------- Tor 源码分析第三部分—— 日志设施与智能链表 --------
————————————————————————————————————————————————————————————————————————————————————
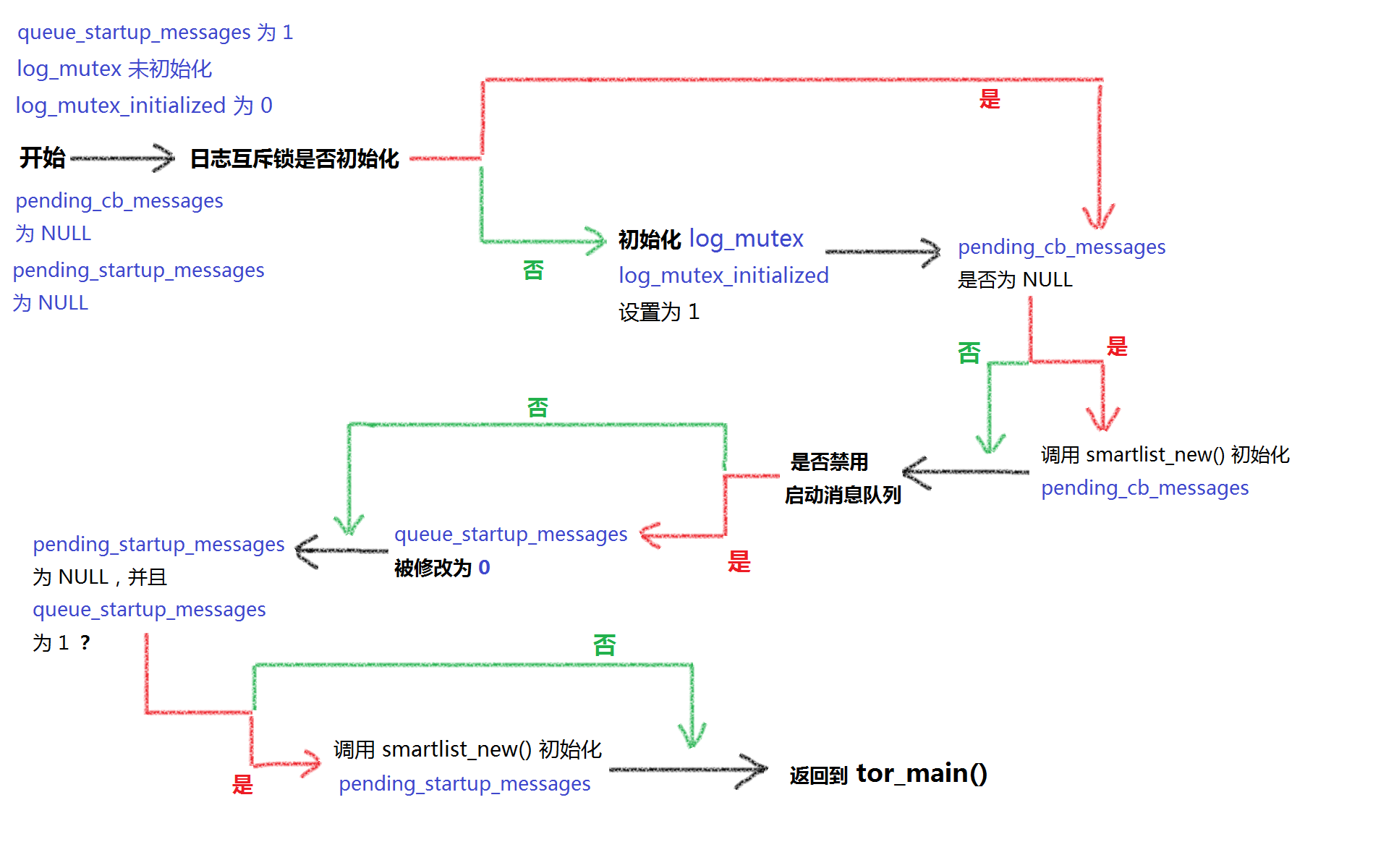
init_logging()(\tor-0.3.1.8\src\common\log.c)内部逻辑如下图所示:

它的任务是初始化 tor 使用的全局日志设施;它首先检测并初始化用于保护日志信息和日志文件的互斥锁(log_mutex),它是一个 tor_mutex_t 对象
—— 请复习前一篇的相关讨论——具体方式为:
判断相同源文件内的全局变量 log_mutex_initialized 的值—— 0 代表日志互斥锁尚未初始化,那么它就调用 tor_mutex_init()
;显然,实际负责初始化 log_mutex 的是 pthread 库例程 pthread_mutex_init() 、并且把状态标记 log_mutex_initialized 置 1 。
涉及到的全局变量如下图:

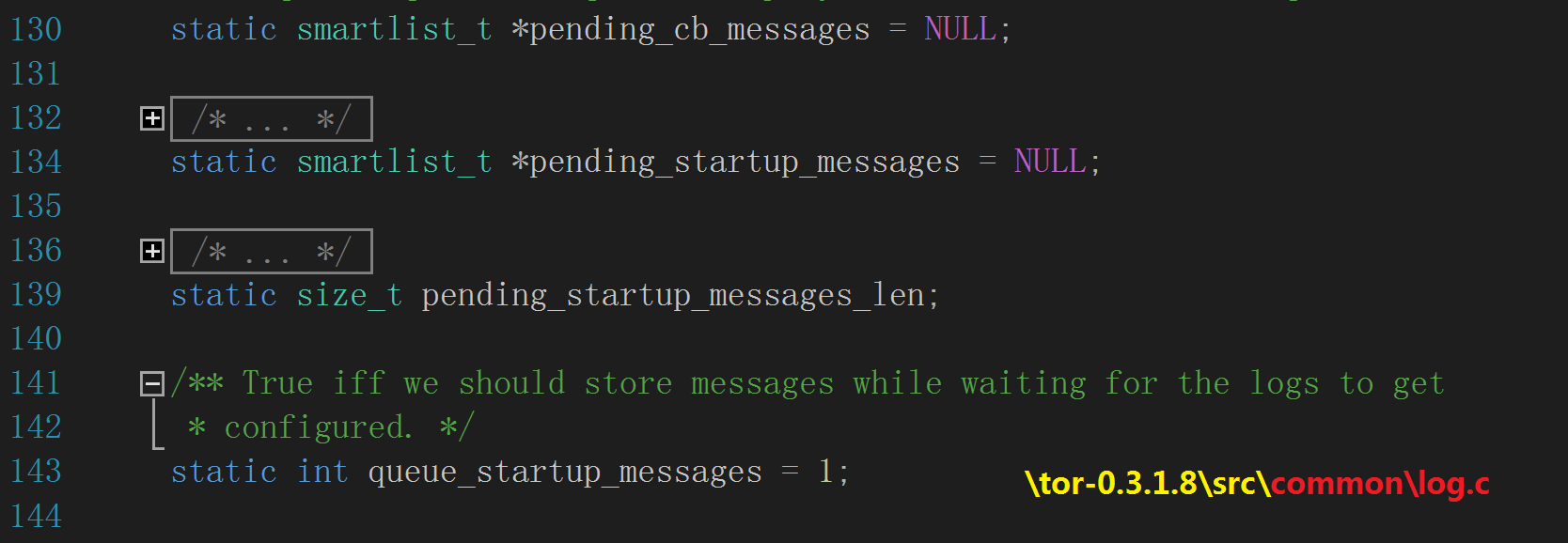
接下来,它检查一枚全局的 smartlist_t 指针—— pending_cb_messages(基于 CallBack 的日志消息队列)——若该指针为 NULL 则
调用 smartlist_new()(\tor-0.3.1.8\src\common\container.c)来初始化它。
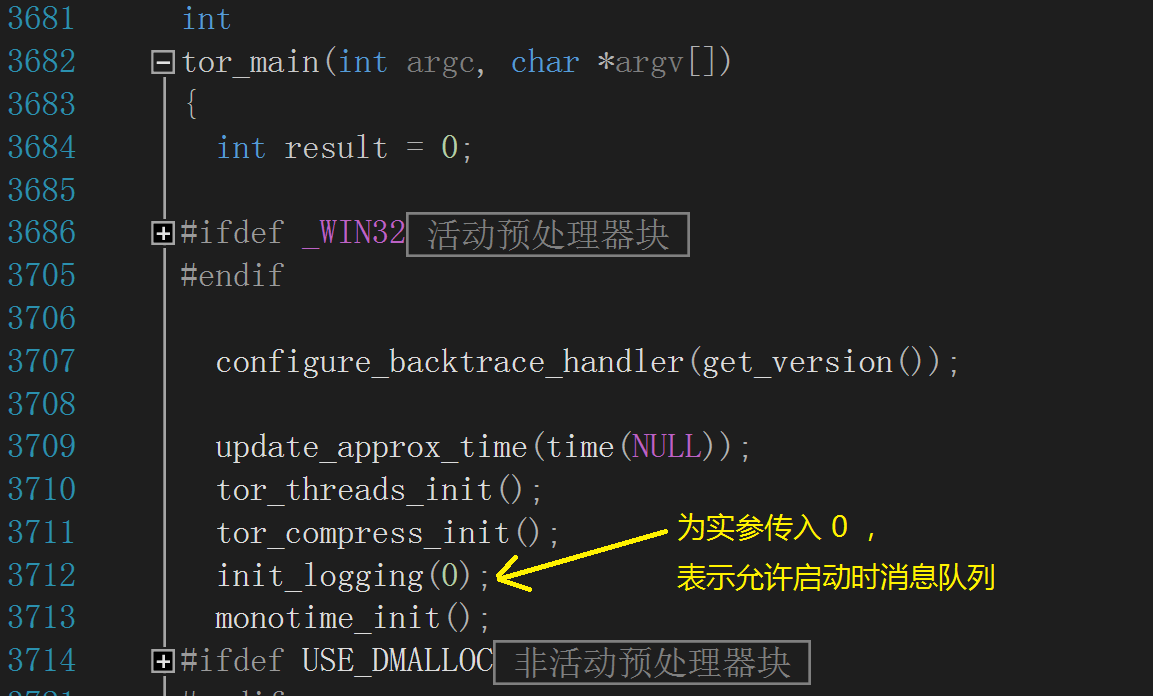
然后检查传入的实参——若为 1,表明禁用启动消息队列,它就把全局变量 queue_startup_messages 修改为 0,意味着在等待配置日志的过程中不保
存消息;事实上,tor_main() 中为该实参传入 0 指示消息应该在早期就记录下来,如下图:
这种情况下,它再次调用 smartlist_new()来分配构建一个 smartlist_t 结构指针并赋给全局变量 pending_startup_messages,用于
处理启动时刻日志消息队列。pending_startup_messages 指向的各类启动消息(待输出)会在日志系统初始化完毕后重新播放出来。
