亿级流量场景下,大型架构设计实现【2】---storm篇
正文前先来一波福利推荐:
福利一:
百万年薪架构师视频,该视频可以学到很多东西,是本人花钱买的VIP课程,学习消化了一年,为了支持一下女朋友公众号也方便大家学习,共享给大家。
福利二:
毕业答辩以及工作上各种答辩,平时积累了不少精品PPT,现在共享给大家,大大小小加起来有几千套,总有适合你的一款,很多是网上是下载不到。
获取方式:
微信关注 精品3分钟 ,id为 jingpin3mins,关注后回复 百万年薪架构师 ,精品收藏PPT 获取云盘链接,谢谢大家支持!

-----------------------正文开始---------------------------
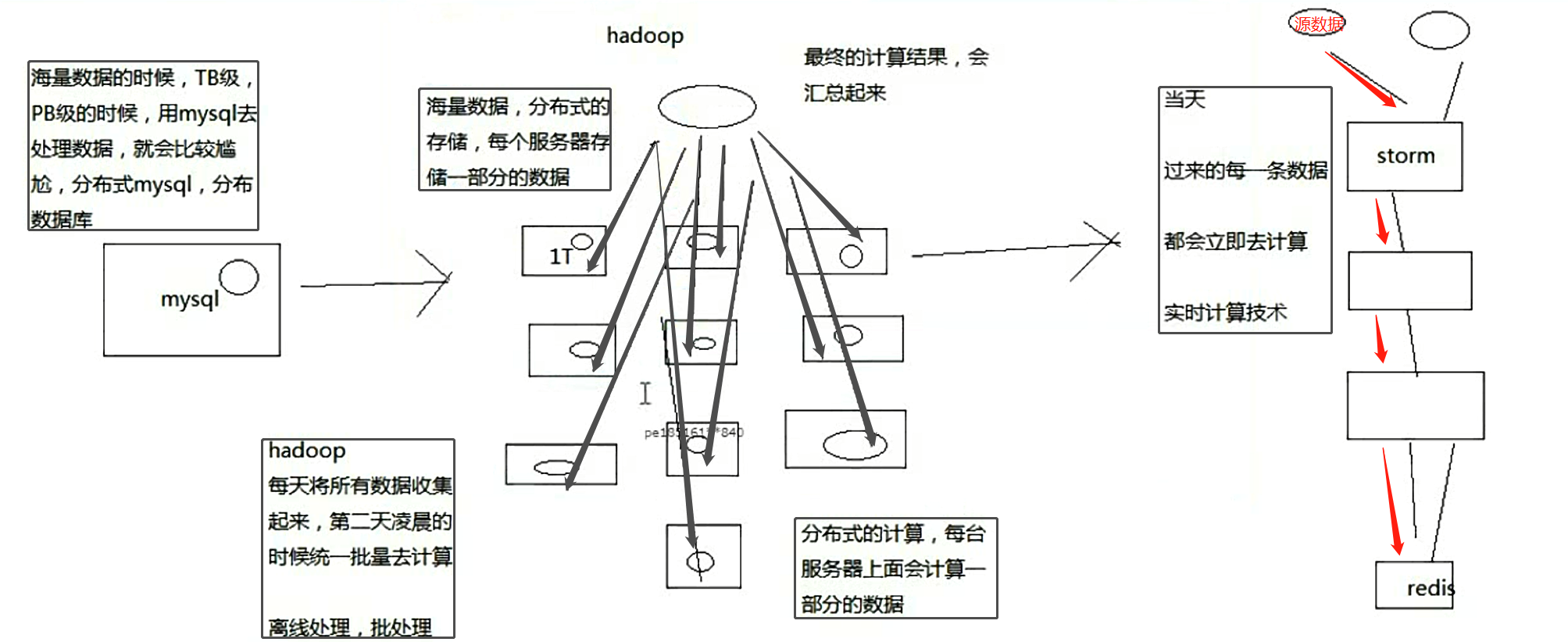
承接之前的博:亿级流量场景下,大型缓存架构设计实现
续写本博客:
****************** start:
接下来,我们是要讲解商品详情页缓存架构,缓存预热和解决方案,缓存预热可能导致整个系统崩溃的问题以及解决方案;
缓存--->热: 预热;热数据
解决方案中和架构设计中,会引入大数据的实时计算技术---> storm;
为什么引入这storm,必须是storm吗,我们后面面去讲解那个解决方案的时候再说;
为什么引入storm:
因为一些热点数据相关的一些实时处理方案,比如快速预热,热点数据的实时感知以及快速降级,都会用到storm,
因为我们可能需要实时的去计算出热点缓存数据,实时计算,亿级流量,高并发,大量的请求处理。这个时候你要做一些实时计算,
那么必须涉及到分布式一些技术,分布式技术才能处理高并发,大量的请求,目前在计算的领域,最成熟的大数据技术就是storm;storm分布式的大数据实时计算技术/系统;
java工程师跟storm之间的关系是什么呢?
