【转】Spark History Server 架构原理介绍
【From】https://blog.csdn.net/u013332124/article/details/88350345
Spark History Server 是spark内置的一个http服务,通过sbin/sbin/start-history-server.sh启动。History Server启动后,会监听一个端口,同时启动两个定时任务线程,分别用来解析eventLog日志文件和清理过期的eventLog日志文件。
Spark History Server启动后,我们可以直接在浏览器输入 http://ip:port 访问。一般默认端口是18080
一、eventLog日志文件以及相关参数
eventLog日志文件介绍
eventLog需要将配置spark.eventLog.enabled设置为true来开启,默认是关闭的。
开启这个配置后,当我们提交spark job到集群中运行时,之后spark job在运行过程中会不断的一些运行信息写到相关的日志文件中。具体的eventLog存放目录由配置spark.eventLog.dir决定的。
Spark job在运行中,会调用EventLoggingListener#logEvent()来输出eventLog内容。spark代码中定义了各种类型的事件,一旦某个事件触发,就会构造一个类型的Event,然后获取相应的运行信息并设置进去,最终将该event对象序列化成json字符串,追加到eventLog日志文件中。
所以,eventLog日志文件是由一行一行的json串组成的,每一行json串都代表了一个事件。如下图:

在eventLog目录中,我们可以看到各个任务的eventLog日志文件

eventLog日志的文件名组成是APPID_ATTEMPTID,其中带.inprogress的表示该任务还在运行中。
相关配置参数
一般这些配置在放在spark-defaults.conf中
| 配置名称 | 默认值 | 备注 |
|---|---|---|
| spark.eventLog.enabled | false | 执行spark job时是否需要输出eventLog到指定目录,建议开启 |
| spark.eventLog.dir | /tmp/spark-events | eventLog输出的hdfs路径 |
| spark.history.fs.update.interval | 10s | history server每隔一段时间就会检查一下eventLog日志目录下的文件是否发生变动,然后进行解析或者更新。如果想要更及时的查看到任务的最新信息,这个时间可以设置的短一些,但太短的周期也会加重服务器的负担。 |
| spark.history.ui.maxApplication | intMaxValue | 限制web界面最多查询多少个任务信息。该值如果设置的太小,会导致webUI上看不到排在后面的一些任务。 |
| spark.history.ui.port | 18080 | history server监听端口 |
| spark.history.fs.cleaner.enabled | false | 是否开启过期eventLog日志清除,建议开启。否则eventLog就非常多 |
| spark.history.fs.cleaner.interval | 1d | eventLog日志清除线程执行的周期。规定每隔多久检查一次eventLog并清除过期的eventLog日志 |
| spark.history.fs.cleaner.maxAge | 7d | 规定eventLog的过期时间 |
| spark.eventLog.compress | false | 是否压缩eventLog日志文件。 |
| spark.history.retainedApplications | 50 | 在内存中缓存任务信息详情的个数,不建议设置的太大。后面就详细介绍这个缓存机制。 |
| spark.history.fs.numReplayThreads | ceil(cpu核数/4) | 解析eventLog的线程数量 |
二、两个定时任务
解析eventLog日志文件线程
该线程在FsHistoryProvider调用startPolling()方法时,通过以下代码启动:
pool.scheduleWithFixedDelay(getRunner(checkForLogs), 0, UPDATE_INTERVAL_S, TimeUnit.SECONDS)
从上面的代码可以看出,该线程每隔一段时间就会执行checkForLogs方法。这个时间间隔由配置spark.history.fs.update.interval决定,默认是10s执行一次。
该线程启动后,会扫描spark.eventLog.dir目录下的所有文件,根据过滤条件筛选出需要解析的eventLog日志文件列表,之后每一个eventLog日志文件都会开启一个线程去解析,这些线程会放到一个线程池中统一调度。该线程池的大小由spark.history.fs.numReplayThreads配置决定,默认会根据服务器的cpu核数动态调整,公式为 ceil(cpu核数/4)。
