hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析
hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析
Spark是一种快速、通用的计算集群系统,Spark提出的最主要抽象概念是弹性分布式数据集(RDD),它是一个元素集合,划分到集群的各个节点上,可以被并行操作。而Flink是可扩展的批处理和流式数据处理的数据处理平台。
Apache Flink,apache顶级项目,是一个高效、分布式、基于Java实现的通用大数据分析引擎,它具有分布式 MapReduce一类平台的高效性、灵活性和扩展性以及并行数据库查询优化方案,它支持批量和基于流的数据分析,且提供了基于Java,Python和Scala的API,跟Apache Spark非常类似,官网链接:https://flink.apache.org
Spark和Flink都支持实时计算,且都可基于内存计算(spark是伪实时的分片技术,只能按每秒分片技术,不能每条数据都实时技术,flink和storm可以)。Spark后面最重要的核心组件仍然是Spark SQL,而在未来几次发布中,除了性能上更加优化外(包括代码生成和快速Join操作),还要提供对SQL语句的扩展和更好地集成。至于Flink,其对于流式计算和迭代计算支持力度将会更加增强。无论是Spark、还是Flink的发展重点,将是数据科学和平台API化,除了传统的统计算法外,还包括学习算法,同时使其生态系统越来越完善。
Spark是一种快速、通用的计算集群系统,Spark提出的最主要抽象概念是弹性分布式数据集(RDD),它是一个元素集合,划分到集群的各个节点上,可以被并行操作。用户也可以让Spark保留一个RDD在内存中,使其能在并行操作中被有效的重复使用。Flink是可扩展的批处理和流式数据处理的数据处理平台,设计思想主要来源于Hadoop、MPP数据库、流式计算系统等,支持增量迭代计算。
1. 原理
Spark 1.4特点如下所示。
Spark为应用提供了REST API来获取各种信息,包括jobs、stages、tasks、storage info等。
Spark Streaming增加了UI,可以方便用户查看各种状态,另外与Kafka的融合也更加深度,加强了对Kinesis的支持。
Spark SQL(DataFrame)添加ORCFile类型支持,另外还支持所有的Hive metastore。
Spark ML/MLlib的ML pipelines愈加成熟,提供了更多的算法和工具。