大公司的java工程师都会用到一些大数据的技术:比如:storm,hbase,zookeeper,或者hive,spark等。
Storm: 实时缓存热点数据统计--->缓存预热,缓存热点数据自动降级;
Hive:Hadoop生态栈中做数据仓库的系统,高并发访问下,海量请求日志的批量统计分析,日报,月报,周报,接口调用情况等;比如有一些公司将海量的请求日志达到hive里边
做离线分析,然后反过来优化自己的系统。
Spark:离线批量数据处理,比如从DB中一次性批量处理几亿的数据,清洗和处理后写入Redis中提供后续系统使用;大型互联网公司的用户相关数据等。
zookeeper:分布式协调,分布式锁。分布式选举-->高可用HA架构,轻量级元数据存储。
HBase:海量数据的在线存储和简单查询,替代mysql的分库分表,提供更好的伸缩性。



storm,说句实话,在做热数据这块,如果要做复杂的热数据的统计和分析,亿流量,高并发的场景下,我还真觉得,最合适的技术就是storm,没有其他
缓存架构,热数据先关的架构设计,热数据相关的架构中最重要的唯一的可选技术。
************************入门介绍*********************************
storm的特点是什么?
(1)支撑各种实时类的项目场景:实时处理消息以及更新数据库,基于最基础的实时计算语义和API(实时数据处理领域);对实时的数据流持续的进行查询或计算,同时将最新的计算结果持续的推送给客户端展示,同样基于最基础的实时计算语义和API(实时数据分析领域);对耗时的查询进行并行化,基于DRPC,即分布式RPC调用,单表30天数据,并行化,每个进程查询一天数据,最后组装结果
storm做各种实时类的项目都ok
(2)高度的可伸缩性:如果要扩容,直接加机器,调整storm计算作业的并行度就可以了,storm会自动部署更多的进程和线程到其他的机器上去,无缝快速扩容
扩容起来,超方便
(3)数据不丢失的保证:storm的消息可靠机制开启后,可以保证一条数据都不丢
数据不丢失,也不重复计算
(4)超强的健壮性:从历史经验来看,storm比hadoop、spark等大数据类系统,健壮的多的多,因为元数据全部放zookeeper,不在内存中,随便挂都不要紧
特别的健壮,稳定性和可用性很高
(5)使用的便捷性:核心语义非常的简单,开发起来效率很高
用起来很简单,开发API还是很简单的
二、Storm的集群架构以及核心概念
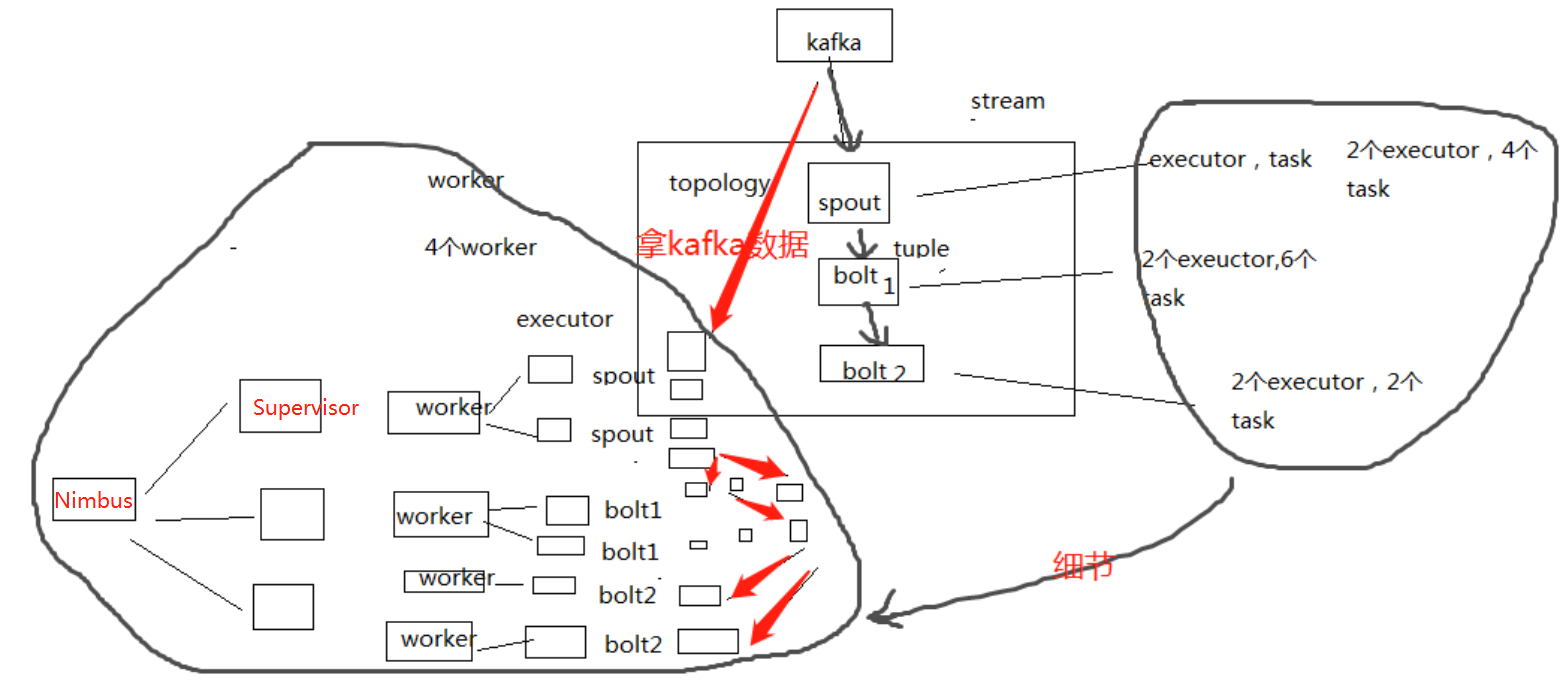
1、Storm的集群架构
Nimbus,Supervisor,ZooKeeper,Worker,Executor,Task
2、Storm的核心概念
Topology,Spout,Bolt,Tuple,Stream
拓扑:务虚的一个概念
Spout:数据源的一个代码组件,就是我们可以实现一个spout接口,写一个java类,在这个spout代码中,我们可以自己尝试去数据源获取数据,比如说从kafka中消费数据
bolt:一个业务处理的代码组件,spout会将数据传送给bolt,各种bolt还可以串联成一个计算链条,java类实现了一个bolt接口,一堆spout+bolt,就会组成一个topology,就是一个拓扑,实时计算作业,spout+bolt,一个拓扑涵盖数据源获取/生产+数据处理的所有的代码逻辑,topology
tuple:就是一条数据,每条数据都会被封装在tuple中,在多个spout和bolt之间传递