涉及到的全局变量如下图:
如果你已经头晕了,那么我们就梳理一下目前为止讨论到全局变量和用途吧:
log_mutex—— 保护日志文件和消息的互斥锁;
log_mutex_initialized—— log_mutex 是否初始化;
pending_cb_messages—— 一枚 smartlist_t 指针(smartlist_t*),存储基于 CallBack 的日志消息队列,可用 smartlist_new() 初始化它;
pending_startup_messages—— 一枚 smartlist_t 指针,存储启动时刻日志消息队列,可用 smartlist_new() 初始化它;
queue_startup_messages—— 启动时刻是否记录日志消息;
disable_startup_queue—— init_logging() 的形参,调用者借助它来开启或关闭启动时刻消息队列功能;
init_logging() 内部逻辑如下图所示:
tor 实现了一种容量可调整、可存储任意数据类型的智能链表——smartlist,它由结构体 smartlist_t
(\tor-0.3.1.8\src\common\container.h)来表示。“container”亦即容器,该模块抽象了许多数据结构来当成容器,
smartlist 只是其中之一。
smartlist_t 内有一个指针数组(list),每个元素(void*)可以指向任意类型的数据,且元素数量可调整,这就是它叫智能链表的原因
,如下图:
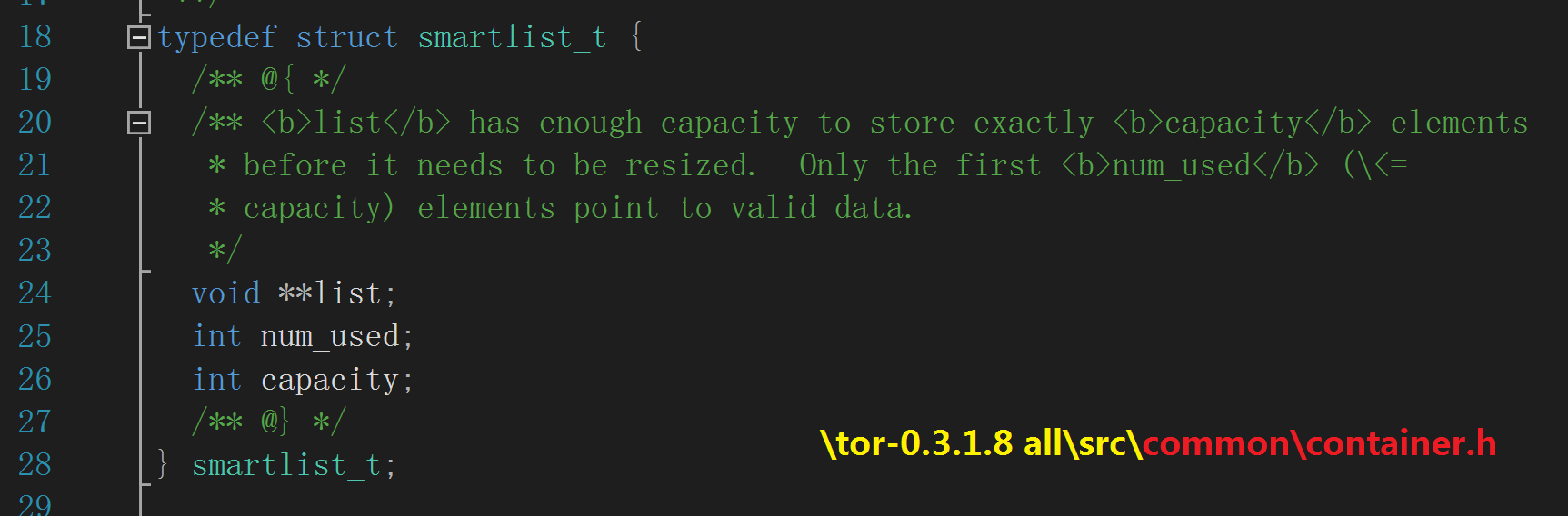
注释里写得很清楚:list 数组的大小可调整,调整后需要更新 capacity 字段(当前容量上限);
num_used 字段记录当前元素数,这些元素(void*)指向有效的数据。你需要意识到一点—— 在 num_used 小于等于 capacity 时,
list 的大小不变;num_used 大于 capacity 时,list 就会动态扩展,同时更新 num_used 和 capacity。
对 smartlist_t 的操作由一些精心编写的例程实施,它们都以 smartlist_ 为前缀,其它模块函数无需知晓智能链表的内部细节,
只需调用这些例程来保证安全、正确地使用智能链表即可,这再次体现出数据抽象和封装、以及接口暴露。。。等高级 C 编程技巧!
