hadoop in hue的搭建(基于cdh版本)
首先官网下载tar包
http://archive.cloudera.com/cdh5/cdh/5/hue-3.9.0-cdh5.5.4.tar.gz
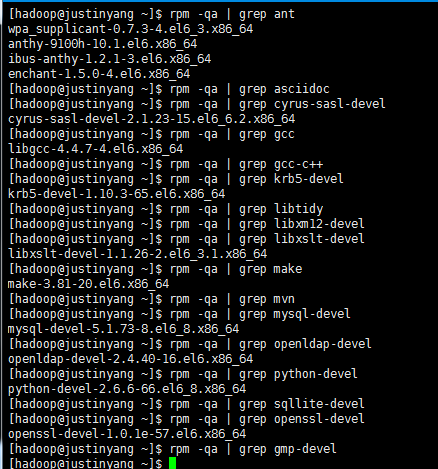
在安装hue之前,还需要安装各种依赖包,首先要检查是否有这些依赖包,mysql和mysql-devel已经在安装hive的时候有了 所以不必安装
添加mvn源
wget http://repos.fedorapeople.org/repos/dchen/apache-maven/epel-apache-maven.repo -O /etc/yum.repos.d/epel-apache-maven.repo
安装依赖(mysql和mysql-devel已经在安装hive的时候有了 所以不必安装)
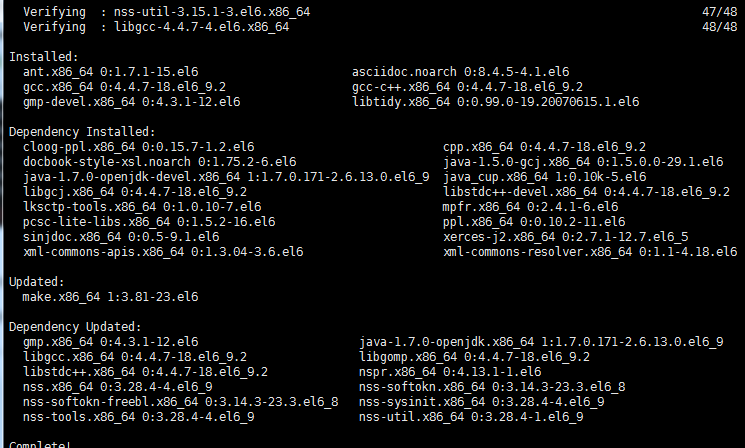
yum install -y ant asciidoc cyrus-sasl-devel cyrus-sasl-gssapi gcc gcc-c++ krb5-devel libtidy libxml2-devel libxslt-devel make mvn openldap-devel python-devel sqlite-devel openssl-devel gmp-devel
切换到hadoop用户并上传并解压tar包
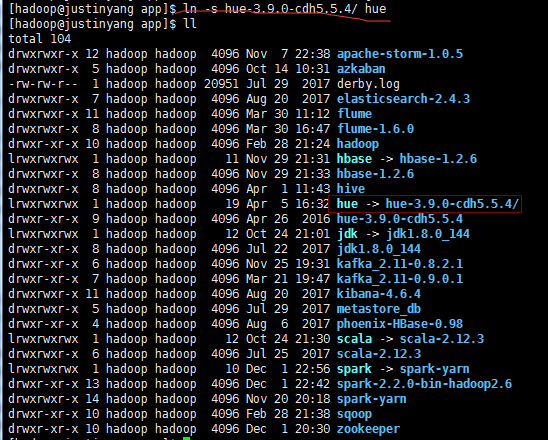
建立软连接
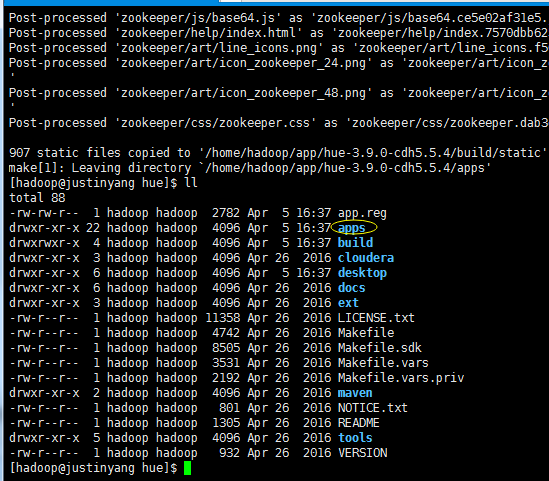
进入hue安装目录 使用make apps进行编译,编译完成后进入apps目录
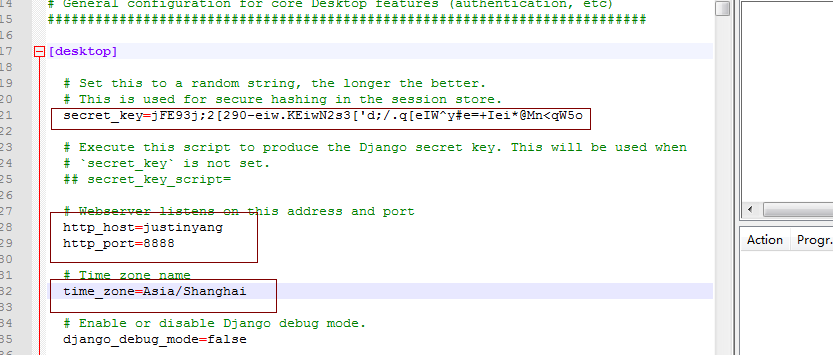
进入desktop的conf目录下修改hue.ini配置文件
secret_key=jFE93j;2[290-eiw.KEiwN2s3['d;/.q[eIW^y#e=+Iei*@Mn<qW5o
