SVM分类器实现实例
我正在做一个关于SVM的小项目,在我执行验证SVM训练后的模型的时候,得到的report分数总是很高,无论是召回率(查全率)、精准度、还是f1-score都很高:
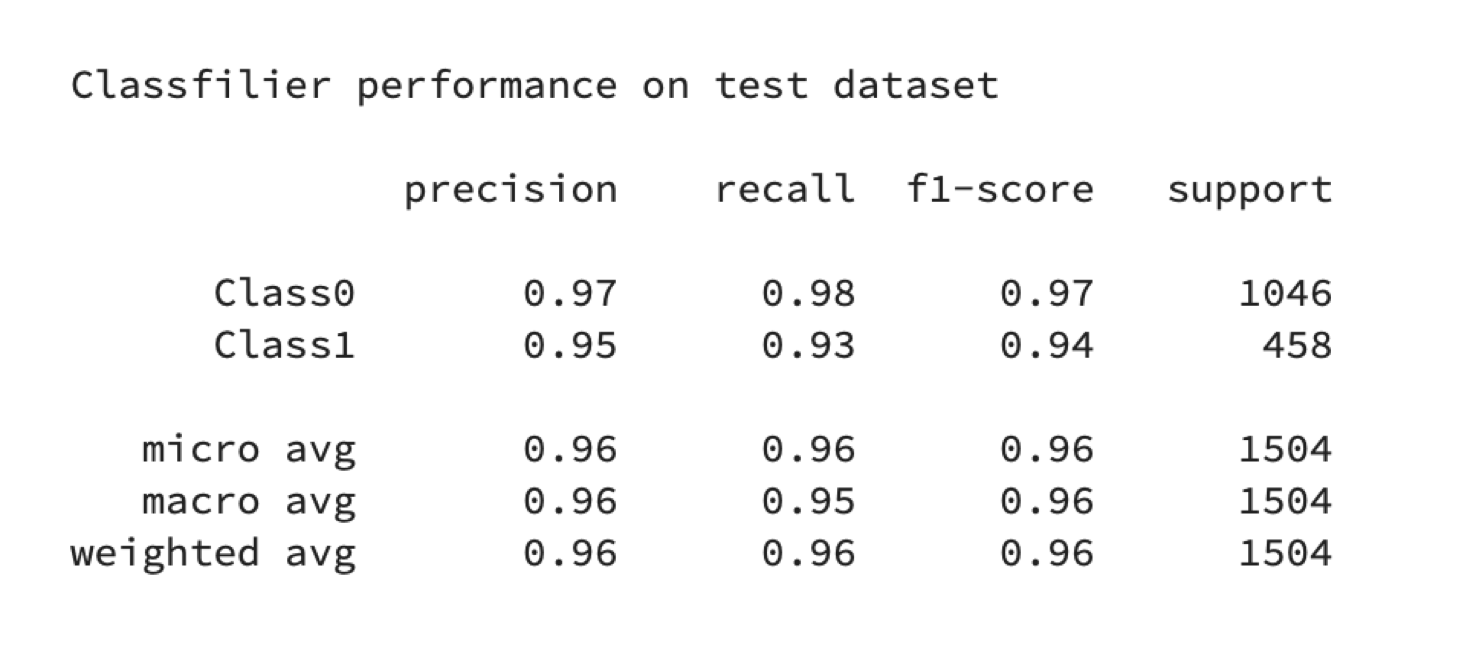
图1 分类器分数report
但是,对于训练的效果就非常差,差到连包含训练集的测试集都无法正确分类,如下图所示,左边是原图像,右边是分类图像,(我标注的标签样本是黄色区域与褐色区域),其中SVC的默认参数为rbf、C=1.0、gamma=“auto_deprecated”,LinearSVC的默认参数为:C=1.0、class_weight=none、dual=true、loss=“squard_hinge”:
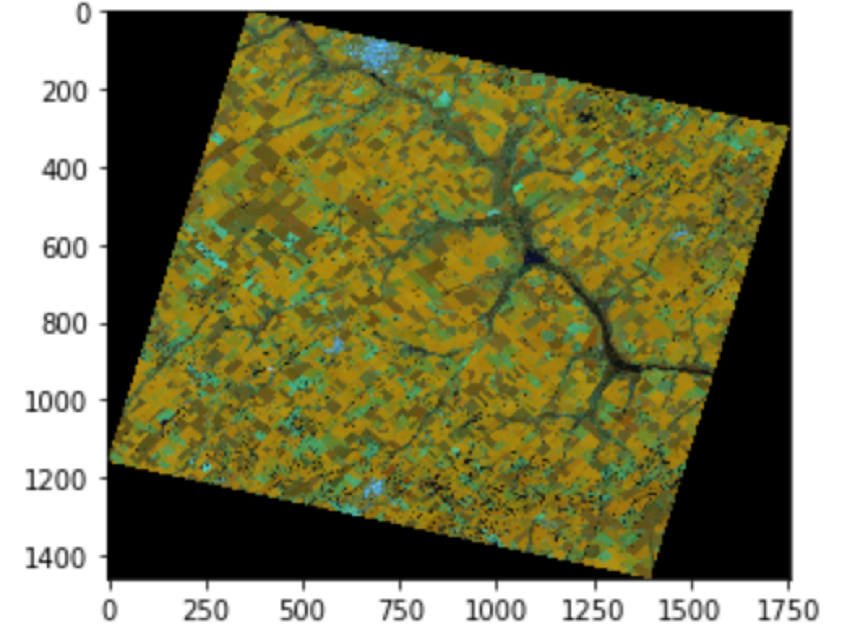
a.原图
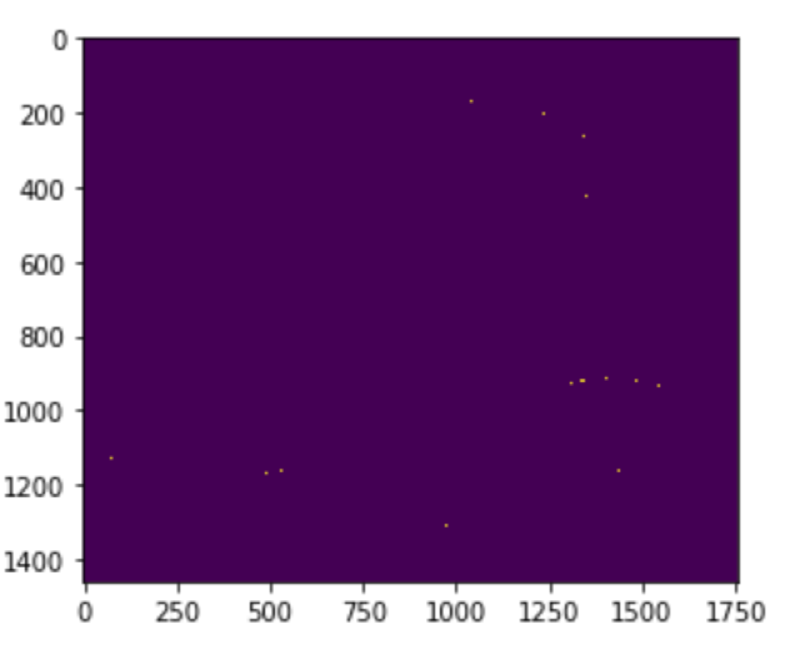
b.SVC(default parameter)
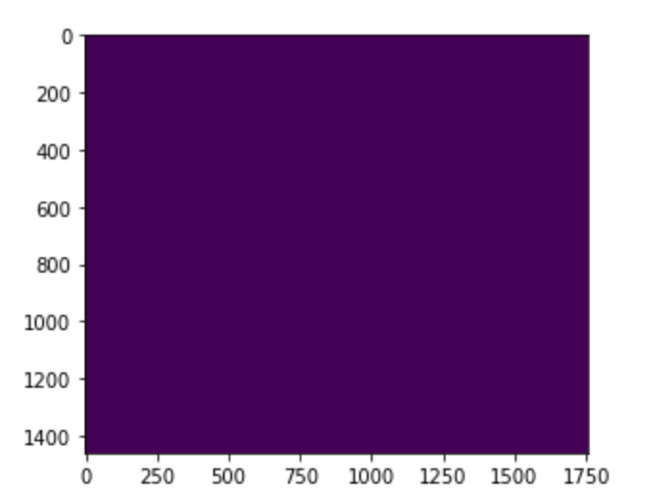
c.LinearSVC(default parameter)
图2. 默认分类效果
由上文可以发现,分类器分类的效果很不好,为了进一步验证这个问题的原因,接下来我分别对LinearSVC和SVC进行参数调整:
1、LinearSVC参数调整
C:使用损失函数是用来对样本的分类偏差进行描述,例如:
由上文可以发现,分类器分类的效果很不好,为了进一步验证这个问题的原因,接下来我分别对LinearSVC和SVC进行参数调整:
1、LinearSVC参数调整
C:使用损失函数是用来对样本的分类偏差进行描述,例如:
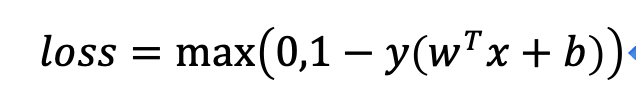
引入松弛变量后,优化问题可以写为:
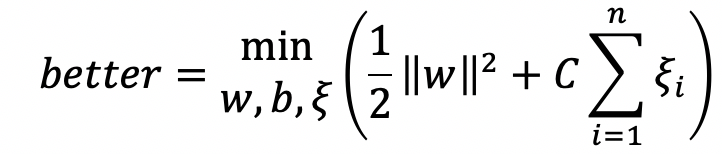
约束条件为:
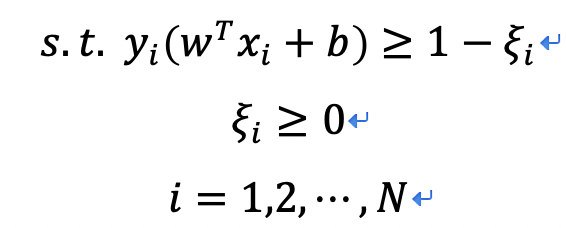

对于不同的C值对于本实例中的分类影响为,如图3所示:
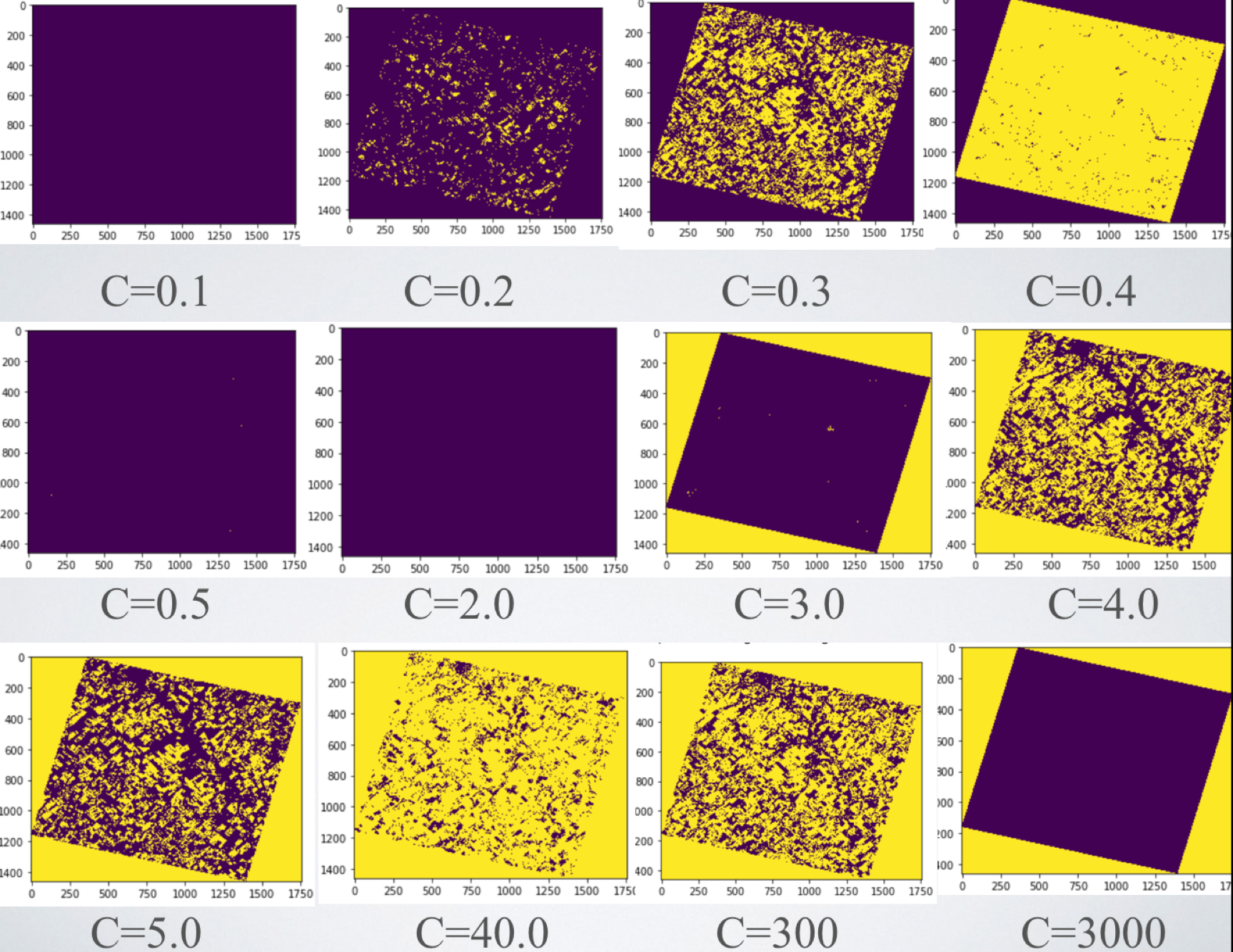
图3. LinearSVC在不同惩罚系数C下的表现
由此可以看出SVC在惩罚系数为0.3、4.0、300时能够较准确根据颜色对图像进行分类。但是作者发现,惩罚系数相同,重新训练时,会有不同的效果展示,才疏学浅,尚未能解释,如果有知道为什么的大神,敬请指点迷津。
2、SVC参数调整
SVC模型中有两个非常重要的参数,即C与gamma,其中C是惩罚系数,这里的惩罚系数同LinearSVC中的惩罚系数意义相同,表示对误差的宽容度,C越高,说明越是不能容忍误差的出现,C越小,表示越容易欠拟合,泛化能力变差。而另一个非常重要的参数gamma,是在选择RBF函数作为核函数后,才出现的,这个也是LinearSVC中所不包含的。高斯函数RBF中的gamma值有一个自带的默认值:gamma='auto_deprecated';表示的是数据映射到新的特征空间后的分布,gamma值越大,支持向量就越少,gamma值越小,支持向量就越多。支持向量的个数影响训练与预测的速度。