这些 smartlist 例程原型如下图所示,分析它们的内部逻辑有助于深入理解智能链表的设计思想:
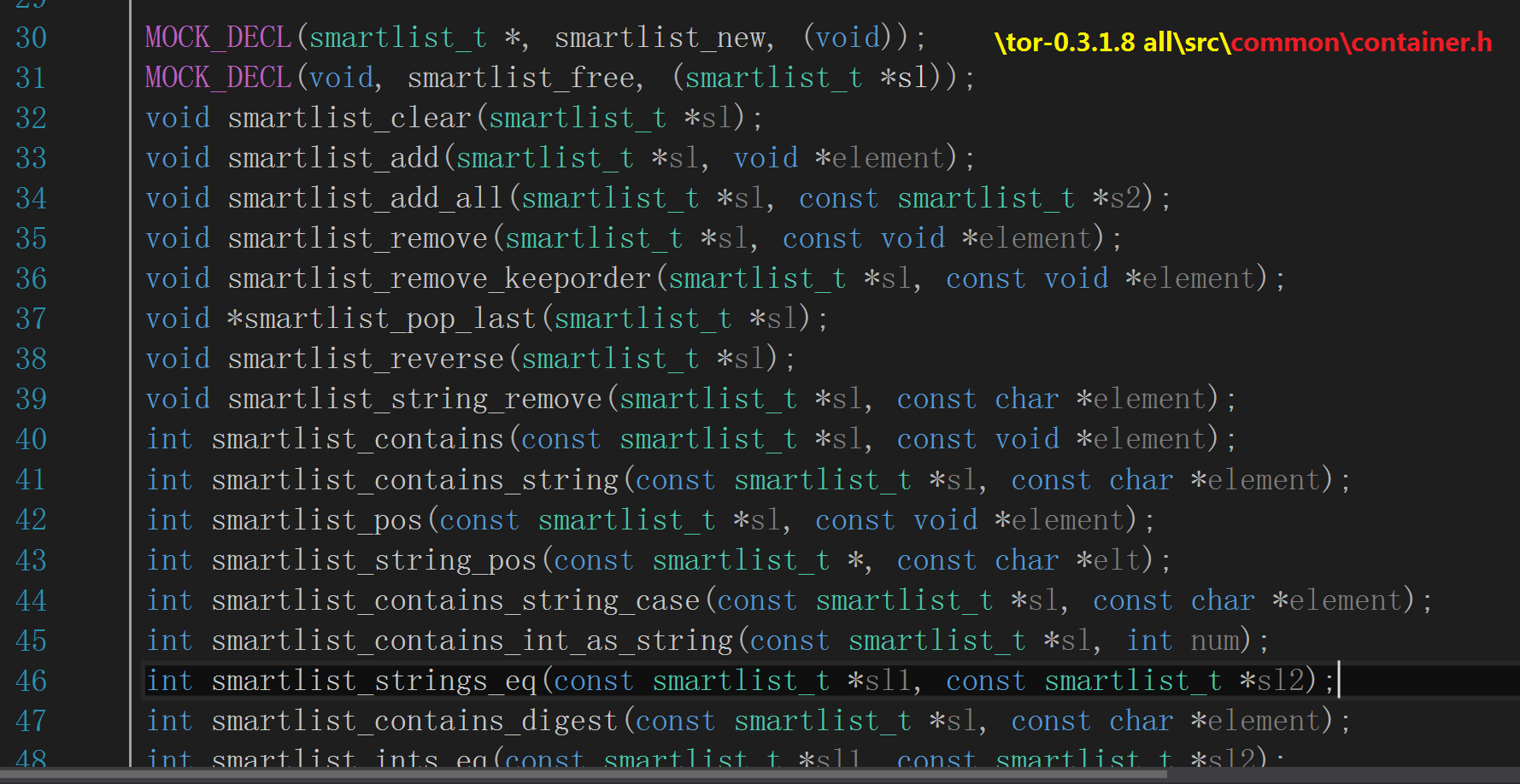
smartlist_new() 在堆中分配一块内存用于 smartlist_t 结构,然后返回一枚指向该内存块的指针,如下图所示:
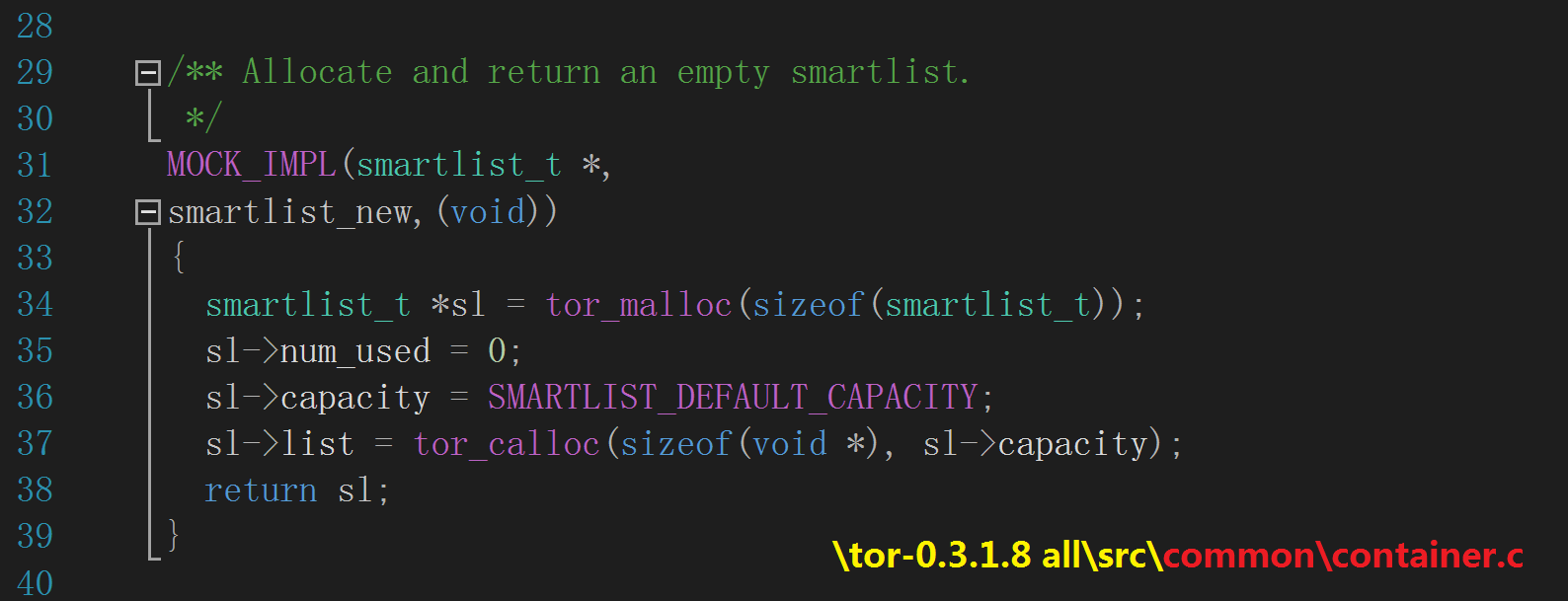
可以看到,实际的分配函数是 tor_malloc(),后者封装了系统库函数 malloc(),并实现 tor 自己的安全分配算法;分配的内存大小
亦即结构体 smartlist_t 的大小(应该是 12 字节),该值在编译阶段计算出来。在返回一枚 smartlist_t 指针前,它还会将 num_used 字段设置为零,
表示尚未加入元素;将 capacity 字段设置为 SMARTLIST_DEFAULT_CAPACITY 宏定义的常量值(16),表示初始的容量上限为 16 枚