# Execute this script to produce the Django secret key. This will be used when
# `secret_key` is not set.
## secret_key_script=
# Webserver listens on this address and port
http_host=192.168.80.136
http_port=8888
# Time zone name
time_zone=Asia/Shanghai
# Enable or disable Django debug mode.
django_debug_mode=false
# Enable or disable database debug mode.
## database_logging=false
# Enable or disable backtrace for server error
http_500_debug_mode=false
# Enable or disable memory profiling.
## memory_profiler=false
# Server email for internal error messages
## django_server_email='hue@localhost.localdomain'
# Email backend
## django_email_backend=django.core.mail.backends.smtp.EmailBackend
# Webserver runs as this user
server_user=hue
server_group=hue
# This should be the Hue admin and proxy user
default_user=hue
# This should be the hadoop cluster admin
default_hdfs_superuser=hadoop
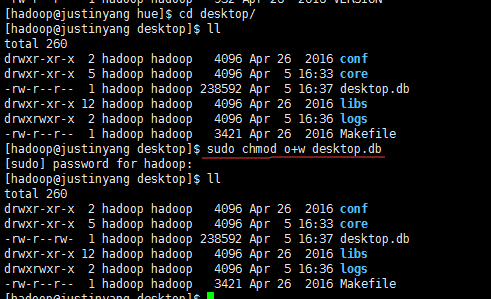
先启动hue ,首先要给desktop.db赋予权限
接着
配置完我们要登录一下hue
接着配置hdfs模块(这个是根据集群是否是HA来配置的,我的是HA的,所以配置如下.非HA集群要和自己默认的hdfs-site.xml和core-site.xml配置文件一致)
