Hadoop 学习笔记 (九) hadoop2.2.0 生产环境部署 HDFS HA部署方法
step1:将安装包hadoop-2.2.0.tar.gz存放到某一个目录下,并解压
step2:修改解压后的目录中的文件夹/etc/hadoop下的xml配置文件(如果文件不存在,则自己创建)
包括hadoop-env.sh mapred-site.xml core-site.xml hdfs-site.xml yarn-site.xml
step3:格式化并启动hdfs
step4:启动yarn
注意事项:
1,主备NameNode有多种配置方法,本课程使用JournalNode方式。为此需要至少准备3个节点作为JournalNode,这三个
节点可与其他服务,比如NodeManager(slave节点上有)公用节点
2,主备两个NameNode应位于不同机器上,这两台机器不要再部署其他服务,即他们分别独享一台机器(注:HDFS2.0中无需再部署
和配置SecondaryName,备NameNode已经替代它完成了相应的功能)(那为什么单机版的中会有secondarynamenode因为单机版的hadoop2.0兼容1.0的模式,可以用)
3,主备NameNode之间有两种切换方式:手动切换和自动切换,其中,自动切换时借助zookeeper实现的,因此,需单独部署一个zookeeper
集群(通常为奇数个节点,至少3个)。本课程使用手动切换方式 接下来介绍:
1 HDFS HA部署方法
2 HDFS HA + Federation部署方法
3 Yarn部署方法 第一种:HDFS HA 部署方法
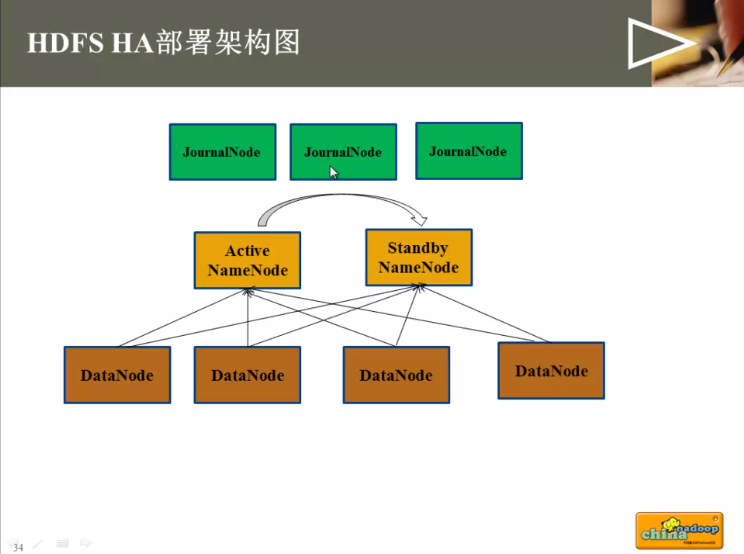
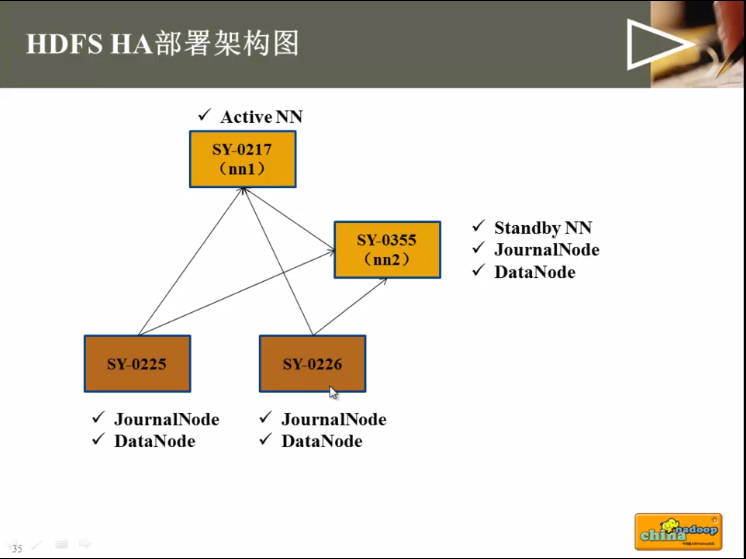
部署家构图:
journalnode需要资源很少,所以可以跟datanode共享。dfs.namenode.name.dir : NameNode fsiamge存放目录(元数据)---------- 可配置多个,一个可能不太可靠
dfs.namenode.shared.edits.dir : 主备NameNode同步元信息的共享存储系统 -------- 三个journal node地址