void 指针(总大小为 16 * 4 = 64 字节);接下来它就会调用 tor_calloc() 实际分配另一块 64 字节大小的堆内存,用于
存储那些 void 指针,并让 list 字段持有该内存块的地址。smartlist_new() 返回后的堆内存布局如下图所示:
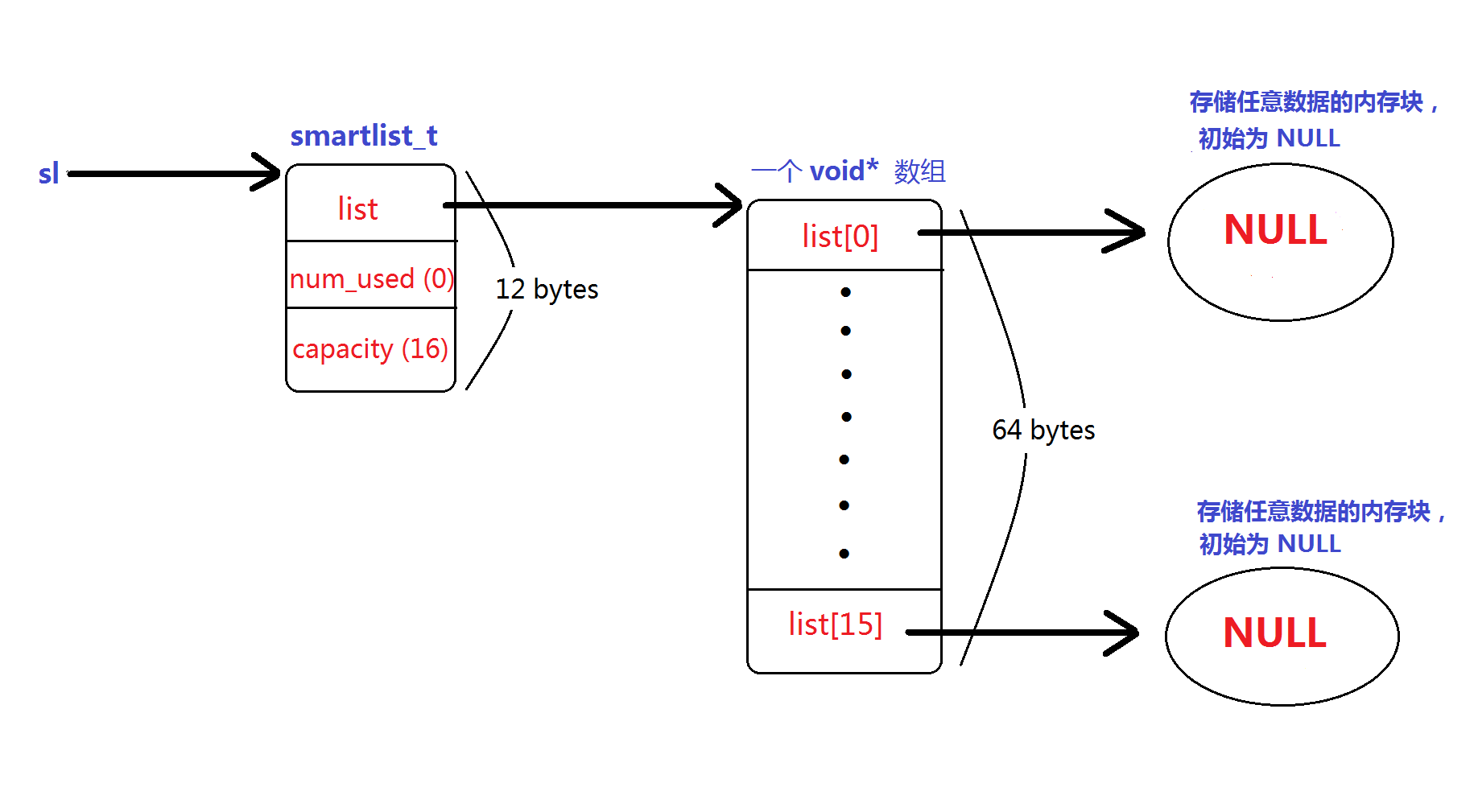
我在后面分析其它 smartlist_*() 辅助例程时,会将此图扩展以解释它们的作用。
smartlist_free() 销毁一个智能链表,但它并未实际释放堆中分配的 smartlist_t 结构与 void* 数组占据的内存,如下图:
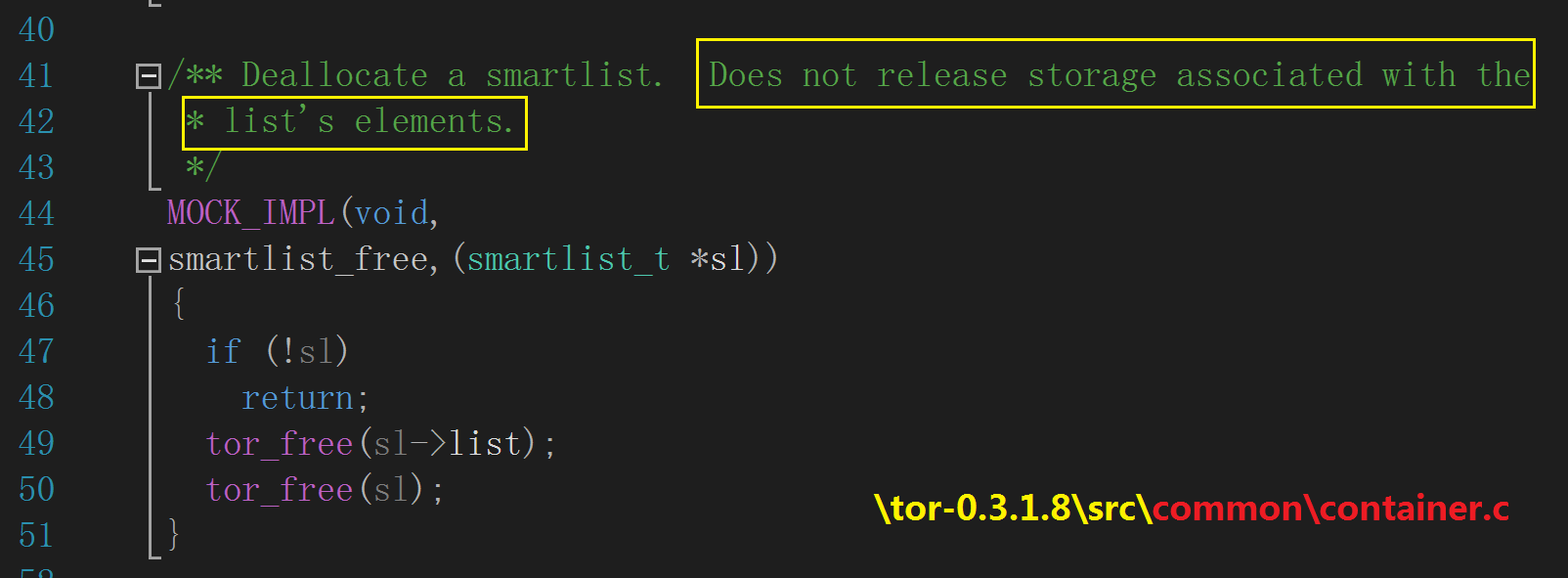
smartlist_free() 通过调用 tor_free() -> raw_free() -> free() 把传入的 smartlist_t 指针置 NULL 后返回,因此它不会回收