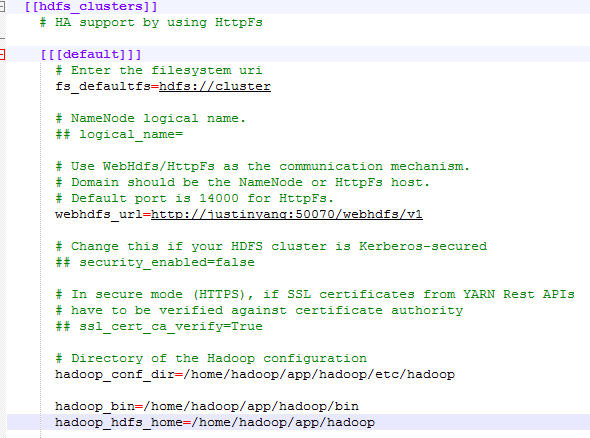
完成之后首先将 hdfs-site.xml中的如下配置加上
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
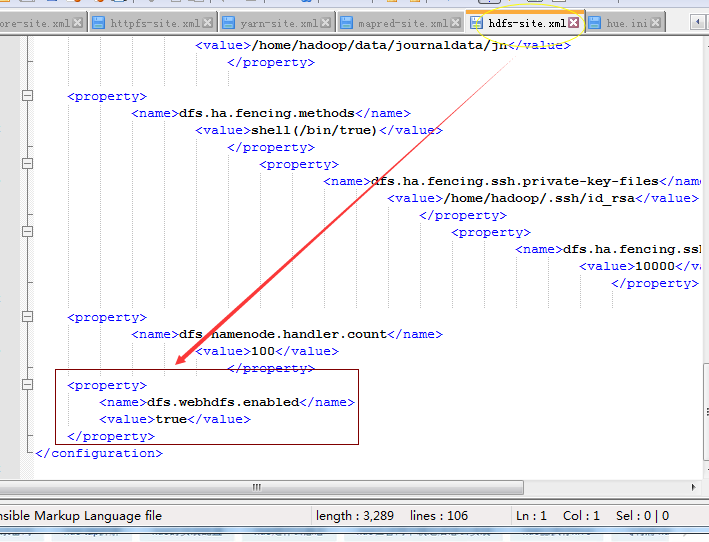
接着core-stie.xml加上
<property>
<name>hadoop.proxyuser.hue.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hue.groups</name>
<value>*</value>
</property>
接着讲这两个配置文件同步到其他节点,我用的是脚本,大家可以用scp命令 例如 scp 文件名 节点名:目标路径 即可

然后启动hdfs文件系统 ,接着重启hue发现
无法访问:/user/hadoop。 Note: you are a Hue admin but not a HDFS superuser, "hdfs" or part of HDFS supergroup, "supergroup".
可以查看这篇http://www.cnblogs.com/justinyang/p/8728021.html
以及http://www.cnblogs.com/justinyang/p/8728015.html 来进行解决
yarn这个模块 default和ha这两个都要配置

zookeeper的模块
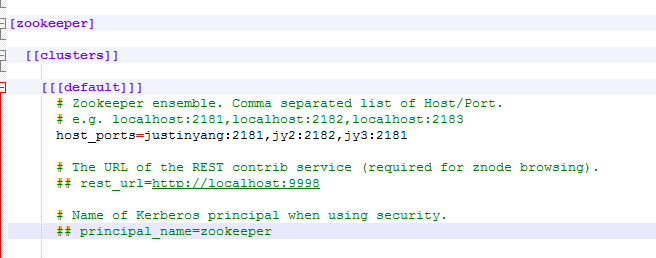
hive这个模块(hive我是安装在justinyang这个节点上的,大家要根据自己的情况来进行实地的配置)

同时hive-site.xml文件有两个配置要修改
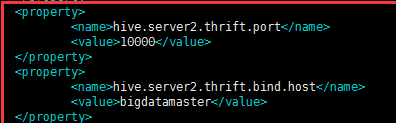
然后首先要启动yarn,然后mysql服务要打开,接着打开hiveserver 同时启动hive

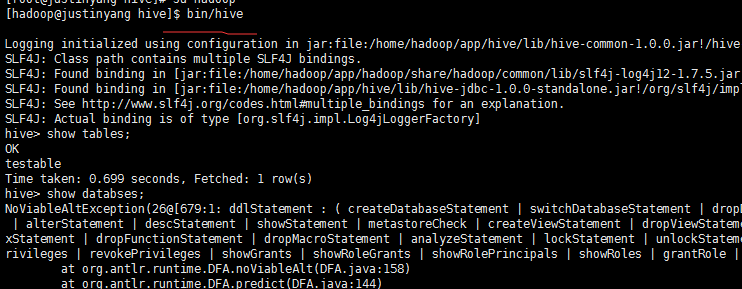
然后查看hue,显示
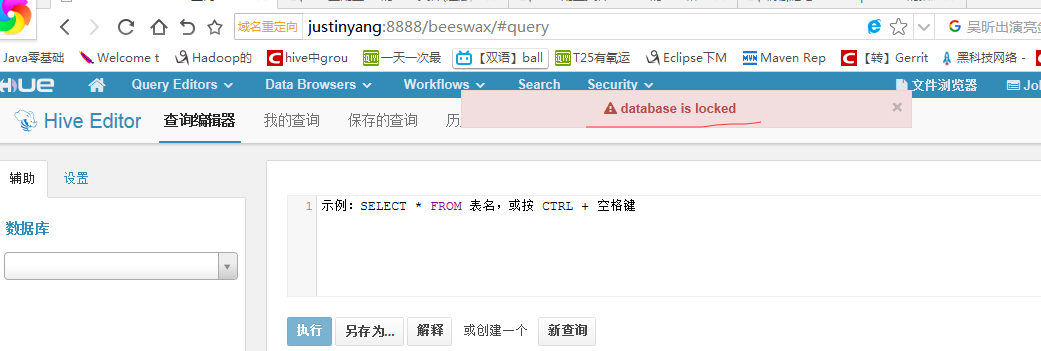