过滤eventLog日志的相关代码:
// scan for modified applications, replay and merge them
val logInfos: Seq[FileStatus] = statusList
.filter { entry =>
val prevFileSize = fileToAppInfo.get(entry.getPath()).map{_.fileSize}.getOrElse(0L)
!entry.isDirectory() &&
!entry.getPath().getName().startsWith(".") &&
prevFileSize < entry.getLen() &&
SparkHadoopUtil.get.checkAccessPermission(entry, FsAction.READ)
}
.flatMap { entry => Some(entry) }
.sortWith { case (entry1, entry2) =>
entry1.getModificationTime() >= entry2.getModificationTime()
}
注意,这里的解析并不会解析整个eventLog文件信息,只会获取application相关的一些基本信息,如下:
val attemptInfo = new FsApplicationAttemptInfo(
logPath.getName(),
appListener.appName.getOrElse(NOT_STARTED),
appListener.appId.getOrElse(logPath.getName()),
appListener.appAttemptId,
appListener.startTime.getOrElse(-1L),
appListener.endTime.getOrElse(-1L),
lastUpdated,
appListener.sparkUser.getOrElse(NOT_STARTED),
appCompleted,
fileStatus.getLen()
)
在所有的eventLog日志都解析成FsApplicationAttemptInfo后,这些信息都会被放到applications对象中。applications是一个LinkedHashMap[String, FsApplicationHistoryInfo]类型的Map。key是eventLog的路径。
清理过期的eventLog日志文件的线程
该线程在FsHistoryProvider调用startPolling()方法时,通过以下代码启动:
pool.scheduleWithFixedDelay(getRunner(cleanLogs), 0, CLEAN_INTERVAL_S, TimeUnit.SECONDS)
从上面的代码可以看出,该线程每隔一段时间就会执行cleanLogs方法。这个时间间隔由配置spark.history.fs.cleaner.interval决定,默认是1天执行一次。
该线程启动后,会遍历内存中applications对象的所有item,然后获取FsApplicationHistoryInfo.lastUpdated的值,根据spark.history.fs.cleaner.maxAge配置判断是否过期,如果过期了就准备删了对应的eventLog日志文件。(注意:这里遍历的对象是applications的item,而不是eventLog目录下的所有文件。另外,判断规则也不是获取eventLog日志文件的更新时间,而是FsApplicationHistoryInfo对象中的lastUpdated属性)
三、History Server的架构
History Server是基于内嵌的jetty来构建http服务的。
这里简单介绍一下jetty的架构,jetty架构的核心是Handler。一个请求过来时,会解析然后被封装成Request,之后会交给Server对象中的Handler处理。Server的Handler可以是各种各样类型的Handler,因为History Server里面注入的是ContextHandlerCollection,我们这里只介绍ContextHandlerCollection。这个类也是Handler的一个实现类,可以理解为是Handler的集合,持有一系列Handler对象,同时还能起到路由器的作用。ContextHandlerCollection基于ArrayTernaryTrie构造了一个字典树,用于快速匹配路径。当收到一个请求时,ContextHandlerCollection根据url找到对应的Handler,然后把请求交给这个Handler去处理。Handler里面封装了各种我们自己实现的Servlet,最终请求就落到了具体的那个Servlet上执行了。