相关的堆内存,如下图所示:
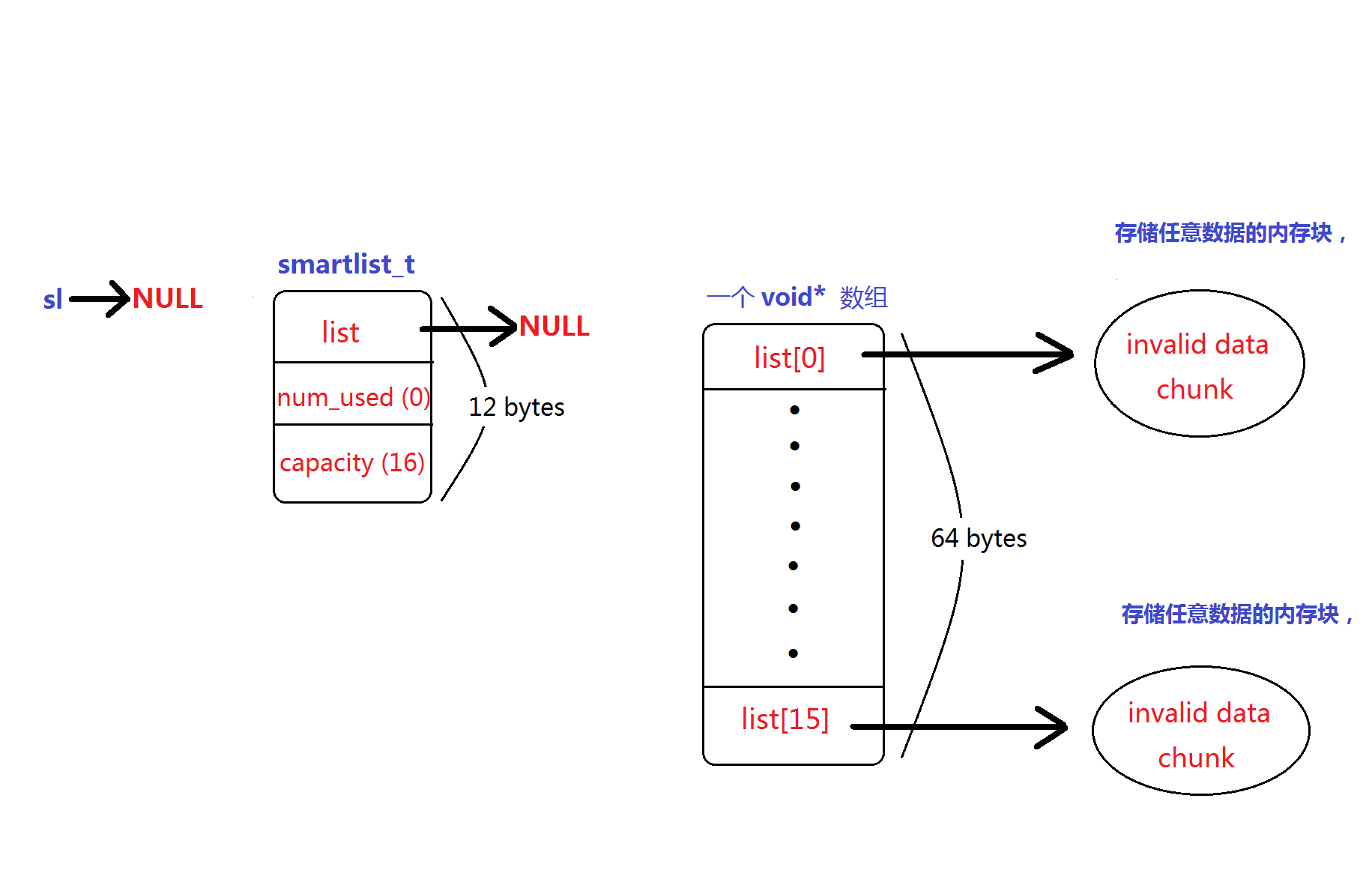
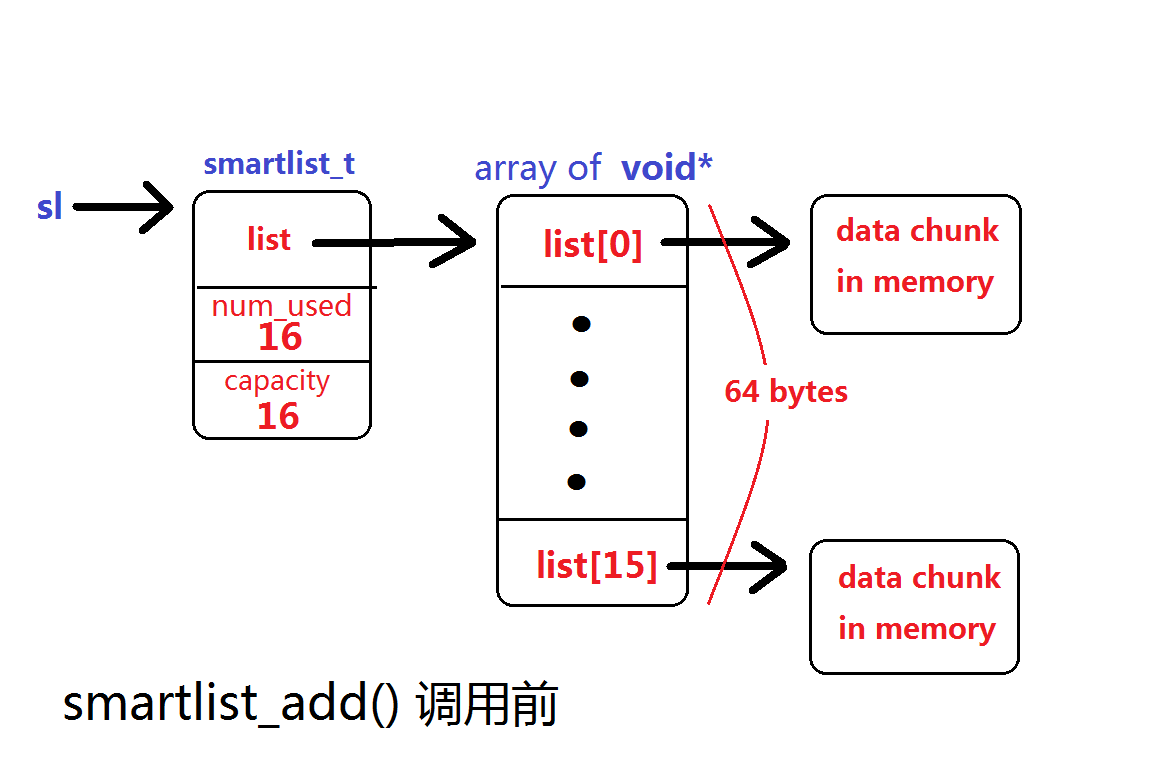
smartlist_add() 往智能链表(void* 数组)内加入新元素。
它首先调用 smartlist_ensure_capacity(),检查当前的容量上限是否允许加入,否则会先动态调大这个 void* 数组的容量后再把新元素
追加到尾部。如下图所示:

注意,它在调用 smartlist_ensure_capacity() 的同时就会通过一枚 smartlist_t 指针递增 num_used 字段值(寓意追加后的
元素数),然后在 smartlist_ensure_capacity() 内部会检查追加后的元素数是否超出当前容量上限,并采取相应措施!
