2 weekend110的hadoop的自定义排序实现 + mr程序中自定义分组的实现
我想得到按流量来排序,而且还是倒序,怎么达到实现呢?
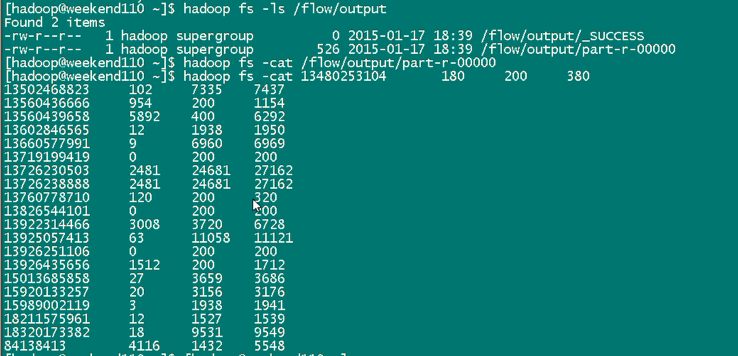
达到下面这种效果,
默认是根据key来排,
我想根据value里的某个排,
解决思路:将value里的某个,放到key里去,然后来排
下面,开始weekend110的hadoop的自定义排序实现
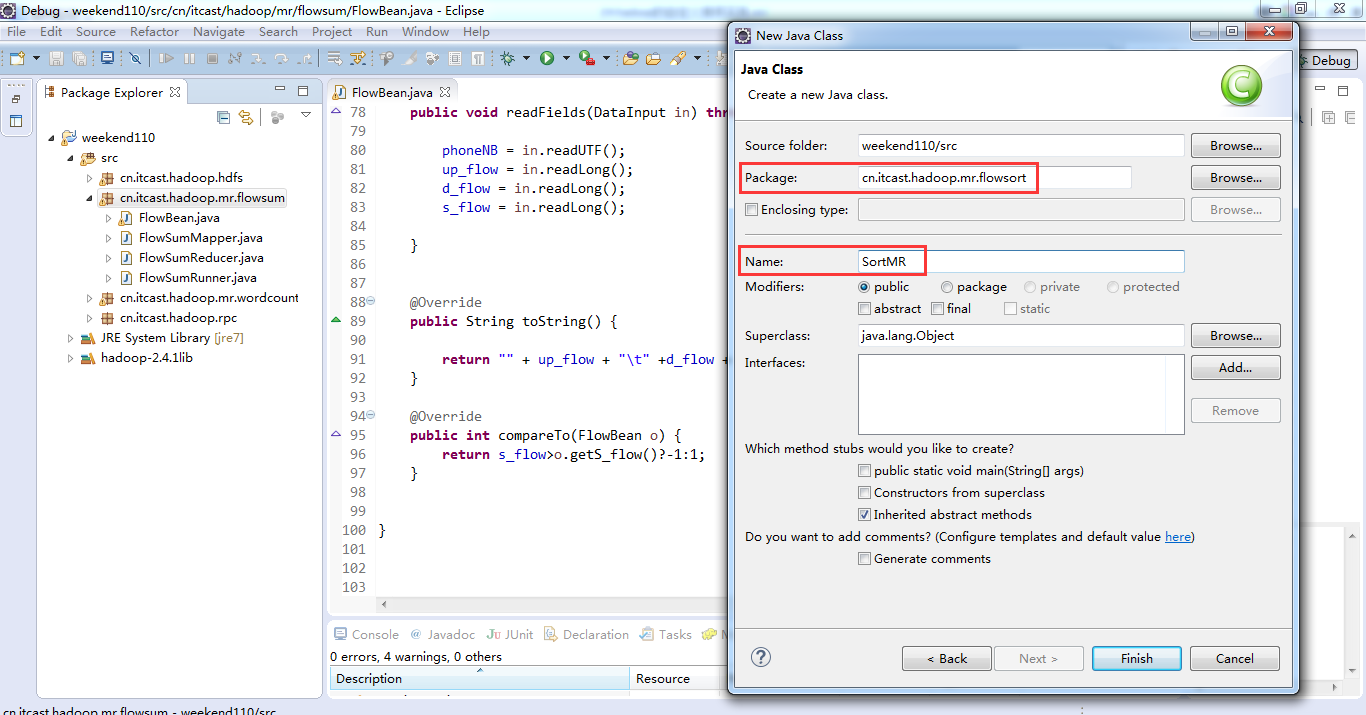
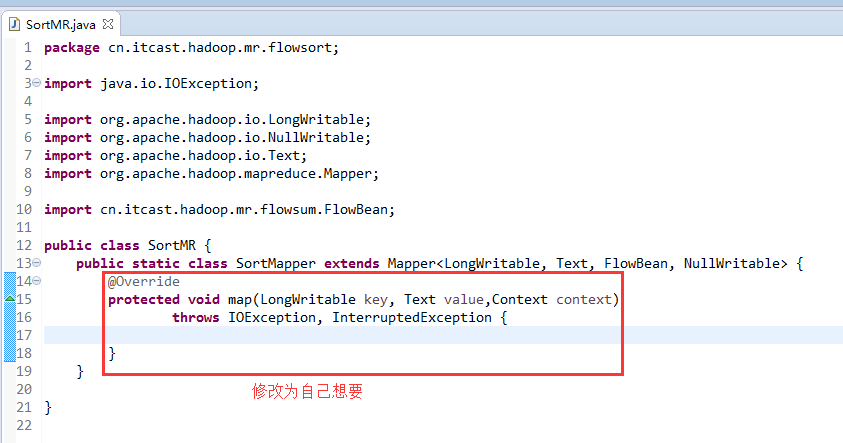
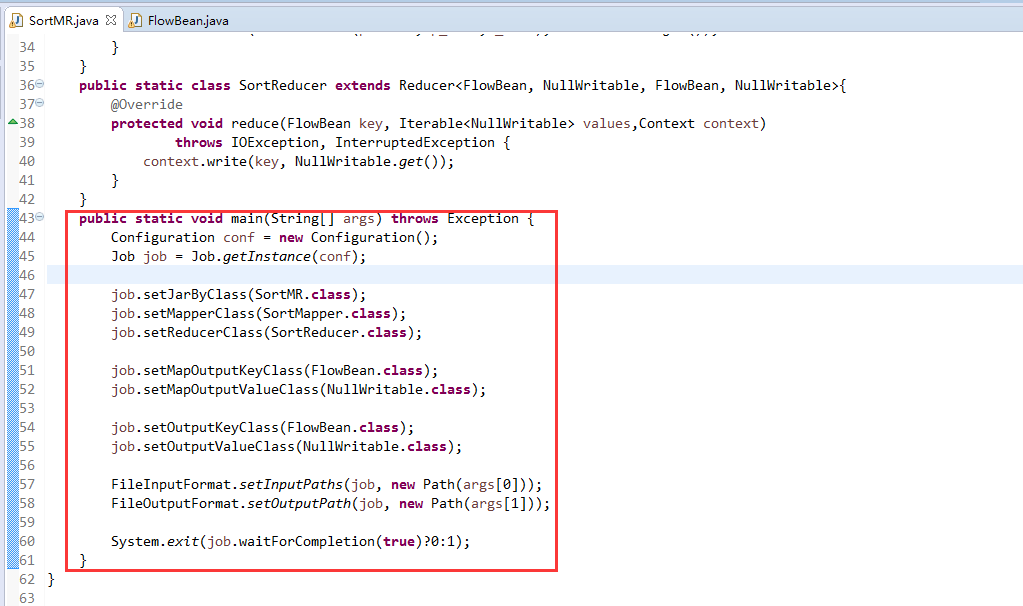
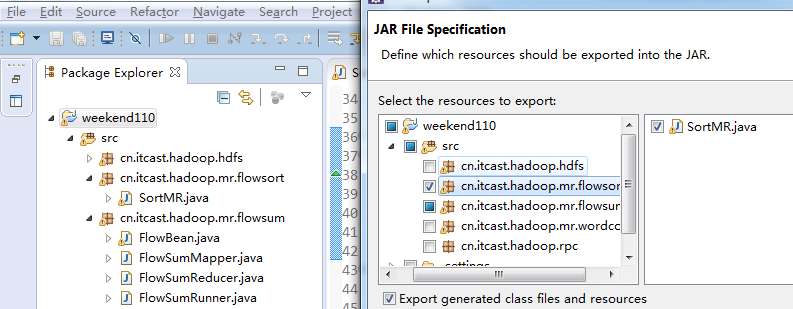
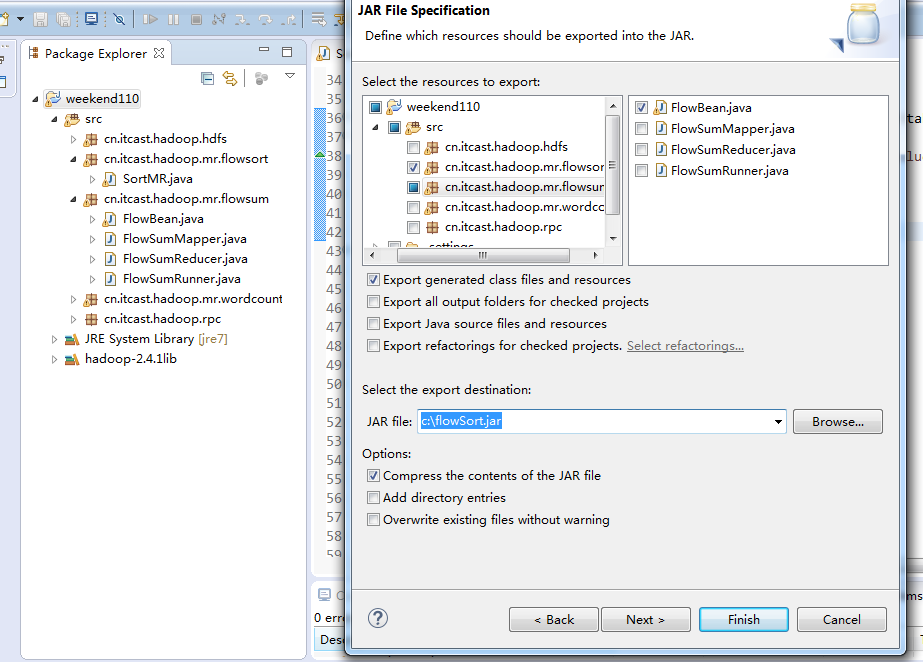
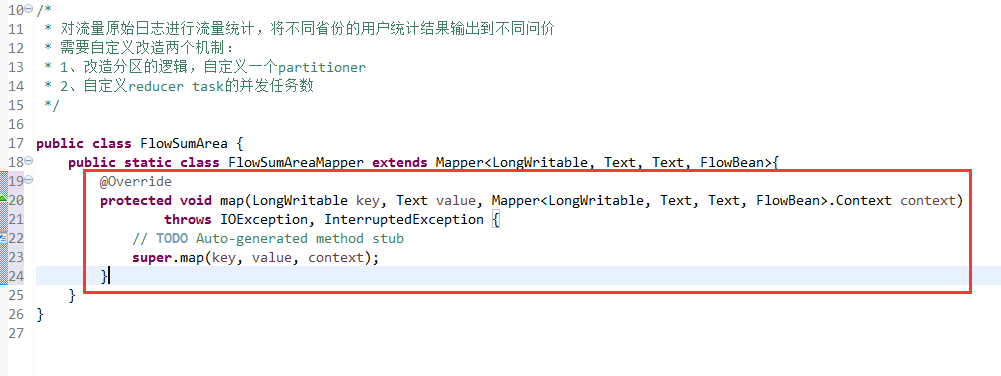
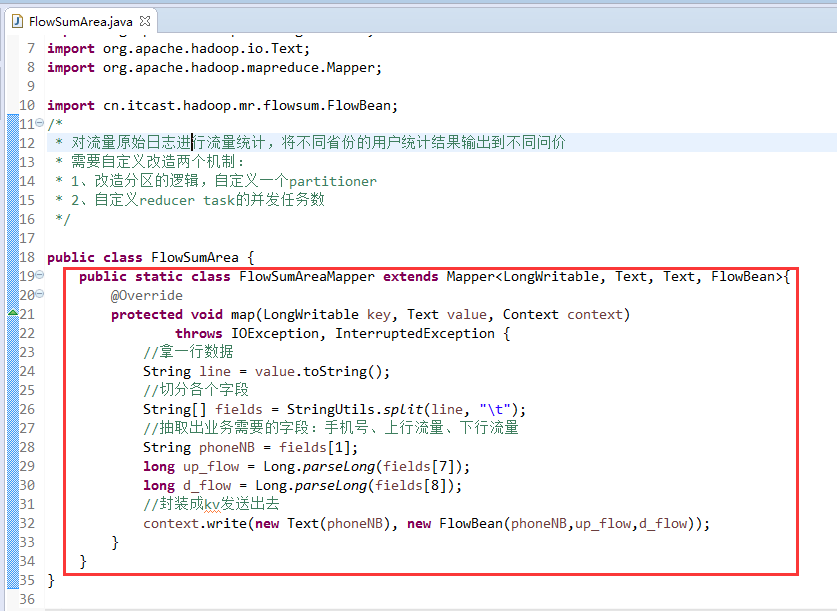
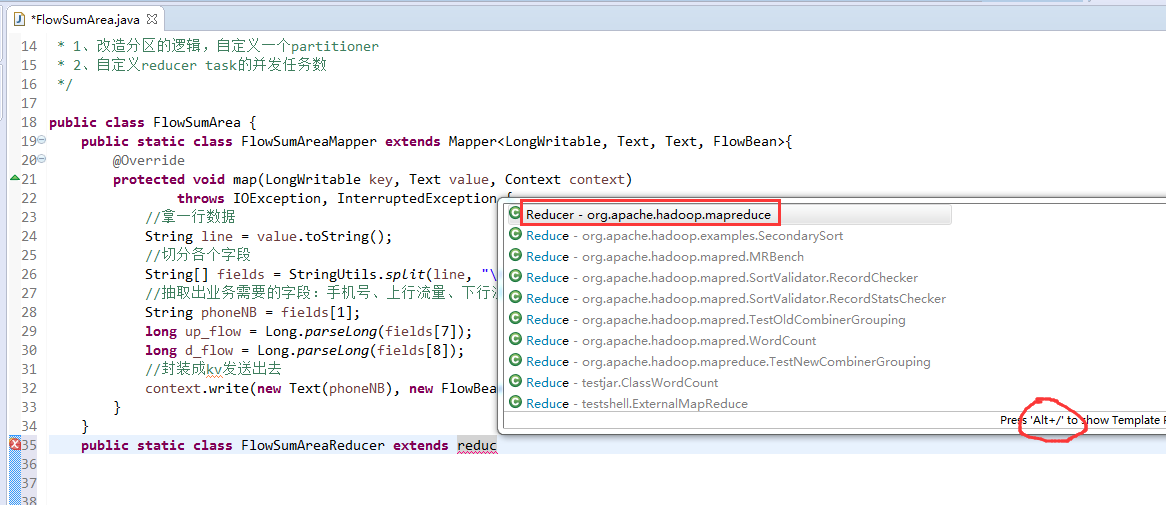
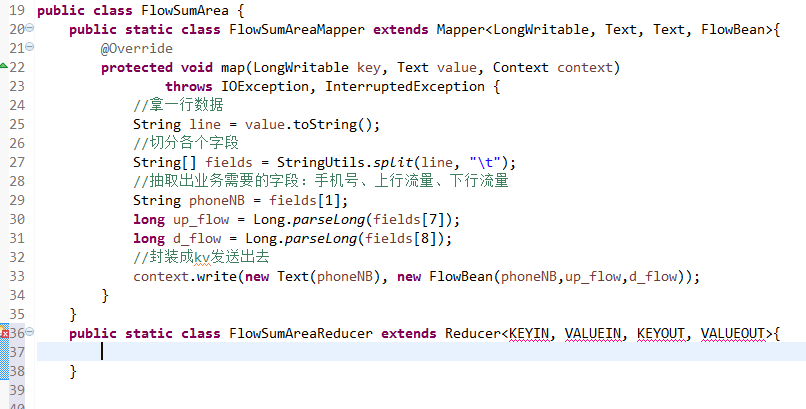
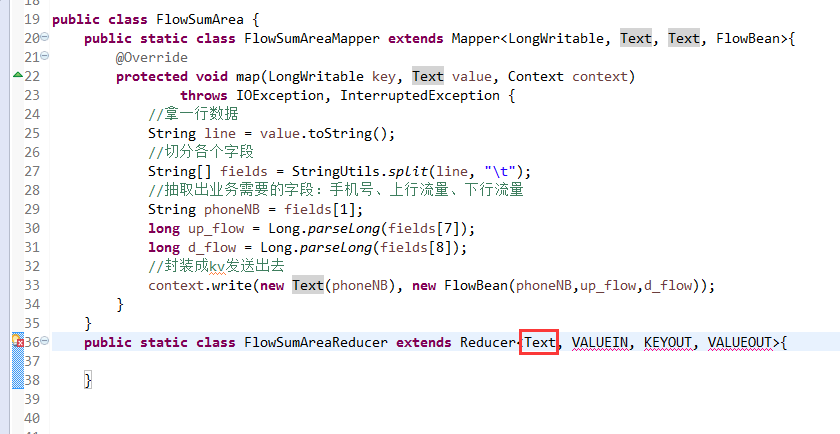
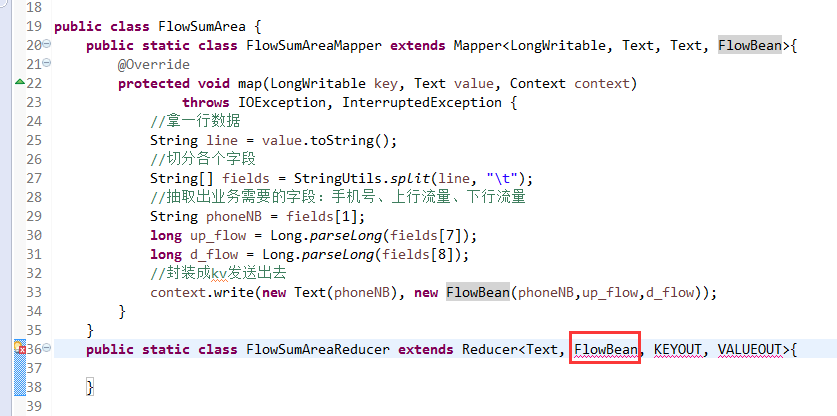
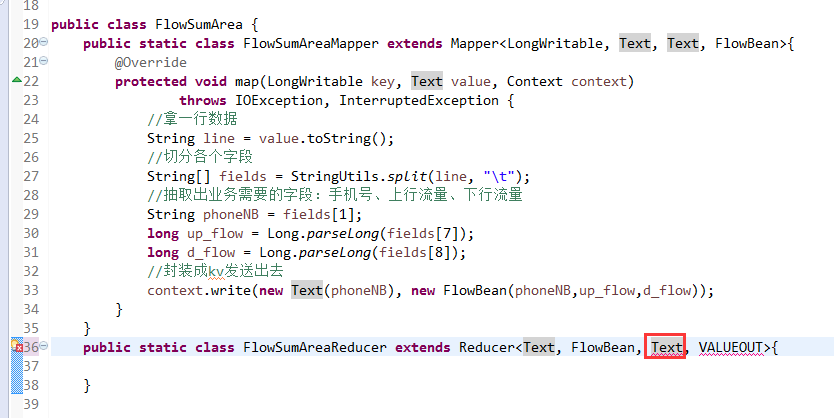
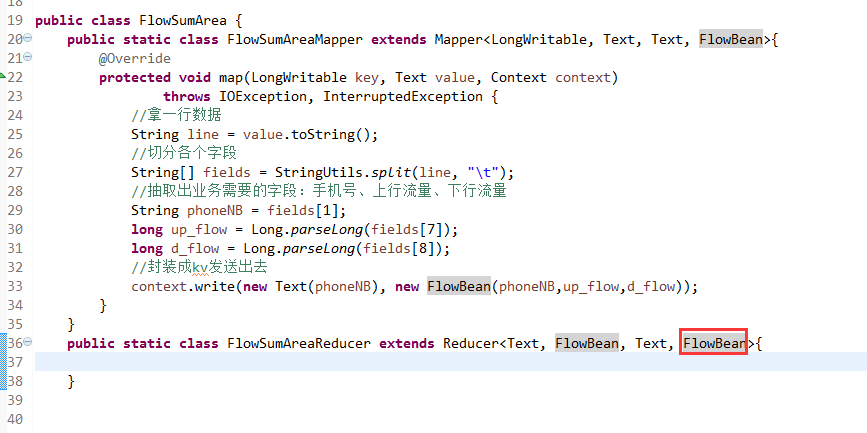
将FlowSortMapper、FlowSortReduce、FlowSortRunner、FlowSortBean,全放到一个SortMR里。
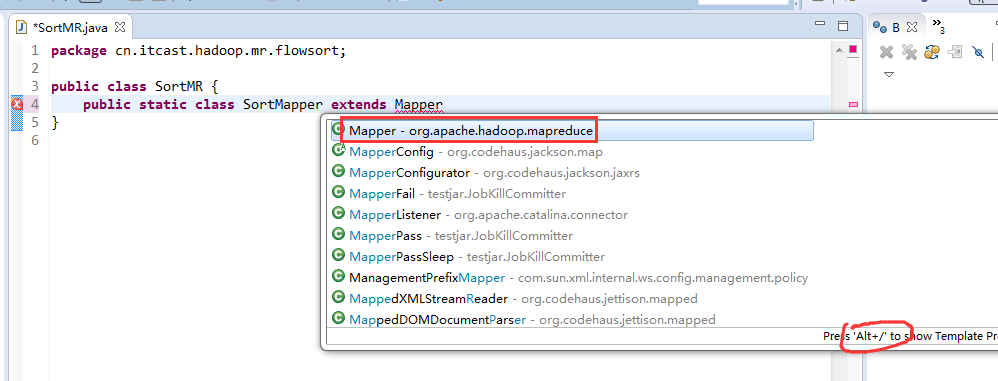