dfs.journalnode.edits.dir : Journal Node 数据存放目录
看个实际的例子:
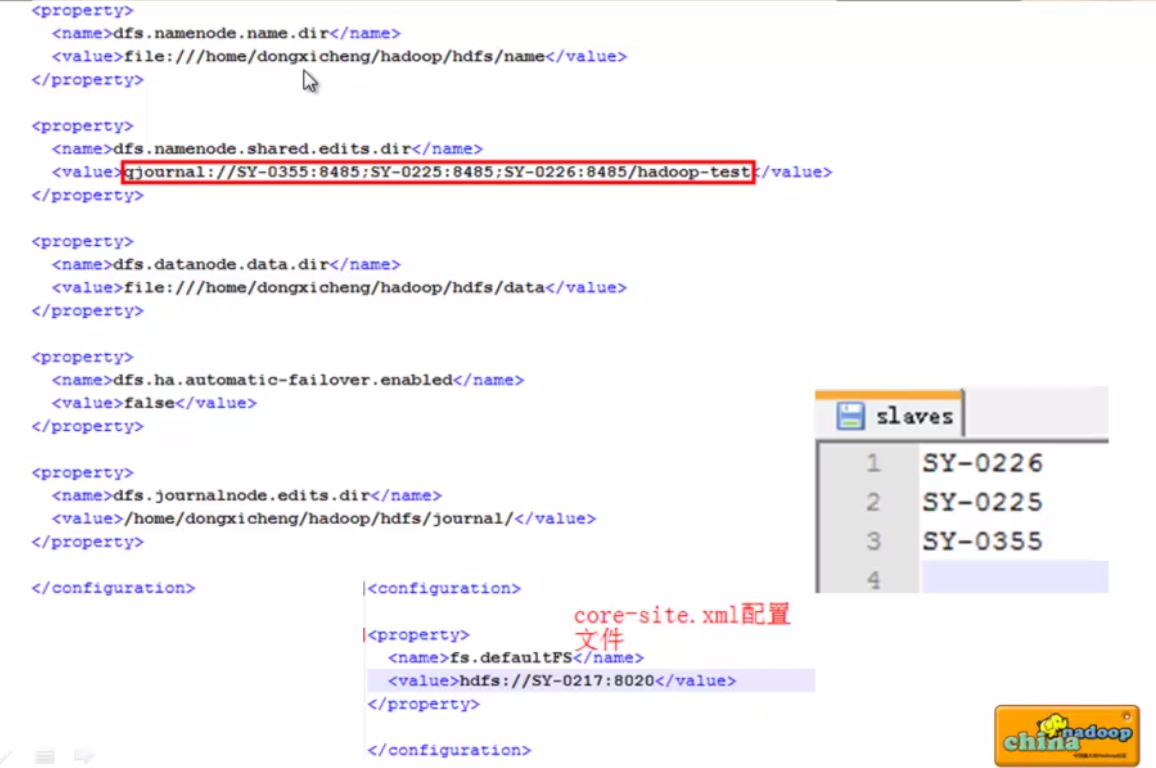
core-site.xml说明:
fs.defaultFS 如果是自动切换这里会是逻辑地址,因为如果自动切换,那这里还要改名字很麻烦,所以自动切换的时候这里会切换成逻辑地址
HDFS-HA 部署流程-启动/关闭HDFSstep1:在各个节点上,启动Journalnode服务
sbin/hadoop-daemon.sh start journal
step2:在[nn1]上,对其进行格式化,并启动
bin/hdfs namenode -format
sbin/hadoop-daemon.sh start namenode
step3:在[nn2]上,同步[nn1]的元数据信息(含格式化过程)
bin/hdfs namenode -bootstrapStandby
step4:在[nn2]上,启动NameNode:
sbin/hadoop-daemon.sh start namenode
经过以上4步,nn1和nn2均处于standby状态
step5:在[nn1]上,将NameNode切换为Active
bin/hdfs haamin -transitionToActive nn1
step6:在[nn1]上,启动所有datanode
sbin/hadoop-daemon[s].sh start datanode
关闭hadoop集群:
在nn1上:sbin/stop-dfs.sh
如何验证:50070(active)50070 standby
Hadoop 学习笔记 (九) hadoop2.2.0 生产环境部署 HDFS HA部署方法的更多相关文章
- Hadoop学习笔记—22.Hadoop2.x环境搭建与配置
自从2015年花了2个多月时间把Hadoop1.x的学习教程学习了一遍,对Hadoop这个神奇的小象有了一个初步的了解,还对每次学习的内容进行了总结,也形成了我的一个博文系列<Hadoop学习笔 ...