stream:就是一个流,务虚的一个概念,抽象的概念,源源不断过来的tuple,就组成了一条数据流

什么是并行度?什么是流分组?
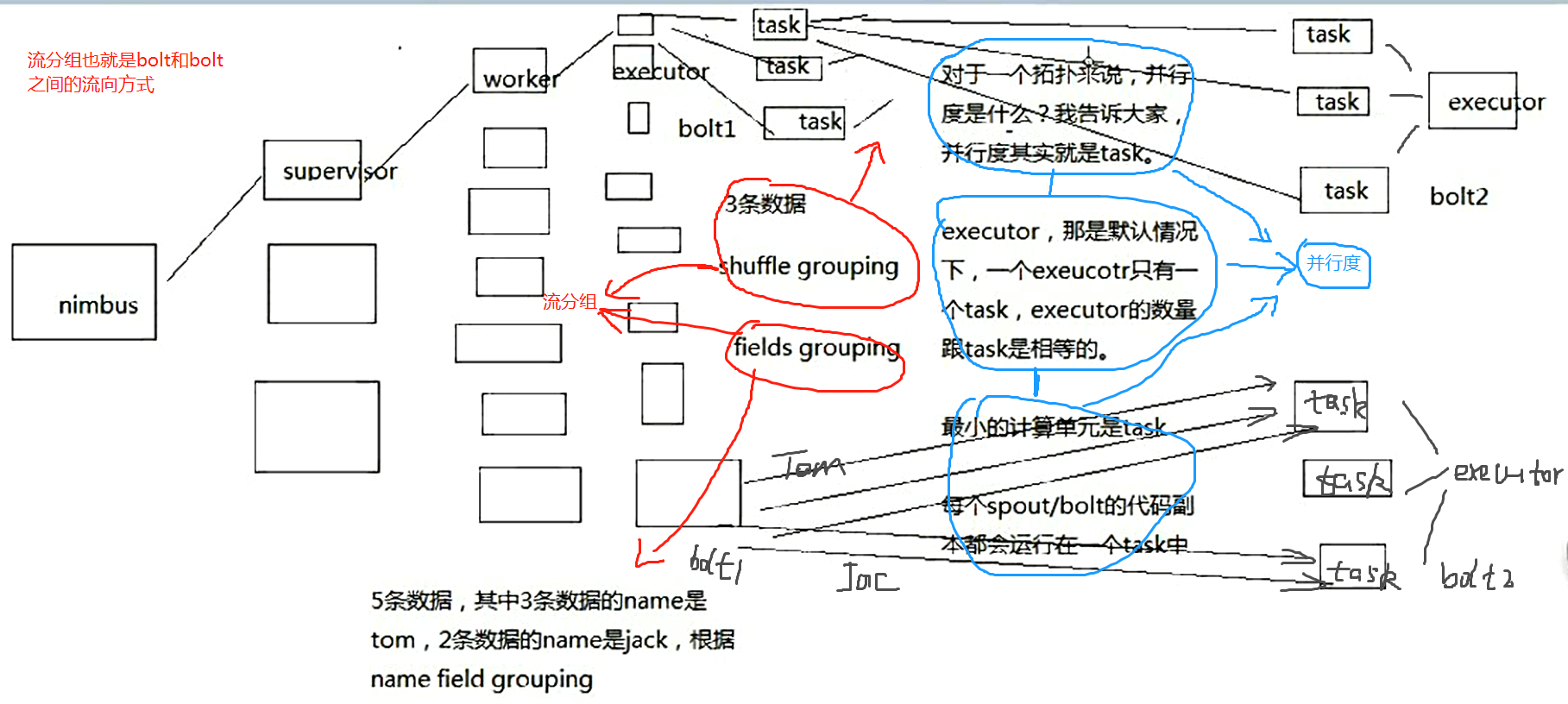
好多年前,我第一次接触storm的时候,真的,我觉得都没几个人能彻底讲清楚,用一句话讲清楚什么是并行度,什么是流分组
很多时候,你以外你明白了,其实你不明白
比如我经常面试一些做过storm的人过来,我就问一个问题,就知道它的水深水浅,流分组的时候,数据在storm集群中的流向,你画一下
比如你自己随便设想一个拓扑结果出来,几个spout,几个bolt,各种流分组情况下,数据是怎么流向的,要求具体画出集群架构中的流向
worker,executor,task,supervisor,流的
几乎没几个人能画对,为什么呢,很多人就没搞明白这个并行度和流分组到底是什么
并行度:Worker->Executor->Task,没错,是Task
流分组:Task与Task之间的数据流向关系
Shuffle Grouping:随机发射,【负载均衡】
Fields Grouping:根据某一个,或者某些个,fields,进行分组,那一个或者多个fields如果值完全相同的话,那么这些tuple,就会发送给下游bolt的其中固定的一个task
你发射的每条数据是一个tuple,每个tuple中有多个field作为字段
比如tuple,3个字段,name,age,salary
{"name": "tom", "age": 25, "salary": 10000} -> tuple -> 3个field,name,age,salary
其他方式:
All Grouping
Global Grouping
None Grouping
Direct Grouping
Local or Shuffle Grouping
************************代码实例*********************************
package com.roncoo.eshop.storm; import java.util.HashMap;
import java.util.Map;
import java.util.Random; import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory; /**
* 单词计数拓扑
*
* 我认识很多java工程师,都是会一些大数据的技术的,不会太精通,没有那么多的时间去研究
* storm的课程,我就只是讲到,最基本的开发,就够了,java开发广告计费系统,大量的流量的引入和接入,就是用storm做得
* 用storm,主要是用它的成熟的稳定的易于扩容的分布式系统的特性
* java工程师,来说,做一些简单的storm开发,掌握到这个程度差不多就够了
*
* @author Administrator
*
*/
public class WordCountTopology { /**
* spout
*
* spout,继承一个基类,实现接口,这个里面主要是负责从数据源获取数据
*
* 我们这里作为一个简化,就不从外部的数据源去获取数据了,只是自己内部不断发射一些句子
*
* @author Administrator
*
*/
