Spark DataFrame写入HBase的常用方式
Spark是目前最流行的分布式计算框架,而HBase则是在HDFS之上的列式分布式存储引擎,基于Spark做离线或者实时计算,数据结果保存在HBase中是目前很流行的做法。例如用户画像、单品画像、推荐系统等都可以用HBase作为存储媒介,供客户端使用。
因此Spark如何向HBase中写数据就成为很重要的一个环节了。本文将会介绍三种写入的方式,其中一种还在期待中,暂且官网即可...
代码在spark 2.2.0版本亲测
1. 基于HBase API批量写入
第一种是最简单的使用方式了,就是基于RDD的分区,由于在spark中一个partition总是存储在一个excutor上,因此可以创建一个HBase连接,提交整个partition的内容。
大致的代码是:
rdd.foreachPartition { records =>
val config = HBaseConfiguration.create
config.set("hbase.zookeeper.property.clientPort", "2181")
config.set("hbase.zookeeper.quorum", "a1,a2,a3")
val connection = ConnectionFactory.createConnection(config)
val table = connection.getTable(TableName.valueOf("rec:user_rec"))
// 举个例子而已,真实的代码根据records来
val list = new java.util.ArrayList[Put]
for(i <- 0 until 10){
val put = new Put(Bytes.toBytes(i.toString))
put.addColumn(Bytes.toBytes("t"), Bytes.toBytes("aaaa"), Bytes.toBytes("1111"))
list.add(put)
}
// 批量提交
table.put(list)
// 分区数据写入HBase后关闭连接
table.close()
}
这样每次写的代码很多,显得不够友好,如果能跟dataframe保存parquet、csv之类的就好了。下面就看看怎么实现dataframe直接写入hbase吧!
2. Hortonworks的SHC写入
由于这个插件是hortonworks提供的,maven的中央仓库并没有直接可下载的版本。需要用户下载源码自己编译打包,如果有maven私库,可以上传到自己的maven私库里面。具体的步骤可以参考如下:
2.1 下载源码、编译、上传
去官网github下载即可:https://github.com/hortonworks-spark/shc
可以直接按照下面的readme说明来,也可以跟着我的笔记走。
下载完成后,如果有自己的私库,可以修改shc中的distributionManagement。然后点击旁边的maven插件deploy发布工程,如果只想打成jar包,那就直接install就可以了。

2.2 引入
在pom.xml中引入:
<dependency>
<groupId>com.hortonworks</groupId>
<artifactId>shc-core</artifactId>
<version>1.1.2-2.2-s_2.11-SNAPSHOT</version>
</dependency>
2.3
首先创建应用程序,Application.scala
object Application {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local").appName("normal").getOrCreate()
spark.sparkContext.setLogLevel("warn")
val data = (0 to 255).map { i => HBaseRecord(i, "extra")}
val df:DataFrame = spark.createDataFrame(data)
df.write
.mode(SaveMode.Overwrite)
.options(Map(HBaseTableCatalog.tableCatalog -> catalog))