RBF公式里面的sigma和gamma的关系为:
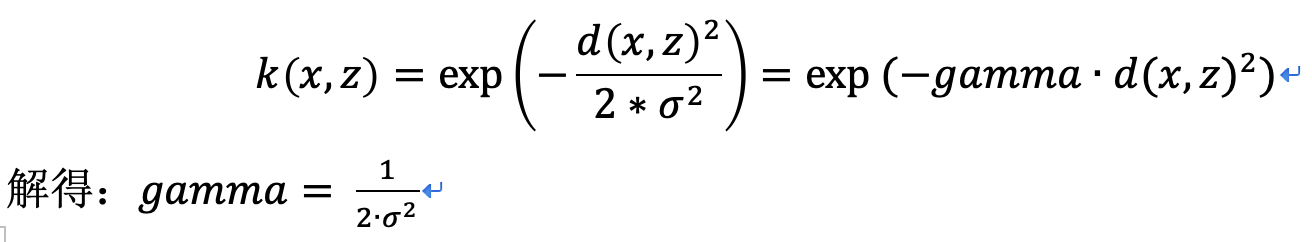
gamma的物理意义是关于RBF的幅宽,它可以影响每个支持向量对应的高斯的作用范围,进而影响分类器的泛化能力。在本例中我更改了多组c的值、gamma的值效果均是差之千里:
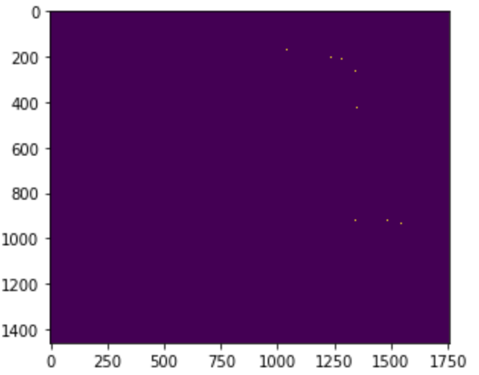
C=2、gamma=’auto’
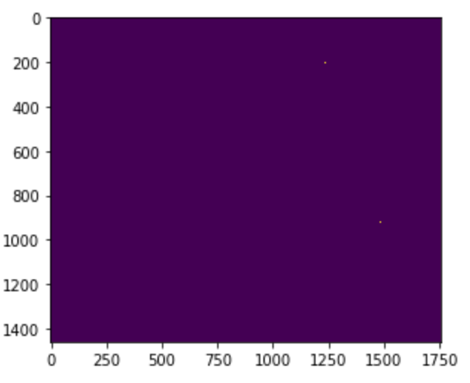
C=default、gamma=1
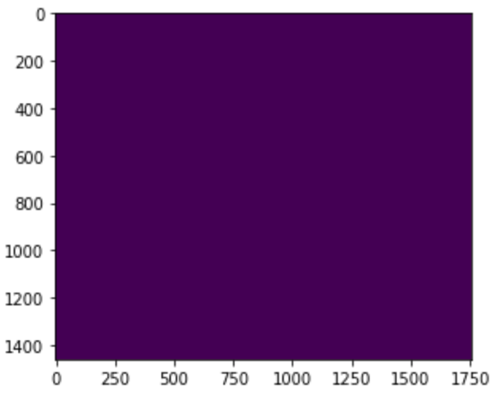
C=default、gamma=10
C=default、gamma=100
图4 SVC参数修改后分类效果
如此效果真的是让人头疼,不过有一点可以确定的是在样本海量的情况下,LinearSVC表现的要更好一些,算法执行时间很快,模型也较小,同样的样本下SVC用到的时间大概是LinearSVC的60倍左右。但是我们不能就此而已,我们要为问题寻找思路,这便转换成了一个寻优问题。
对于同时受到两个参数影响的调参问题,我们可以使用一些寻优算法,常用的寻优算法可分为两类:一类是在参数定义域空间内进行网格式搜索,例如专门针对SVC参数的GridSearch算法、交叉验证算法,这类算法虽然稳定性高、参数估计准确,但是算法时间复杂度较高,计算量较大;另一类是采用启发式优化,例如gaSVMForClass遗传算法参数寻优、psoSVMForClass粒子群优化算法参数寻优等,这类算法能够更快的寻找到最优参数组合。
