Oracle 11g全表扫描以Direct Path Read方式执行
在Oracle Database 11g中有一个新特性,全表扫描可以通过直接路径读的方式来执行(Direct Path Read),这是一个合理的变化,如果全表扫描的大量数据读取是偶发性的,则直接路径读可以避免大量数据对于Buffer Cache的冲击。
当然对于小表来说,Oracle允许通过Buffer Cache来进行全表扫描,因为这可能更快,也对性能影响不大。
小表受到隐含参数:_small_table_threshold 影响。如果表大于 5 倍的小表限制,则自动会使用DPR替代FTS。
可以设置初始化参数: _serial_direct_read 来禁用串行直接路径读。
当然,Oracle通过一个内部的限制,来决定执行DPR的阈值。
可以通过设置10949事件屏蔽这个特性,返回到Oracle 11g之前的模式上:
alter session set events '10949 trace name context forever, level 1';
还有一个参数 _very_large_object_threshold 用于设定(MB单位)使用DPR方式的上限,这个参数需要结合10949事件共同发挥作用。
10949 事件设置任何一个级别都将禁用DPR的方式执行FTS,但是仅限于小于 5 倍 BUFFER Cache的数据表,同时,如果一个表的大小大于 0.8 倍的 _very_large_object_threshold 设置,也会执行DPR。
这些限定的目标在于:
对于大表的全表扫描,必须通过Direct Path Read方式执行,以减少对于Buffer Cache的冲击和性能影响。
但是我们可以通过参数调整来决定执行DPR的上限和下限。
Event 10949 可以在线设置,但对现有session可能不会生效,新登录的会话会执行新的设置:
在实例级别修改参数设置:
- ALTER SYSTEM SET EVENTS '10949 TRACE NAME CONTEXT FOREVER';
增加参数到SPFILE中:
- alter system set event='10949 TRACE NAME CONTEXT FOREVER' scope=spfile;
对当前会话设置:
- ALTER SESSION SET EVENTS '10949 TRACE NAME CONTEXT FOREVER';
隐含参数"_serial_direct_read" 可以达到类似的限制,其默认值为AUTO,设置为NEVER时禁用 11g 的自动direct path read的特性。该参数可以动态在实例或会话级别修改,而无需重启实例。
- SQL> alter system set "_serial_direct_read"=auto;
- SQL> alter system set "_serial_direct_read"=never;
以下的AWR信息是典型的DPR症状: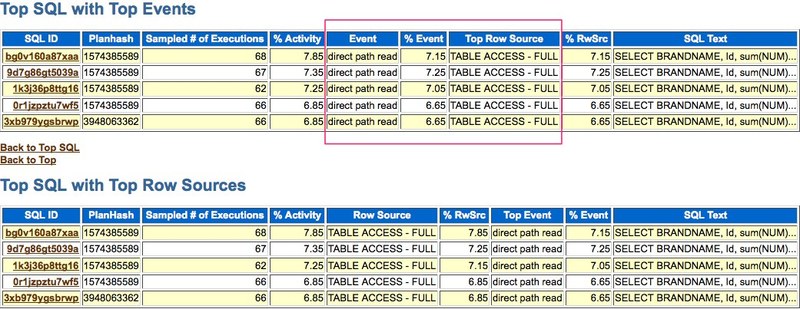
http://sai-oracle.blogspot.com/2010/06/full-table-scan-behavior-in-11g.html
Before 11gr2, full table scan access path read all the blocks of a table (or index fast full scan) under high water mark into the buffer cache unless either "_serial_direct_read" hidden parameter is set to true or the table/index have default parallelism set.
In 11gR2, Oracle will automatically decide whether to use direct path reads bypassing buffer cache for serial full table scans.
For using direct path reads, Oracle first has to write any dirty blocks of the table to disk by issuing object level checkpoint and then read all the blocks from disk into the PGA of server process. If it has to undo any uncommitted transactions to provide read consistency or to do delayed block clean out, Oracle will use server process PGA to construct read consistent block buffers.
If block clean out has to be performed by the server process using direct path reads for full table scans, it won't write those modified blocks back to disk, so every time you perform full table scan using direct path reads it'd have to keep doing the same work of cleaning out the blocks for every execution. For this reason, it is recommended to manually clean out those blocks by performing full table scan without using direct path reads.
Following behavior was observed with my testing on 11.2.0.1:
Hidden parameter "_small_table_threshold" defines the number of blocks to consider a table as small. Any table having more blocks (about 5 times the value of "_small_table_threshold" if you leave it at default value) will automatically use direct path reads for serial full table scans (FTS).
Hidden parameter "_very_large_object_threshold" defines the upper limit of object size in MB for using direct path reads. There is no effect on FTS behavior just by setting this parameter alone.
Event 10949 set to any level will disable direct path reads for serial scans only if the size of an object is less then 5 times the size of buffer cache.
Combination of event 10949 and "_very_large_object_threshold" parameter will disable direct path reads for serial scans if the size of an object is less than 5 times the size of buffer cache or the value of "_very_large_object_threshold" is less than about 0.8 times the size of an object.
So, if you want to disable direct path reads for serial scans for any object, then set event 10949 at any level and set "_very_large_object_threshold" to greater than the size of largest object in MB.
Hidden parameter "_serial_direct_read" (or event 10355 set at any level) set to TRUE will enable direct path reads for all serial scans, unless the table is considered as small table and it's caching attribute is set (by issuing alter table xxxx cache). Remember that any sql statement already parsed and not using direct path reads will continue to do so unless hard parse is forced after setting these parameters. For this reason, it is better not to set these parameters.
It is not recommended to set any of the above mentioned hidden parameters if you want direct path reads to be used for serial scans, let Oracle decide dynamically based on the size of an object.