public static class RandomSentenceSpout extends BaseRichSpout { private static final long serialVersionUID = 3699352201538354417L; private static final Logger LOGGER = LoggerFactory.getLogger(RandomSentenceSpout.class); private SpoutOutputCollector collector;
private Random random; /**
* open方法
*
* open方法,是对spout进行初始化的
*
* 比如说,创建一个线程池,或者创建一个数据库连接池,或者构造一个httpclient
*
*/
@SuppressWarnings("rawtypes")
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
// 在open方法初始化的时候,会传入进来一个东西,叫做SpoutOutputCollector
// 这个SpoutOutputCollector就是用来发射数据出去的
this.collector = collector;
// 构造一个随机数生产对象
this.random = new Random();
} /**
* nextTuple方法
*
* 这个spout类,之前说过,最终会运行在task中,某个worker进程的某个executor线程内部的某个task中
* 那个task会负责去不断的无限循环调用nextTuple()方法
* 只要的话呢,无限循环调用,可以不断发射最新的数据出去,形成一个数据流
*
*/
public void nextTuple() {
Utils.sleep(100);
String[] sentences = new String[]{"the cow jumped over the moon", "an apple a day keeps the doctor away",
"four score and seven years ago", "snow white and the seven dwarfs", "i am at two with nature"};
String sentence = sentences[random.nextInt(sentences.length)];
LOGGER.info("【发射句子】sentence=" + sentence);
// 这个values,你可以认为就是构建一个tuple
// tuple是最小的数据单位,无限个tuple组成的流就是一个stream
collector.emit(new Values(sentence));
} /**
* declareOutputFielfs这个方法
*
* 很重要,这个方法是定义一个你发射出去的每个tuple中的每个field的名称是什么
*
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("sentence"));
} } /**
* 写一个bolt,直接继承一个BaseRichBolt基类
*
* 实现里面的所有的方法即可,每个bolt代码,同样是发送到worker某个executor的task里面去运行
*
* @author Administrator
*
*/
public static class SplitSentence extends BaseRichBolt { private static final long serialVersionUID = 6604009953652729483L; private OutputCollector collector; /**
