基于熵的方法计算query与docs相似度
一.简单总结
其实相似度计算方法也是老生常谈,比如常用的有:
1.常规方法
a.编辑距离
b.Jaccard
c.余弦距离
d.曼哈顿距离
e.欧氏距离
f.皮尔逊相关系数
2.语义方法
a.LSA
b.Doc2Vec
c.DSSM
......
二.利用熵计算相似度
关于什么是熵、相对熵、交叉熵的概念,网上有很多,这里就不总结了。本篇主要关注工程方面,即怎么用代码实现,参考的论文来自《Content-based relevance estimation on the web using inter-document similarities》(2012-CIKM)。
利用熵计算query与文档相似度并排序的步骤分为召回和重排序,比如先从大规模文档中召回小部分子集再进行重排序。召回部分可以用一些简单的效率高的方法快速确定候选子集,再将这些子集进行重排序。本篇关注如何利用熵重排序相关文档。
召回后的排序公式如下:
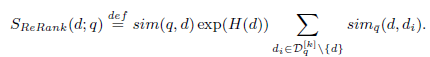
说明:
(1).H(d)表示文档d的熵
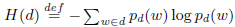
其中 =|w|/|d|,分子是词w个数,分母为文档d中的总词数
=|w|/|d|,分子是词w个数,分母为文档d中的总词数
(2).文档间的相似度

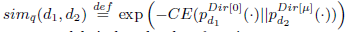
其中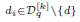 表示query的top-k个相关文档;利用交叉熵
表示query的top-k个相关文档;利用交叉熵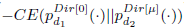 计算文档间的相似度,这里面的文档去除了query中的词。
计算文档间的相似度,这里面的文档去除了query中的词。
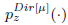 表示语言模型Dirichlet-smoothed,常见的平滑方法如下:
表示语言模型Dirichlet-smoothed,常见的平滑方法如下:

其中Dirichlet 方法:
a.首先计算最基本的最大的似然估计w|d 单词在单个文档出现的频率(有可能为0,所以就需要平滑,将所有f(w|d1), f(w|d2)....f(w|dn) 的所有频率加总
b.设定u值,根据实证研究: Dirichlet 方法的u值在100-200之间是最理想 ,但论文中给出的是1000,0为不使用平滑
c. 计算P(w|C)的概率
(3).sim(q,d)表示query与doc的相似度,可以使用其它方法计算,也可以使用如(2)中的方法计算
三.程序
完整程序https://github.com/jiangnanboy/entropy_sim
核心程序:
/**
* 结合交叉熵和狄里克雷平滑语言方法计算相关度
* @param queryTerms
* @return
*/
private Map<String, Double> queryDocScore(List<String> queryTerms) {
//统计查询中的词频
Map<String, Long> queryTermsCount = queryTerms
.stream()
.collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));
//查询中的总词频
long queryTermsSize = queryTermsCount
.values()
.stream()
.mapToLong(word -> word)
.sum(); //文档集中的词频
Map<String, Long> collectionTermsCount = corpusTerms
.stream()
.collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));
//文档集中的总词频
long collectionTermsSize = collectionTermsCount
.values()
.stream()
.mapToLong(word -> word)
.sum(); Map<String, Double> scoredDocument = new HashMap<>();
documentList.forEach(docTerms -> {
//文档中的词频
Map<String, Long> docTermsCount = docTerms
.stream()
.collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));
//文档中的总词频
long docTermsSize = docTermsCount
.values()
.stream()
.mapToLong(word -> word)
.sum(); //计算交叉熵(或者相对熵)
OptionalDouble score = queryTerms
.stream()
.mapToDouble(queryTerm -> {
//queryTerm的似然
double queryCE = (double)queryTermsCount.get(queryTerm) / queryTermsSize;
//经过Dirichlet smooth的term weight
double docCE = (1.0 + docTermsCount.getOrDefault(queryTerm, 0L) +
this.lambda * (collectionTermsCount.getOrDefault(queryTerm, 0L) / collectionTermsSize)) /
(docTermsSize + this.lambda);
return queryCE * Math.log(1 / docCE);//交叉熵
//return queryCE * Math.log(queryCE / docCE);//相对熵
})
.reduce(Double::sum);
String docID = corpusHashMap.get(docTerms);
scoredDocument.put(docID, Math.exp(-score.getAsDouble()));
});
return scoredDocument;
}
基于熵的方法计算query与docs相似度的更多相关文章
- 海量数据挖掘MMDS week2: 频繁项集挖掘 Apriori算法的改进:基于hash的方法
http://blog.csdn.net/pipisorry/article/details/48901217 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 基于神经网络的混合计算(DNC)-Hybrid computing using a NN with dynamic external memory
前言: DNC可以称为NTM的进一步发展,希望先看看这篇译文,关于NTM的译文:人工机器-NTM-Neutral Turing Machine 基于神经网络的混合计算 Hybrid computing ...