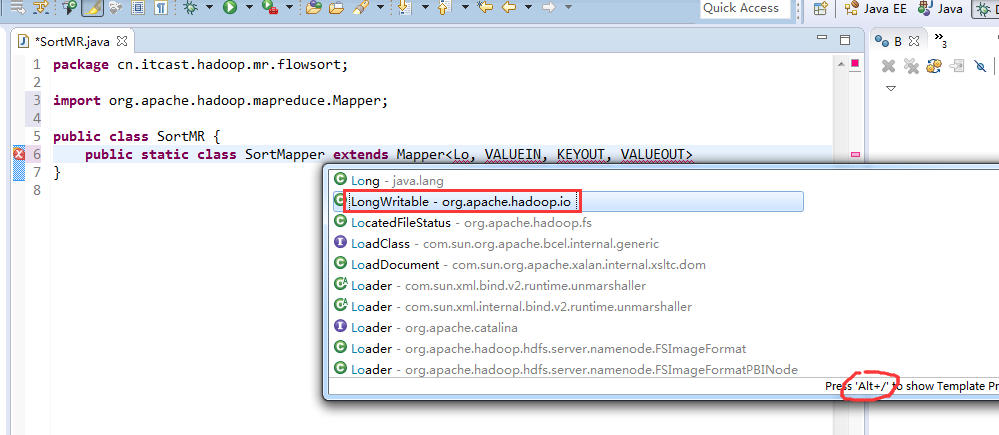
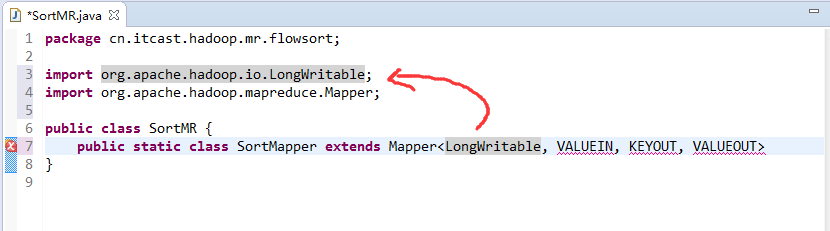
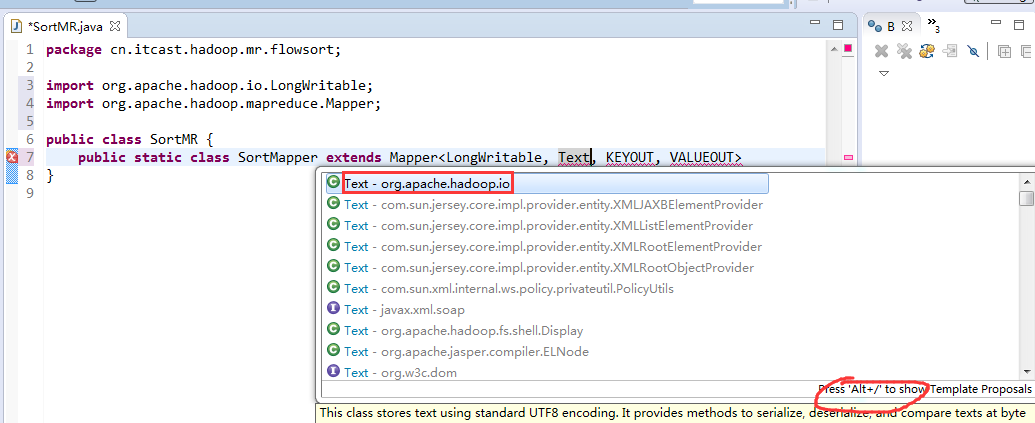
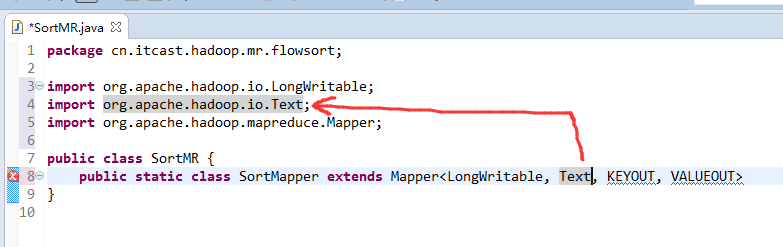

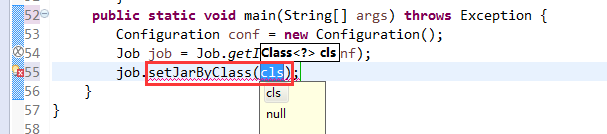
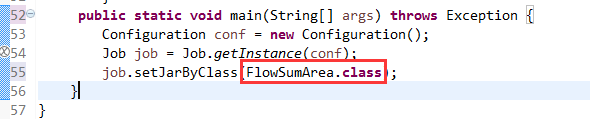
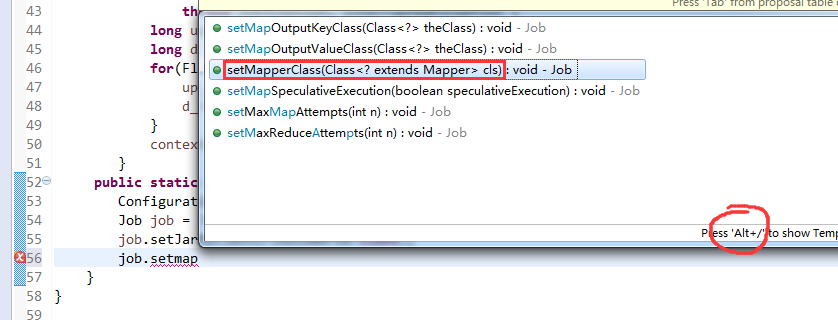
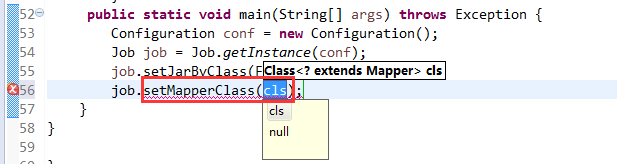
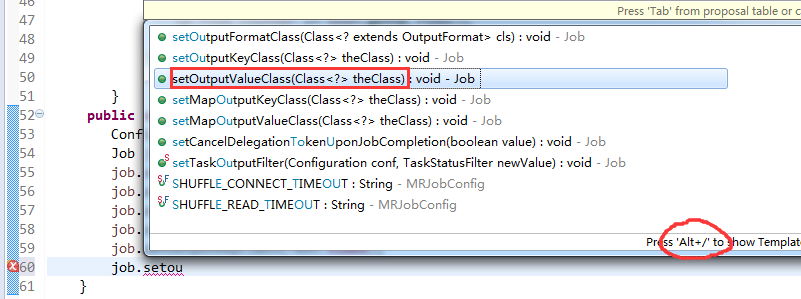
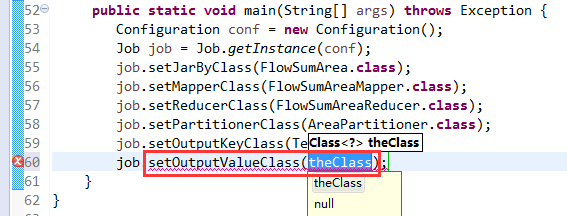
V2我们不要,怎么写代码?
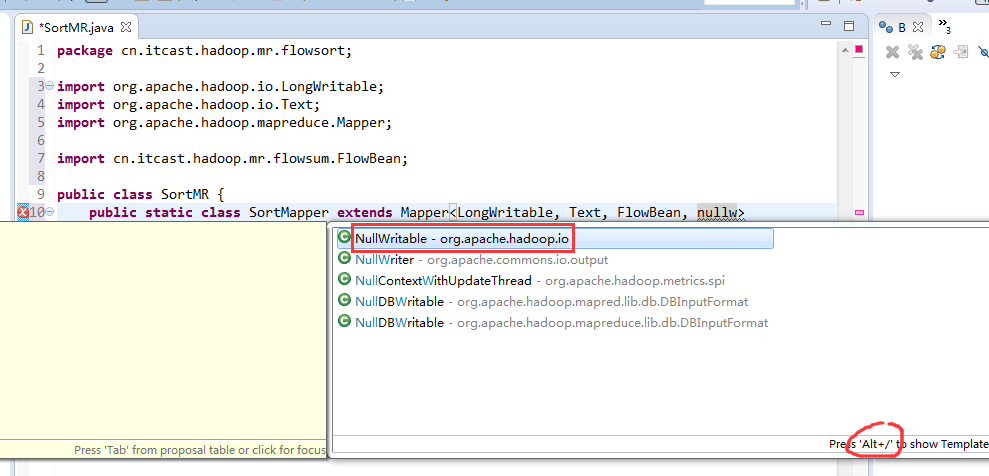

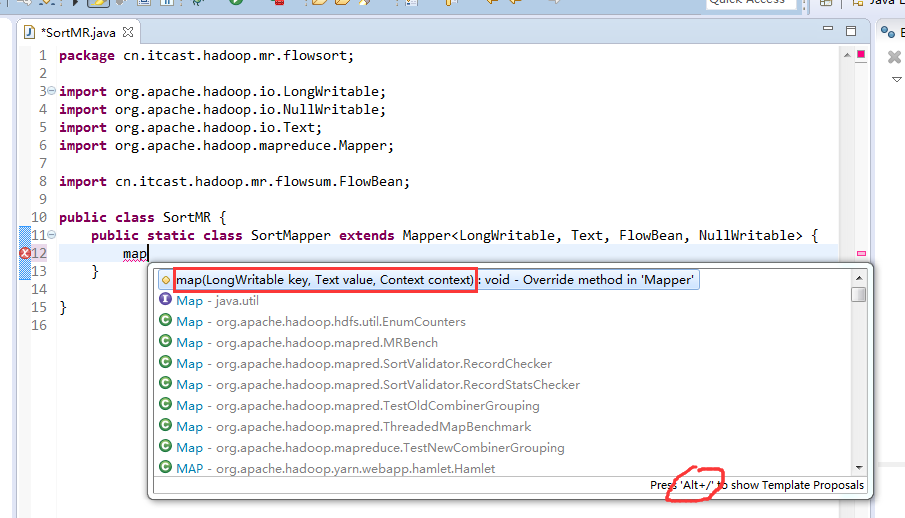
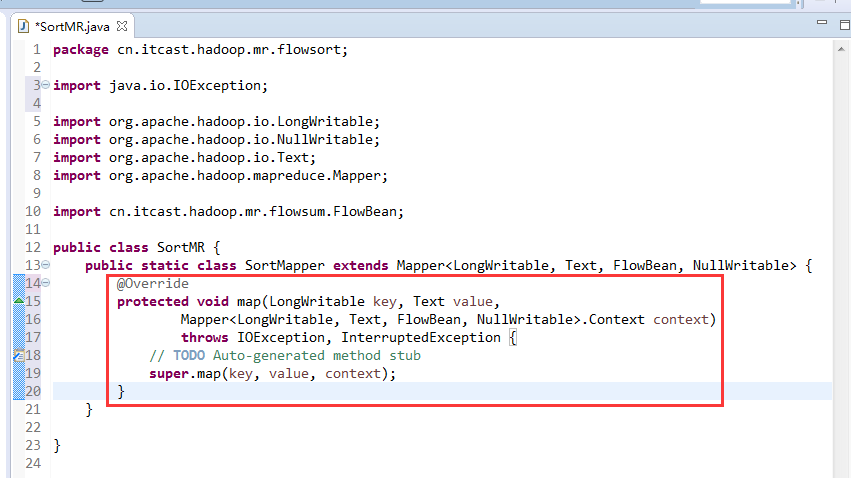
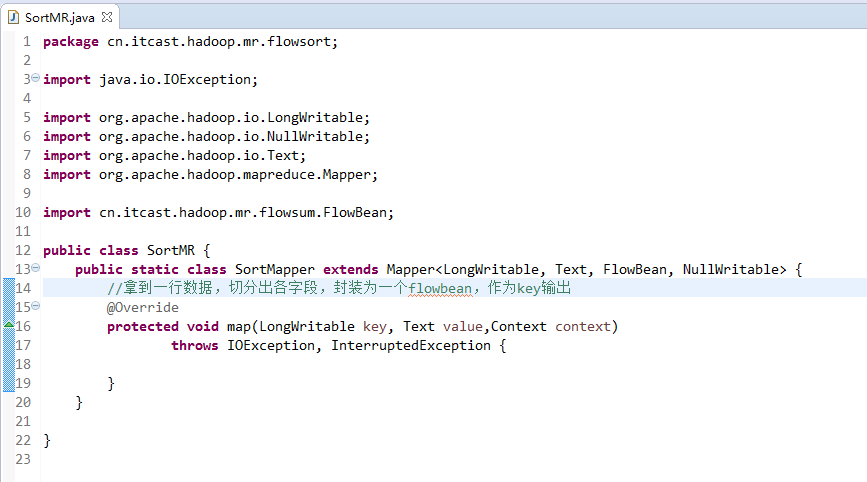
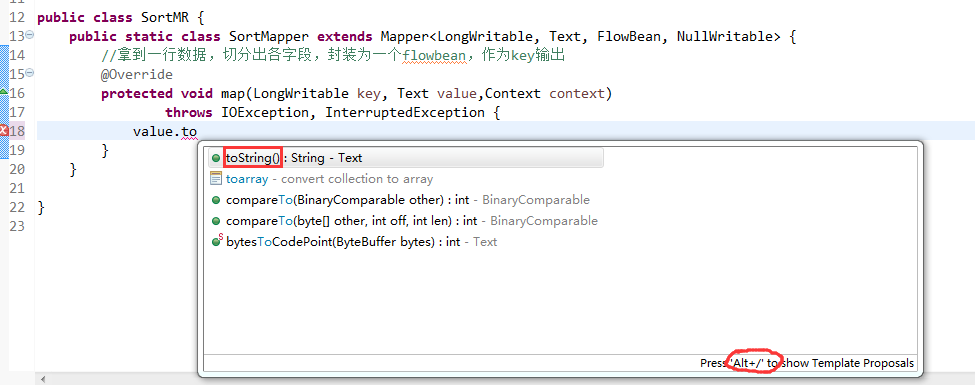
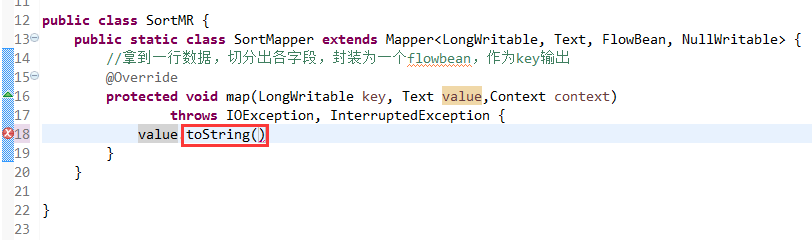
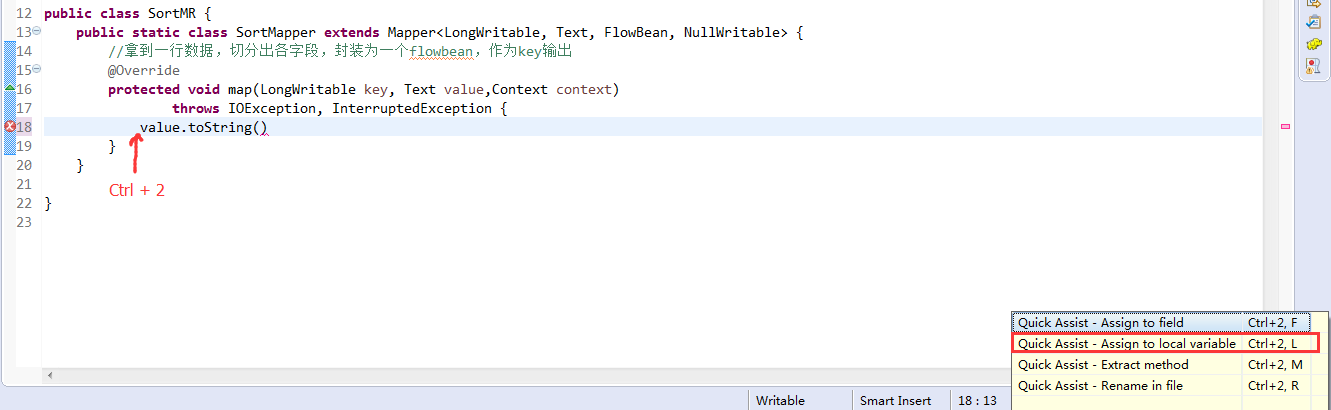