* 对于bolt来说,第一个方法,就是prepare方法
*
* OutputCollector,这个也是Bolt的这个tuple的发射器
*
*/
@SuppressWarnings("rawtypes")
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
} /**
* execute方法
*
* 就是说,每次接收到一条数据后,就会交给这个executor方法来执行
*
*/
public void execute(Tuple tuple) {
String sentence = tuple.getStringByField("sentence");
String[] words = sentence.split(" ");
for(String word : words) {
collector.emit(new Values(word));
}
} /**
* 定义发射出去的tuple,每个field的名称
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
} } public static class WordCount extends BaseRichBolt { private static final long serialVersionUID = 7208077706057284643L; private static final Logger LOGGER = LoggerFactory.getLogger(WordCount.class); private OutputCollector collector;
private Map<String, Long> wordCounts = new HashMap<String, Long>(); @SuppressWarnings("rawtypes")
public void prepare(Map conf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
} public void execute(Tuple tuple) {
String word = tuple.getStringByField("word"); Long count = wordCounts.get(word);
if(count == null) {
count = 0L;
}
count++; wordCounts.put(word, count); LOGGER.info("【单词计数】" + word + "出现的次数是" + count); collector.emit(new Values(word, count));
} public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word", "count"));
} } public static void main(String[] args) {
// 在main方法中,会去将spout和bolts组合起来,构建成一个拓扑
TopologyBuilder builder = new TopologyBuilder(); // 这里的第一个参数的意思,就是给这个spout设置一个名字