smartlist_ensure_capacity() 处理完毕后,就可以确保作为数组下标的表达式 sl->list[sl->num_used++] 访问到的目标元素在
许可范围内,它被初始化为一枚新的 void 指针,语法解析如下图所示:

假设当前元素数已达初始上限(num_used = capacity = 16),相关的堆内存智能链表布局如下图:
执行 smartlist_add() 调用后的堆内存智能链表布局如下图:
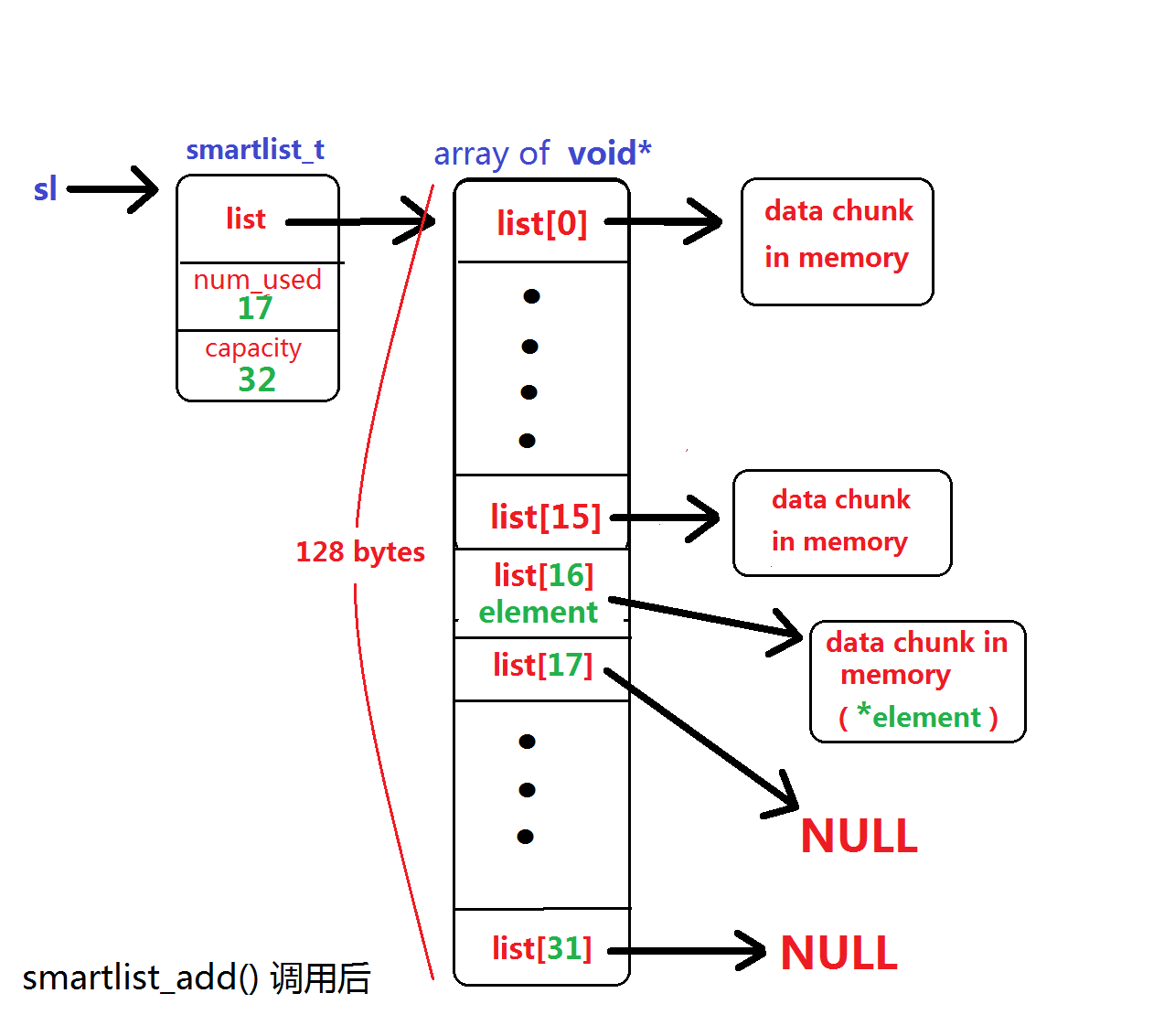
由此可见,smartlist_ensure_capacity() 会按照 2 次幂来扩展 void* 数组的当前容量上限,而 smartlist_add() 在扩展部分
的起始地址处追加元素,扩展部分的其余元素为 NULL,留待后续使用。
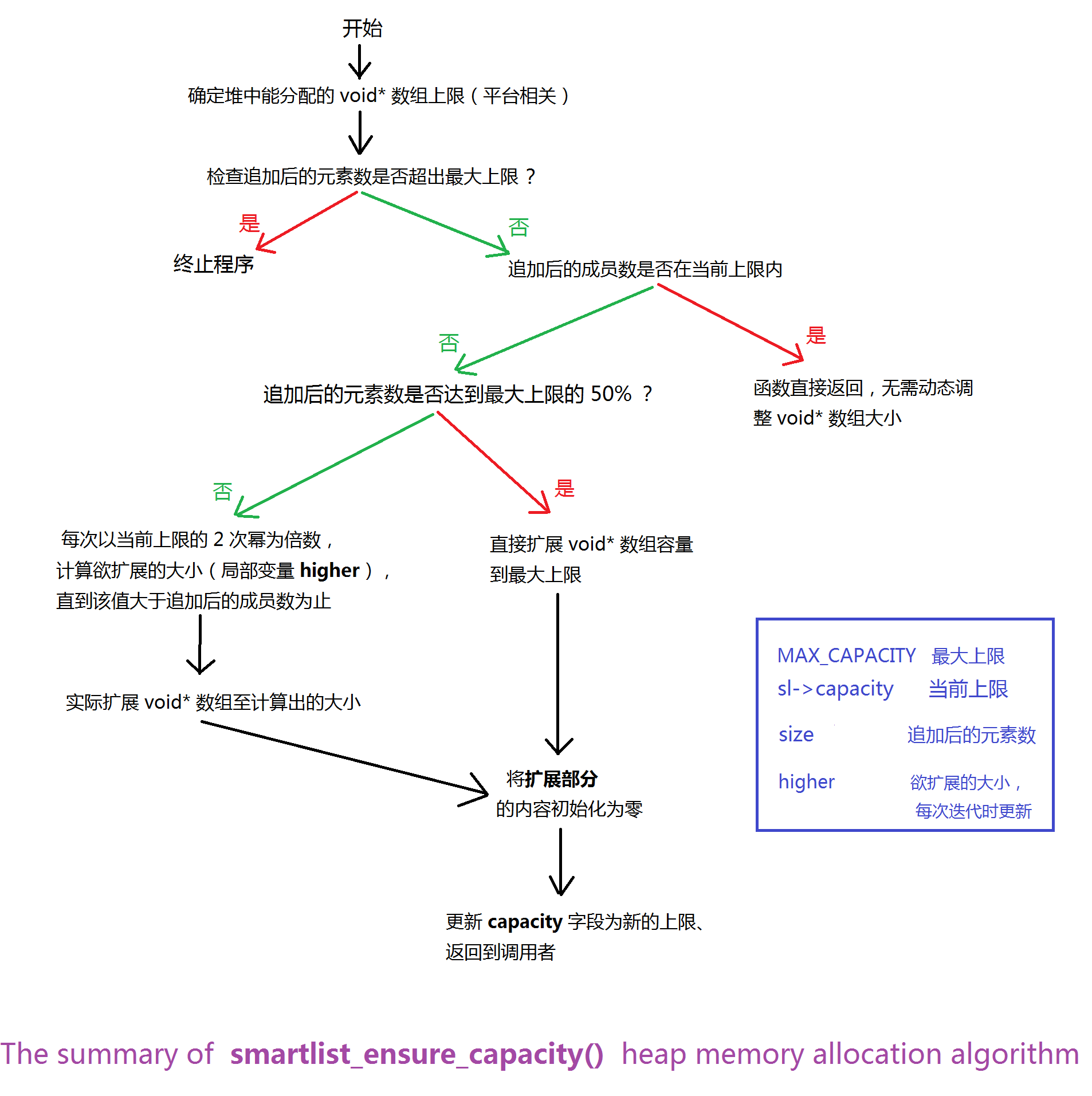
现在让我们深入 smartlist_ensure_capacity() 内部研究它的堆内存分配算法,这种每次以 2 的幂扩展的机制在某种程度上类似于
OS 的内核内存分配算法简化版!如下图所示:
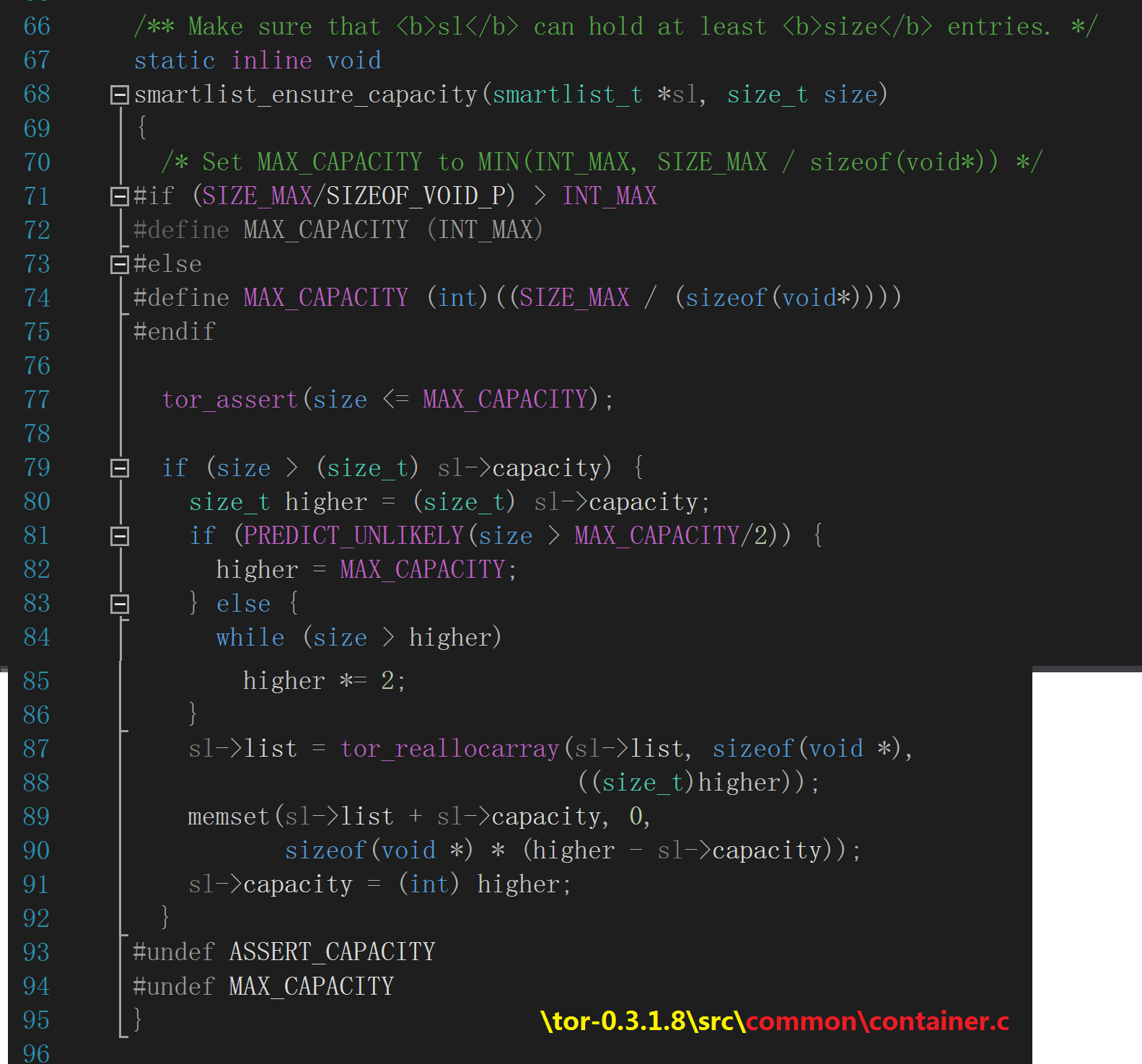
smartlist_ensure_capacity() 逻辑要点:
① 它是一个内联(inline)例程,这意味着在编译阶段,编译器会直接将其插入到调用者函数的内部,换言之,当我们反汇编
smartlist_add() 时,不会看到类似“call smartlist_ensure_capacity”这种指令,因为后者的逻辑已经被硬编码至前者内部,
这能够减少函数调用、返回时的栈帧创建、销毁等性能开销!
② 它的第二个参数类型为 size_t(亦即 unsigned int),这是一种安全表示长度、大小的类型(无负值),如前所述,