- Hadoop学习笔记—2.不怕故障的海量存储:HDFS基础入门
一.HDFS出现的背景 随着社会的进步,需要处理数据量越来越多,在一个操作系统管辖的范围存不下了,那么就分配到更多的操作系统管理的磁盘中,但是却不方便管理和维护—>因此,迫切需要一种系统来管理多 ...
- Hadoop 学习笔记 (十) hadoop2.2.0 生产环境部署 HDFS HA Federation 含Yarn部署
其他的配置跟HDFS-HA部署方式完全一样.但JournalNOde的配置不一样>hadoop-cluster1中的nn1和nn2和hadoop-cluster2中的nn3和nn4可以公用同样的 ...
- Hadoop学习笔记—21.Hadoop2的改进内容简介
Hadoop2相比较于Hadoop1.x来说,HDFS的架构与MapReduce的都有较大的变化,且速度上和可用性上都有了很大的提高,Hadoop2中有两个重要的变更: (1)HDFS的NameNod ...
- hadoop学习笔记(五):java api 操作hdfs
HDFS的Java访问接口 1)org.apache.hadoop.fs.FileSystem 是一个通用的文件系统API,提供了不同文件系统的统一访问方式. 2)org.apache.hadoop. ...
- [读书笔记]C#学习笔记五: C#3.0自动属性,匿名属性及扩展方法
前言 这一章算是看这本书最大的收获了, Lambda表达式让人用着屡试不爽, C#3.0可谓颠覆了我们的代码编写风格. 因为Lambda所需篇幅挺大, 所以先总结C#3.0智能编译器给我们带来的诸多好 ...
- C#学习笔记四: C#3.0自动属性&匿名属性及扩展方法
前言 这一章算是看这本书最大的收获了, Lambda表达式让人用着屡试不爽, C#3.0可谓颠覆了我们的代码编写风格. 因为Lambda所需篇幅挺大, 所以先总结C#3.0智能编译器给我们带来的诸多好 ...
- hadoop学习笔记-目录
以下是hadoop学习笔记的顺序: hadoop学习笔记(一):概念和组成 hadoop学习笔记(二):centos7三节点安装hadoop2.7.0 hadoop学习笔记(三):hdfs体系结构和读 ...
- hadoop学习笔记(二):centos7三节点安装hadoop2.7.0
环境win7+vamvare10+centos7 一.新建三台centos7 64位的虚拟机 master node1 node2 二.关闭三台虚拟机的防火墙,在每台虚拟机里面执行: systemct ...
随机推荐
- park、unpark、ord 函数使用方法(转)
park,unpark,ord这3个函数,在我们工作中,用到它们的估计不多. 我在最近一个工作中,因为通讯需要用到二进制流,然后接口用php接收.当时在处理时候,查阅不少资料.因为它们使用确实比较少, ...
- 局域网内使用linux的ntp服务
假设我们的饿局域网无法连接外网,但又需要同步时间,怎么办? 1. 已局域网内的一台机器作为基础,适用date修改其他机器的时间,date -s ...,很不方便,这里不介绍. 2. 适用ntp服务,自 ...
- [转]allocWithZone 和 单例模式
一.问题起源 一切起源于Apple官方文档里面关于单例(Singleton)的示范代码:Creating a Singleton Instance. 主要的争议集中在下面这一段: ? 1 2 3 4 ...
- NDK开发之日志打印
要在NDK中打印日志,只需要以下三步: 一.在Android.mk中添加以下内容: LOCAL_LDLIBS := -lm -llog 或者 LOCAL_LDLIBS:=-L$(SYSROOT)/us ...
- nginx同时监听本机ipv4/ipv6端口
修改nginx.conf配置文件 server { listen ; listen [::]:; } 0.0.0.0 表示本机所有ipv4地址,需要监听特定地址替换即可 [::] 表示本机所有ip ...
- minicom移植到ARM开发平台
minicom需要ncurses库的支持.arm-linux-gcc中并没有此库故需要交叉编译ncurses,否则出现很多头文件.库函数找不到. 软件环境: ncurses-6.0 下载网址:http ...
- Linq扩展方法之All 、Any
// Summary: // 确定序列中的所有元素是否满足条件. // Parameters: // source:包含要应用谓词的元素的 System.Collections.Generic.IEn ...
- 借鉴网上的winform模仿QQ窗口停靠功能稍作改动
2015-07-11 15:24:04 1 using System; using System.Collections.Generic; using System.ComponentModel; u ...
- HDU-1012(水题)
http://acm.hdu.edu.cn/showproblem.php?pid=1012 分析:就按题目给的公式一步步输出就行了. #include<stdio.h> #include ...
- TransactionScope简单用法
记录TransactionScope简单用法,示例如下: void Test() { using (TransactionScope scope = new TransactionScope()) { ...