// 第二个参数的意思,就是创建一个spout的对象
// 第三个参数的意思,就是设置spout的executor有几个
builder.setSpout("RandomSentence", new RandomSentenceSpout(), 2);
builder.setBolt("SplitSentence", new SplitSentence(), 5)
.setNumTasks(10)
.shuffleGrouping("RandomSentence");
// 这个很重要,就是说,相同的单词,从SplitSentence发射出来时,一定会进入到下游的指定的同一个task中
// 只有这样子,才能准确的统计出每个单词的数量
// 比如你有个单词,hello,下游task1接收到3个hello,task2接收到2个hello
// 5个hello,全都进入一个task
builder.setBolt("WordCount", new WordCount(), 10)
.setNumTasks(20)
.fieldsGrouping("SplitSentence", new Fields("word")); Config config = new Config(); // 说明是在命令行执行,打算提交到storm集群上去
if(args != null && args.length > 0) {
config.setNumWorkers(3);
try {
StormSubmitter.submitTopology(args[0], config, builder.createTopology());
} catch (Exception e) {
e.printStackTrace();
}
} else {
// 说明是在eclipse里面本地运行
config.setMaxTaskParallelism(20); LocalCluster cluster = new LocalCluster();
cluster.submitTopology("WordCountTopology", config, builder.createTopology()); Utils.sleep(60000); cluster.shutdown();
}
} }
************************部署一个storm集群*********************************
讲了手写了storm wordcount程序
蕴含了很多的知识点
(1)Spout
(2)Bolt
(3)OutputCollector,Declarer
(4)Topology
(5)设置worker,executor,task,流分组
storm的核心基本原理,基本的开发,学会了
storm集群部署,怎么将storm的拓扑扔到storm集群上去跑
部署一个storm集群
(1)安装Java 7和Pythong 2.6.6 -- 此处略过
(2)下载storm安装包,解压缩,重命名,配置环境变量
-------------------------------------------------
上传apache-storm-1.0.6.tar.gz到 /usr/local
cd /usr/local
tar -zxvf apache-storm-1.0.6.tar.gz
mv apache-storm-1.0.5 storm
cd ./storm/conf
编辑storm.yaml