本文先从GridSearch入手,毕竟它是sklearn模块中的子模块,导入方法也较简单:直接from sklearn.model_selection import GridSearchCV就ok。
GridSearch网格搜索是一种调参手段,它的基本原理是暴力求解,即尝试每一种可能性,将表现最好的认为是结果。使用的方法是穷举搜索,在所有的候选参数中,通过循环遍历,尝试每一种可能性。对于要调整两个参数c和g的高斯核函数来说,加入c的可能值有5种,g的可能值有6种,那么要遍历所有的c与g的组合参数值,就有5*6种可能,也就是可以列一个表格包含5列6行的表格,然后依次对表格内容进行遍历便可以实现遍历所有的30种可能了。
例如:遍历gamma在[0.001, 0.01, 0.1, 10, 100, 1000]范围,C在[0.001, 0.01, 0.1, 10, 100, 1000]范围内的最优值,便可以执行以下程序:
best_score = 0
for gamma in [0.001, 0.01, 0.1, 10, 100, 1000]:
for C in [0.001, 0.01, 0.1, 10, 100, 1000]:
svm = SVC(gamma=gamma, C=C)
svm.fit(X_train, y_train)
score = svm.score(X_test, y_test)
if score > best_score:
best_score = score
best_parameters = {'gamma':gamma, 'C':C}
print("best score:{:.2f}".format(best_score))
print("best parameters:{}".format(best_parameters))
最终结果便是:
best score:0.95
best parameters:{'gamma': 0.01, 'C': 10}
由此可以看出,其实这个GridSearch方法就是一个代替我们去进行尝试的machine,它无法自己寻求合理的c与gamma的取值范围,且比较耗时,你设置的C值和gamma值越多,寻优时间就会翻倍增加。另外我将这对最优组合放在实际预测中查看效果,效果也是不甚理想啊:
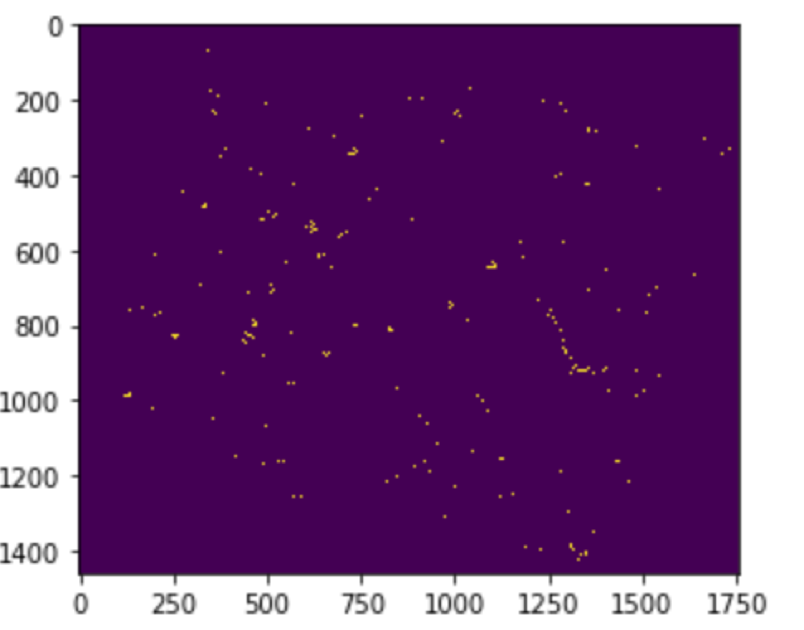
图5 GridSearch寻到的最优C&gamma组合预测的效果
效果不理想的原因与我设置的C值与gamma值不全肯定有很大的关系,所以再利用我们这种方法就不怎么可行了,于是我们继续更改:
第一种笨方法:
还是利用GridSearch,只不过在C、gamma赋值处将固定值替换为初值加步长的形式,用到了range()函数。
第二种方法是利用我前文所讲到的离子群优化算法寻优:
离子群优化算法(Particle Swarm Optimization Algorithm, PSO)是一种基于群体协作的随机搜索算法,其原理是源于对于鸟类捕食行为的研究,通过群体中的个体之间的协作核信息共享来寻找最优解,PSO算法的优势在于简单的算法实现和简洁的参数设置,目前较广泛的应用于函数优化、图像处理等方面,但是其缺点也是不可忽视的:提前收敛、容易陷入局部最优、维数灾难等缺点。