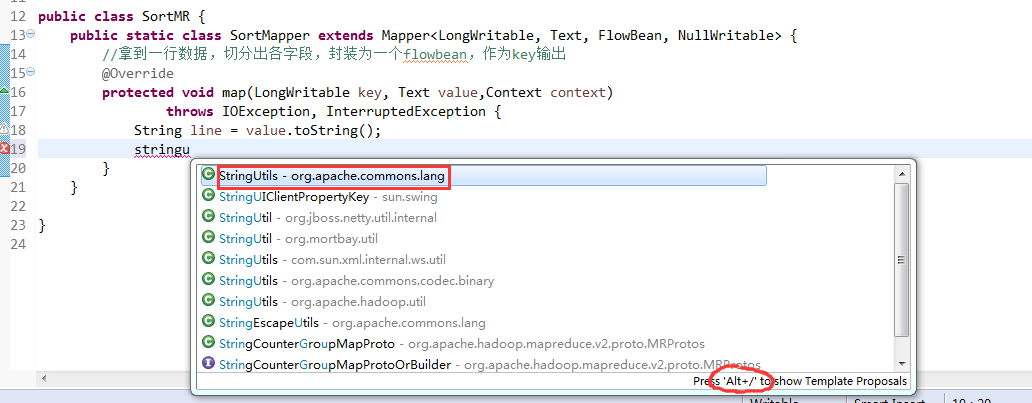



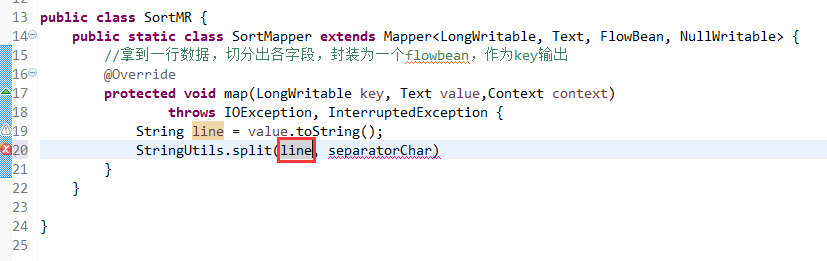
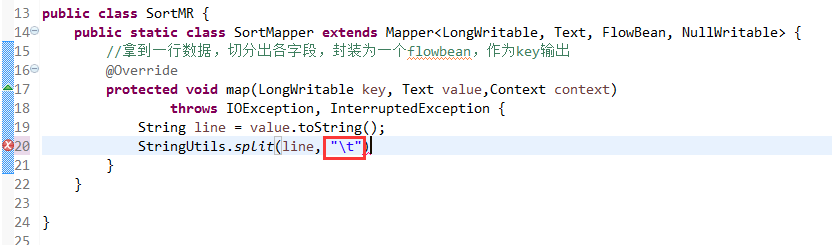
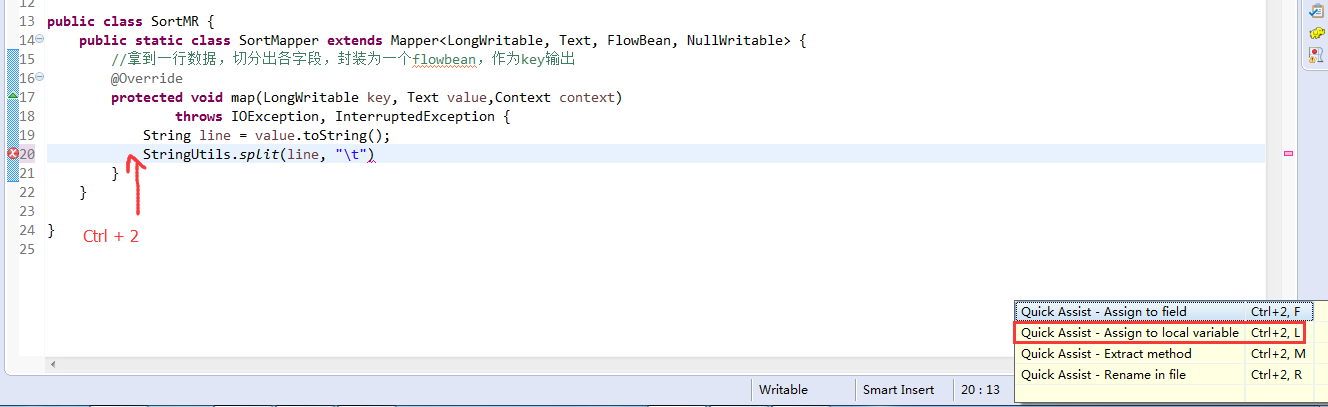


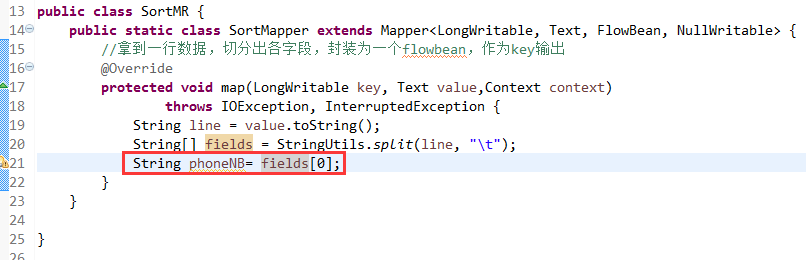

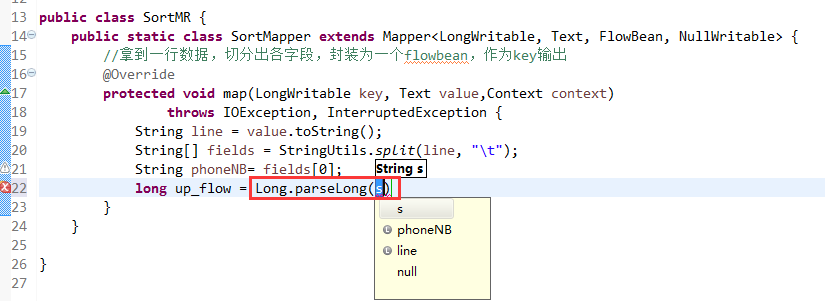
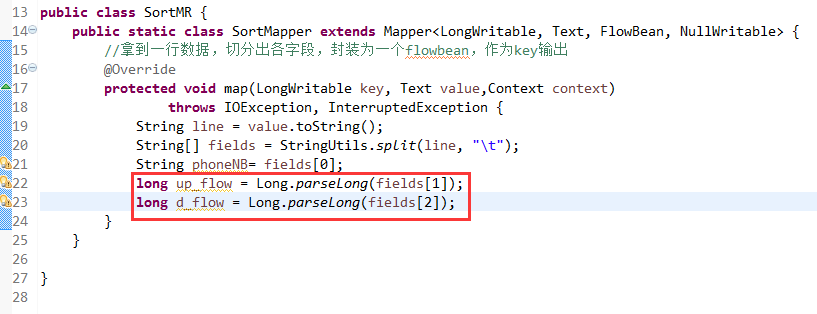
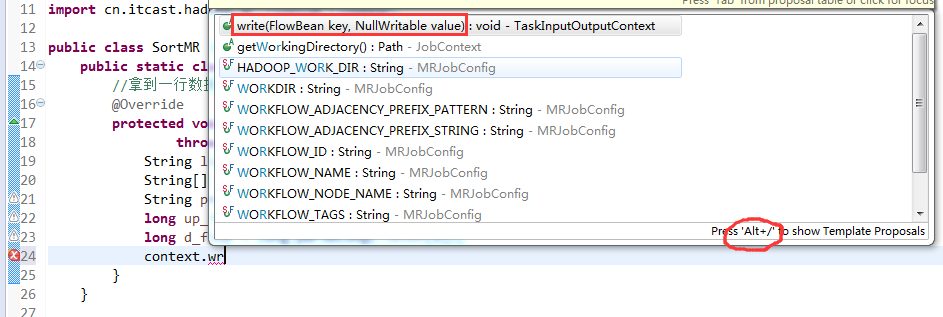
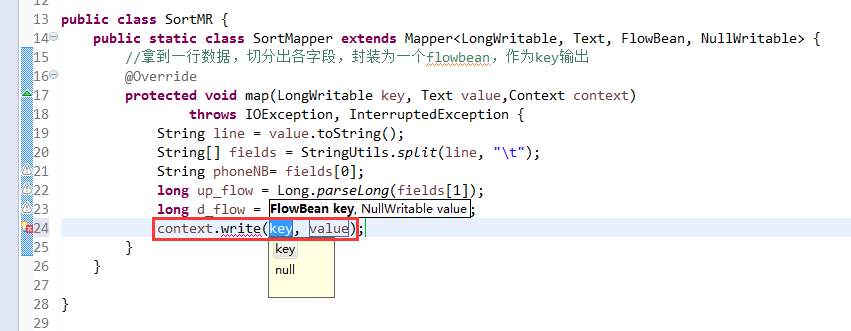
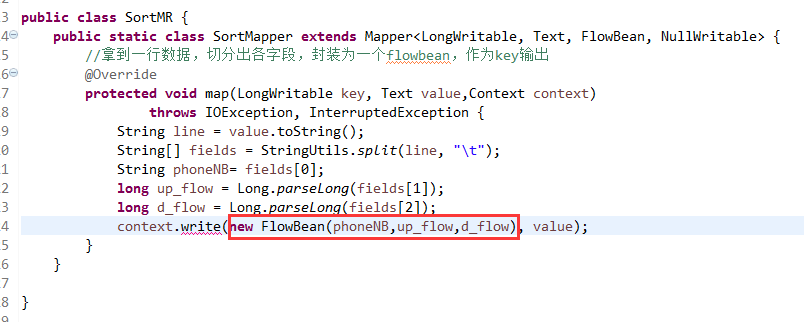
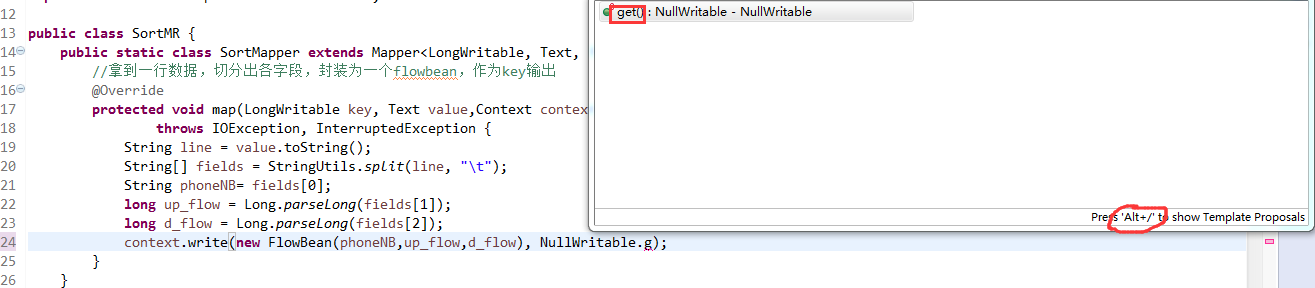
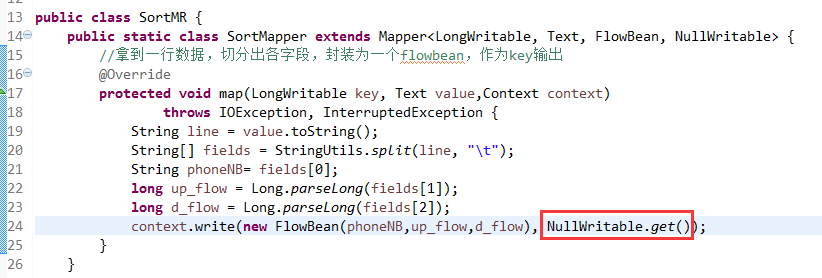

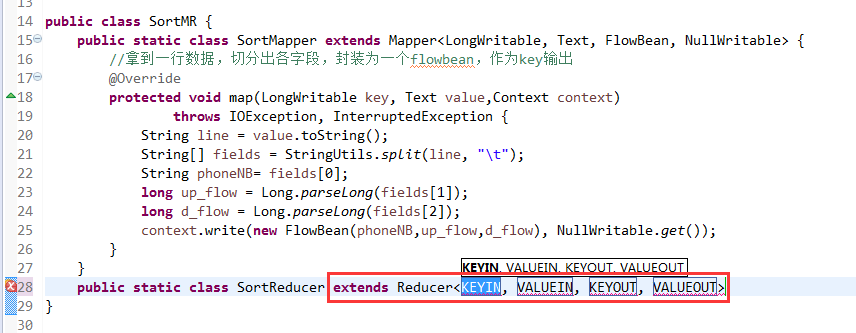
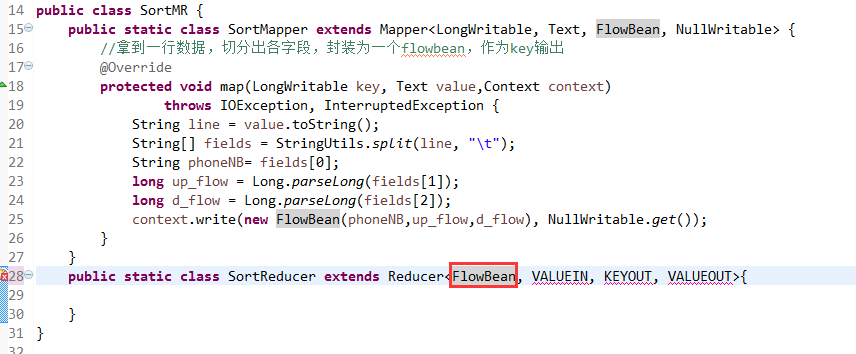
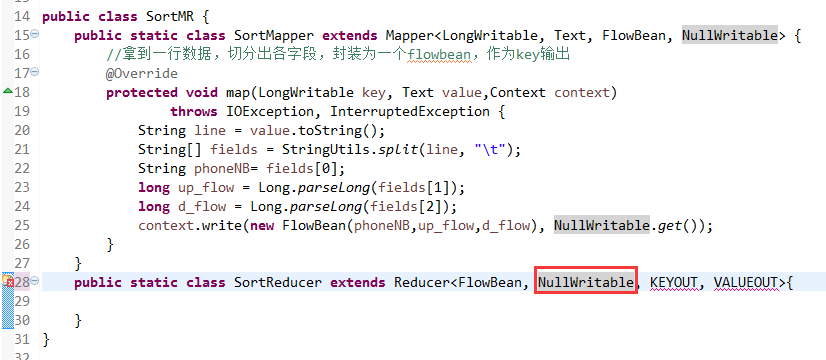

