爬虫之Xpath案例
案例:使用XPath的爬虫
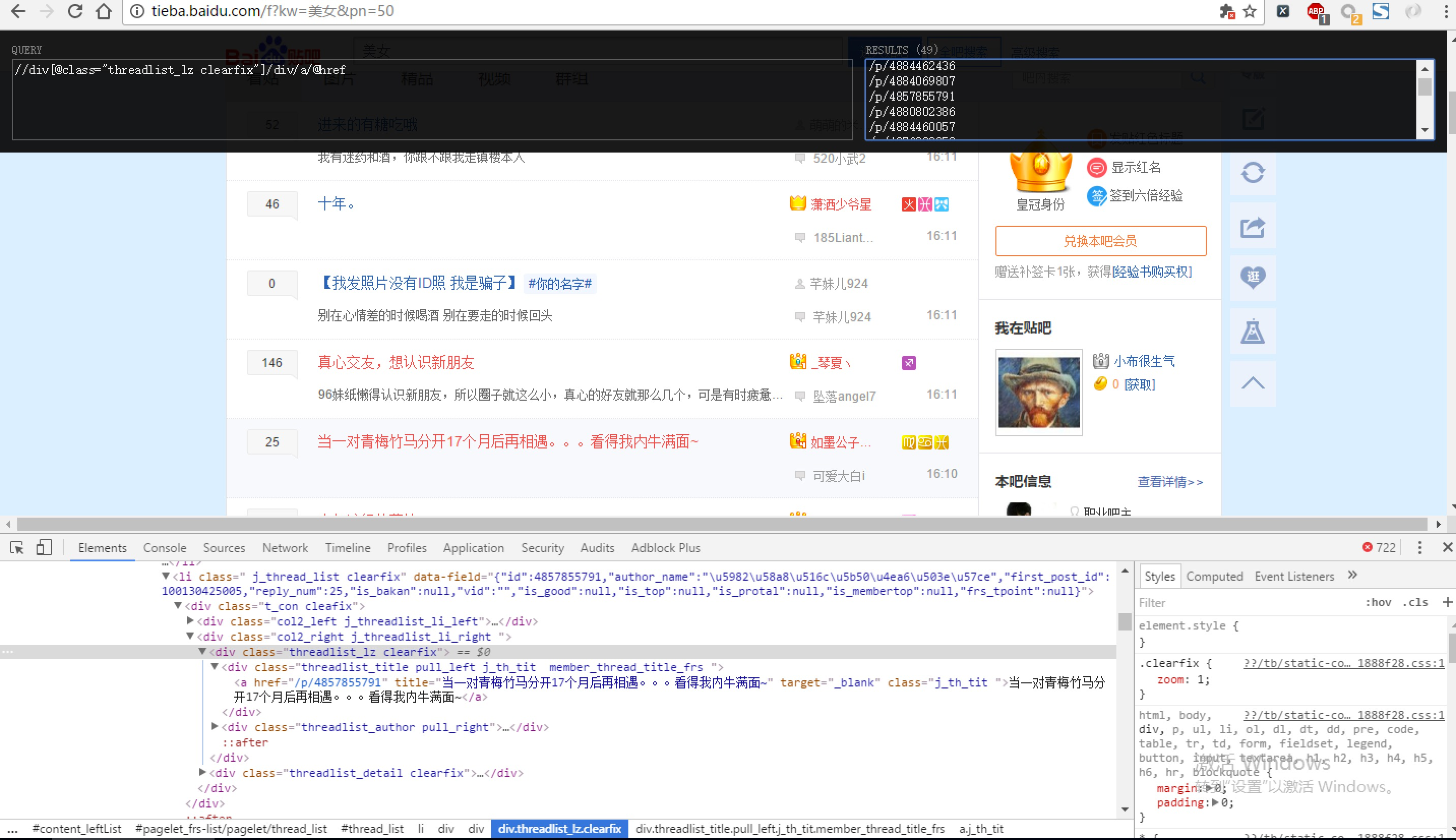
现在我们用XPath来做一个简单的爬虫,我们尝试爬取某个贴吧里的所有帖子,并且将该这个帖子里每个楼层发布的图片下载到本地。
# tieba_xpath.py
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import os
import urllib
import urllib2
from lxml import etree
class Spider:
def __init__(self):
self.tiebaName = raw_input("请需要访问的贴吧:")
self.beginPage = int(raw_input("请输入起始页:"))
self.endPage = int(raw_input("请输入终止页:"))
self.url = 'http://tieba.baidu.com/f'
self.ua_header = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1 Trident/5.0;"}
# 图片编号
self.userName = 1
def tiebaSpider(self):
for page in range(self.beginPage, self.endPage + 1):
pn = (page - 1) * 50 # page number
word = {'pn' : pn, 'kw': self.tiebaName}
word = urllib.urlencode(word) #转换成url编码格式(字符串)
myUrl = self.url + "?" + word
# 示例:http://tieba.baidu.com/f? kw=%E7%BE%8E%E5%A5%B3 & pn=50
# 调用 页面处理函数 load_Page
# 并且获取页面所有帖子链接,
links = self.loadPage(myUrl) # urllib2_test3.py
# 读取页面内容
def loadPage(self, url):
req = urllib2.Request(url, headers = self.ua_header)
html = urllib2.urlopen(req).read()
# 解析html 为 HTML 文档
selector=etree.HTML(html)
#抓取当前页面的所有帖子的url的后半部分,也就是帖子编号
# http://tieba.baidu.com/p/4884069807里的 “p/4884069807”
links = selector.xpath('//div[@class="threadlist_lz clearfix"]/div/a/@href')
# links 类型为 etreeElementString 列表
# 遍历列表,并且合并成一个帖子地址,调用 图片处理函数 loadImage
for link in links:
link = "http://tieba.baidu.com" + link
self.loadImages(link)
# 获取图片
def loadImages(self, link):
req = urllib2.Request(link, headers = self.ua_header)
html = urllib2.urlopen(req).read()
selector = etree.HTML(html)
# 获取这个帖子里所有图片的src路径
imagesLinks = selector.xpath('//img[@class="BDE_Image"]/@src')
# 依次取出图片路径,下载保存
for imagesLink in imagesLinks:
self.writeImages(imagesLink)
# 保存页面内容
def writeImages(self, imagesLink):
'''
将 images 里的二进制内容存入到 userNname 文件中
'''
print imagesLink
print "正在存储文件 %d ..." % self.userName
# 1. 打开文件,返回一个文件对象
file = open('./images/' + str(self.userName) + '.png', 'wb')
# 2. 获取图片里的内容
images = urllib2.urlopen(imagesLink).read()
# 3. 调用文件对象write() 方法,将page_html的内容写入到文件里
file.write(images)
# 4. 最后关闭文件
file.close()
# 计数器自增1
self.userName += 1
# 模拟 main 函数
if __name__ == "__main__":
# 首先创建爬虫对象
mySpider = Spider()
# 调用爬虫对象的方法,开始工作
mySpider.tiebaSpider()
爬虫之Xpath案例的更多相关文章
- Python爬虫之xpath语法及案例使用
Python爬虫之xpath语法及案例使用 ---- 钢铁侠的知识库 2022.08.15 我们在写Python爬虫时,经常需要对网页提取信息,如果用传统正则表达去写会增加很多工作量,此时需要一种对数 ...
- 爬虫常用Xpath和CSS3选择器对比
爬虫常用Xpath和CSS3选择器对比 1. 简介 CSS是来配合HTML工作的,和Xpath对比起来,CSS选择器通常都比较短小,但是功能不够强大.CSS中的空白符' '和Xpath的'//'都表示 ...
- 中国爬虫违法违规案例汇总github项目介绍
中国爬虫违法违规案例汇总github项目介绍 GitHub - 本项目用来整理所有中国大陆爬虫开发者涉诉与违规相关的新闻.资料与法律法规.致力于帮助在中国大陆工作的爬虫行业从业者了解我国相关法律,避免 ...