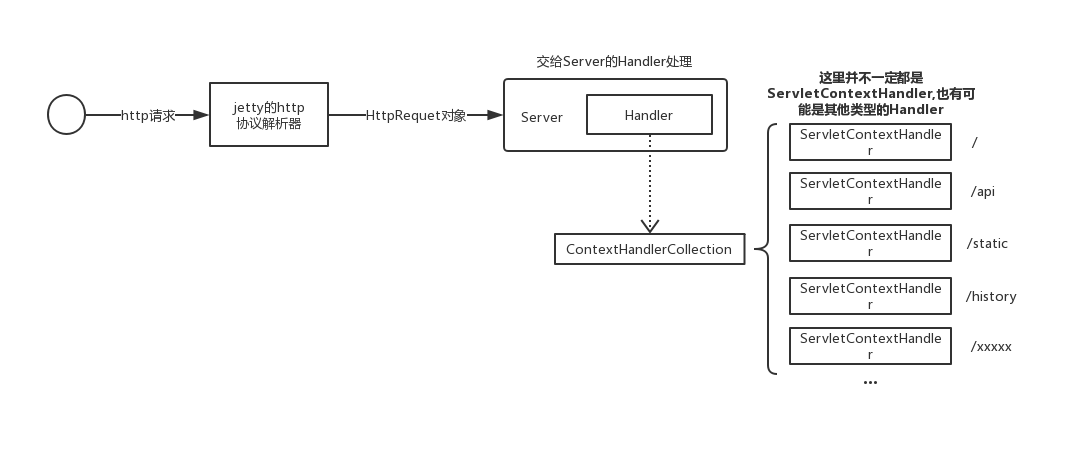
History Server在启动时,会往ContextHandlerCollection中加入一个ServletContextHandler,这里放着jersey的ServletContainer类,用来提供restful api。jersey会自动解析org.apache.spark.status.api.v1包下面的类,然后将对应的请求转发过去。
History Server启动时还会注册其他的handler,这里不多做介绍。
缓存机制
任务的applications信息是长期驻留在内存并不断更新的。当我们在页面点击查看某个任务的运行详情时,History Server就会重新去解析对应eventLog日志文件,这时就是解析整个eventLog文件了,然后将构建好的详情信息保存到缓存中。它的缓存使用了guava的CacheLoader,缓存的个数限制由配置spark.history.retainedApplications决定,在将任务信息放入缓存的同时,History Server还会提前构建好这个任务的各种状态的sparkUI(也就是web界面),并创建好ServletContextHandler,然后放到ContextHandlerCollection中去。
我们可以通过阿里的arthas来观察一下ContextHandlerCollection的变化情况:
服务刚启动时,就5个GzipHandler,他们的底层也都是ServletContextHandler。

随意在WebUI上点击查看某个任务的详情信息后,我们可以看到增加了20来个的handler,大多都是和这个任务相关的handler。

再点一个任务详情

通过缓存任务详情信息以及UI,用户就可以很快的查看任务的各种维度的运行信息以及相关界面。
四、一些潜在的问题
1. spark.history.retainedApplications 设置太大导致的OOM问题
由于每个任务的详情信息数据量都比较大,有的任务能达到G级别。spark.history.retainedApplications如果设置的过大,很可能会导致java堆内存空间放不下这些信息,最终导致OOM。建议维持在默认值50即可。
2. eventLog 日志文件过大导致的OOM问题
就算spark.history.retainedApplications设置的很小,但是有些时候任务产生的eventLog本身就很大,比如一个eventLog日志就达到10G。只要解析几个类似的eventLog并缓存,就可能造成OOM了。对于这种情况,我们可以通过修改spark的源码来解决,目前可以通过2个方面入手:
在eventLog解析线程过滤处加一个过滤条件,即eventLog文件大小大于100M的我们就过滤不处理。即过滤代码中加上entry.getLen()<104857600。
找出eventLog日志太大的原因,比如我们集群是由于Accumulator的信息过多,所以可以修改JsonProtocol#accumulablesToJson()方法,在spark job运行时不统计Accumulator的信息
3. History Server 突然不可用的问题
表现为history页面无数据,抓了一下包,发现所有的请求都被转发到首页对应的那个handler中去了。也就是所有的请求都返回了首页的html内容。比如在浏览器输入 “/xxxx/xxx/xxx/xx” 也被转发到了 “/”。归根究底就是jetty的路由问题。
经过观察,发现当ContextHandlerCollection中的handler到达一定数量,就会发生这种情况。一般当handler数量达到14000就可能导致jetty路由失效。
目前可以通过调小spark.history.retainedApplications来控制handler的数量,因为缓存一个任务的详情会增加23个handler,因此理论上将spark.history.retainedApplications控制在500以下都可以认为是安全的。
经测试,将spark.history.retainedApplications从1000调整到100后,不会发生类似问题。
目前还未找到jetty路由失效的真正原因。
————————————————
版权声明:本文为CSDN博主「疯狂哈丘」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/u013332124/article/details/88350345
【转】Spark History Server 架构原理介绍的更多相关文章
- Spark History Server配置使用
Spark history Server产生背景 以standalone运行模式为例,在运行Spark Application的时候,Spark会提供一个WEBUI列出应用程序的运行时信息:但该WEB ...
