWS服务程序
开发WINDOWS服务程序 开发步骤: 1.New->Other->Service Application 2.现在一个服务程序的框架已经搭起来了,打开Service1窗口,有几个属性说明 ...
- P5663 加工零件
P5663 加工零件 题解 暴力搜索 搜索显然会TLE #include<iostream> #include<cstdio> #include<cstdlib> ...
- VSCode 代码格式化 快捷键
Visual Studio Code可以通过以下快捷键 格式化代码: On Windows Shift + Alt + F On Mac Shift + Option + F On Ubuntu ...
- Matrix学习
package com.loaderman.customviewdemo; import android.app.Activity; import android.graphics.ColorMatr ...
- API的查看
步骤: 1. 双击打开API 2. 点击显示, 找到索引 3. 输入要查找的类名 , 敲击Enter两次 4. 看该类所属的包, java.lang包下的类,在使用的时候不需要导包 ,其他的都需要导包 ...
- Python 3.x 引入了函数注释
Python 3.x 引入了函数注释,以增强函数的注释功能,下面是一个普通的自定义函数: def dog(name, age, species): return (name, age, spe ...
- DTC & MSDTC (待研究)
相关学习文档: Database Systems: The Complete Book
- LeetCode_167. Two Sum II - Input array is sorted
167. Two Sum II - Input array is sorted Easy Given an array of integers that is already sorted in as ...
- Apache配置优化之开启GZip传输
1.确保apache已经编译的模块里有mod_deflate模块 2.确保apache的配置文件里引入了压缩的模块 3.确保要开启Gzip压缩的虚拟主机配置里有如下配置,并重启apache服务:如果要 ...
- redis列表和有序集合
redis中的list数据类型是可以插入重复数据的,有去重的需求的话可以用redis有序集合数据类型 Redis Zadd 命令用于将一个或多个成员元素及其分数值加入到有序集当中. 如果某个成员已经是 ...