smartlist_add() 会为该参数传入递增 1 后的值,而 smartlist_ensure_capacity() 会判断这个更新的值是否超出了 void* 数组
的当前上限;
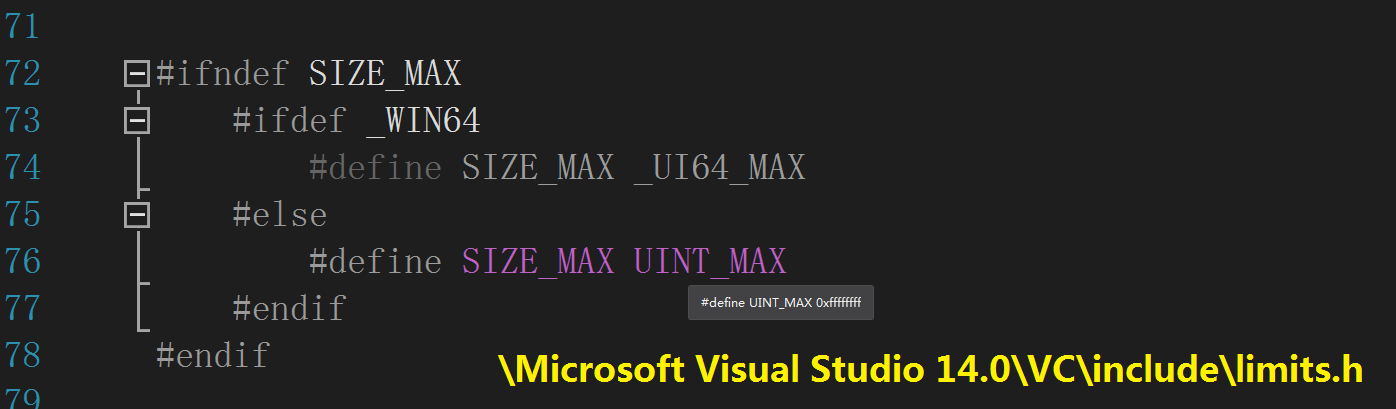
③ 开头部分的一些条件编译块计算 OS/硬件平台支持的 void* 数组最大上限—— SIZE_MAX 定义在平台相关的 limits.h 头文件内,
如下图所示,该头文件位于 Visual Studio 安装目录的 include 子路径下,它的值取决于编译器,比如这里的 0xFFFFFFFF,
就是十进制的 4,294,967,295 ;同理,INT_MAX 的值计算为 2,147,483,647 ;
SIZEOF_VOID_P 的值在 32 位平台上为 4。
经过一系列的预计算,最终得出 MAX_CAPACITY(表示 void* 数组的最大上限,以“元素数”为单位)的值为
1,073,741,823 个元素(SIZE_MAX / (sizeof(void*)),也就是说,void* 数组最大到 4 GB。
④ 用到了 tor_assert() 检查追加后的元素数,当超过最大容量上限时,调用库函数 abort() 终止程序运行;
tor_assert() 在前一篇讲过了。
⑤ 如果追加后的元素数在当前容量上限许可内,smartlist_ensure_capacity() 直接返回,不做任何事,它的调用者
可以安心执行后续操作;如果追加后的元素数超出当前上限,则每次按照 2 的幂为倍数增大当前上限,直到能够容纳
追加后的元素数,并且将扩展部分的内存初始化为零,以供后续使用、还要更新 capacity 字段为新的上限。
在分析源码的算法时,往往言词描述显得苍白无力,还是看看下面这张我绘制的 smartlist_ensure_capacity() 内部逻辑吧,
是不是有点 OS 内核内存分配器的影子?