PSO算法的基本流程为:
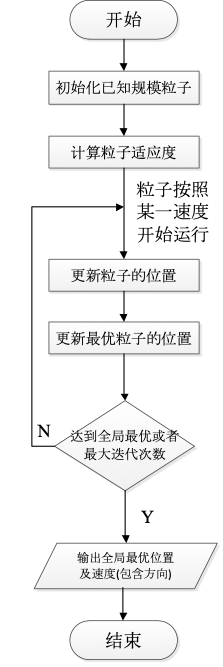
Step1:初始化一群粒子(假设群体规模为已知),初始化随机位置及速度;
Step2:评价每个粒子的适应度(计算其与最优位置的距离);
Step3:对每个微粒,将其适应值与其经过的最好位置pbest作比较,如果较好的话,则更新较好位置为最好位置;
Step4:加入权重因子,继续迭代更改粒子的速度及位置;
Step5:重复step2和step3直至达到结束条件(全局最优/迭代次数上限),否则继续执行2,3。
(未完待续,详情见下篇)
SVM分类器实现实例的更多相关文章
- 菜鸟之路——机器学习之SVM分类器学习理解以及Python实现
SVM分类器里面的东西好多呀,碾压前两个.怪不得称之为深度学习出现之前表现最好的算法. 今天学到的也应该只是冰山一角,懂了SVM的一些原理.还得继续深入学习理解呢. 一些关键词: 超平面(hyper ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- 自己训练SVM分类器进行HOG行人检测
正样本来源是INRIA数据集中的96*160大小的人体图片,使用时上下左右都去掉16个像素,截取中间的64*128大小的人体. 负样本是从不包含人体的图片中随机裁取的,大小同样是64*128(从完全不 ...