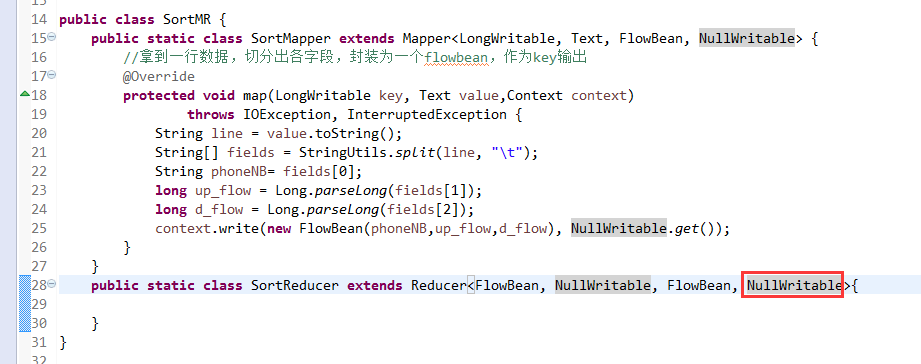
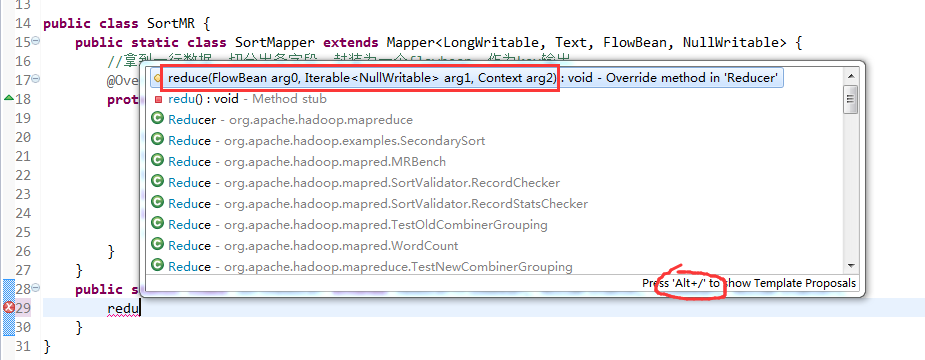
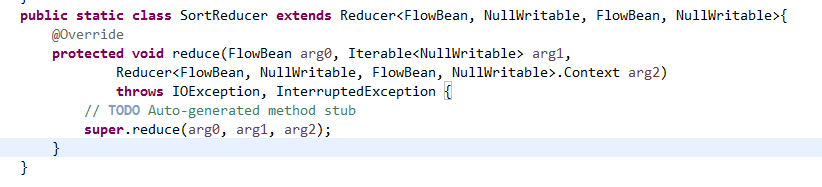



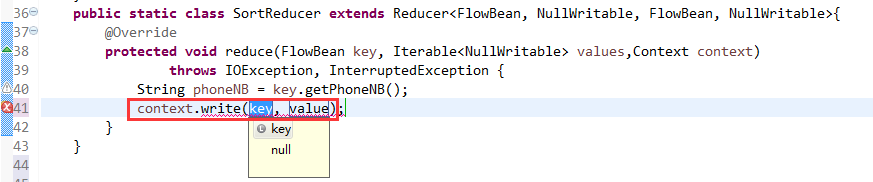

那么,我们想要实现由
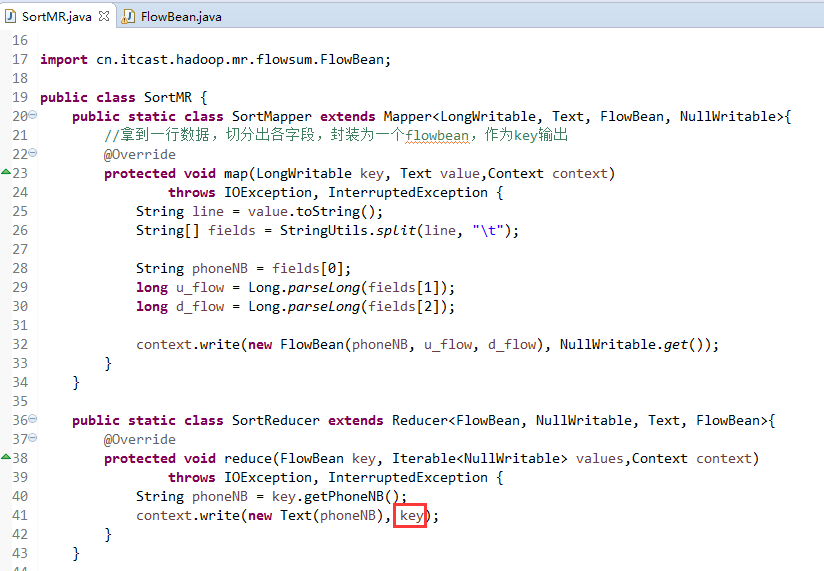
达到下面这种效果,
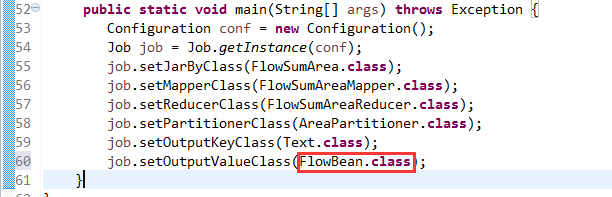
也要修改FlowBean代码
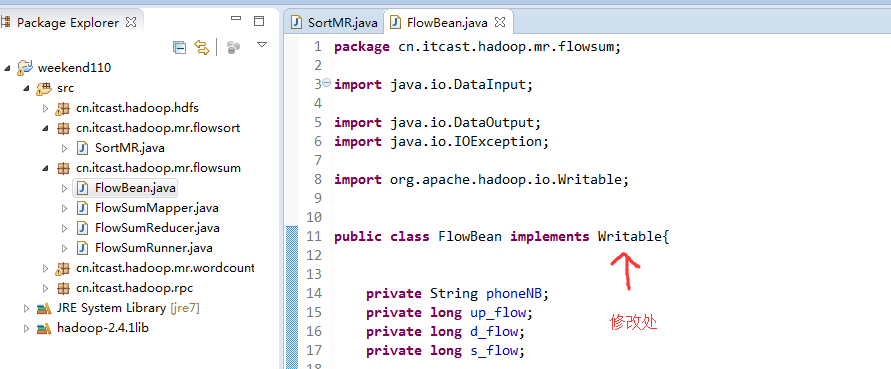
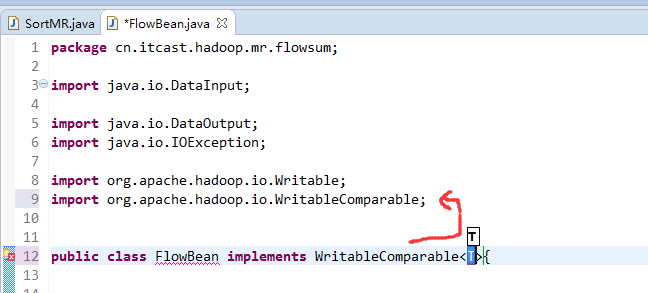
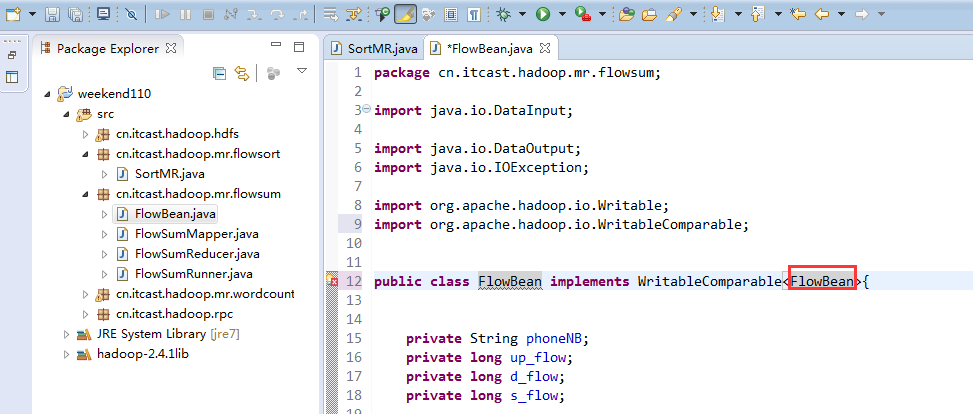
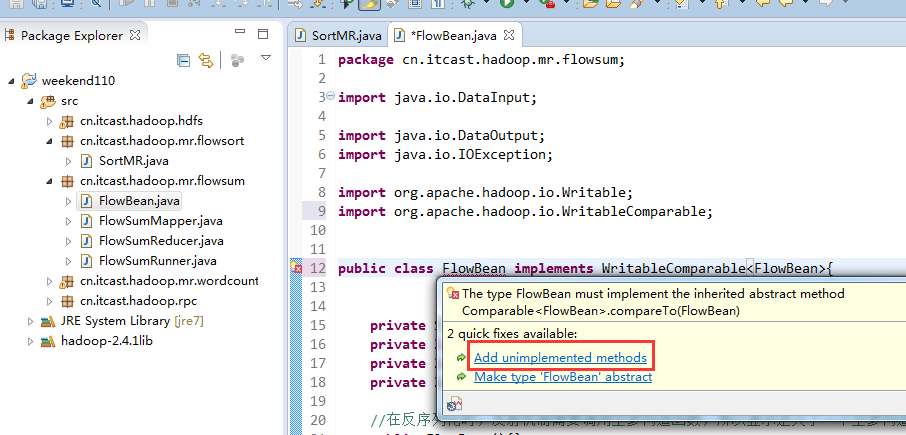
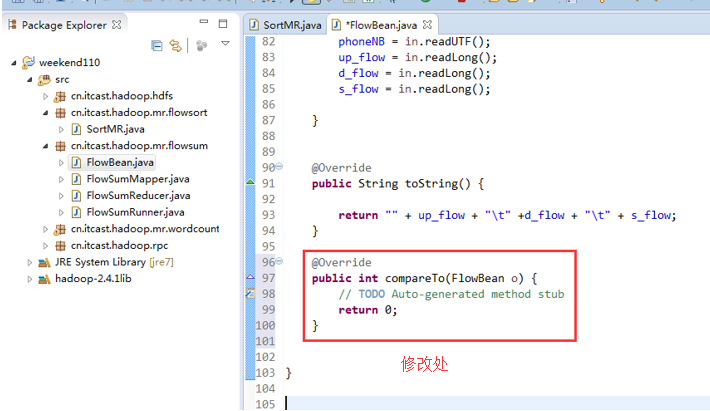
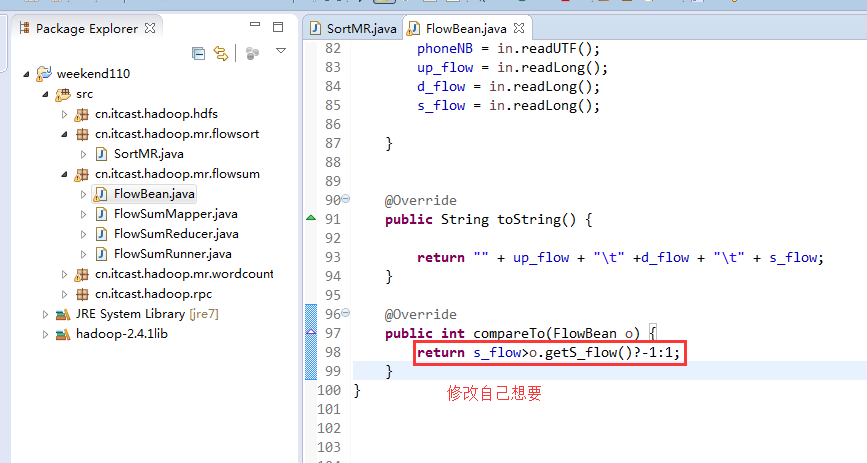
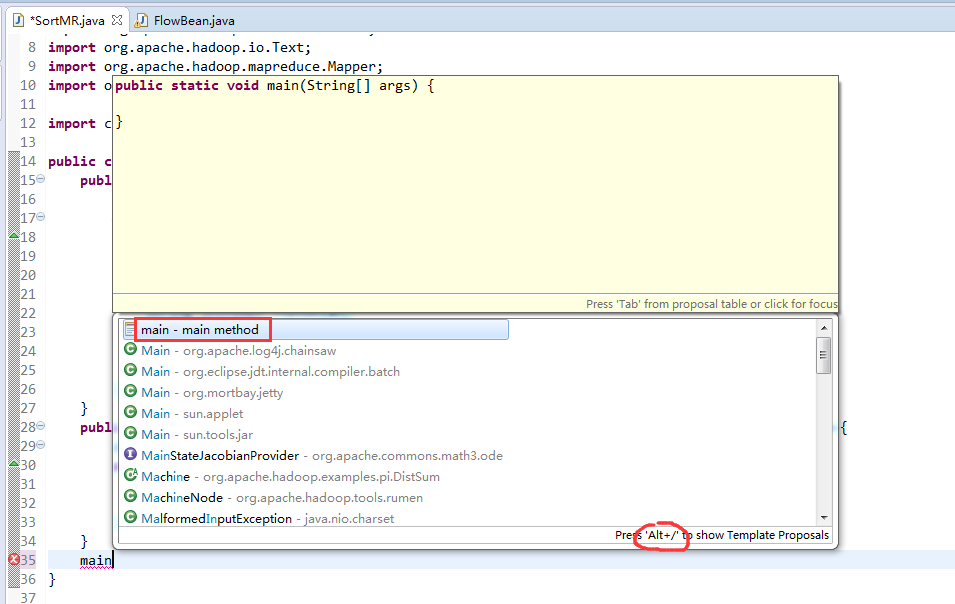
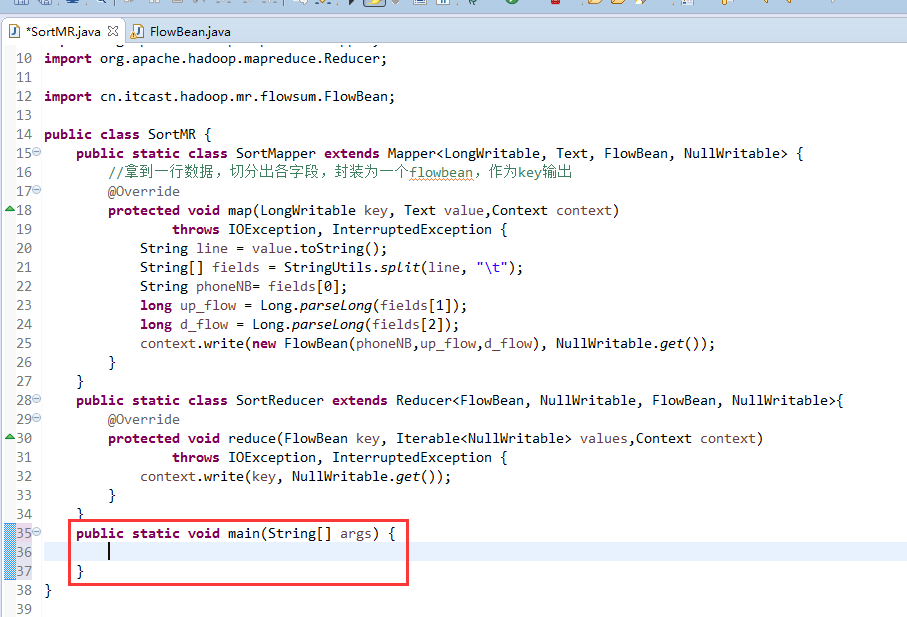
多领悟揣摩。
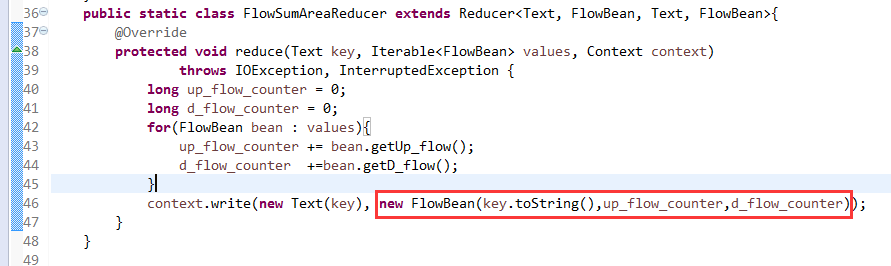
关于SotrMR和FlowBean(增改过的)
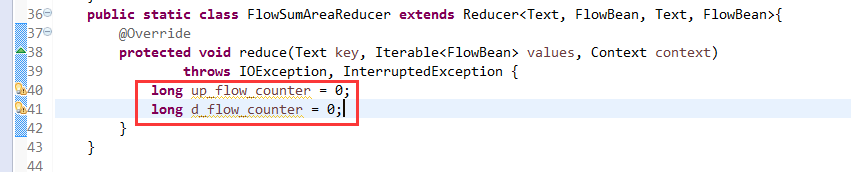
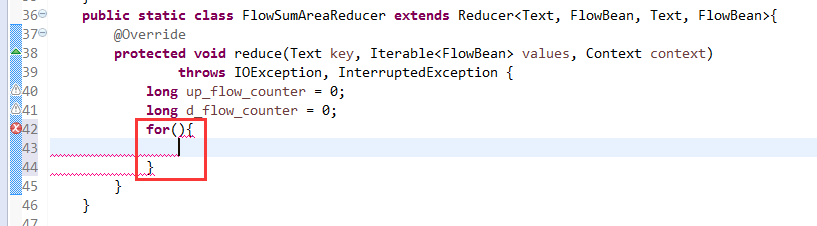
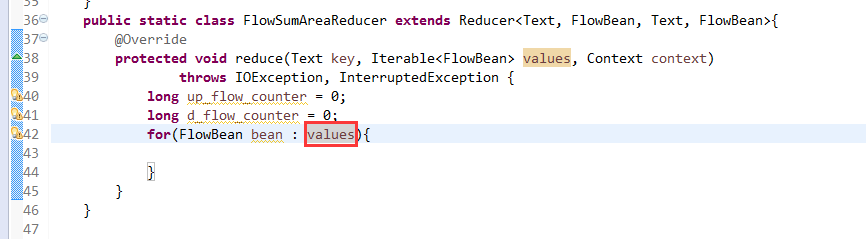
关于FlowMapper、FlowReducer、FlowSumRunner、FlowBean
之间的对比