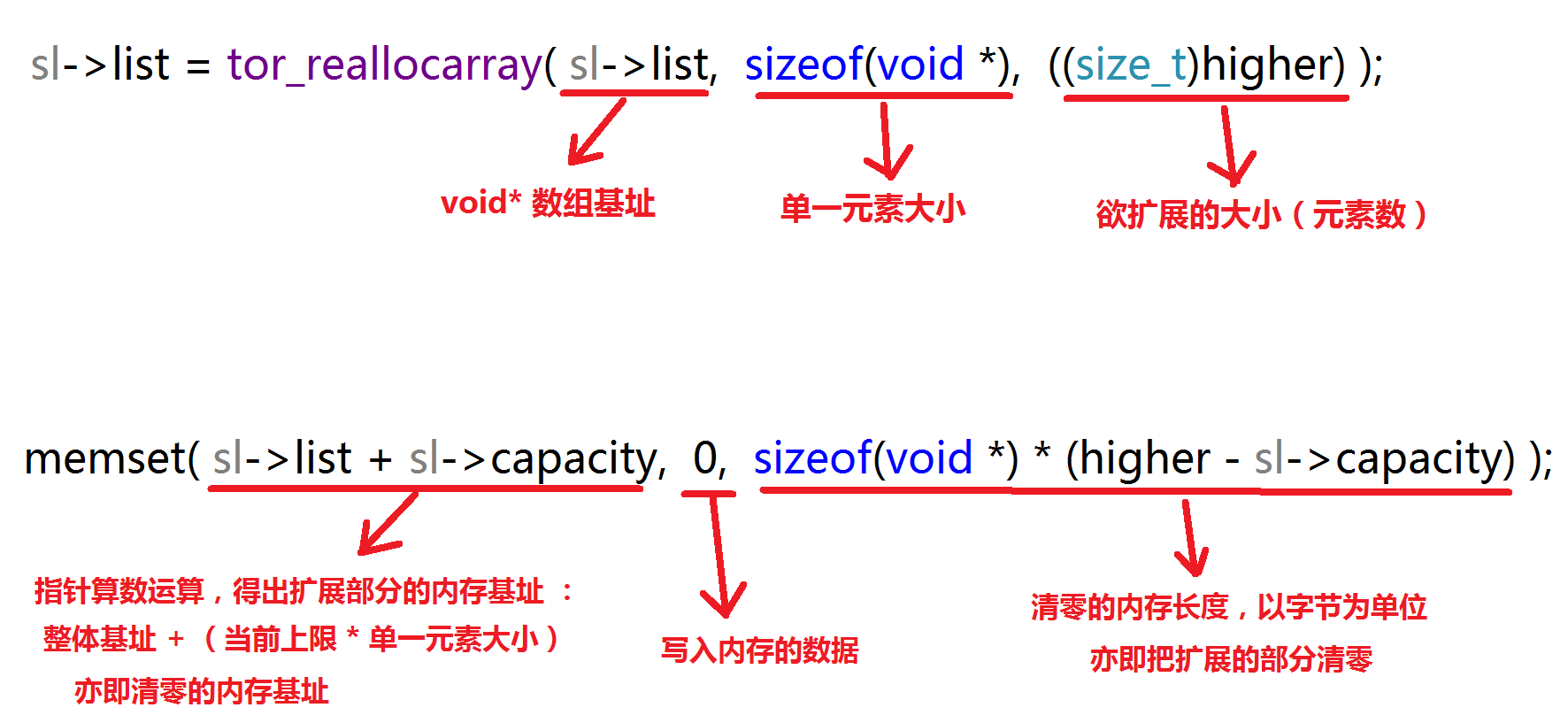
我们最后再分析一下 smartlist_ensure_capacity() 内部实际负责扩展内存的 tor_reallocarray(),
以及负责清零内存的 memset() 函数调用,作为对本篇的收场,如下图所示:
由此我们推测出 init_logging() 以及相关的组件使用 smartlist 来集中管理日志消息。
下一篇将分析第二个条件编译块前的函数调用——monotime_init()。
——————————————————————————————————————————————————————
------- Tor 源码分析第三部分—— 日志设施与智能链表 --------的更多相关文章
- 一个普通的 Zepto 源码分析(三) - event 模块
一个普通的 Zepto 源码分析(三) - event 模块 普通的路人,普通地瞧.分析时使用的是目前最新 1.2.0 版本. Zepto 可以由许多模块组成,默认包含的模块有 zepto 核心模块, ...
- Koa源码分析(三) -- middleware机制的实现
Abstract 本系列是关于Koa框架的文章,目前关注版本是Koa v1.主要分为以下几个方面: Koa源码分析(一) -- generator Koa源码分析(二) -- co的实现 Koa源码分 ...
- Spring MVC源码分析(三):SpringMVC的HandlerMapping和HandlerAdapter的体系结构设计与实现
概述在我的上一篇文章:Spring源码分析(三):DispatcherServlet的设计与实现中提到,DispatcherServlet在接收到客户端请求时,会遍历DispatcherServlet ...
- Backbone源码分析(三)
Backbone源码分析(一) Backbone源码分析(二) Backbone中主要的业务逻辑位于Model和Collection,上一篇介绍了Backbone中的Model,这篇文章中将主要探讨C ...
- 二维码扫描 zxing源码分析(三)result、history部分
前两个部分的地址是:ZXING源码分析(一)CAMERA部分 . zxing源码分析(二)decode部分 下面我们来看第三部分 result包下面有很多的类,其中的核心类是 com.google. ...
- Java集合源码分析(三)Vevtor和Stack
前言 前面写了一篇关于的是LinkedList的除了它的数据结构稍微有一点复杂之外,其他的都很好理解的.这一篇讲的可能大家在开发中很少去用到.但是有的时候也可能是会用到的! 注意在学习这一篇之前,需要 ...
- Spark RPC框架源码分析(三)Spark心跳机制分析
一.Spark心跳概述 前面两节中介绍了Spark RPC的基本知识,以及深入剖析了Spark RPC中一些源码的实现流程. 具体可以看这里: Spark RPC框架源码分析(二)运行时序 Spark ...
- mybatis源码分析(三)------------映射文件的解析
本篇文章主要讲解映射文件的解析过程 Mapper映射文件有哪几种配置方式呢?看下面的代码: <!-- 映射文件 --> <mappers> <!-- 通过resource ...
- Docker源码分析(三):Docker Daemon启动
1 前言 Docker诞生以来,便引领了轻量级虚拟化容器领域的技术热潮.在这一潮流下,Google.IBM.Redhat等业界翘楚纷纷加入Docker阵营.虽然目前Docker仍然主要基于Linux平 ...
随机推荐
- Docker mongodb 3.4 分片 一主 一副 一仲 鉴权集群部署.
非docker部署 为了避免过分冗余,并且在主节点挂了,还能顺利自动提升,所以加入仲裁节点 为什么要用docker部署,因为之前直接在虚拟机启动10个mongod 进程.多线程并发测试的时候,mong ...
- ActiveMq笔记3-AMQ高可用性理论
单点的ActiveMQ作为企业应用无法满足高可用和集群的需求,所以ActiveMQ提供了master-slave.broker cluster等多种部署方式,但通过分析多种部署方式之后我认为需要将两种 ...
- 【其他】3dmax撤销Ctrl+z不能用的解决办法
转载请注明出处:http://www.cnblogs.com/shamoyuu/p/3dmax_ctrlz.html 如果你经常去网上下载各种模型参考学习的话,出现这个问题的概率会非常高.因为出现这个 ...
- GAN︱生成模型学习笔记(运行机制、NLP结合难点、应用案例、相关Paper)
我对GAN"生成对抗网络"(Generative Adversarial Networks)的看法: 前几天在公开课听了新加坡国立大学[机器学习与视觉实验室]负责人冯佳时博士在[硬 ...
- R语言︱数据规范化、归一化
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 笔者寄语:规范化主要是因为数据受着单位的影响较 ...
- php中静态变量和静态方法。
在php类的内部当使用static进行修饰了类的属性或者方法,则改属性或者方法被成为类的静态属性或者静态访问, 静态属性和非静态属性的区别 php官方的解释 声明类成员或方法为static,就可以不实 ...
- com.mysql.jdbc.exceptions.jdbc4.MySQLSyntaxErrorException: Unknown database 'smvch'
1.错误描述 INFO:2015-05-01 14:20:44[main] - Initializing c3p0 pool... com.mchange.v2.c3p0.ComboPooledDat ...
- AHCI模式安装XP以及驱动下载
一.准备AHCI驱动 1.关于AHCI基础知识,请参考<AHCI模式的驱动下载.安装及蓝屏问题综合>一文. 2.安装AHCI驱动之前,请先确认桌面上.系统盘没有重要的东西需要备份,因为如果 ...
- Java并发 线程池
线程池技术就是事先创建一批线程,这批线程被放入到一个池子里,在没有请求到达服务端时候,这些线程都是处于待命状态,当请求到达时候,程序会从线程池里取出一个线程,这个线程处理到达的请求,请求处理完毕,该线 ...
- Nethogs - 网络流量监控工具
命令iftop来检查带宽使用情况.netstat用来查看接口统计报告.还有其他的一些工具Bandwidthd.Speedometer.Nethogs.Darkstat.jnettop.ifstat.i ...