- python爬虫:XPath语法和使用示例
python爬虫:XPath语法和使用示例 XPath(XML Path Language)是一门在XML文档中查找信息的语言,可以用来在XML文档中对元素和属性进行遍历. 选取节点 XPath使用路 ...
- 非常全的一份Python爬虫的Xpath博文
非常全的一份Python爬虫的Xpath博文 Xpath 是 python 爬虫过程中非常重要的一个用来定位的一种语法. 一.开始使用 首先我们需要得到一个 HTML 源代码,用来模拟爬取网页中的源代 ...
- Python爬虫(十三)_案例:使用XPath的爬虫
本篇是使用XPath的案例,更多内容请参考:Python学习指南 案例:使用XPath的爬虫 现在我们用XPath来做一个简单的爬虫,我们尝试爬取某个贴吧里的所有帖子且将该帖子里每个楼层发布的图片下载 ...
- 爬虫神器xpath的用法(三)
xpath的多线程爬虫 #encoding=utf-8 ''' pool = Pool(4) cpu的核数为4核 results = pool.map(爬取函数,网址列表) ''' from mult ...
- 爬虫神器XPath,程序员带你免费获取周星驰等明星热门电影
本教程由"做全栈攻城狮"原创首发,本人大学生一枚平时还需要上课,但尽量每日更新文章教程.一方面把我所习得的知识分享出来,希望能对初学者有所帮助.另一方面总结自己所学,以备以后查看. ...
- 互联网金融爬虫怎么写-第一课 p2p网贷爬虫(XPath入门)
版权声明:本文为博主原创文章,未经博主允许不得转载. 相关教程: 手把手教你写电商爬虫-第一课 找个软柿子捏捏 手把手教你写电商爬虫-第二课 实战尚妆网分页商品采集爬虫 手把手教你写电商爬虫-第三课 ...
随机推荐
- vue中回车键登录
created() { let that = this; document.onkeypress = function(e) { var keycode = document.all ? event. ...
- EasyUI 的常见标签
1. Resizable 属性 原理: 页面加载完毕后,EasyUI主文件会扫描页面上的每个标签,判断这些标签的class值是否以"easyui-"开头, 如果是,则拿到之后的部分 ...
- python 简单的文件下载
需要使用urllib2库 import urllib2def download(url, szFileName = ""): #szFileName:下载文件到的目标路径 if s ...
- sipp模拟freepbx分机测试(SIP协议调试)
1.sipp的安装 1) 在centos 7.2下安装 yum install make gcc gcc-c++ ncurses ncurses.x86_64 ncurses-devel ncurse ...
- 揭秘DOM中data和nodeValue属性同步改变那些事
问题引发:最近在整理DOM系列的一些知识点,发现在DOM的某些接口API中,存在一些我想不通的现象.就随便举个例子吧:DOM文档模型中的文本节点,可以通过nodeValue或data属性访问文本节点的 ...
- supervisor配置与应用
1.简介 supervisor 是一款基于Python的进程管理工具,可以很方便的管理服务器上部署的应用程序.supervisor的功能如下: a. 启动.重启.关闭包括但不限于python进程. b ...
- python logging模块介绍
1.日志级别 日志一共分成5个等级,从低到高分别是:DEBUG INFO WARNING ERROR CRITICAL. DEBUG:详细的信息,通常只出现在诊断问题上 INFO:确认一切按预期运行 ...
- Python数据库连接池实例——PooledDB
不用连接池的MySQL连接方法 import MySQLdb conn= MySQLdb.connect(host='localhost',user='root',passwd='pwd',db='m ...
- 最长上升子序列算法(n^2 及 nlogn) (LIS) POJ2533Longest Ordered Subsequence
问题描述: 一个数的序列bi,当b1 < b2 < ... < bS的时候,我们称这个序列是上升的.对于给定的一个序列(a1, a2, ..., aN),我们可以得到一些上升的子序列 ...
- HDU1520:Anniversary party(树形dp第一发)
题目:http://acm.hdu.edu.cn/showproblem.php?pid=1520 一个公司去参加宴会,要求去的人不能有直接领导关系,给出每一个人的欢乐值,和L K代表K是L的直接领导 ...