Oracle 11g全表扫描以Direct Path Read方式执行的更多相关文章
- Oracle查找全表扫描的SQL语句
原文链接:http://blog.itpub.net/9399028/viewspace-678358/ 对于SQL的执行计划,一般尽量避免TABLE ACCESS FULL的出现,那怎样去定位,系统 ...
- 数据库全表扫描的SQL种类
1.所查询的表的条件列没有索引: 2.需要返回所有的行: 3.对索引主列有条件限制,但是使用了函数,则Oracle 使用全表扫描,如: where upper(city)=’TOKYO’; 这样的语 ...
- Oracle收集对表收集统计信息导致全表扫描直接路径读?
direct path read深入解析 前言 最近碰到一件很奇葩的事情,因为某条SQL执行缓慢,原因是走了笛卡尔(两组大数据结果集),而且笛卡尔还是NL的一个部分,要循环31M次. 很容易发现是统计 ...
- Oracle的大表,小表与全表扫描
大小表区分按照数据量的大小区分: 通常对于小表,Oracle建议通过全表扫描进行数据访问,对于大表则应该通过索引以加快数据查询,当然如果查询要求返回表中大部分或者全部数据,那么全表扫描可能仍然是最好的 ...
- Oracle列操作引起的全表扫描
首先是一种比较明显的情况: select * from table where column + 1 = 2 这里对column进行了列操作,加1以后,与column索引里的内容对不上,导致colum ...
- Oracle 表的访问方式(1) ---全表扫描、通过ROWID访问表
1.Oracle访问表的方式 全表扫描.通过ROWID访问表.索引扫描 2.全表扫描(Full Table Scans, FTS) 为实现全表扫描,Oracle顺序地访问表中每条记录,并检查每一条记录 ...
- Oracle全表扫描
优化器在形成执行计划时需要做的一个重要选择——如何从数据库查询出需要的数据.对于SQL语句存取的任何表中的任何行,可能存在许多存取路径(存取方法),通过它们可以定位和查询出需要的数据.优化器选择其中自 ...
- Oracle 高水位线和全表扫描
--Oracle 高水位线和全表扫描--------------------------2013/11/22 高水位线好比水库中储水的水位线,用于描述数据库中段的扩展方式.高水位线对全表扫描方式有着至 ...
- oracle优化:避免全表扫描(高水位线)
如果我们查询了一条SQL语句,这条SQL语句进行了全表扫描,那到底是扫描了多少个数据块呢?是表有多少数据,就扫描多少块吗?不是的.而是扫描高水位线一下的所有块.有的时候有人经常说,我的表也不大呀,怎么 ...
随机推荐
- LOJ #6050. 「雅礼集训 2017 Day11」TRI
完全不会的数学神题,正解留着以后填坑 将一个口胡的部分分做法,我们考虑计算格点多边形(包括三角形)面积的皮克公式: \[S=a+\frac{1}{2}b-1\text({a为图形内部节点个数,b为边界 ...
- 【死磕 Spring】----- IOC 之深入理解 Spring IoC
在一开始学习 Spring 的时候,我们就接触 IoC 了,作为 Spring 第一个最核心的概念,我们在解读它源码之前一定需要对其有深入的认识,本篇为[死磕 Spring]系列博客的第一篇博文,主要 ...
- 我是如何拿到蚂蚁金服 offer 的 ?
阅读本文大概需要 5.6 分钟. 作者:翟洪毅 一.梦想和被拒 二.积累 三.结语 首先介绍一下投稿作者 翟洪毅,16年华理计算机本科毕业.在年前拿到了蚂蚁金服Java开发的offer,P6. 工 ...
- 线性回归预测PM2.5----台大李宏毅机器学习作业1(HW1)
一.作业说明 给定训练集train.csv,要求根据前9个小时的空气监测情况预测第10个小时的PM2.5含量. 训练集介绍: (1)CSV文件,包含台湾丰原地区240天的气象观测资料(取每个月前20天 ...
- 4.alembic数据迁移工具
alembic是用来做ORM模型与数据库的迁移与映射.alembic使用方式跟git有点类似,表现在两个方面,第一个,alemibi的所有命令都是以alembic开头: 第二,alembic的迁移文件 ...
- Java进阶篇设计模式之三 ----- 建造者模式和原型模式
前言 在上一篇中我们学习了工厂模式,介绍了简单工厂模式.工厂方法和抽象工厂模式.本篇则介绍设计模式中属于创建型模式的建造者模式和原型模式. 建造者模式 简介 建造者模式是属于创建型模式.建造者模式使用 ...
- MySQL via EF6 的试用报告
1.如何通过 EF6 来连接 MySQL? 2.如何通过 EF6 来实现 CRUD? 2.1.Create 添加 2.2.Retrieve 查询 2.3.Update 修改 2.4.Delete 删除 ...
- C#语法——消息,MVVM的核心技术。
在C#中消息有两个指向,一个指向Message,一个指向INotify.这里主要讲INotify. INotify也有人称之为[通知],不管叫消息还是通知,都是一个意思,就是传递信息. 消息的定义 I ...
- Spring Boot使用Spring Data Jpa对MySQL数据库进行CRUD操作
只需两步!Eclipse+Maven快速构建第一个Spring Boot项目 构建了第一个Spring Boot项目. Spring Boot连接MySQL数据库 连接了MySQL数据库. 本文在之前 ...
- SLAM+语音机器人DIY系列:(二)ROS入门——1.ROS是什么
摘要 ROS机器人操作系统在机器人应用领域很流行,依托代码开源和模块间协作等特性,给机器人开发者带来了很大的方便.我们的机器人“miiboo”中的大部分程序也采用ROS进行开发,所以本文就重点对ROS ...