- 云知声 Atlas 超算平台: 基于 Fluid + Alluxio 的计算加速实践
Fluid 是云原生基金会 CNCF 下的云原生数据编排和加速项目,由南京大学.阿里云及 Alluxio 社区联合发起并开源.本文主要介绍云知声 Atlas 超算平台基于 Fluid + Alluxi ...
- 使用并行的方法计算斐波那契数列 (Fibonacci)
更新:我的同事Terry告诉我有一种矩阵运算的方式计算斐波那契数列,更适于并行.他还提供了利用TBB的parallel_reduce模板计算斐波那契数列的代码(在TBB示例代码的基础上修改得来,比原始 ...
- PDO 学习与使用 ( 一 ) :PDO 对象、exec 方法、query 方法与防 SQL 注入
1.安装 PDO 数据库抽象层 PDO - PHP Data Object 扩展类库为 PHP 访问数据库定义了一个轻量级的.一致性的接口,它提供了一个数据访问抽象层,针对不同的数据库服务器使用特定的 ...
- R与数据分析旧笔记(十六) 基于密度的方法:DBSCAN
基于密度的方法:DBSCAN 基于密度的方法:DBSCAN DBSCAN=Density-Based Spatial Clustering of Applications with Noise 本算法 ...
- 面试题:两种方法计算n!
直接上代码package com.face.test; public class Test { /** * 面试题:递归方法计算n! */ @org.junit.Test public void di ...
- 创建一个接口Shape,其中有抽象方法area,类Circle 、Rectangle实现area方法计算其面积并返回。又有Star实现Shape的area方法,其返回值是0,Star类另有一返回值boolean型方法isStar;在main方法里创建一个Vector,根据随机数的不同向其中加入Shape的不同子类对象(如是1,生成Circle对象;如是2,生成Rectangle对象;如是3,生成S
题目补充: 创建一个接口Shape,其中有抽象方法area,类Circle .Rectangle实现area方法计算其面积并返回. 又有Star实现Shape的area方法,其返回值是0,Star类另 ...
- Spark Mllib里决策树回归分析使用.rootMeanSquaredError方法计算出以RMSE来评估模型的准确率(图文详解)
不多说,直接上干货! Spark Mllib里决策树二元分类使用.areaUnderROC方法计算出以AUC来评估模型的准确率和决策树多元分类使用.precision方法以precision来评估模型 ...
随机推荐
- Java 抽象类详解
在<Java中的抽象方法和接口>中,介绍了抽象方法与接口,以及做了简单的比较. 这里我想详细探讨下抽象类. 一.抽象类的定义 被关键字“abstract”修饰的类,为抽象类.(而且,abx ...
- According to MySQL 5.5.45+, 5.6.26+ and 5.7.6+ requirements SSL connection must be established by de
MySQL在高版本需要指明是否进行SSL连接 spring.datasource.url=jdbc:mysql://127.0.0.1:3306/framework?characterEncoding ...
- Java Thread(线程)案例详解sleep和wait的区别
上次对Java Thread有了总体的概述与总结,当然大多都是理论上的,这次我将详解Thread中两个常用且容易疑惑的方法.并通过实例代码进行解疑... F区别 sleep()方法 sleep()使当 ...
- git diff 的简单使用(比较版本区别)
假如我们修改viewMail.vue 文件(部分代码) 从 //根据ID获取详情 getById () { let that = this; this.viewMailModal = true; th ...
- js之数据类型(对象类型——构造器对象——日期)
Date对象是js语言中内置的数据类型,用于提供日期与时间的相关操作.学习它之前我们先了解一下什么是GMT,什么时UTC等相关的知识. GMT: 格林尼治标准时间(Greenwich Mean Tim ...
- 搭建nginx环境
1.安装nginx 下载地址:http://nginx.org/en/download.html 博主选择的是nginx1.8.1,点击下载 下载完成后是一个压缩包, 解压后双击nginx.exe 这 ...
- 15.SpringMVC核心技术-数据验证
在 Web 应用程序中,为了防止客户端传来的数据引发程序的异常,常常需要对数据进行验证. 输入验证分为客户端验证与服务器端验证.客户端验证主要通过 JavaScript 脚本进 行, 而服务器端验证则 ...
- scp上传文件到远程服务器
scp -P 22 E:/download/2028792_www.yeves.cn_nginx/cloud.pem root@ip:/usr/local/src
- Swift Review总结一:从 Swift Style 开始
最近凑了几个热心的小伙伴写一些Swift的新手demo(两周后应该能和大家见面了),我参与了review.于是借demo里的代码总结一下新手写Swift要注意的问题,尤其是从oc转到用swift写的开 ...
- RHEL6进入救援模式
1.救援模式 救援模式作用: 更改root密码: 恢复硬盘.文件系统操作 系统无法启动时,通过救援模式启动 2.放入系统光盘,重启从光盘启动: 4.选择语言,默认English就行 5.保持默 ...