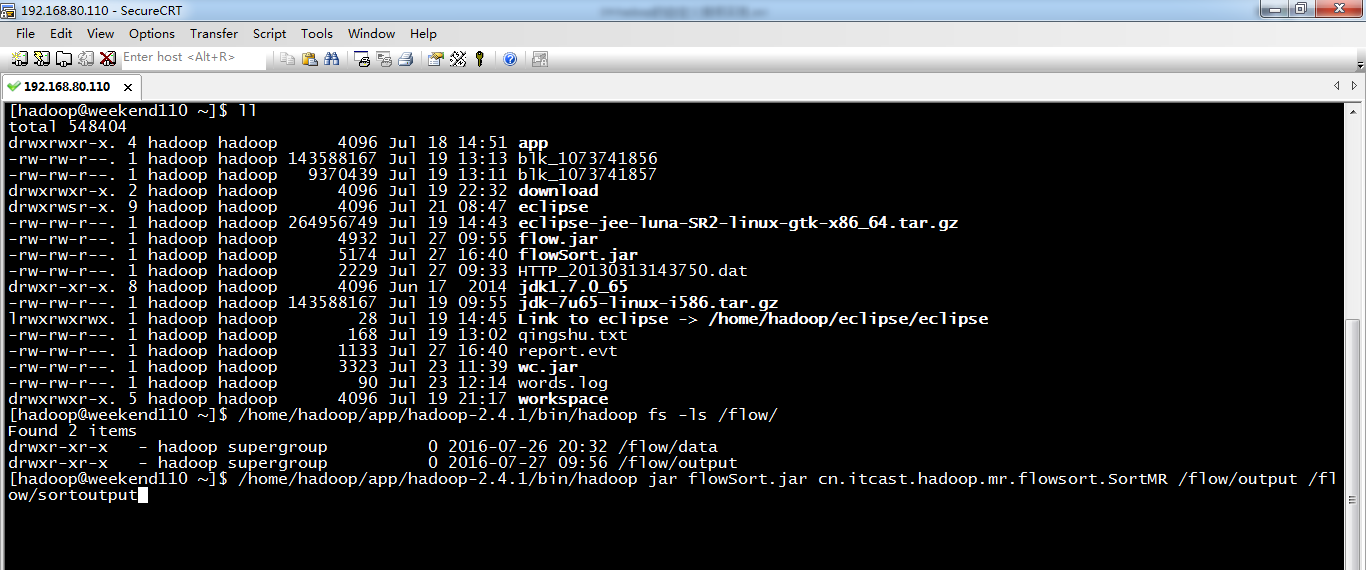
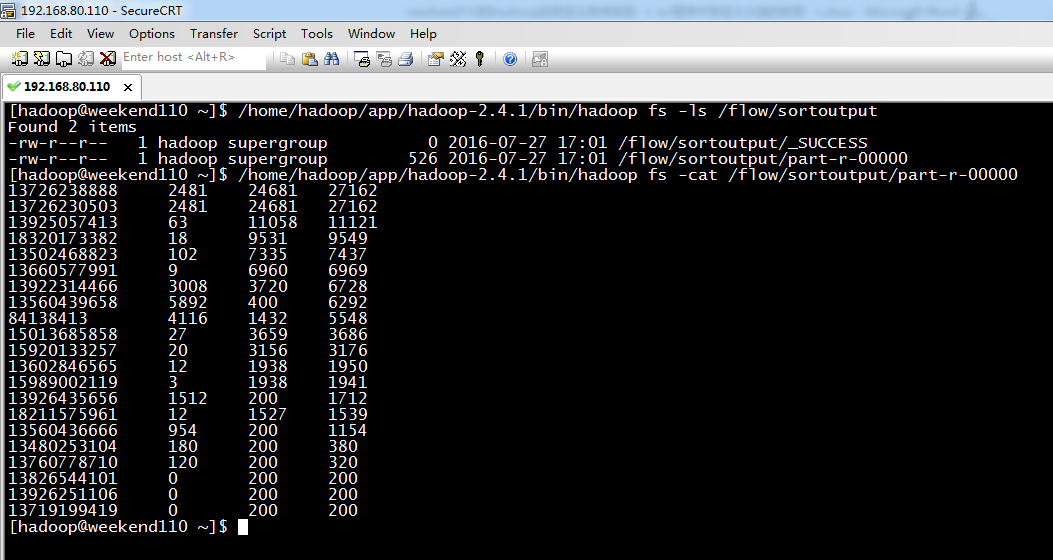
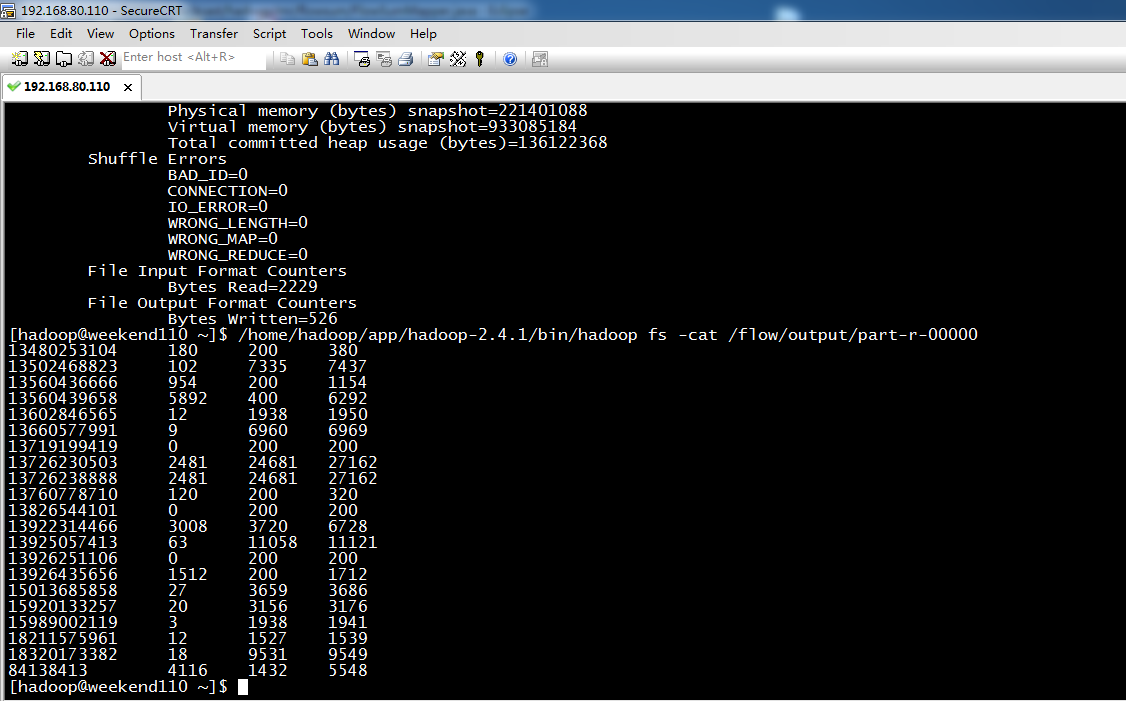
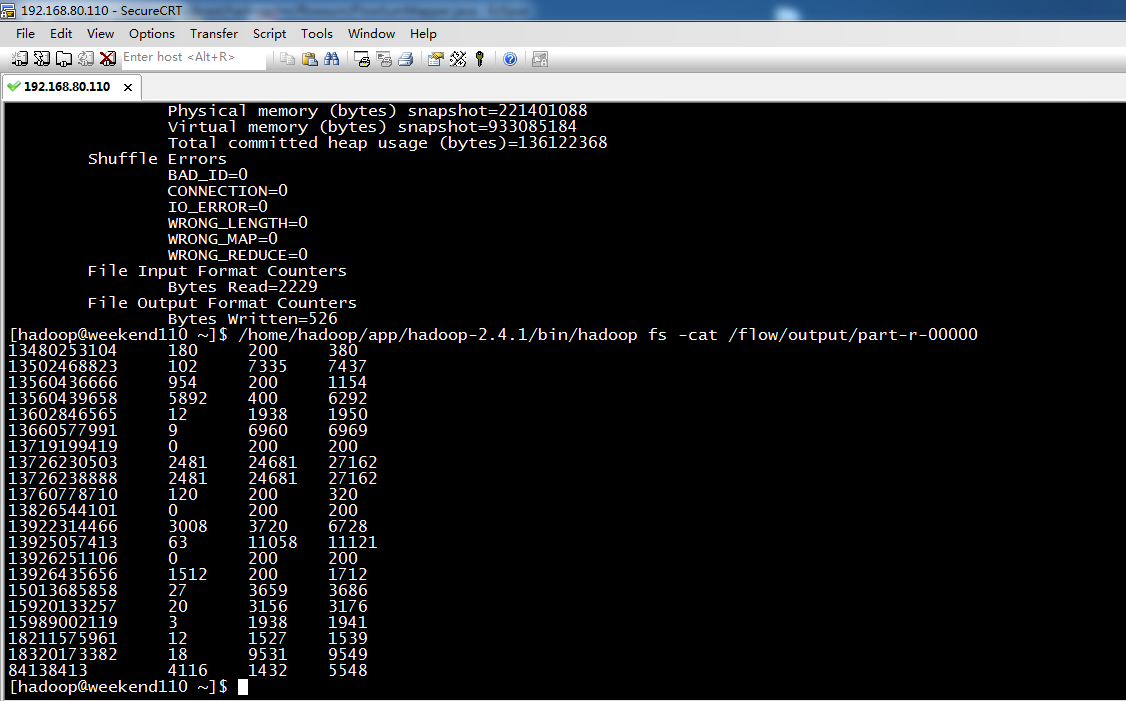
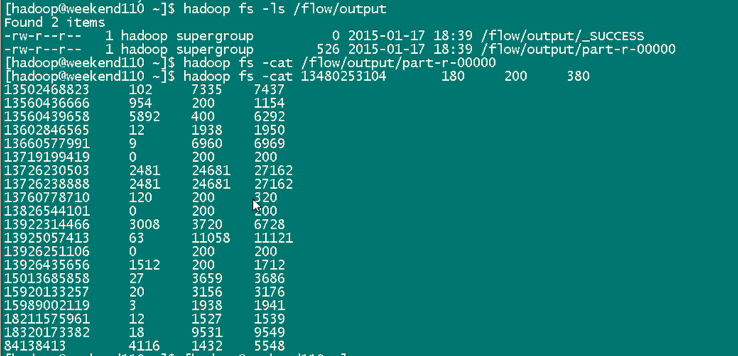
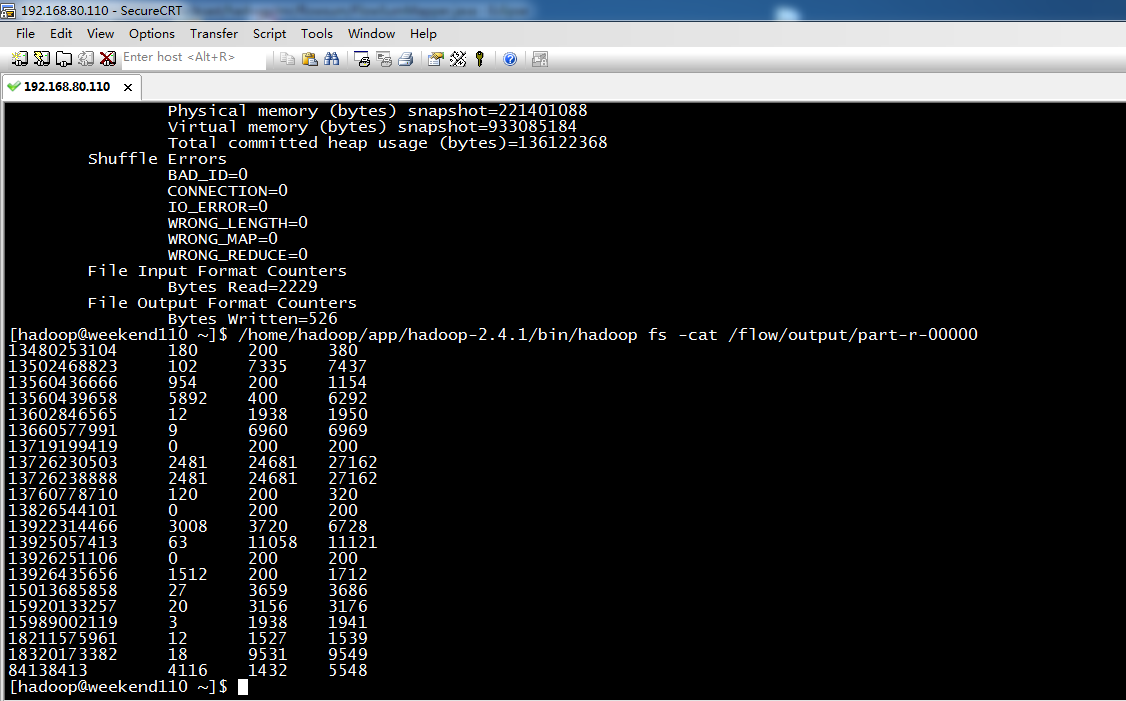
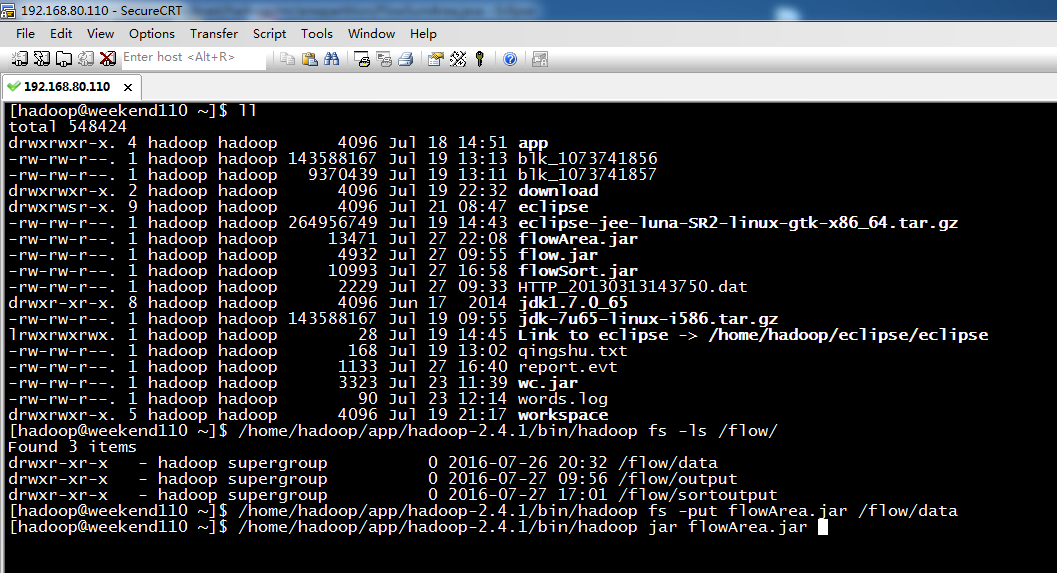
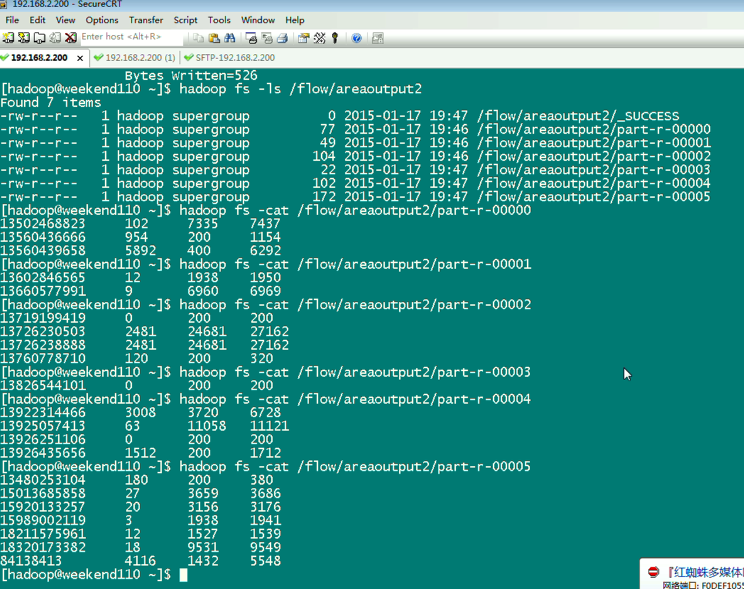
[hadoop@weekend110 ~]$ /home/hadoop/app/hadoop-2.4.1/bin/hadoop fs -cat /flow/sortoutput/part-r-00000
13726238888 2481 24681
13726230503 2481 24681
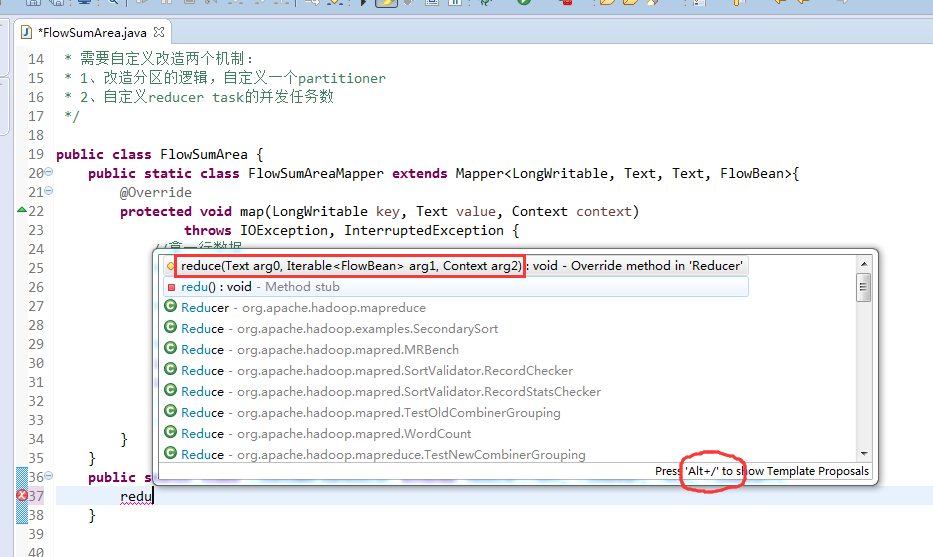
13925057413 63 11058
18320173382 18 9531
13502468823 102 7335
13660577991 9 6960
13922314466 3008 3720
13560439658 5892 400 6292
84138413 4116 1432
15013685858 27 3659
15920133257 20 3156
13602846565 12 1938
15989002119 3 1938
13926435656 1512 200
18211575961 12 1527
13560436666 954 200
13480253104 180 200
13760778710 120 200
13826544101 0 200
13926251106 0 200
13719199419 0 200
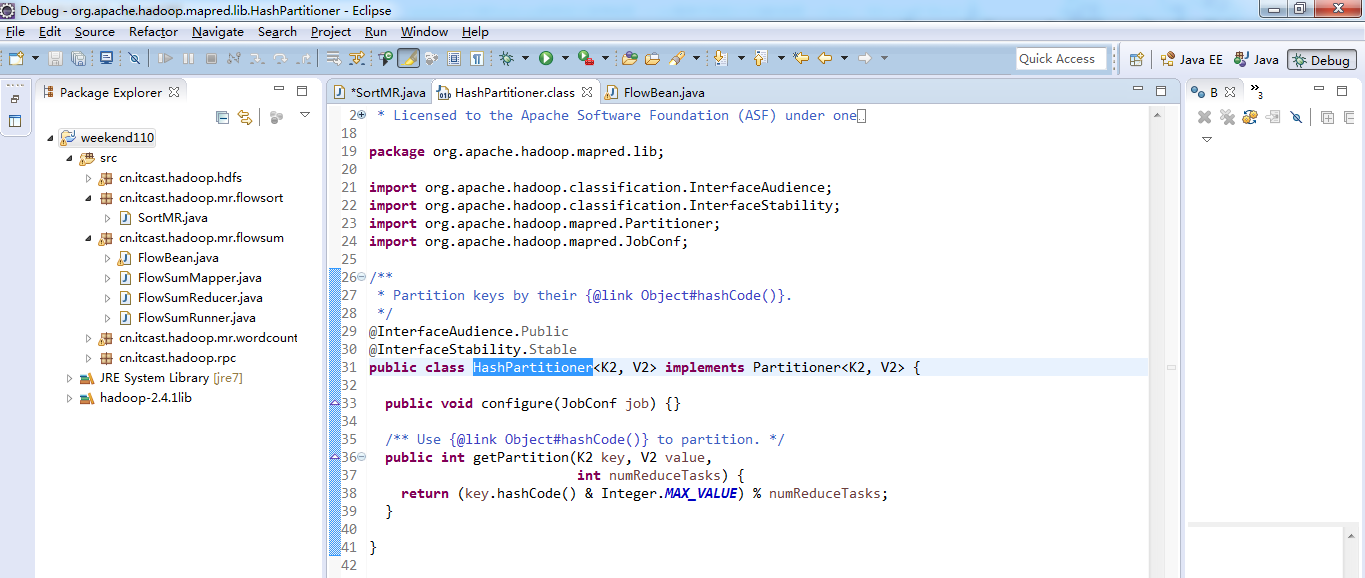
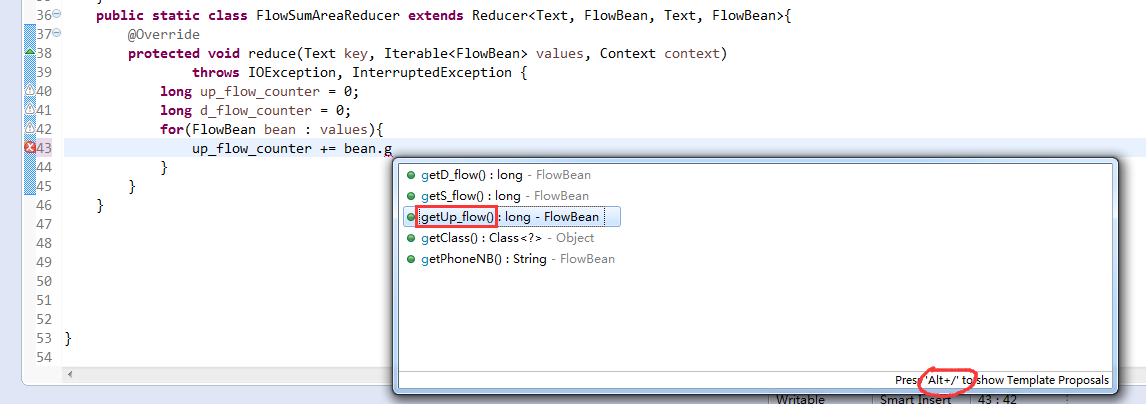
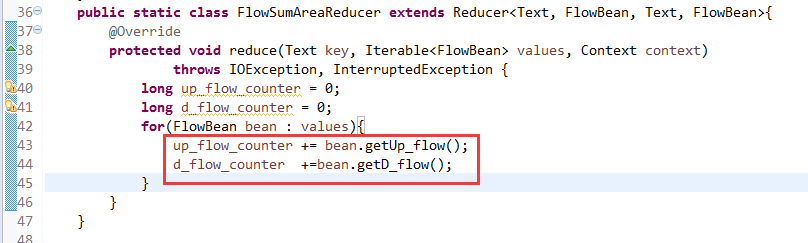
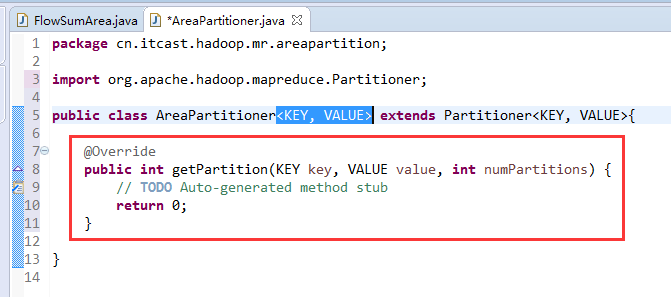
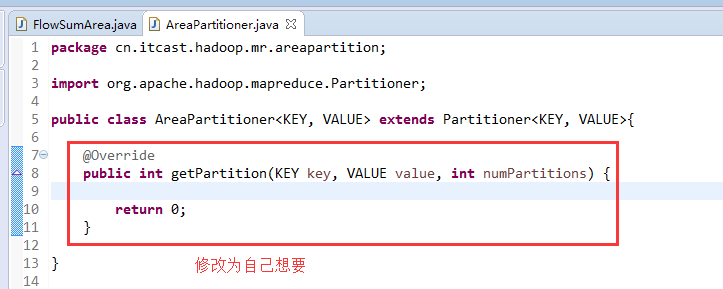
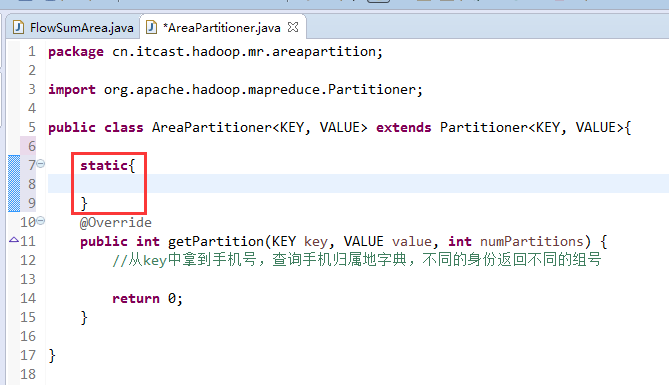
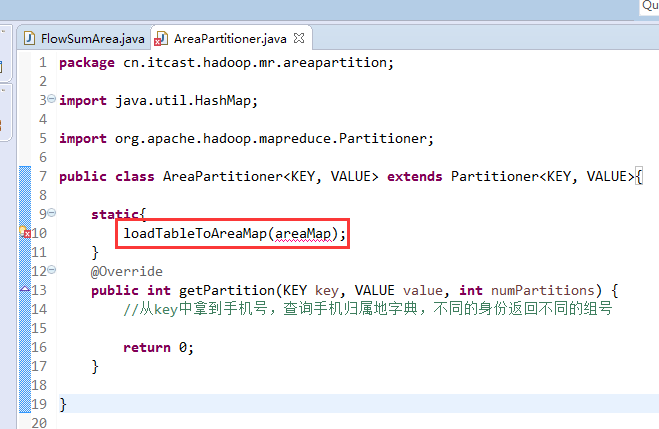
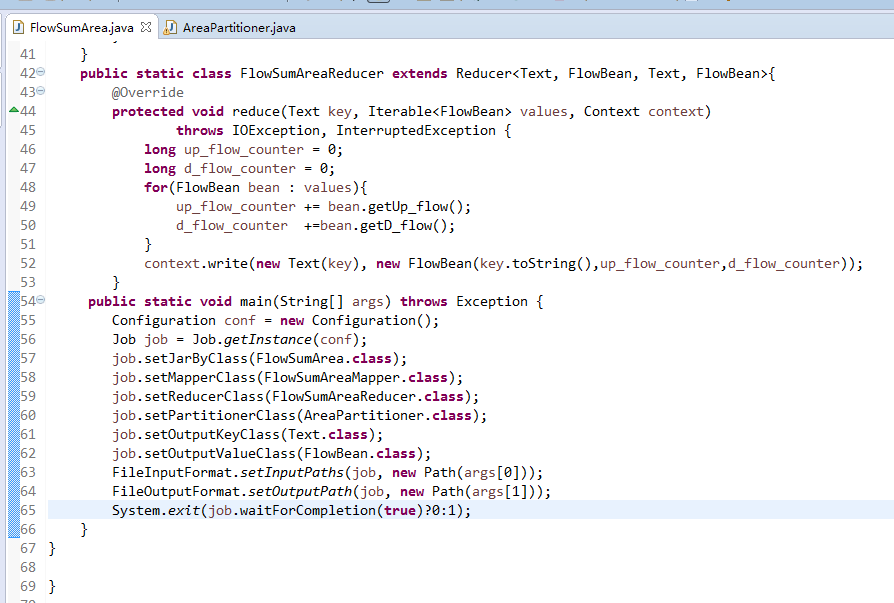
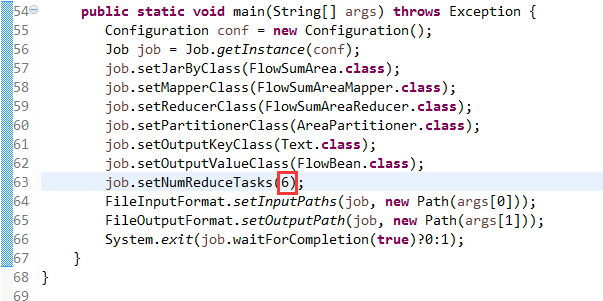
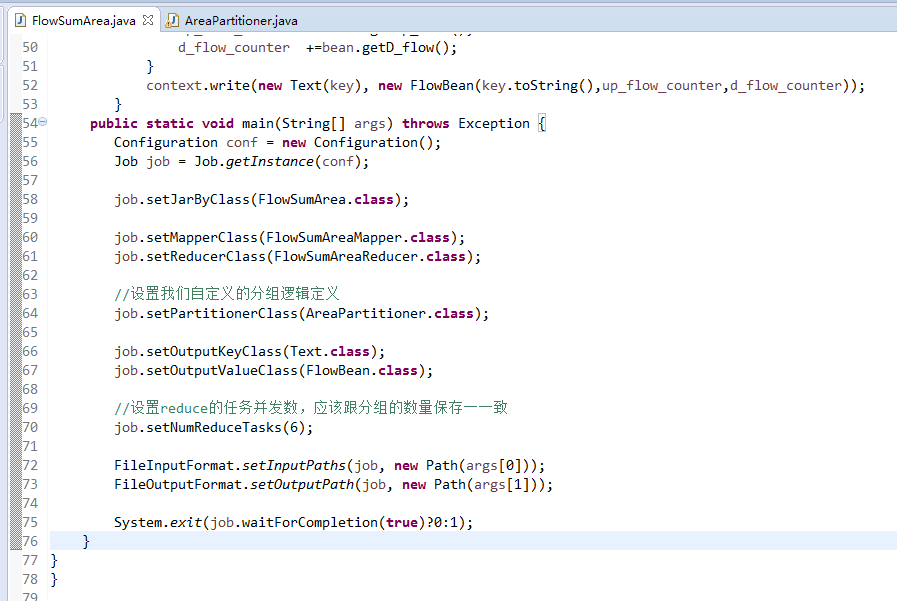
默认分组是哈希,
/**
* Licensed to the Apache Software Foundation (ASF) under one
* or more contributor license agreements. See the NOTICE file
