基于熵的方法计算query与docs相似度
一.简单总结
其实相似度计算方法也是老生常谈,比如常用的有:
1.常规方法
a.编辑距离
b.Jaccard
c.余弦距离
d.曼哈顿距离
e.欧氏距离
f.皮尔逊相关系数
2.语义方法
a.LSA
b.Doc2Vec
c.DSSM
......
二.利用熵计算相似度
关于什么是熵、相对熵、交叉熵的概念,网上有很多,这里就不总结了。本篇主要关注工程方面,即怎么用代码实现,参考的论文来自《Content-based relevance estimation on the web using inter-document similarities》(2012-CIKM)。
利用熵计算query与文档相似度并排序的步骤分为召回和重排序,比如先从大规模文档中召回小部分子集再进行重排序。召回部分可以用一些简单的效率高的方法快速确定候选子集,再将这些子集进行重排序。本篇关注如何利用熵重排序相关文档。
召回后的排序公式如下:
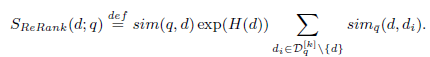
说明:
(1).H(d)表示文档d的熵
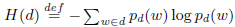
其中 =|w|/|d|,分子是词w个数,分母为文档d中的总词数
=|w|/|d|,分子是词w个数,分母为文档d中的总词数
(2).文档间的相似度

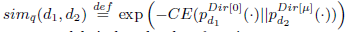
其中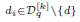 表示query的top-k个相关文档;利用交叉熵
表示query的top-k个相关文档;利用交叉熵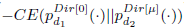 计算文档间的相似度,这里面的文档去除了query中的词。
计算文档间的相似度,这里面的文档去除了query中的词。
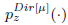 表示语言模型Dirichlet-smoothed,常见的平滑方法如下:
表示语言模型Dirichlet-smoothed,常见的平滑方法如下:

其中Dirichlet 方法:
a.首先计算最基本的最大的似然估计w|d 单词在单个文档出现的频率(有可能为0,所以就需要平滑,将所有f(w|d1), f(w|d2)....f(w|dn) 的所有频率加总
b.设定u值,根据实证研究: Dirichlet 方法的u值在100-200之间是最理想 ,但论文中给出的是1000,0为不使用平滑
c. 计算P(w|C)的概率
(3).sim(q,d)表示query与doc的相似度,可以使用其它方法计算,也可以使用如(2)中的方法计算
三.程序
完整程序https://github.com/jiangnanboy/entropy_sim
核心程序:
/**
* 结合交叉熵和狄里克雷平滑语言方法计算相关度
* @param queryTerms
* @return
*/
private Map<String, Double> queryDocScore(List<String> queryTerms) {
//统计查询中的词频
Map<String, Long> queryTermsCount = queryTerms
.stream()
.collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));
//查询中的总词频
long queryTermsSize = queryTermsCount
.values()
.stream()
.mapToLong(word -> word)
.sum(); //文档集中的词频
Map<String, Long> collectionTermsCount = corpusTerms
.stream()
.collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));
//文档集中的总词频
long collectionTermsSize = collectionTermsCount
.values()
.stream()
.mapToLong(word -> word)
.sum(); Map<String, Double> scoredDocument = new HashMap<>();
documentList.forEach(docTerms -> {
//文档中的词频
Map<String, Long> docTermsCount = docTerms
.stream()
.collect(Collectors.groupingBy(Function.identity(), Collectors.counting()));
//文档中的总词频
long docTermsSize = docTermsCount
.values()
.stream()
.mapToLong(word -> word)
.sum(); //计算交叉熵(或者相对熵)
OptionalDouble score = queryTerms
.stream()
.mapToDouble(queryTerm -> {
//queryTerm的似然
double queryCE = (double)queryTermsCount.get(queryTerm) / queryTermsSize;
//经过Dirichlet smooth的term weight
double docCE = (1.0 + docTermsCount.getOrDefault(queryTerm, 0L) +
this.lambda * (collectionTermsCount.getOrDefault(queryTerm, 0L) / collectionTermsSize)) /
(docTermsSize + this.lambda);
return queryCE * Math.log(1 / docCE);//交叉熵
//return queryCE * Math.log(queryCE / docCE);//相对熵
})
.reduce(Double::sum);
String docID = corpusHashMap.get(docTerms);
scoredDocument.put(docID, Math.exp(-score.getAsDouble()));
});
return scoredDocument;
}
基于熵的方法计算query与docs相似度的更多相关文章
- 海量数据挖掘MMDS week2: 频繁项集挖掘 Apriori算法的改进:基于hash的方法
http://blog.csdn.net/pipisorry/article/details/48901217 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- 基于神经网络的混合计算(DNC)-Hybrid computing using a NN with dynamic external memory
前言: DNC可以称为NTM的进一步发展,希望先看看这篇译文,关于NTM的译文:人工机器-NTM-Neutral Turing Machine 基于神经网络的混合计算 Hybrid computing ...