.format("org.apache.spark.sql.execution.datasources.hbase")
.save()
}
def catalog = s"""{
|"table":{"namespace":"rec", "name":"user_rec"},
|"rowkey":"key",
|"columns":{
|"col0":{"cf":"rowkey", "col":"key", "type":"string"},
|"col1":{"cf":"t", "col":"col1", "type":"boolean"},
|"col2":{"cf":"t", "col":"col2", "type":"double"},
|"col3":{"cf":"t", "col":"col3", "type":"float"},
|"col4":{"cf":"t", "col":"col4", "type":"int"},
|"col5":{"cf":"t", "col":"col5", "type":"bigint"},
|"col6":{"cf":"t", "col":"col6", "type":"smallint"},
|"col7":{"cf":"t", "col":"col7", "type":"string"},
|"col8":{"cf":"t", "col":"col8", "type":"tinyint"}
|}
|}""".stripMargin
}
case class HBaseRecord(
col0: String,
col1: Boolean,
col2: Double,
col3: Float,
col4: Int,
col5: Long,
col6: Short,
col7: String,
col8: Byte)
object HBaseRecord
{
def apply(i: Int, t: String): HBaseRecord = {
val s = s"""row${"%03d".format(i)}"""
HBaseRecord(s,
i % 2 == 0,
i.toDouble,
i.toFloat,
i,
i.toLong,
i.toShort,
s"String$i: $t",
i.toByte)
}
}
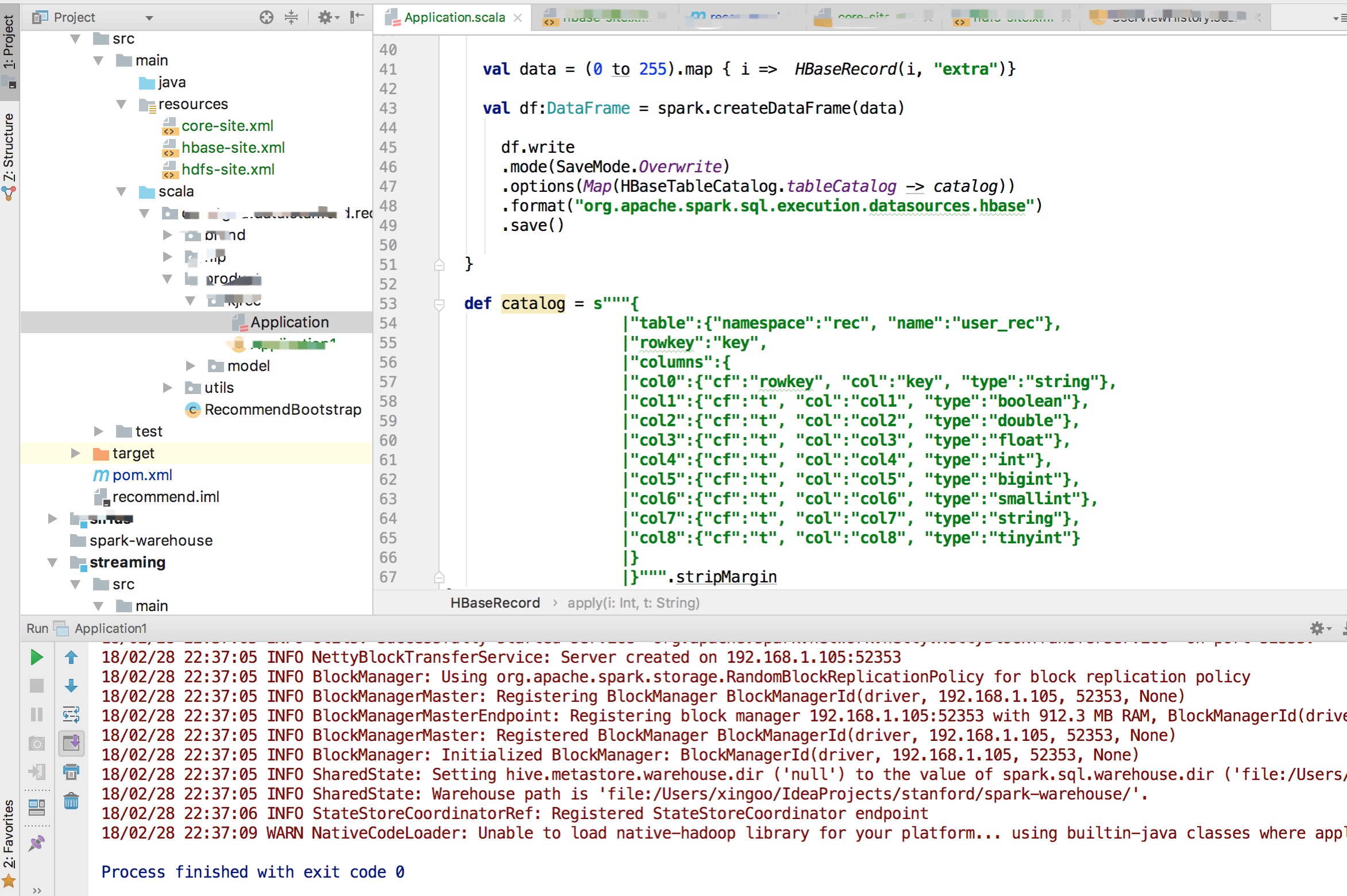
然后再resources目录下,添加hbase-site.xml、hdfs-site.xml、core-site.xml等配置文件。主要是获取Hbase中的一些连接地址。
3. HBase 2.x+即将发布的hbase-spark
如果有浏览官网习惯的同学,一定会发现,HBase官网的版本已经到了3.0.0-SNAPSHOT,并且早就在2.0版本就增加了一个hbase-spark模块,使用的方法跟上面hortonworks一样,只是format的包名不同而已,猜想就是把hortonworks给拷贝过来了。
另外Hbase-spark 2.0.0-alpha4目前已经公开在maven仓库中了。
http://mvnrepository.com/artifact/org.apache.hbase/hbase-spark
不过,内部的spark版本是1.6.0,太陈旧了!!!!真心等不起了...
期待hbase-spark官方能快点提供正式版吧。
参考
- hortonworks-spark/shc github:https://github.com/hortonworks-spark/shc
- maven仓库地址: http://mvnrepository.com/artifact/org.apache.hbase/hbase-spark
- Hbase spark sql/ dataframe官方文档:https://hbase.apache.org/book.html#_sparksql_dataframes
Spark DataFrame写入HBase的常用方式的更多相关文章
- Spark写入HBase(Bulk方式)
在使用Spark时经常需要把数据落入HBase中,如果使用普通的Java API,写入会速度很慢.还好Spark提供了Bulk写入方式的接口.那么Bulk写入与普通写入相比有什么优势呢? BulkLo ...