大家可以看这篇文章,如何处理数据库被锁的问题 hue集成hive访问报database is locked http://www.cnblogs.com/justinyang/p/8728522.html
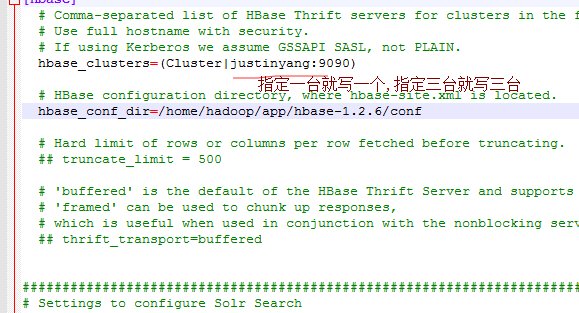
接着配置hbase,
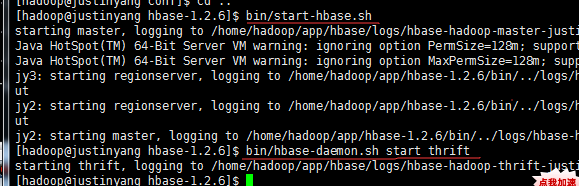
接着启动hbase和thrift服务
接着查看hbase
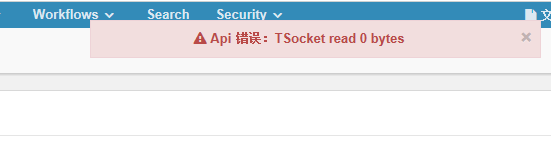
这个问题可参考http://www.cnblogs.com/justinyang/p/8728630.html来进行解决.
hadoop in hue的搭建(基于cdh版本)的更多相关文章
- Hadoop数据分析平台项目实战(基于CDH版本集群部署与安装)
1.Hadoop的主要应用场景: a.数据分析平台. b.推荐系统. c.业务系统的底层存储系统. d.业务监控系统. 2.开发环境:Linux集群(Centos64位)+Window开发模式(win ...
- CDH版本hadoop2.6伪分布式安装
1.基础环境配置 主机名 IP地址 角色 Hadoop用户 centos05 192.168.48.105 NameNode.ResourceManager.SecondaryNameNode. Da ...
- cdh版本的hue安装配置部署以及集成hadoop hbase hive mysql等权威指南
hue下载地址:https://github.com/cloudera/hue hue学习文档地址:http://archive.cloudera.com/cdh5/cdh/5/hue-3.7.0-c ...
- CDH版本大数据集群下搭建Hue(hadoop-2.6.0-cdh5.5.4.gz + hue-3.9.0-cdh5.5.4.tar.gz)(博主推荐)
不多说,直接上干货! 我的集群机器情况是 bigdatamaster(192.168.80.10).bigdataslave1(192.168.80.11)和bigdataslave2(192.168 ...