Tungsten项目的持续优化,特别是内存管理、代码生成、垃圾回收等方面都有很多改进。
SparkR发布,更友好的R语法支持。

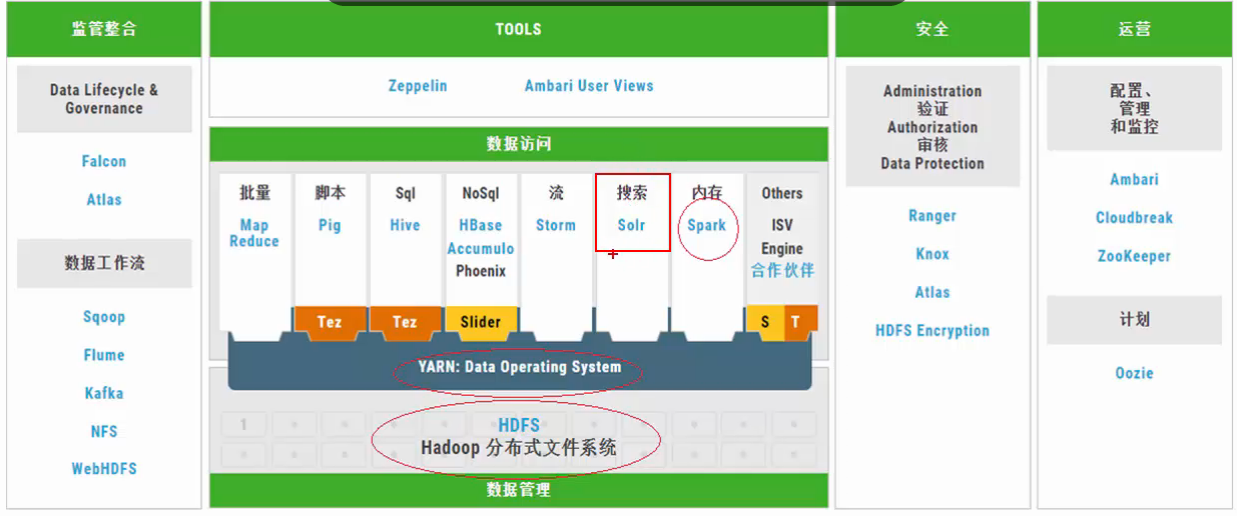
Spark架构图
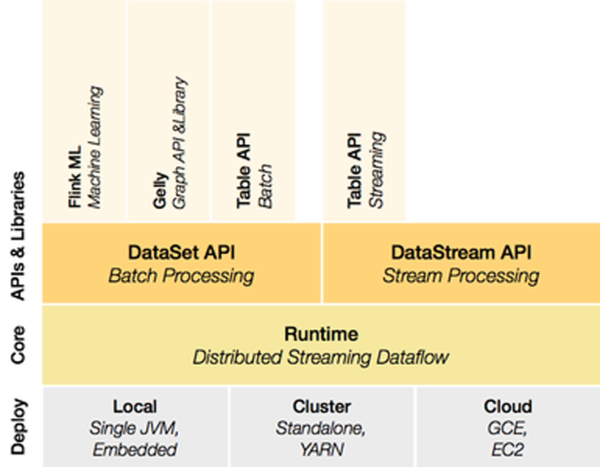
Flink架构图
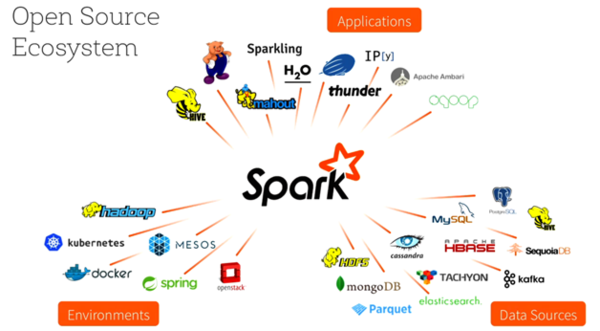
Spark生态系统图
Flink 0.9特点如下所示。
DataSet API 支持Java、Scala和Python。
DataStream API支持Java and Scala。
Table API支持类SQL。
有机器学习和图处理(Gelly)的各种库。
有自动优化迭代的功能,如有增量迭代。
支持高效序列化和反序列化,非常便利。
与Hadoop兼容性很好。
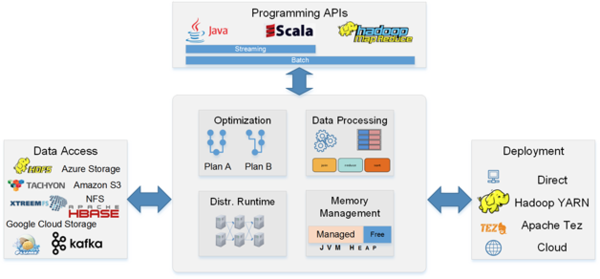
Flink生态系统图
2. 分析对比
2.1 性能对比
首先它们都可以基于内存计算框架进行实时计算,所以都拥有非常好的计算性能。经过测试,Flink计算性能上略好。
测试环境:
CPU:7000个;
内存:单机128GB;
版本:Hadoop 2.3.0,Spark 1.4,Flink 0.9
数据:800MB,8GB,8TB;
算法:K-means:以空间中K个点为中心进行聚类,对最靠近它们的对象归类。通过迭代的方法,逐次更新各聚类中心的值,直至得到最好的聚类结果。
迭代:K=10,3组数据

迭代次数(纵坐标是秒,横坐标是次数)
总结:Spark和Flink全部都运行在Hadoop YARN上,性能为Flink > Spark > Hadoop(MR),迭代次数越多越明显,性能上,Flink优于Spark和Hadoop最主要的原因是Flink支持增量迭代,具有对迭代自动优化的功能。
2.2 流式计算比较
它们都支持流式计算,Flink是一行一行处理,而Spark是基于数据片集合(RDD)进行小批量处理,所以Spark在流式处理方面,不可避免增加一些延时。Flink的流式计算跟Storm性能差不多,支持毫秒级计算,而Spark则只能支持秒级计算。
2.3 与Hadoop兼容
计算的资源调度都支持YARN的方式
数据存取都支持HDFS、HBase等数据源。
Flink对Hadoop有着更好的兼容,如可以支持原生HBase的TableMapper和TableReducer,唯一不足是现在只支持老版本的MapReduce方法,新版本的MapReduce方法无法得到支持,Spark则不支持TableMapper和TableReducer这些方法。
