zookeeper 随记
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务。
zookeeper的几种模式:
1、单点模式
2、分布式集群模式,节点运行在多台机器
3、单点多实例
在这里只介绍单点多实例安装。
下载jdk和zookeeper软件包 jdk-8u181-linux-x64.tar.gz,zookeeper-3.4.13.tar.gz。
jdk安装以及配置环境变量
1、安装zookeeper,解压
# tar zxvf /zookeeper-3.4..tar.gz -C /usr/local
# ln -s zookeeper-3.4.13 zookeeper
2、拷贝配置文件为zoo1.cfg
# cp zoo_sample.cfg zoo1.cfg
3、修改zoo1.cfg配置文件,修改端口为2182,修改对应的data数据目录,当然也可以添加日志目录,如果想自定义日志目录,可以在配置文件中加入:dataLogDir=路径,最下面添加服务器端口,有几个实例添加几个,记得修改对应的端口,然后拷贝该文件到zoo2.cfg,zoo3.cfg,修改对应的端口号和数据目录

4、创建myid
# echo 1 > data1/myid
# echo 2 > data2/myid
# echo 3 > data3/myid
5、分别启动实例
# zkServer.sh start zoo1.cfg
# zkServer.sh start zoo2.cfg
# zkServer.sh start zoo3.cfg
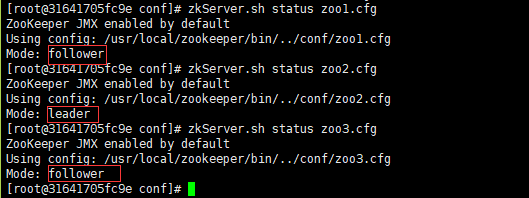
6、查看状态
# zkServer.sh status zoo1.cfg
# zkServer.sh status zoo2.cfg
# zkServer.sh status zoo3.cfg
7、获取mntr,conf的信息
# echo mntr | nc 192.168.4.50
# echo conf | nc 192.168.4.50
8、查看节点是否正常
# echo ruok|nc 192.168.4.50
9、进入zookeeper命令行
# ./bin/zkCli.sh -server 192.168.4.50:
10、列出zookeeper内容
ls /
11、创建新的znode
create /zk "yjt"
12、获取znode值
# get /zk
13、重新设置zk的值
set /zk "hello world!"
14、删除znode节点
# delete /zk
注:zookeeper原理理解链接:https://www.cnblogs.com/felixzh/p/5869212.html
zookeeper 随记的更多相关文章
- Kafka 基本知识分享
目录 一.基本术语 二.Kafka 基本命令 三.易混淆概念 四.Kafka的特性 五.Kafka的使用场景 六.Kakfa 的设计思想 七.Kafka 配置文件设置 八.新消费者 九.Kafka该怎 ...
- 记一次ZOOKEEPER集群超时问题分析
CDH安装的ZK,三个节点,基本都是默认配置,一直用得正常,今天出现问题,客户端连接超时6倍时长,默认最大会话超时时间是一分钟.原因分析:1.首先要确认网络正确.确认时钟同步.2.查看现有的配置,基本 ...
- 记一次zookeeper集群搭建错误的排除
zookeeper官网上的文档说得很清楚. http://zookeeper.apache.org/doc/r3.5.1-alpha/zookeeperAdmin.html#sc_designing ...
- 记一次zookeeper单机伪集群分布
zookeeper的各版本(历史版本)下载地址:http://apache.org/dist/zookeeper/ 环境>:linux 下载的zookeeper解压成3个
- 【ZooKeeper】ZooKeeper入门流水记
单机模式 下载zookeeper的包 wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.9/zookeeper-3.4.9.ta ...
- 记一次深坑,dubbo暴露的服务无法注册到zookeeper的原因
项目用的架构,springboot,dubbo,zookeeper dubbo的provider作为服务单独使用,里面的service实现类使用了@Transactional注解,想集成spring的 ...
- hadoop集群的各部分一般都会使用到多个端口,有些是daemon之间进行交互之用,有些是用于RPC访问以及HTTP访问。而随着hadoop周边组件的增多,完全记不住哪个端口对应哪个应用,特收集记录如此,以便查询。这里包含我们使用到的组件:HDFS, YARN, Hbase, Hive, ZooKeeper:
组件 节点 默认端口 配置 用途说明 HDFS DataNode 50010 dfs.datanode.address datanode服务端口,用于数据传输 HDFS DataNode 50075 ...
- Spark踩坑记——Spark Streaming+Kafka
[TOC] 前言 在WeTest舆情项目中,需要对每天千万级的游戏评论信息进行词频统计,在生产者一端,我们将数据按照每天的拉取时间存入了Kafka当中,而在消费者一端,我们利用了spark strea ...
- Spark踩坑记——数据库(Hbase+Mysql)
[TOC] 前言 在使用Spark Streaming的过程中对于计算产生结果的进行持久化时,我们往往需要操作数据库,去统计或者改变一些值.最近一个实时消费者处理任务,在使用spark streami ...
随机推荐
- .Dot NET Cored简介
一.诞生原因 1..Net平台封闭. 2.不支持跨平台. 3.受限于Windows平台性能,无法解决高性能场景. 二.优势 1.支持跨平台.开源.系统建设成本低. 2.效率和性能较好. 三.缺点 1. ...
- webstorm最新激活码2019----亲测可用
亲测日期:2019.12.10 网址里面有 lookdiv.com 里面的钥匙就是lookdiv.com
- 如何编写snort的检测规则
如何编写snort的检测规则 2013年09月08日 ⁄ 综合 ⁄ 共 16976字 前言 snort是一个强大的轻量级的网络入侵检测系统.它具有实时数据流量分析和日志IP网络数据包的能力,能够进行协 ...
- ABAP-JCO服务端连接问题
公司网络服务加域,若SAP服务器后端未配置端口号映射,则外部服务器注册JCO服务监听需要调整 # server jco.server.connection_count=5 jco.server.gwh ...
- CoAP协议
CoAP(Constrained Application Protocol) CoAP是6LowPAN协议栈中的应用层协议 CoAP是超轻量型协议 CoAP的默认UDP端口号为5683 1. 四种消息 ...
- javascript动态添加html节点
之前一直没怎么接触需要动态添加和删除html节点的项目,这次项目中用到了,也学习了. 在一个<table id="tab">标签中添加一个<tr id=" ...
- 解决 React Native:The development server returned response error code: 404
解决方法: 打开android/app/build.gradle compile 'com.facebook.react:react-native:+' 修改为: compile ("com ...
- linux防火墙扩展模块实战(二)
iptables扩展模块 扩展匹配条件:需要加载扩展模块(/usr/lib64/xtables/*.so),方可生效 查看帮助 man iptables-extensions (1)隐式扩展 ...
- unity之中级必备知识
Mask,Scroll Rect实现图拖拽:新建Imag,添加Mask,Scroll Rect组件:新建Image,托放在Scroll下的Content:新建Scroll Bar实现滚动条的同步:托放 ...
- 使用springboot和easypoi进行的数据导出的小案例
在这个案例中使用的有springboot和easypoi进行数据导出到excel中 yml文件是这样的: server: port: 8080 spring: datasource: url: jdb ...