* distributed with this work for additional information
* regarding copyright ownership. The ASF licenses this file
* to you under the Apache License, Version 2.0 (the
* "License"); you may not use this file except in compliance
* with the License. You may obtain a copy of the License at
*
* http://www.apache.org/licenses/LICENSE-2.0
*
* Unless required by applicable law or agreed to in writing, software
* distributed under the License is distributed on an "AS IS" BASIS,
* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
* See the License for the specific language governing permissions and
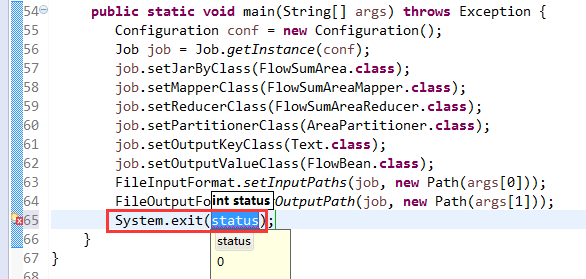
* limitations under the License.
*/
package org.apache.hadoop.mapred.lib;
import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.mapred.Partitioner;
import org.apache.hadoop.mapred.JobConf;
/**
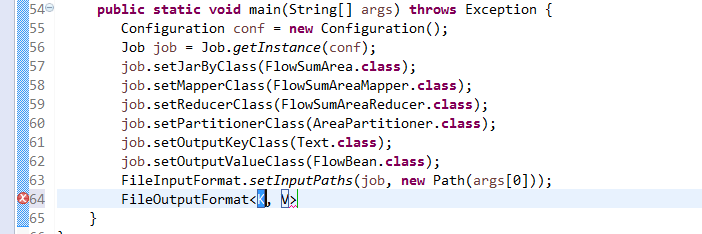
* Partition keys by their {@link Object#hashCode()}.
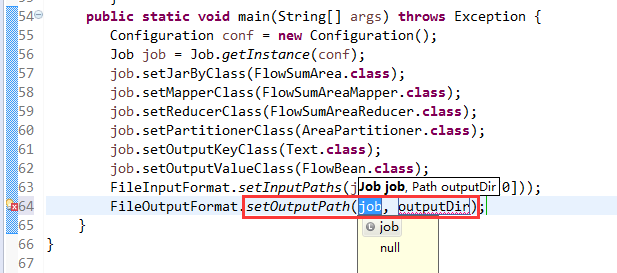
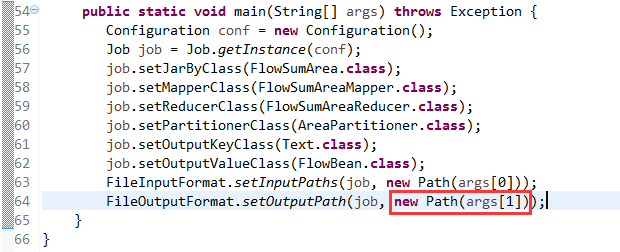
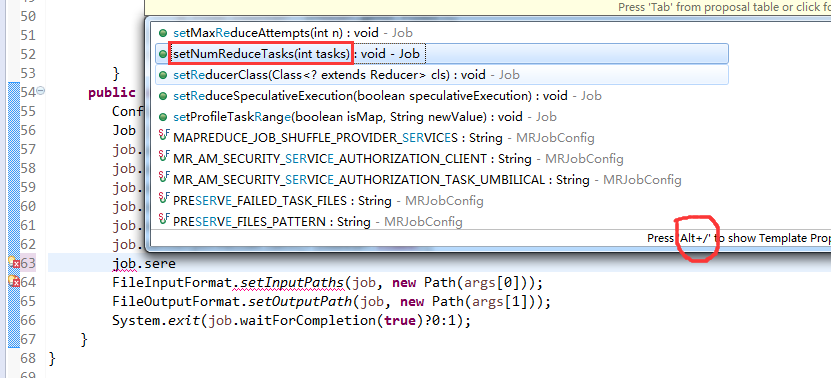
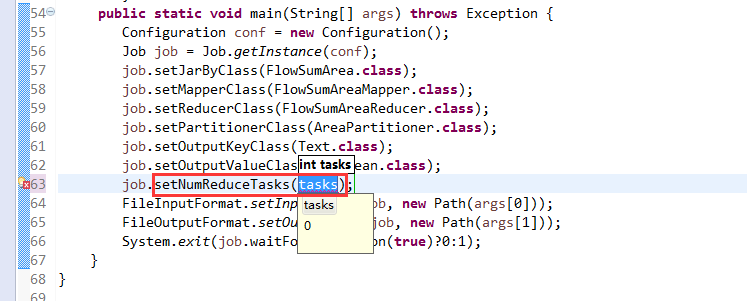
*/
@InterfaceAudience.Public
@InterfaceStability.Stable
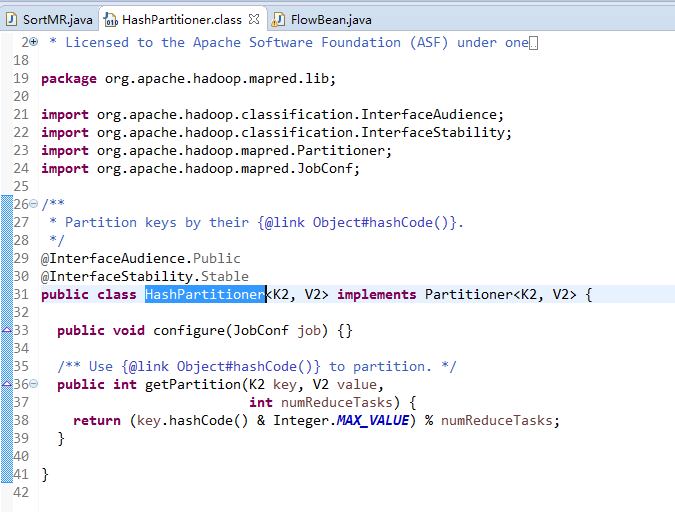
public class HashPartitioner<K2, V2> implements Partitioner<K2, V2> {
public void configure(JobConf job) {}
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K2 key, V2 value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}