-------------------------------------------------------
storm.zookeeper.servers:
- "eshop-cache01"
- "eshop-cache02"
- "eshop-cache03"
nimbus.seeds: ["eshop-cache01"]
storm.local.dir: "/var/storm"
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
-------------------------------------------------------
创建数据文件目录:mkdir /var/storm
将storm分发到其他主机上:
scp -r/usr/local/storm/ root@eshop-cache02:/usr/local
scp -r/usr/localstorm/ root@eshop-cache03:/usr/local
在所有主机上添加storm的环境变量: vi /etc/profile
export STORM_HOME=/usr/local/storm
export PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin:/usr/java/latest/bin:/root/bin:/usr/local/zookeeper/bin:$STORM_HOME/bin
source /etc/profile
(4)启动storm集群和ui界面
eshop-cache01:
storm nimbus >/dev/null 2>&1 &
storm supervisor >/dev/null 2>&1 &
storm ui >/dev/null 2>&1 &
eshop-cache02:
storm supervisor >/dev/null 2>&1 &
storm ui >/dev/null 2>&1 &
eshop-cache03:
storm supervisor >/dev/null 2>&1 &
storm ui >/dev/null 2>&1 &
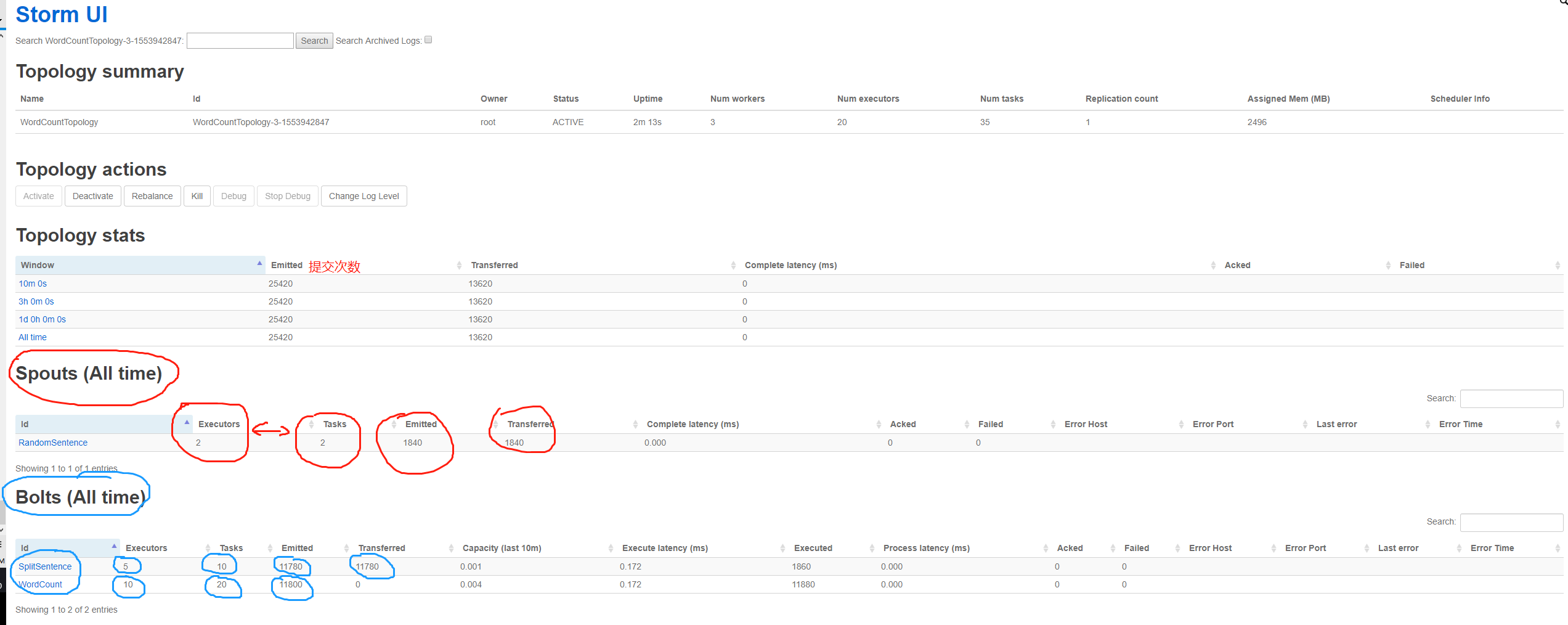
访问一下ui界面,8080端口: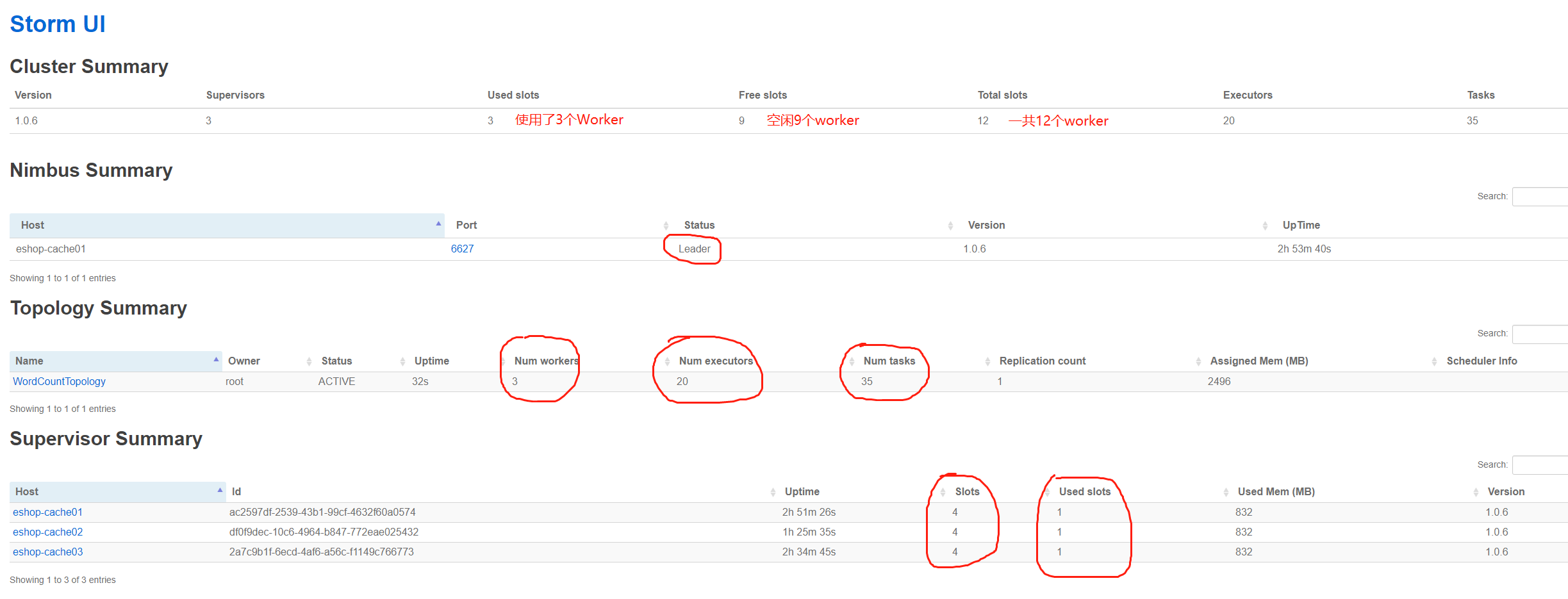
--------------------------------界面简单介绍:
- Used slots:使用的worker数。
- Free slots:空闲的worker数。
- Executors:每个worker的物理线程数。
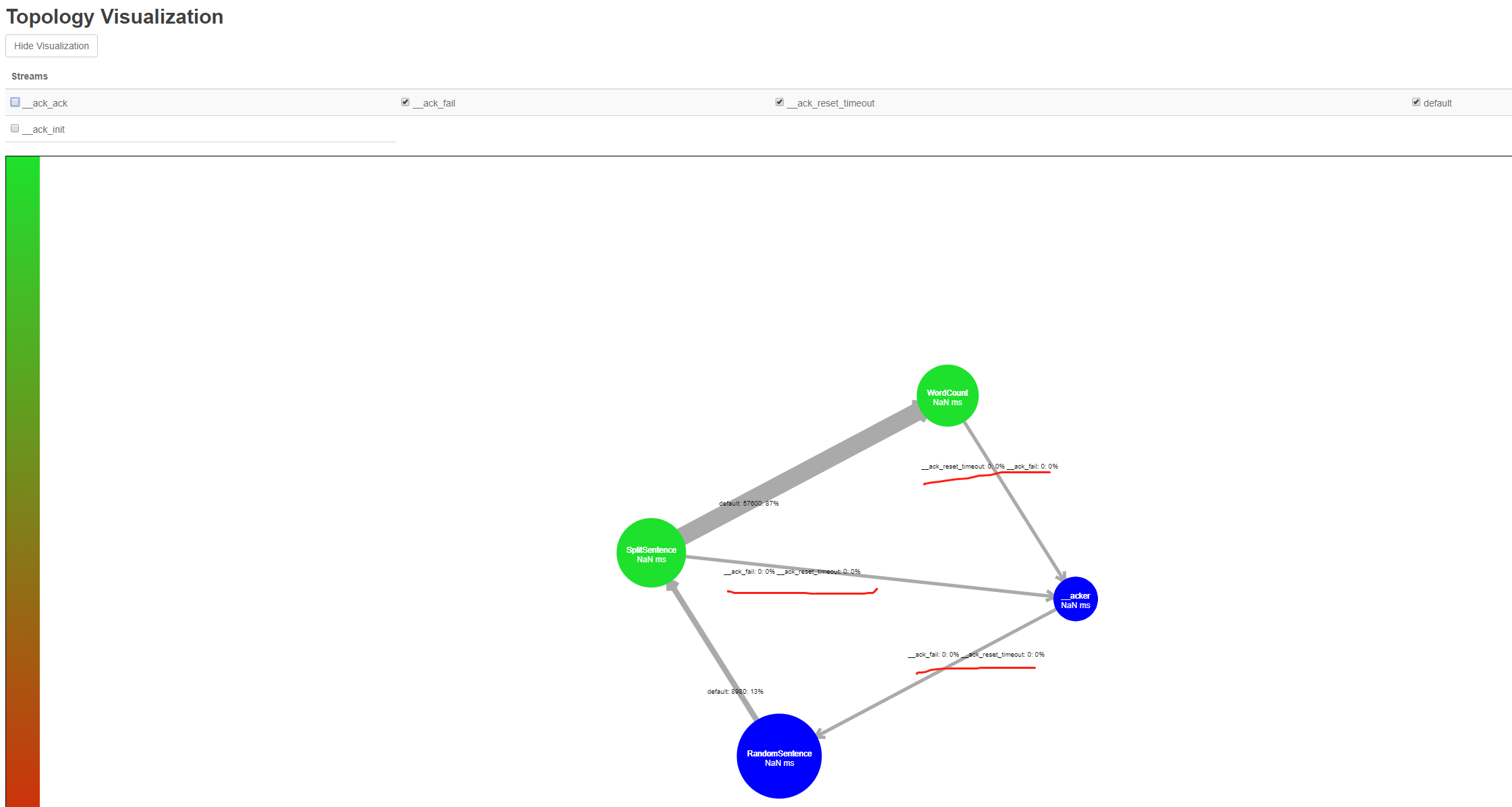
下图为细节图:
--------------------------------停止storm执行的拓扑任务:

线上日志截图:

---------------------------------------------- end
亿级流量场景下,大型架构设计实现【2】---storm篇的更多相关文章
- 亿级流量场景下,大型缓存架构设计实现【1】---redis篇
*****************开篇介绍**************** -------------------------------------------------------------- ...
- 【高并发】亿级流量场景下如何为HTTP接口限流?看完我懂了!!