2.4 SQL支持
都支持,Spark对SQL的支持比Flink支持的范围要大一些,另外Spark支持对SQL的优化,而Flink支持主要是对API级的优化。
2.5 计算迭代
delta-iterations,这是Flink特有的,在迭代中可以显著减少计算,Hadoop(MR)、Spark和Flink的迭代流程:
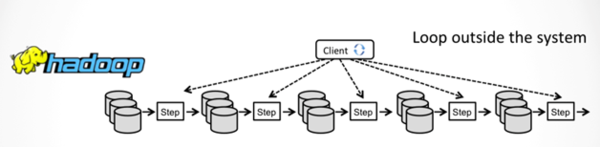
Hadoop(MR)迭代流程
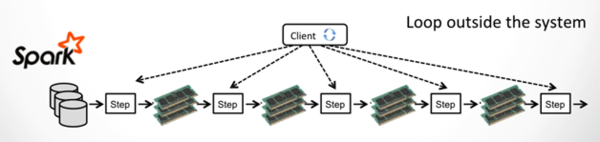
Spark迭代流程

Flink迭代流程
Flink自动优化迭代程序具体流程如图所示。
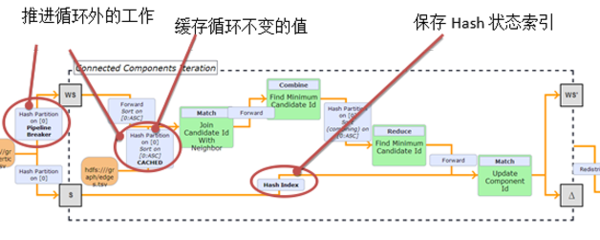
Flink自动优化迭代程序具体流程
2.6 社区支持
Spark社区活跃度比Flink高很多。
hadoop之Spark强有力竞争者Flink,Spark与Flink:对比与分析的更多相关文章
- 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink
转自:https://www.cnblogs.com/reed/p/7730329.html 今天看到一篇讲得比较清晰的框架对比,这几个框架的选择对于初学分布式运算的人来说确实有点迷茫,相信看完这篇文 ...
- 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink——flink支持SQL,待看
简介 大数据是收集.整理.处理大容量数据集,并从中获得见解所需的非传统战略和技术的总称.虽然处理数据所需的计算能力或存储容量早已超过一台计算机的上限,但这种计算类型的普遍性.规模,以及价值在最近几年才 ...
- 数据框架对比:Hadoop、Storm、Samza、Spark和Flink——flink支持SQL,待看
简介 大数据是收集.整理.处理大容量数据集,并从中获得见解所需的非传统战略和技术的总称.虽然处理数据所需的计算能力或存储容量早已超过一台计算机的上限,但这种计算类型的普遍性.规模,以及价值在最近几年才 ...
- Spark与Flink大数据处理引擎对比分析!
大数据技术正飞速地发展着,催生出一代又一代快速便捷的大数据处理引擎,无论是Hadoop.Storm,还是后来的Spark.Flink.然而,毕竟没有哪一个框架可以完全支持所有的应用场景,也就说明不可能 ...