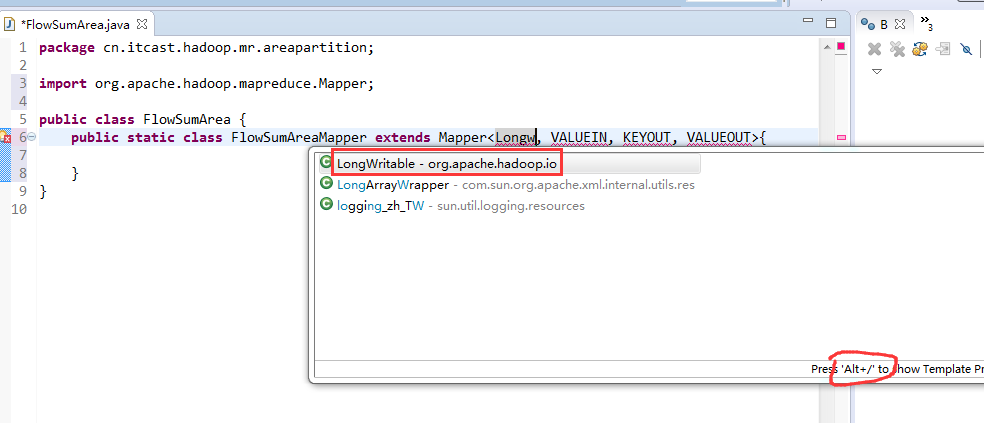


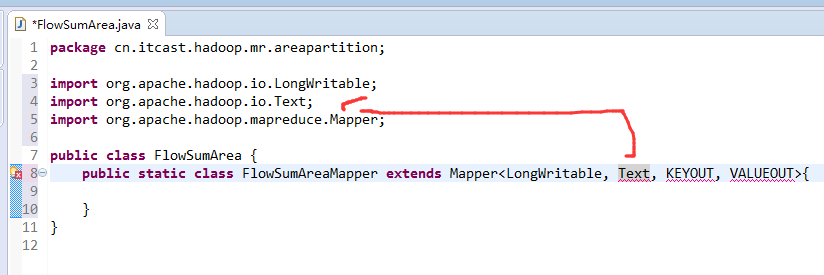
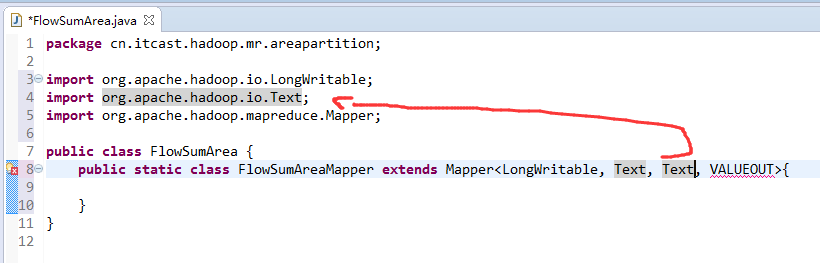



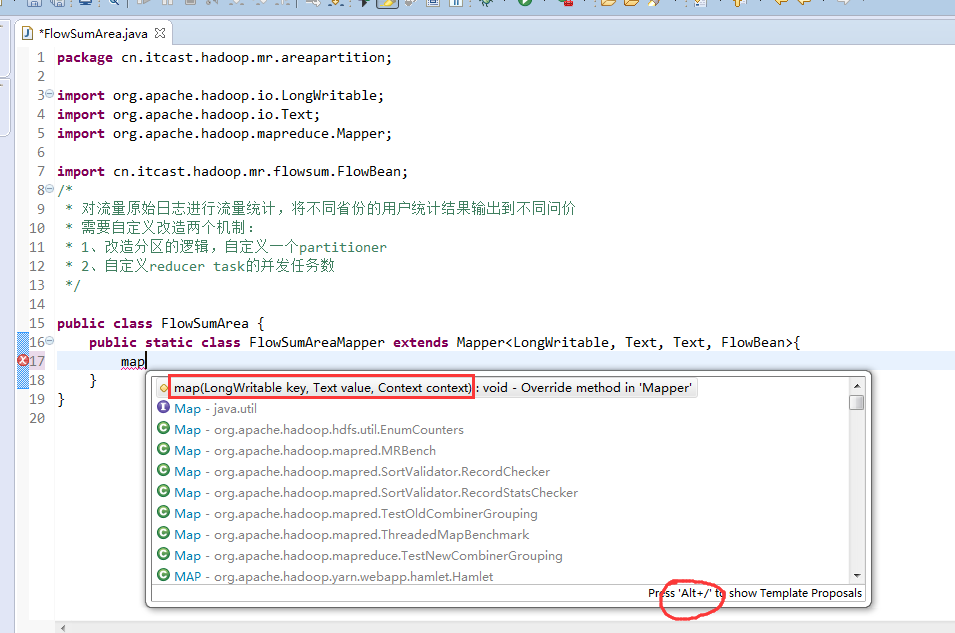





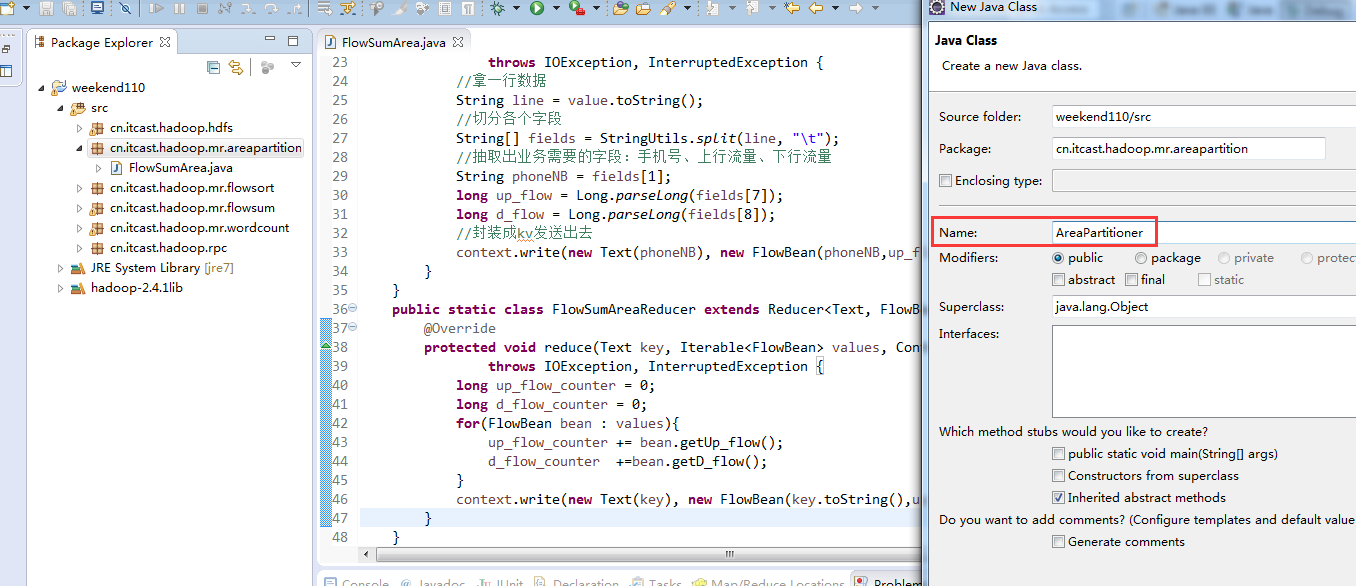
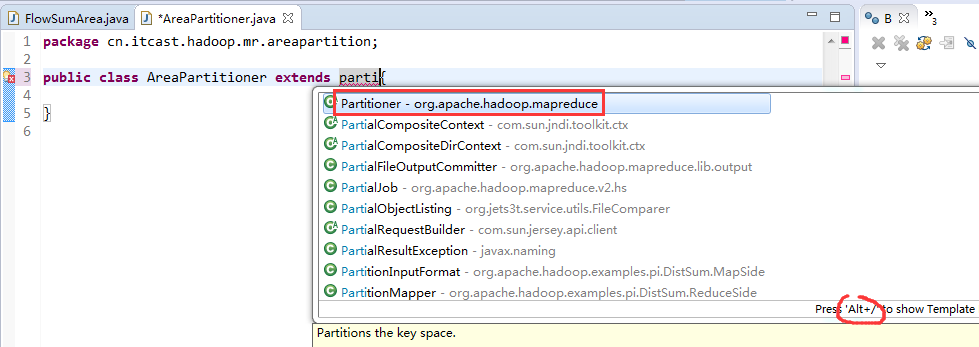
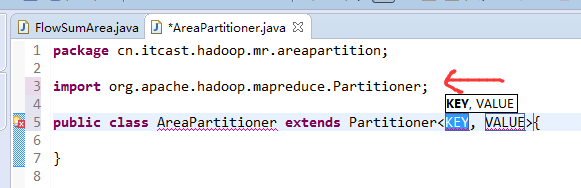
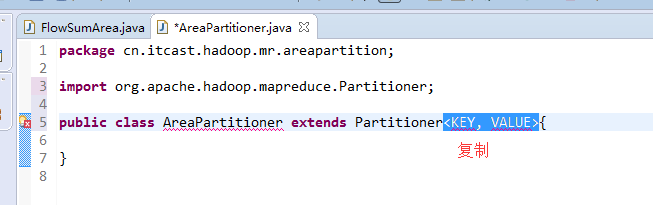
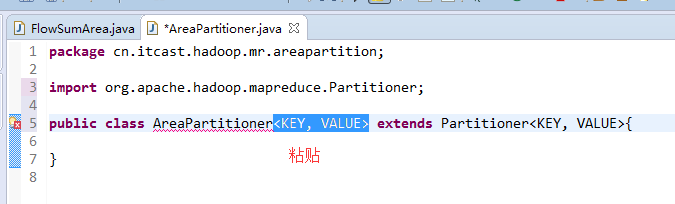
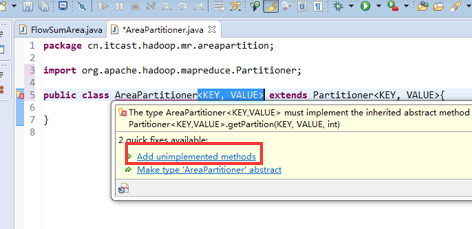













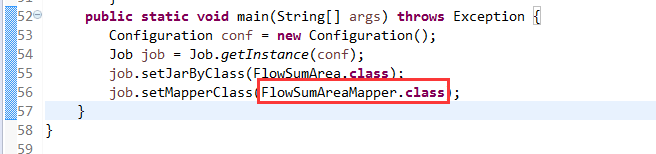
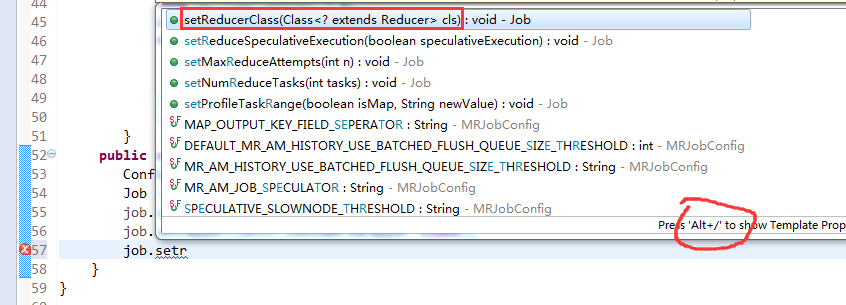
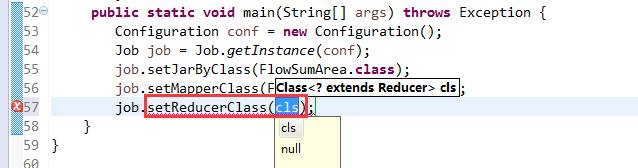
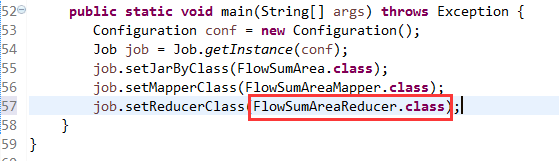
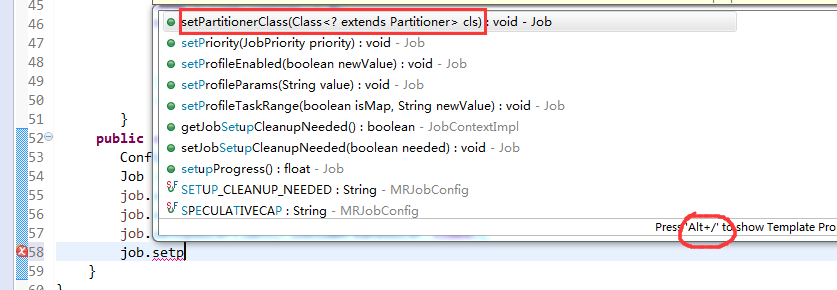
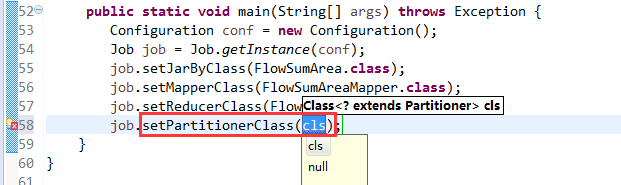
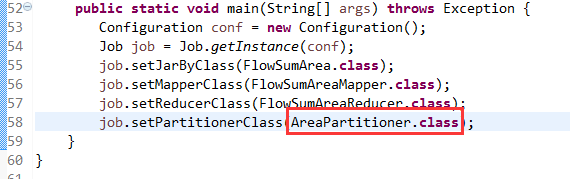


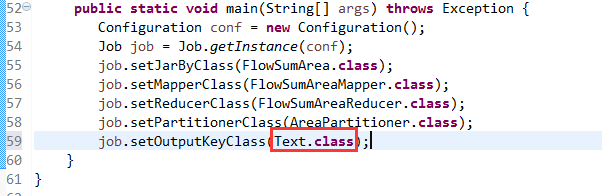
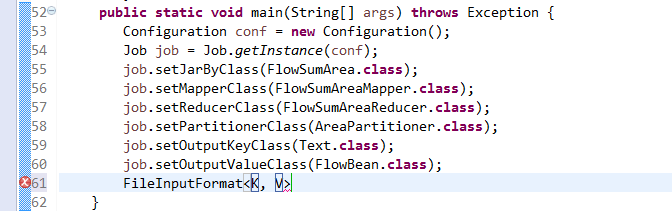

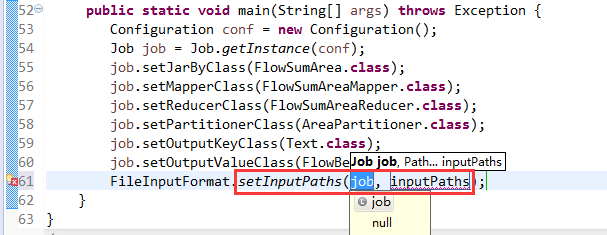
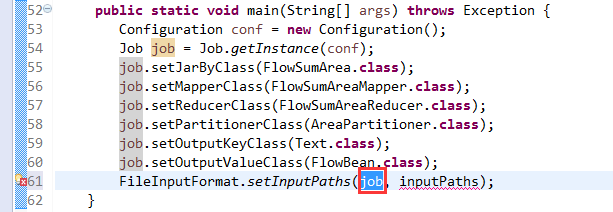