- Spark History Server产生背景
以standalone运行模式为例,在运行Spark Application的时候,Spark会提供一个WEBUI列出应用程序的运行时信息:但该WEBUI随着Application的完成(成功/失败) ...
- Spark history Server配置实用
Spark history Server产生背景 以standalone运行模式为例,在运行Spark Application的时候,Spark会提供一个WEBUI列出应用程序的运行时信息:但该WEB ...
- Spark学习笔记-使用Spark History Server
在运行Spark应用程序的时候,driver会提供一个webUI给出应用程序的运行信息,但是该webUI随着应用程序的完成而关闭端口,也就是 说,Spark应用程序运行完后,将无法查看应用程序的历史记 ...
- Spark集群之Spark history server额外配置
Note: driver在SparkContext使用stop()方法后才将完整的信息提交到指定的目录,如果不使用stop()方法,即使在指定目录中产生该应用程序的目录,history server ...
- spark history server
参考:http://blog.csdn.net/lsshlsw/article/details/44786575 为什么需要historyServer? 在运行Spark Application的时候 ...
- Spark history server 遇到的一些问题
最近学习Spark,看了一个视频,里面有提到启动spark后,一般都会启动Spark History Server.视频里把 spark.history.fs.logDirectory 设置成了Had ...
- 63、Spark Streaming:架构原理深度剖析
一.架构原理深度剖析 StreamingContext初始化时,会创建一些内部的关键组件,DStreamGraph,ReceiverTracker,JobGenerator,JobScheduler, ...
- Spark 学习笔记之 Spark history Server 搭建
在hdfs上建立文件夹/directory hadoop fs -mkdir /directory 进入conf目录 spark-env.sh 增加以下配置 export SPARK_HISTORY ...
随机推荐
- 热门前沿知识相关面试问题-android插件化面试问题讲解
插件化由来: 65536/64K[技术层面上]随着代码越来越大,业务逻辑越来繁杂,所以很容易达到一个65536的天花板,其65536指的是整个项目中的方法总数如果达到这个数量时则不无法创建新的方法了, ...
- SpringBoot对接收及返回Instant类型的处理(转)
一:处理post请求json中的Instant类型1.springboot中日期格式化配置: spring: jackson: date-format: yyyy-MM-dd HH:mm:ss tim ...
- 6 RESTful规范
https://www.cnblogs.com/alice-bj/p/9258121.html 1.什么是RESTful REST与技术无关,代表的是一种软件架构风格,REST是Representat ...
- android的ant编译打包
Android本身是支持ant打包项目的,并且SDK中自带一个build.xml文件. 通过该文件,可以对文件进行编译.打包.安装等.并且支持多种方式打包,如debug或者release. 一般的,可 ...
- codevs 1464 装箱问题 2 x
题目描述 Description 一个工厂制造的产品形状都是长方体,它们的高度都是h,长和宽都相等,一共有六个型号,他们的长宽分别为1*1, 2*2, 3*3 ...
- python中的位运算
目录 1.判断奇偶数 2.交换两个数 3.找出没有重复的数 4.3的n次方 5. 找出不大于N的最大的2的幂指数 1.判断奇偶数 如果把n以二进制形式展示的话,我们只需要判断最后一个二进制位是1还是0 ...
- 微信小程序“反编译”
https://www.jianshu.com/p/ad8f417219e9 https://segmentfault.com/a/1190000018592740?utm_source=tag-ne ...
- 22.Python赋值运算符(入门必读)
赋值运算符主要用来为变量(或常量)赋值,在使用时,既可以直接用基本赋值运算符“=”将右侧的值赋给左侧的变量,右侧也可以在进行某些运算后再赋值给左侧的变量. = 基本赋值运算符 Python 使用“=” ...
- python-matplotlib-1
Python图表绘制:matplotlib绘图库入门 matplotlib 简介 matplotlib 是python最著名的绘图库,它提供了一整套和matlab相似的命令API,十分适合交互式地行制 ...
- ZooKeeper的简述
一.简介 ZooKeeper是一个高性能,分布式的,开源分布式应用协调服务.它提供了简单原始的功能,分布式应用可以基于它实现更高级的服务,比如同步,集群管理,命名空间,配置维护等.ZooKeeper使 ...