- 一站式Flink&Spark平台解决方案——StreamX
大家好,我是独孤风.今天为大家推荐的是一个完全开源的项目StreamX.该项目的发起者Ben也是我的好朋友. ****什么是StreamX,StreamX 是Flink & Spark极速开发 ...
- 大数据框架对比:Hadoop、Storm、Samza、Spark和Flink--容错机制(ACK,RDD,基于log和状态快照),消息处理at least once,exactly once两个是关键
分布式流处理是对无边界数据集进行连续不断的处理.聚合和分析.它跟MapReduce一样是一种通用计算,但我们期望延迟在毫秒或者秒级别.这类系统一般采用有向无环图(DAG). DAG是任务链的图形化表示 ...
- 大数据常见端口汇总-hadoop、hbase、hive、spark、kafka、zookeeper等(持续更新)
常见端口汇总:Hadoop: 50070:HDFS WEB UI端口 8020 : 高可用的HDFS RPC端口 9000 : 非高可用的HDFS RPC端口 8088 ...
- 大数据相关技术原理资料整理(hdfs, spark, hbase, kafka, zookeeper, redis, hive, flink, k8s, OpenTSDB, InfluxDB, yarn)
hdfs: hdfs官方文档 深入理解HDFS的架构和原理 https://blog.csdn.net/kezhong_wxl/article/details/76573901 HDFS原理解析(总体 ...
- 教你成为全栈工程师(Full Stack Developer) 四十五-一文读懂hadoop、hbase、hive、spark分布式系统架构
转载自http://www.shareditor.com/blogshow?blogId=96 机器学习.数据挖掘等各种大数据处理都离不开各种开源分布式系统,hadoop用于分布式存储和map-red ...
随机推荐
- Ext中解析字符串
Ext.encode()将json转为json字符串Ext.decode()将json字符串转为json
- Unofficial Windows Binaries for Python Extension Packages
http://www.lfd.uci.edu/~gohlke/pythonlibs/#numpy
- vc2010 win32 控制台应用程序中文乱码
vc2010 win32 控制台应用程序中文乱码 在 vc2010 上用 win32 控制台程序写些测试代码调用 windows api ,处理错误信息时,发现用 wprintf 输出的错误信息出现了 ...
- Android各个版本 版本号对应关系表
Platform Version API Level VERSION_CODE Notes Android 5.0 21 LOLLIPOP Platform Highlights Android 4. ...
- Java 线程池的介绍以及工作原理
在什么情况下使用线程池? 1.单个任务处理的时间比较短 2.将需处理的任务的数量大 使用线程池的好处: 1. 降低资源消耗: 通过重复利用已创建的线程降低线程创建和销毁造成的消耗.2. 提高响应速度: ...
- 《30天自制操作系统》11_day_学习笔记
harib08a: 鼠标的显示问题:我们可以看到,鼠标移到窗口最右侧之后就不能再移动了,而WIN中,鼠标是可以移动到最右边隐藏起来的.怎么办?把鼠标指针显示的范围扩宽就行!我们来修改一下HariMai ...
- PostgreSQL 三节点集群故障模拟及恢复
PostgreSQL 三节点集群故障模拟及恢复 (postgreSQL9.5.1) 正常状态: 10.2.208.10:node1:master 10.2.208.11:node2:standby1同 ...
- sublime text 快速补全
sublime text 快速补全 关于补全,其实有很多,记录一些常用的在这里,忘记了可以查找 nav>ul>li <nav> <ul> ...
- 在数组中搜索数据用 filteredArrayUsingPredicate
苹果官方说明文档:https://developer.apple.com/library/mac/documentation/Cocoa/Conceptual/Predicates/Articles/ ...
- 构造方法特点,void
构造方法特点: 1.和类有相同的名字 2.无返回值 3.被默认强制void void作用:====>>说明声明的方法没有返回值 构造方法作用: -->初始化实例属性 -->用于 ...