第九篇:随机森林(Random Forest)
前言
随机森林非常像《机器学习实践》里面提到过的那个AdaBoost算法,但区别在于它没有迭代,还有就是森林里的树长度不限制。
因为它是没有迭代过程的,不像AdaBoost那样需要迭代,不断更新每个样本以及子分类器的权重。因此模型相对简单点,不容易出现过拟合。
下面先来讲讲它的具体框架流程。
框架流程

随机森林可以理解为Cart树森林,它是由多个Cart树分类器构成的集成学习模式。其中每个Cart树可以理解为一个议员,它从样本集里面随机有放回的抽取一部分进行训练,这样,多个树分类器就构成了一个训练模型矩阵,可以理解为形成了一个议会吧。
然后将要分类的样本带入这一个个树分类器,然后以少数服从多数的原则,表决出这个样本的最终分类类型。
设有N个样本,M个变量(维度)个数,该算法具体流程如下:
1. 确定一个值m,它用来表示每个树分类器选取多少个变量。(注意这也是随机的体现之一)
2. 从数据集中有放回的抽取 k 个样本集,用它们创建 k 个树分类器。另外还伴随生成了 k 个袋外数据,用来后面做检测。
3. 输入待分类样本之后,每个树分类器都会对它进行分类,然后所有分类器按照少数服从多数原则,确定分类结果。
性能制约
1. 森林中的每个树越茂盛,分类效果就越好。
2. 树和树的枝叶穿插越多,分类效果就越差。
重要参数
1. 预选变量个数 (即框架流程中的m);
2. 随机森林中树的个数。
这两个参数的调优非常关键,尤其是在做分类或回归的时候。
构建随机森林模型
函数名:randomForest(......);
函数重要参数说明:
- x,y参数自然是特征矩阵和标签向量;
- na.action:是否忽略有缺失值的样本;
- ntree:树分类器的个数。500-1000为佳;
- mtry:分枝的变量选择数;
- importance:是否计算各个变量在模型中的重要性(后面会提到)。
构建好模型之后,带入predict函数和待预测数据集就可得出预测结果。然而,R语言中对随机森林这个机制的支持远远不止简单的做分类这么简单。它还提供以下这几个功能,在使用这些功能之前,都要先调用randomForest函数架构出模型。
使用随机森林进行变量筛选
之前的文章提到过使用主成分分析法PCA,以及因子分析EFA,但是这两种方法都有各自的缺点。它们都是属于变量组合技术,会形成新的变量,之后一般还需要一个解释的阶段。
对于一些解释起来比较麻烦,以及情况不是很复杂的情况,直接使用随机森林进行特征选择就可以了,下面为具体步骤:

执行这个脚本后:
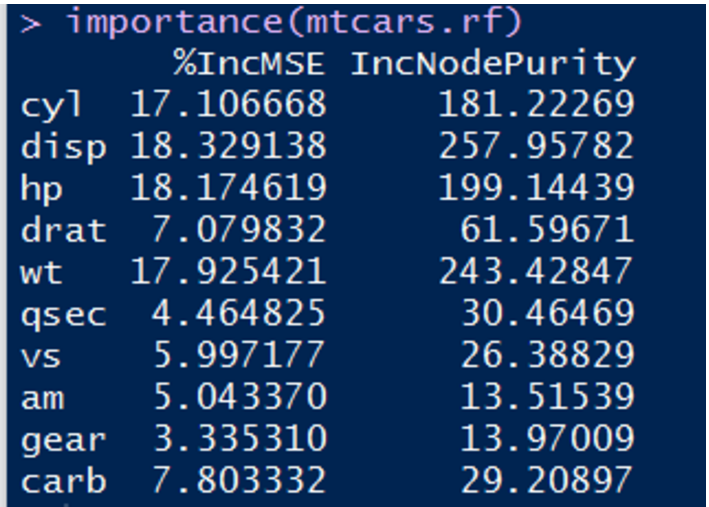
其中的两列是衡量变量重要性的指标,越高表示该变量对分类的影响越大。第一列是根据精度平均减少值作为标准度量,而第二列则是采用节点不纯度的平均减少值作为度量标准。
重要度的计量方法参考下图(摘自百度文库):

使用随机森林绘制MDS二维图
通过MDS图我们能大致看出哪些类是比较容易搞混的:

生成下图:
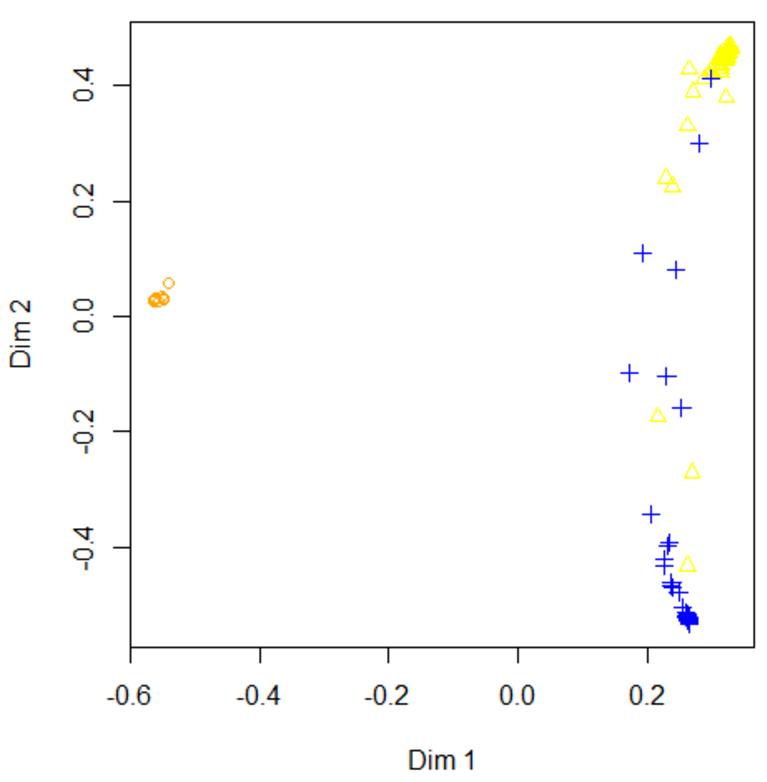
可以看出,第二列第三列存在着容易混淆的情况。
小结
R语言包中提供的随机森林功能包还有很多,对于调优很有帮助,请务必查询相关资料并掌握。
另外,部分变种的随机森林算法还可以用来做回归。
第九篇:随机森林(Random Forest)的更多相关文章
- sklearn_随机森林random forest原理_乳腺癌分类器建模(推荐AAA)
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录制视频) https://study.163.com/course/introduction.htm?courseId=1005269003& ...
- 机器学习方法(六):随机森林Random Forest,bagging
欢迎转载,转载请注明:本文出自Bin的专栏blog.csdn.net/xbinworld. 技术交流QQ群:433250724,欢迎对算法.技术感兴趣的同学加入. 前面机器学习方法(四)决策树讲了经典 ...
- 【机器学习】随机森林(Random Forest)
随机森林是一个最近比较火的算法 它有很多的优点: 在数据集上表现良好 在当前的很多数据集上,相对其他算法有着很大的优势 它能够处理很高维度(feature很多)的数据,并且不用做特征选择 在训练完后, ...
- 随机森林random forest及python实现
引言想通过随机森林来获取数据的主要特征 1.理论根据个体学习器的生成方式,目前的集成学习方法大致可分为两大类,即个体学习器之间存在强依赖关系,必须串行生成的序列化方法,以及个体学习器间不存在强依赖关系 ...
- 机器学习(六)—随机森林Random Forest
1.什么是随机采样? Bagging可以简单的理解为:放回抽样,多数表决(分类)或简单平均(回归): Bagging的弱学习器之间没有boosting那样的联系,不存在强依赖关系,基学习器之间属于并列 ...
- 【机器学习】随机森林 Random Forest 得到模型后,评估参数重要性
在得出random forest 模型后,评估参数重要性 importance() 示例如下 特征重要性评价标准 %IncMSE 是 increase in MSE.就是对每一个变量 比如 X1 随机 ...
- 随机森林(Random Forest)
决策树介绍:http://www.cnblogs.com/huangshiyu13/p/6126137.html 一些boosting的算法:http://www.cnblogs.com/huangs ...
- 随机森林——Random Forests
[基础算法] Random Forests 2011 年 8 月 9 日 Random Forest(s),随机森林,又叫Random Trees[2][3],是一种由多棵决策树组合而成的联合预测模型 ...
- 决策树模型组合之(在线)随机森林与GBDT
前言: 决策树这种算法有着很多良好的特性,比如说训练时间复杂度较低,预测的过程比较快速,模型容易展示(容易将得到的决策树做成图片展示出来)等.但是同时, 单决策树又有一些不好的地方,比如说容易over ...
随机推荐
- IntelliJ IDEA下Maven SpringMVC+Mybatis入门搭建例子
很久之前写了一篇SSH搭建例子,由于工作原因已经转到SpringMVC+Mybatis,就以之前SSH实现简单登陆的例子,总结看看SpringMVC+Mybatis怎么实现. Spring一开始是轻量 ...
- php+redis 学习 二 悲观锁
<?php header('content-type:text/html;chaeset=utf-8'); /** * redis实战 * * 实现悲观锁机制 * */ $timeout = 5 ...
- Sublime Text3 快捷键汇总及设置快捷键配置环境变量
Ctrl+D 选词 (反复按快捷键,即可继续向下同时选中下一个相同的文本进行同时编辑)Ctrl+G 跳转到相应的行Ctrl+J 合并行(已选择需要合并的多行时)Ctrl+L 选择整行(按住-继续选择下 ...
- vagrant使用小结
vagrant使用小结 最近公司用了vagrant的虚拟镜像服务,感觉挺不错的.在此仅记录使用方法. 优点:我们可以通过 Vagrant 封装一个 Linux 的开发环境,分发给团队成员.成员可以在自 ...
- maven配置全局的jdk和配置局部的jdk
配置全局的jdk需要修改maven的setting.xml文件 <profile> <id>jdk17</id> <activation> <ac ...
- object类的equals方法简介 & String类重写equals方法
object类中equals方法源码如下所示 public boolean equals(Object obj) { return this == obj; } Object中的equals方法是直接 ...
- Java经典编程题50道之三十二
取一个整数a从右端开始的4-7位. public class Example32 { public static void main(String[] args) { cut(12 ...
- Shell脚本报错:-bash: ./switch.sh: /bin/bash^M: bad interpreter: No such file or directory
在学习shell中测试case参数命令代码如下 #!/bin/bash #switch测试 case $1 in start) echo 'start' ;; ...
- iOS原生和H5的相互调用
为什么现在越来越多的APP中开始出现H5页面? 1,H5页面开发效率更高,更改更加方便: 2,适当缩小APP安装包的大小: 3,蹭热点更加方便,比如五一,十一,双十一搞活动: 那么为什么说H5无法取代 ...
- 老男孩Python全栈开发(92天全)视频教程 自学笔记21
day21课程内容: json: #序列化 把对象(变量)从内存中 编程可存储和可传输的过程 称为序列化import jsondic={'name':'abc','age':18}with open ...