写在前面 在互联网应用中,高并发系统会面临一个重大的挑战,那就是大量流高并发访问,比如:天猫的双十一.京东618.秒杀.抢购促销等,这些都是典型的大流量高并发场景.关于秒杀,小伙伴们可以参见我的另一篇 ...
- 亿级流量场景下,大型架构设计实现【全文检索高级搜索---ElasticSearch篇】-- 中
1.Elasticsearch的基础分布式架构: 1.Elasticsearch对复杂分布式机制的透明隐藏特性2.Elasticsearch的垂直扩容与水平扩容3.增减或减少节点时的数据rebalan ...
- 万级TPS亿级流水-中台账户系统架构设计
万级TPS亿级流水-中台账户系统架构设计 标签:高并发 万级TPS 亿级流水 账户系统 背景 业务模型 应用层设计 数据层设计 日切对账 背景 我们需要给所有前台业务提供统一的账户系统,用来支撑所有前 ...
- Netty Redis 亿级流量 高并发 实战 (长文 修正版)
目录 疯狂创客圈 Java 分布式聊天室[ 亿级流量]实战系列之 -30[ 博客园 总入口 ] 写在前面 1.1. 快速的能力提升,巨大的应用价值 1.1.1. 飞速提升能力,并且满足实际开发要求 1 ...
- java亿级流量电商详情页系统的大型高并发与高可用缓存架构实战视频教程
亿级流量电商详情页系统的大型高并发与高可用缓存架构实战 完整高清含源码,需要课程的联系QQ:2608609000 1[免费观看]课程介绍以及高并发高可用复杂系统中的缓存架构有哪些东西2[免费观看]基于 ...
- SpringCloud 亿级流量 架构演进
疯狂创客圈 Java 高并发[ 亿级流量聊天室实战]实战系列 [博客园总入口 ] 架构师成长+面试必备之 高并发基础书籍 [Netty Zookeeper Redis 高并发实战 ] 前言 Crazy ...
- 【架构师之路】Nginx负载均衡与反向代理—《亿级流量网站架构核心技术》
本篇摘自<亿级流量网站架构核心技术>第二章 Nginx负载均衡与反向代理 部分内容. 当我们的应用单实例不能支撑用户请求时,此时就需要扩容,从一台服务器扩容到两台.几十台.几百台.然而,用 ...
- (亿级流量)分布式防重复提交token设计
大型互联网项目中,很多流量都达到亿级.同一时间很多的人在使用,而每个用户提交表单的时候都可能会出现重复点击的情况,此时如果不做好控制,那么系统将会产生很多的数据重复的问题.怎样去设计一个高可用的防重复 ...
随机推荐
- Firemonkey 原生二维码扫描优化
之前用了ZXing的Delphi版本,运行自带的例子,速度非常慢,与安卓版本的相比查了很多,因此打算使用集成jar的方法,但是总觉得美中不足. 经过一番研究,基本上解决了问题. 主要有两方面的优化: ...
- MySQL在删除表时I/O错误原因分析
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 本文由腾讯数据库技术 发表于云+社区专栏 问题现象 最近使用sysbench测试MySQL,由于测试时间较长,写了一个脚本按prepare- ...
- CSS引入本地字体与在线字体
有些时候为了强调某些文字,需要使用一些比较特别的字体,CSS中现在也可以比较方便的引入字体了,如下: /* 定义字体 */ @font-face{ font-family: Arista2; src: ...
- Genymotion Android模拟器Genymotion的安装和使用
Android模拟器Genymotion的安装和使用 by:授客 QQ:1033553122 环境: Win7 Genymotion 2.12.0 下载地址:http://download.canad ...
- (一)初识Redis
1.redis简介 Redis是一个速度非常快的key-value非关系型存储数据库,可以存储5种形态的键值对,可以将存储在内存中的键值对持久化到硬盘,可以使用复制特性扩展读性能,还可以使用客户端分片 ...
- Lenovo System x3650 设置管理接口地址
1.开启服务器. 2.显示<F1> Setup提示后,按 F1.(此提示在屏幕上仅显示几秒钟.必须迅速按 F1.) 如果同时设置了开机密码和管理员密码,则必须输入管理员密码才能访问完整的 ...
- windows之如何把iso文件转换为VHD文件
(1)Convert-WindowsImage.ps1的下载路径: 链接:https://pan.baidu.com/s/18duFQFW8T_yI2JeQ1lhJgQ 提取码:b5ps autoun ...
- 深入理解 new 操作符
和其他高级语言一样 JavaScript 也有 new 操作符,我们知道 new 可以用来实例化一个类,从而在内存中分配一个实例对象. 但在 JavaScript 中,万物皆对象,为什么还要通过 ne ...
- Android 平台 Native 代码的崩溃捕获机制及实现
本文来自于腾讯Bugly公众号(weixinBugly),未经作者同意,请勿转载,原文地址:https://mp.weixin.qq.com/s/g-WzYF3wWAljok1XjPoo7w 一.背景 ...
- SUSE12SP3-Mycat(3)Server.xml配置详解
简介 server.xml 几乎保存了所有 mycat 需要的系统配置信息.其在代码内直接的映射类为 SystemConfig 类. user 标签 <user name="test& ...