- 云知声 Atlas 超算平台: 基于 Fluid + Alluxio 的计算加速实践
Fluid 是云原生基金会 CNCF 下的云原生数据编排和加速项目,由南京大学.阿里云及 Alluxio 社区联合发起并开源.本文主要介绍云知声 Atlas 超算平台基于 Fluid + Alluxi ...
- 使用并行的方法计算斐波那契数列 (Fibonacci)
更新:我的同事Terry告诉我有一种矩阵运算的方式计算斐波那契数列,更适于并行.他还提供了利用TBB的parallel_reduce模板计算斐波那契数列的代码(在TBB示例代码的基础上修改得来,比原始 ...
- PDO 学习与使用 ( 一 ) :PDO 对象、exec 方法、query 方法与防 SQL 注入
1.安装 PDO 数据库抽象层 PDO - PHP Data Object 扩展类库为 PHP 访问数据库定义了一个轻量级的.一致性的接口,它提供了一个数据访问抽象层,针对不同的数据库服务器使用特定的 ...
- R与数据分析旧笔记(十六) 基于密度的方法:DBSCAN
基于密度的方法:DBSCAN 基于密度的方法:DBSCAN DBSCAN=Density-Based Spatial Clustering of Applications with Noise 本算法 ...
- 面试题:两种方法计算n!
直接上代码package com.face.test; public class Test { /** * 面试题:递归方法计算n! */ @org.junit.Test public void di ...
- 创建一个接口Shape,其中有抽象方法area,类Circle 、Rectangle实现area方法计算其面积并返回。又有Star实现Shape的area方法,其返回值是0,Star类另有一返回值boolean型方法isStar;在main方法里创建一个Vector,根据随机数的不同向其中加入Shape的不同子类对象(如是1,生成Circle对象;如是2,生成Rectangle对象;如是3,生成S
题目补充: 创建一个接口Shape,其中有抽象方法area,类Circle .Rectangle实现area方法计算其面积并返回. 又有Star实现Shape的area方法,其返回值是0,Star类另 ...
- Spark Mllib里决策树回归分析使用.rootMeanSquaredError方法计算出以RMSE来评估模型的准确率(图文详解)
不多说,直接上干货! Spark Mllib里决策树二元分类使用.areaUnderROC方法计算出以AUC来评估模型的准确率和决策树多元分类使用.precision方法以precision来评估模型 ...
随机推荐
- 第一章 MIZ701 VIVADO 搭建SOC最小系统HelloWorld
本章内容是MIZ701中的第五章,本来也是要过渡一下FPGA部分的,但是由于MIZ701没有单独提供PL部分的晶振时钟,时钟必须通过PS产生,所以本章内容作为Miz701的第一章内容.本章的目的是 ...
- k8s-jenkins pipeline部署
- 【GCN】图卷积网络初探——基于图(Graph)的傅里叶变换和卷积
[GCN]图卷积网络初探——基于图(Graph)的傅里叶变换和卷积 2018年11月29日 11:50:38 夏至夏至520 阅读数 5980更多 分类专栏: # MachineLearning ...
- php curl post请求
/** * CreateBy Song * @param String $url url地址 * @param Array $post url参数 * @return Array */ functio ...
- 几个主流浏览器 Window.open打开新窗口 、模拟a标签打开新窗口的 表现
Window.open打开新窗口 1.常用浏览器打开新窗口(正常打开window.open)的的不同表现形式(PC/移动端) 2.Window.open在异步处理中打开(_blank) a标签在异步处 ...
- MongoDB实战读书笔记(二):面向文档的数据
1 schema设计原则 1.1 关系型数据库的三大设计范式 第一范式(1NF)无重复的列 第二范式(2NF)属性完全依赖于主键 [ 消除部分子函数依赖 ] 第三范式(3NF)属性不依赖于其它非主属性 ...
- vue组件常用传值
一.使用Props传递数据 在父组件中使用儿子组件 <template> <div> 父组件:{{mny}} <Son1 :mny="mny"&g ...
- C++ STL 之 内建函数对象
STL 内建了一些函数对象.分为:算数类函数对象,关系运算类函数对象,逻辑运算类仿函数.这些仿函数所产生的对象,用法和一般函数完全相同,当然我们还可以产生无名的临时对象来履行函数功能.使用内建函数对象 ...
- K2 BPM_K2受邀出席SAP研讨会:共话“智能+”时代下的赋能与转型_全业务流程管理专家
3月5日,第十三届全国人大二次会议在北京召开.政府工作报告首次出现“智能+”,并明确指出2019年,要打造工业互联网平台,拓展“智能+”,为制造业转型升级赋能.从政府工作报告中不难看出,“智能+” ...
- python解决导入自定义库失败: ModuleNotFoundError: No module named 'MyLib'
python安装目录:...\python_3_6_1_64bit 新建文件:chenyeubai.pth,写入库所在的绝对路径E:\workSpace\my_code\learn\myLib 安装路 ...