- CDH版本大数据集群下搭建的Hue详细启动步骤(图文详解)
关于安装请见 CDH版本大数据集群下搭建Hue(hadoop-2.6.0-cdh5.5.4.gz + hue-3.9.0-cdh5.5.4.tar.gz)(博主推荐) Hue的启动 也就是说,你Hue ...
- 【Hadoop离线基础总结】CDH版本Hadoop 伪分布式环境搭建
CDH版本Hadoop 伪分布式环境搭建 服务规划 步骤 第一步:上传压缩包并解压 cd /export/softwares/ tar -zxvf hadoop-2.6.0-cdh5.14.0.tar ...
- 【Hadoop离线基础总结】CDH版本的zookeeper环境搭建
CDH版本的zookeeper环境搭建 下载 下载地址 http://archive.cloudera.com/cdh5/cdh/5/ 修改配置文件 创建ZooKeeper数据存放目录 mkdir - ...
- 搭建 CDH 版本hive
搭建一个完整的cdh 的版本,由于涉及的产品和步骤太多,在客户那里部署环境时,很容易出现意外,所以如果只是需要部署一个测试环境来进行验证,我们没有必要完完整整的部署整个cdh. 下面是通过命令行的 ...
- Hadoop 系列(八)—— 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
随机推荐
- FileReader对象的readAsDataURL方法来读取图像文件
FileReader对象的readAsDataURL方法可以将读取到的文件编码成Data URL.Data URL是一项特殊的技术,可以将资料(例如图片)内嵌在网页之中,不用放到外部文件.使用Dat ...
- reinterpret_cast,static_cast, dynamic_cast,const_cast的运用分析
reinterpret_cast(重新解释类型转换) reinterpret_cast 最famous的特性就是什么都可以,转换任意的类型,包括C++所有通用类型,所以也最不安全 应用 整形和指针之间 ...
- Vue常用开源项目汇总
前言:Vue (读音 /vjuː/,类似于 view) 是一套用于构建用户界面的渐进式框架.与其它大型框架不同的是,Vue 被设计为可以自底向上逐层应用.Vue 的核心库只关注视图层,不仅易于上手,还 ...
- java并发编程基础 --- 7章节 java中的13个原子操作类
当程序更新一个变量时,如果多线程同时更新这个变量,可能得到期望之外的值,比如变量 i=1,A线程更新 i+1,B线程也更新 I+1,经过两个线程的操作之后可能 I不等于3,而是等于2.因为A和B线程更 ...
- java中的notify和notifyAll有什么区别?
先说两个概念:锁池和等待池 锁池:假设线程A已经拥有了某个对象(注意:不是类)的锁,而其它的线程想要调用这个对象的某个synchronized方法(或者synchronized块),由于这些线程在进入 ...
- 如何使用maven搭建web项目
博客园注册了有二十多天了,还没有写过博客,今天就发一篇,也便于后面查找笔记. 我个人已经做了几年的java web开发了,由于所在的公司是业务型公司,用的都是一些老旧的稳定技术,很少接触到稍微新点的内 ...
- 云计算之路-阿里云上-容器难容:容器服务故障以及自建 docker swarm 集群故障
3月21日,由于使用阿里云服务器自建 docker swarm 集群的不稳定,我们将自建 docker swarm 集群上的所有应用切换阿里云容器服务 swarm 版(非swarm mode). 3月 ...
- Semaphore 源码分析
Semaphore 源码分析 1. 在阅读源码时做了大量的注释,并且做了一些测试分析源码内的执行流程,由于博客篇幅有限,并且代码阅读起来没有 IDE 方便,所以在 github 上提供JDK1.8 的 ...
- 20155227 实现mypwd
20155227 实现mypwd 1 学习pwd命令 2 研究pwd实现需要的系统调用(man -k; grep),写出伪代码 3 实现mypwd 4 测试mypwd 课堂学习笔记 实现mypwd 在 ...
- Beta阶段敏捷冲刺报告-DAY5
Beta阶段敏捷冲刺报告-DAY5 Scrum Meeting 敏捷开发日期 2017.11.6 会议时间 12:00 会议地点 软工所 参会人员 全体成员 会议内容 乱序问题的解决,异常输入提示 讨 ...