- Python图像处理(15):SVM分类器
快乐虾 http://blog.csdn.net/lights_joy/ 欢迎转载,但请保留作者信息 在opencv中支持SVM分类器.本文尝试在python中调用它. 和前面的贝叶斯分类器一样,SV ...
- 线性SVM分类器实战
1 概述 基础的理论知识参考线性SVM与Softmax分类器. 代码实现环境:python3 2 数据处理 2.1 加载数据集 将原始数据集放入"data/cifar10/"文件夹 ...
- 4. SVM分类器求解(2)
最优间隔分类器(optimal margin classifier) 重新回到SVM的优化问题: 我们将约束条件改写为: 从KKT条件得知只有函数间隔是1(离超平面最近的点)的线性约束式前面的系数,也 ...
- opencv中的Bayes分类器应用实例
转载:http://blog.csdn.net/yang_xian521/article/details/6967515 PS:很多时候,我们并不需要特别精通某个理论,而且有的时候即便你非常精通,但是 ...
- 大数据-10-Spark入门之支持向量机SVM分类器
简介 支持向量机SVM是一种二分类模型.它的基本模型是定义在特征空间上的间隔最大的线性分类器.支持向量机学习方法包含3种模型:线性可分支持向量机.线性支持向量机及非线性支持向量机.当训练数据线性可分时 ...
- 利用Hog特征和SVM分类器进行行人检测
在2005年CVPR上,来自法国的研究人员Navneet Dalal 和Bill Triggs提出利用Hog进行特征提取,利用线性SVM作为分类器,从而实现行人检测.而这两位也通过大量的测试发现,Ho ...
随机推荐
- windows xp + mysql5.5 + phpmyadmin insert 中文繁體
windows xp + mysql5.5 + phpmyadmin insert 中文繁體 今天也發生了,無法insert成功的問題: 在phpmyadmin 或doc下連接mysql執行都不行: ...
- C游新官网总结
从2017年9月18号,我开始独立做C游新官网项目.第一次独立完成项目,压力还是挺大的,毕竟还要自己去写前端,前端我已经忘了差不多了. 做这个网站主要是公司开始转型,开始自己建立渠道倒量,这样网站的S ...
- Linux(二十一)Shell编程
21.1 为什么要学习Shell编程 (1)Linux运维工程师在进行服务器集群管理时,需要编写Shell程序来进行服务器管理. (2)对于JavaEE和Python程序员来说,工作的需要,你的老大会 ...
- cocos2d-x 欢乐捕鱼游戏总结
这几天一直都在做一个捕鱼游戏Demo,大概花掉了我快一个礼拜的时间.游戏主体是使用的cocos2d-x高级开发教程里面提供的小部分框架基本功能.然后自己加入所有的UI元素和玩法.变成了一个体验不错的捕 ...
- 详解Trie
一.Trie的概念 Trie又称字典树,前缀树(事实上前缀树这个名字就很好的解释了Trie的储存方式) 来一张图理解一下Trie的储存方式:(图片来自百度百科) 由这张图我们也可以知道Trie的特点: ...
- 洛谷 P2205 解题报告
P2205 画栅栏Painting the Fence 题目描述 \(Farmer\) \(John\) 想出了一个给牛棚旁的长围墙涂色的好方法.(为了简单起见,我们把围墙看做一维的数轴,每一个单位长 ...
- Python(1)
Python 学习 Part1 1. 斐波那契数序列 >>> a,b=0,1 >>> a 0 >>> b 1 >>> while ...
- JS 数据类型、赋值、深拷贝和浅拷贝
js 数据类型 六种 基本数据类型: Boolean. 布尔值,true 和 false. null. 一个表明 null 值的特殊关键字. JavaScript 是大小写敏感的,因此 null 与 ...
- TCP连接和 time_wait、close_waite
TCP连接和 time_wait.close_waite tags:time_wait close_waite RST TCP 引言:前两天朋友公司的服务器垮掉了,最后查出的原因是发现大量的time_ ...
- PAT1028:List Sorting
1028. List Sorting (25) 时间限制 200 ms 内存限制 65536 kB 代码长度限制 16000 B 判题程序 Standard 作者 CHEN, Yue Excel ca ...