- spark踩坑——dataframe写入hbase连接异常
最近测试环境基于shc[https://github.com/hortonworks-spark/shc]的hbase-connector总是异常连接不到zookeeper,看下报错日志: 18/06 ...
- spark DataFrame的创建几种方式和存储
一. 从Spark2.0以上版本开始,Spark使用全新的SparkSession接口替代Spark1.6中的SQLContext及HiveContext接口来实现其对数据加载.转换.处理等功能.Sp ...
- Spark:DataFrame 写入文本文件
将DataFrame写成文件方法有很多最简单的将DataFrame转换成RDD,通过saveASTextFile进行保存但是这个方法存在一些局限性:1.将DataFrame转换成RDD或导致数据结构的 ...
- Spark如何写入HBase/Redis/MySQL/Kafka
一些概念 一个partition 对应一个task,一个task 必定存在于一个Executor,一个Executor 对应一个JVM. Partition 是一个可迭代数据集合 Task 本质是作用 ...
- spark运算结果写入hbase及优化
在Spark中利用map-reduce或者spark sql分析了数据之后,我们需要将结果写入外部文件系统. 本文,以向Hbase中写数据,为例,说一下,Spark怎么向Hbase中写数据. 首先,需 ...
- Spark:将DataFrame写入Mysql
Spark将DataFrame进行一些列处理后,需要将之写入mysql,下面是实现过程 1.mysql的信息 mysql的信息我保存在了外部的配置文件,这样方便后续的配置添加. //配置文件示例: [ ...
- 大数据学习day34---spark14------1 redis的事务(pipeline)测试 ,2. 利用redis的pipeline实现数据统计的exactlyonce ,3 SparkStreaming中数据写入Hbase实现ExactlyOnce, 4.Spark StandAlone的执行模式,5 spark on yarn
1 redis的事务(pipeline)测试 Redis本身对数据进行操作,单条命令是原子性的,但事务不保证原子性,且没有回滚.事务中任何命令执行失败,其余的命令仍会被执行,将Redis的多个操作放到 ...
- MapReduce和Spark写入Hbase多表总结
作者:Syn良子 出处:http://www.cnblogs.com/cssdongl 转载请注明出处 大家都知道用mapreduce或者spark写入已知的hbase中的表时,直接在mapreduc ...
随机推荐
- struts2 从一个action跳转到另一个action的struts.xml文件的配置
解释: 想要用<result>跳转到另一个action,原来的配置代码是: <action name="insertDept" class="strut ...
- Linuxc - define 与 typedef的区别
预处理就是讲一些头文件展开. 预处理还会将使用到宏定义的值替换为真正的值.宏只是单纯的字符串的替换. #define 宏定义 眼里没有语法,不用分号结尾. typedef 定义别名,是有语法的,要用分 ...
- python3 第六章 - 条件判断
Python条件语句是通过一条或多条语句的执行结果(True或者False)来决定执行的代码块. 条件语句的执行过程,如下图: 条件语句,又称为if语句,它的完整语法如下: if 条件1: 语句块1 ...
- CentOS6.x机器安装Azure CLI2.0【2】
安装Azure CLI 2.0的前提是:机器中必须有 Python 2.7.x 或 Python 3.x.如果机器中没有其中任何一个Python版本,请及时安装 1.准备一台CentOS 6.9的机器 ...
- WebSphere--连接管理器
连接管理器使您可以控制并减少由 Web 应用程序使用的资源.相对于非 Web 应用程序,基于 Web 的应用程序对数据服务器的访问会导致更高的和不可预料的系统开销,这是由于 Web 用户更为频繁的连接 ...
- [JAVA] - 从 m 个元素中随机选中 n 个
之前业务中曾经遇到过从m个元素中选取 n 个的需求,当时只是跑循环根据长度进行随机选取,然后放入 Set 中去重,一直到收集到足够的个数. 这样做的缺点很明显,当剩下的元素个数越少的时候,选取的元素越 ...
- 错误:This function has none of DETERMINISTIC... 的解决
问题: 在MySQL创建了一个批量插入的存储过程,在代码中调用的时候报错误信息: error code [1418];This function has none of DETERMINISTIC, ...
- Storm Topology Parallelism
Understanding the Parallelism of a Storm Topology What makes a running topology: worker processes, e ...
- A/X家FPGA架构及资源评估
评估对比xilinx以及altera两家FPGA芯片逻辑资源. 首先要说明, 现今FPGA除了常规逻辑资源,还具有很多其他片内资源比如块RAM.DSP单元.高速串行收发器.PLL.ADC等等,用以应对 ...
- zabbix图形乱码
毕竟是中文为主,特别是有些香项目最好以中文命名,容易区分,也方便识别 环境: centos7.3安装zabbix3.2 问题: 图文乱码问题 原理上只要找到对应的字符集,在修改配置文件 windows ...