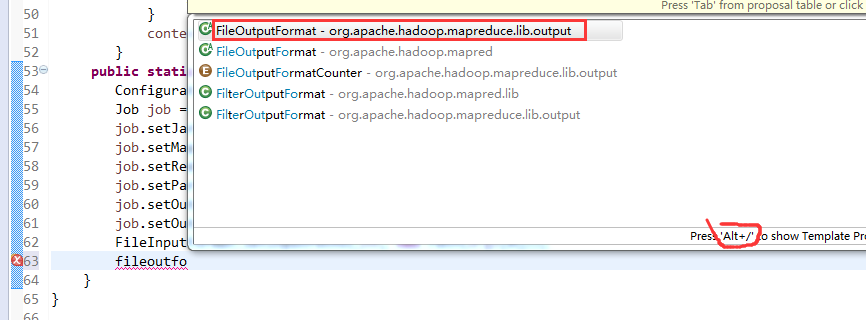




[hadoop@weekend110 ~]$ /home/hadoop/app/hadoop-2.4.1/bin/hadoop jar flowArea.jar cn.itcast.hadoop.mr.areapartition.FlowSumArea /flow/data /flow/areaoutput


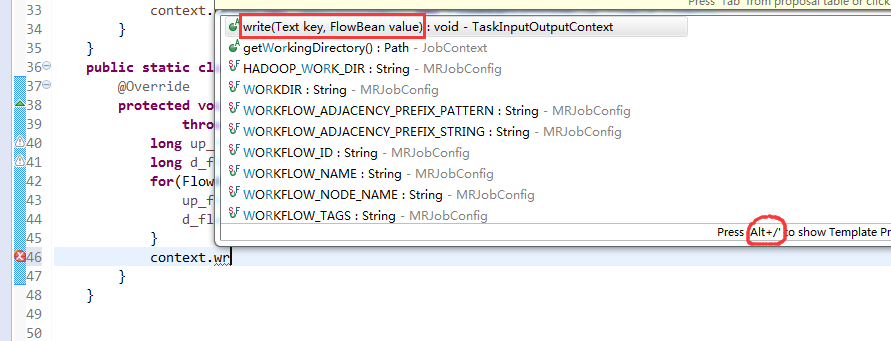
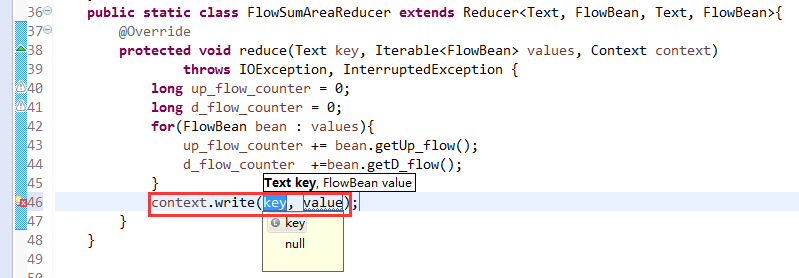
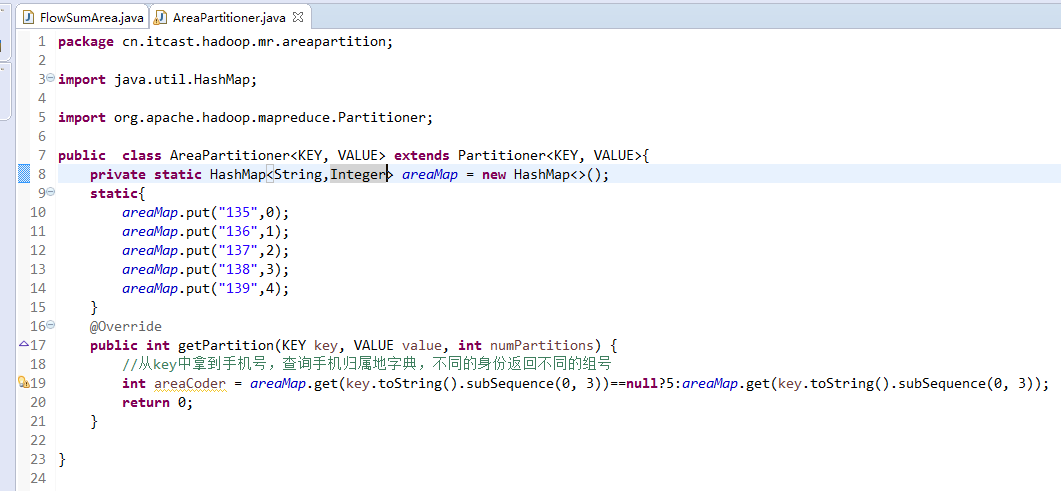
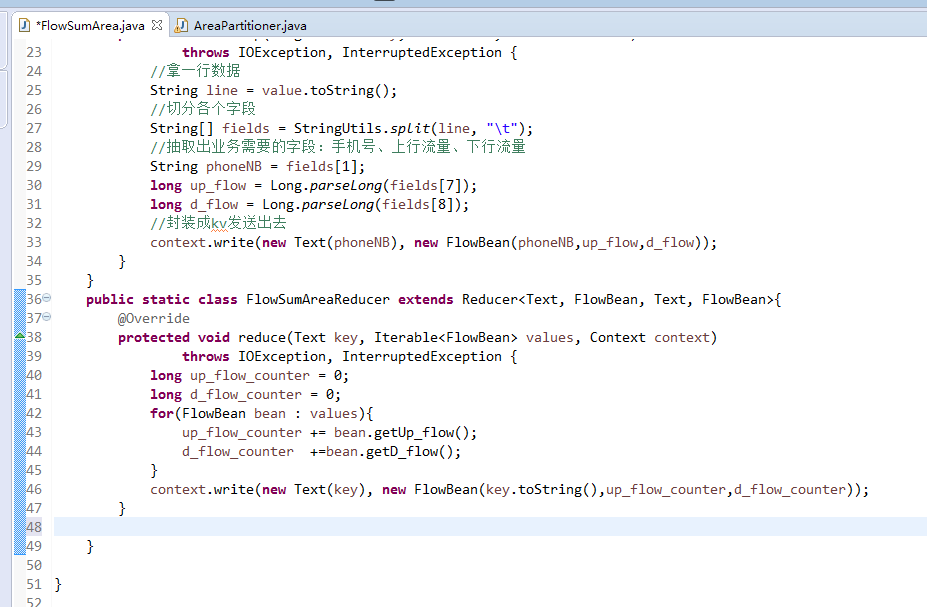
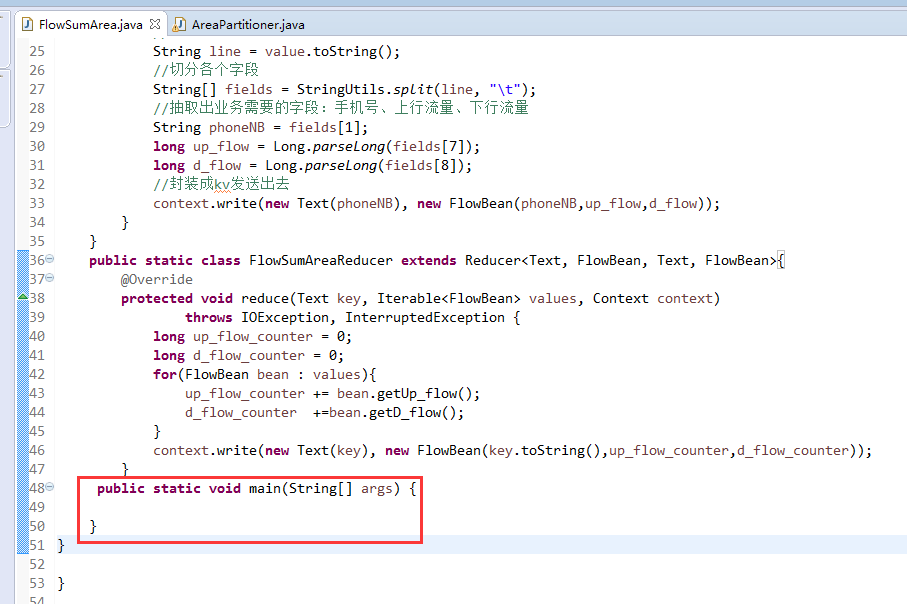
以上是weekend110的mr程序中自定义分组的实现
2 weekend110的hadoop的自定义排序实现 + mr程序中自定义分组的实现的更多相关文章
- 在.net桌面程序中自定义鼠标光标
有的时候,一个自定义的鼠标光标能给你的程序增色不少.本文这里介绍一下如何在.net桌面程序中自定义鼠标光标.由于.net的桌面程序分为WinForm和WPF两种,这里分别介绍一下. WinForm程序 ...
- 微信小程序中自定义modal
微信小程序中自定义modal .wxml <modal hidden="{{hidden}}" title="这里是title" confirm-text ...
- Hadoop MapReduce概念学习系列之mr程序组件全貌(二十)
其实啊,spilt是,控制Apache Hadoop Mapreduce的map并发任务数,详细见http://www.cnblogs.com/zlslch/p/5713652.html map,是m ...
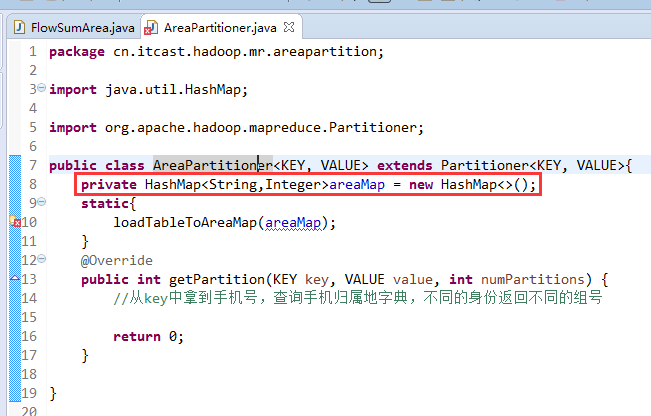
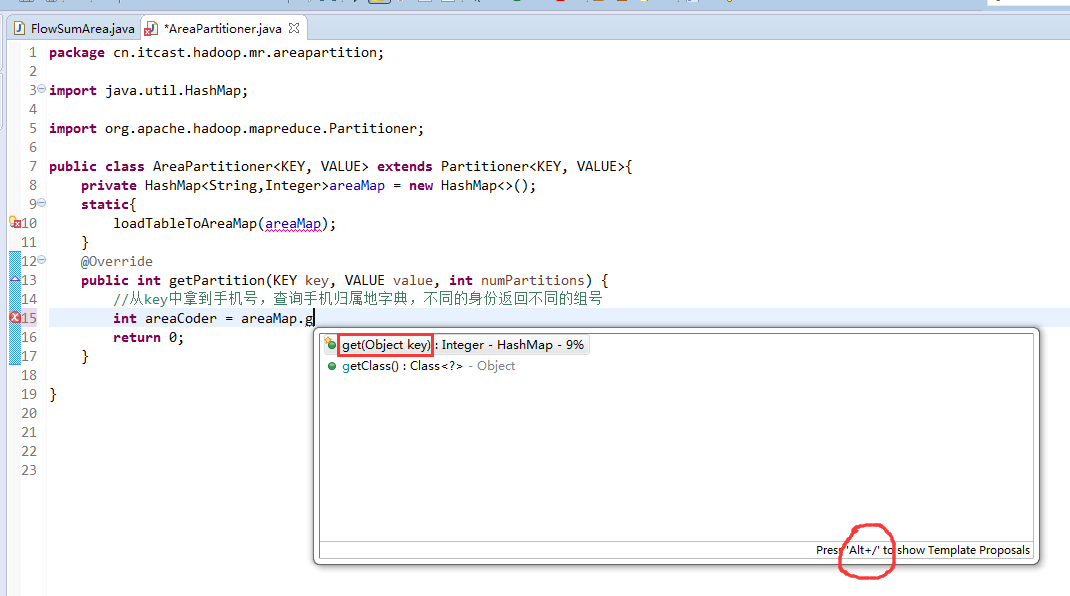
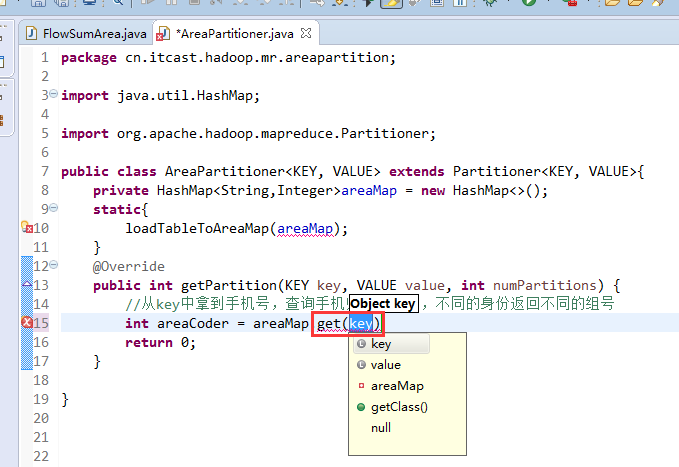
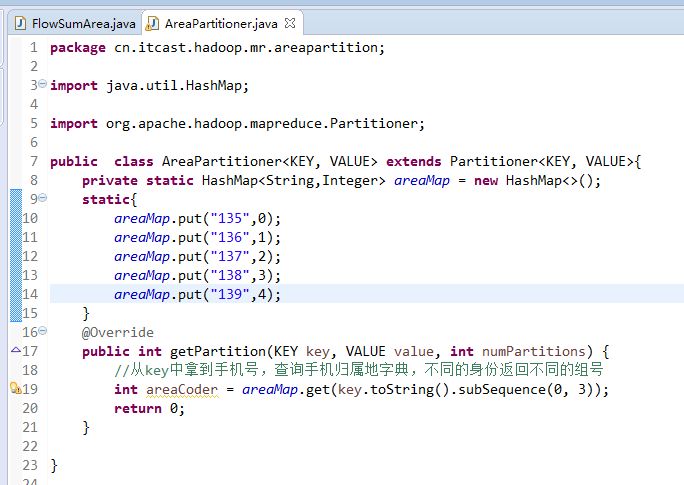
- 一脸懵逼学习Hadoop中的MapReduce程序中自定义分组的实现
1:首先搞好实体类对象: write 是把每个对象序列化到输出流,readFields是把输入流字节反序列化,实现WritableComparable,Java值对象的比较:一般需要重写toStrin ...
- Cognos开发自定义排序规则的报表和自定义排名报表
场景:有一个简单的销售数据分析,可以按照日期,按照商品类型来分析订单笔数和订单金额. 目的:用户可以自定义查看按照不同指标排序的数据,用户可以查看按照不同指标排名的前N名数据 一:功能及效果展示 效果 ...
- 微信小程序中自定义swiper轮播图面板指示点的样式
重置样式: .swiper{ width: 100%; height: 240px; margin-bottom: 0.5rem; position:relative; } div.wx-swiper ...
- Hadoop MapReduce概念学习系列之mr程序详谈(二十三)
这个暂时,没写好. K1,v1 这是增强的for循环. for(Sting w : words) { } 迭代器里,前面,放的是什么类型,后面,迭代的是谁.
- 微信小程序中自定义函数的学习使用
新手,最近在给学校搞个党费计算器.需要自己定义函数来实现某个功能. 1.无参函数: 函数都是写在js文件里面的. Page({ data:{ income1:'0', }, cal:function( ...
- Combox程序中自定义数据源
有combox控件,命名为cbxPutStatus,在程序中为其手工定义数据源,并绑定 private void POrderSplitFrm_Load(object sender, EventArg ...
随机推荐
- Java基础巩固----泛型
注:参考书籍:Java语言程序设计.本篇文章为读书笔记,供大家参考学习使用 1.使用泛型的主要优点是能够在编译时而不是在运行时检查出错误,提高了代码的安全性和可读性,同时也提高了代码的复用性. 1.1 ...
- overflow:hidden真的失效了吗
项目中常常有同学遇到这样的问题,现象是给元素设置了overflow:hidden,但超出容器的部分并没有被隐藏,难道是设置的hidden失效了吗? 其实看似不合理的现象背后都会有其合理的解释. 我们知 ...
- GitHub使用教程for Eclipse
1.下载egit插件http://www.eclipse.org/egit/ http://www.eclipse.org/egit/download/ Installing the Latest R ...
- linq any()方法实现sql in()方法的效果
public IQueryable<Vsec009ComSecComp> QueryList(Sec009ComSecCompQueryCondition condition) { var ...
- 使用自定义《UIActivity》进行内容分享-b
简介 这段时间有很多朋友都问我关于怎么去集成ShareSDK或者友盟社会化分享SDK的问题, 其实我想说, Apple一开始就提供了一个类, 供我们去使用分享了, 在iOS 6之后更加增强了这个类, ...
- C与OC、C++的区别
C语言的特点:1)C语言是结构化语言,层次清晰,调试和维护比较容易2)表现能力和处理能力比较强,可直接访问内存的物理地址3)c语言实现对硬件的编辑,c语言课用语系统软件的开发,也可用语应用软件的开发, ...
- EXCEL : We can't do that to a merged cell.
- [转]如何根据cpu的processor数来确定程序的并发线程数量
原文:http://blog.csdn.net/kirayuan/article/details/6321967 我们可以在cat 里面发现processor数量,这里的processor可以理解为逻 ...
- matplotlib 显示中文
# --*-- coding: utf-8 --*-- from matplotlib.font_manager import FontProperties import matplotlib.pyp ...
- const char*, char const*, char*const的区别
http://www.cnblogs.com/aduck/articles/2244884.html