goroutine调度
0.1、索引
https://blog.waterflow.link/articles/1662974432717
1、进程
一个进程包含可以由任何进程分配的公共资源。这些资源包括但不限于内存地址空间、文件句柄、设备和线程。
一个进程会包含下面一些属性:
- Process ID:进程ID
- Process State:进程状态
- Process Priority:进程优先级
- Program Counter:程序计数器
- General purpose register:通用寄存器
- List of open files:打开的文件列表
- List of open devices:打开的设备列表
- Protection information:保护信息
- List of the child process:子进程列表
- Pending alarms:待定警告
- Signals and signal handlers:信号和信号处理程序
- Accounting information:记账信息
2、线程
线程是轻量级的进程,一个线程将在进程内的所有线程之间共享进程的资源,如代码、数据、全局变量、文件和内存地址空间。但是栈和寄存器不会共享,每个线程都有自己的栈和寄存器
线程的优点:
- 提高系统的吞吐量
- 提高响应能力
- 由于属性更少,上下文切换更快
- 多核CPU的有效利用
- 资源共享(代码、数据、地址空间、文件、全局变量)
3、用户级线程
用户级线程也称为绿色线程,如:C 中的coroutine、Go 中的 goroutine 和 Ruby 中的 Fiber
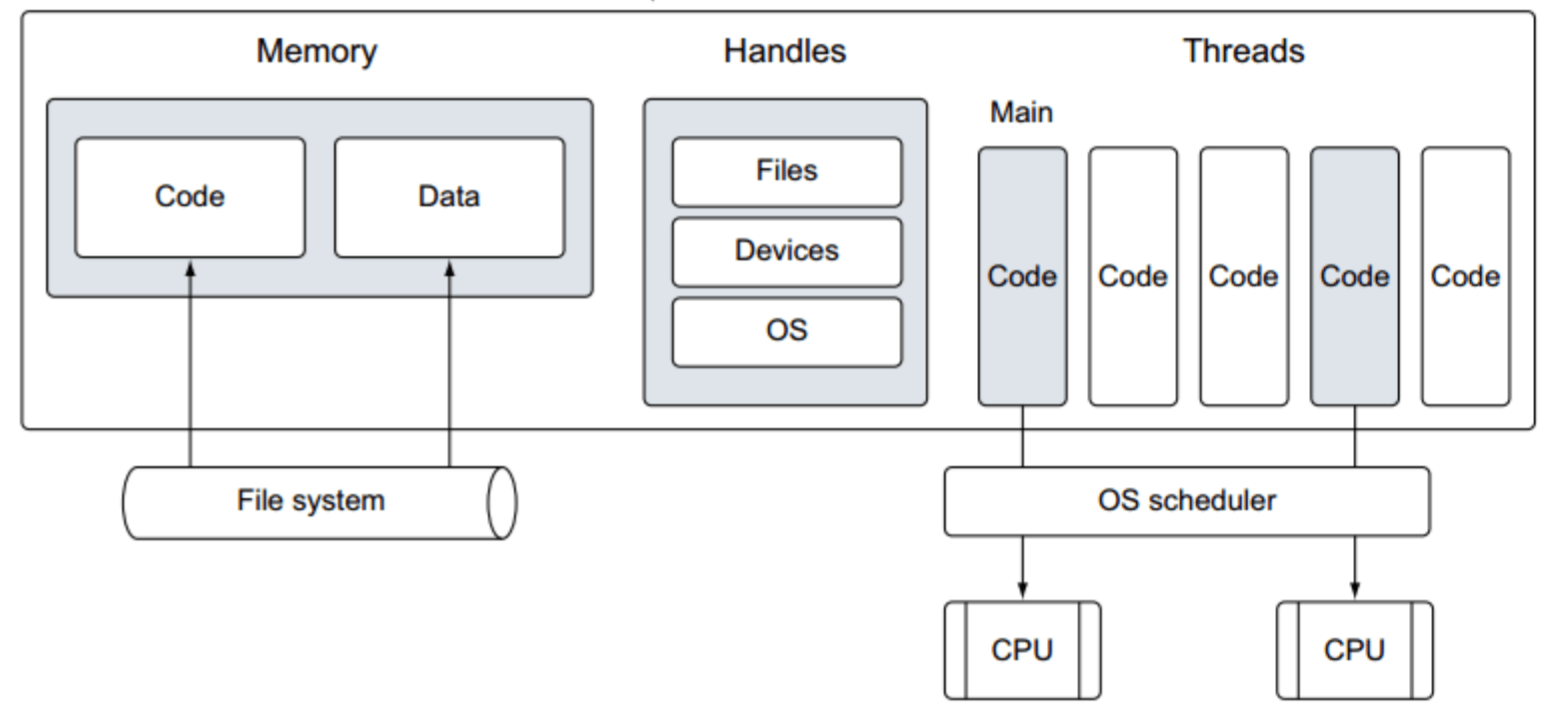
该进程维护一个内存地址空间,处理文件,以及正在运行的应用程序的设备和线程。操作系统调度程序决定哪些线程将在任何给定的 CPU 上接收时间
因此,与耗时和资源密集型的进程创建相比,在一个进程中创建多个用户线程(goroutine)效率更高。
4、goroutine
在Go中用户级线程被称作Goroutine,在创建goroutine时需要做到:
- 易于创建
- 轻量级
- 并发执行
- 可扩展
- 无限堆栈(最大堆栈大小在 64 位上为 1 GB,在 32 位上为 250 MB。)
- 处理阻塞调用
- 高效 (work stealing)
其中阻塞调用可能是下面一些原因:
- 在channel中收发数据
- 网络IO调用
- 阻塞的系统调用
- 计时器
- 互斥操作(Mutex)
为什么go需要调度goroutine?
Go 使用称为 goroutine 的用户级线程,它比内核级线程更轻且更便宜。 例如,创建一个初始 goroutine 将占用 2KB 的堆栈大小,而内核级线程将占用 8KB 的堆栈大小。 还有,goroutine 比内核线程有更快的创建、销毁和上下文切换,所以 go 调度器 需要退出来调度 goroutine。OS 不能调度用户级线程,OS 只知道内核级线程。 Go 调度器 将 goroutine 多路复用到内核级线程,这些线程将在不同的 CPU 内核上运行
什么时候会调度goroutine?
如果有任何操作应该或将会影响 goroutine 的执行,比如 goroutine 的启动、等待执行和阻塞调用等……
go调度 如何将 goroutine 多路复用到内核线程中?
1、1:1调度(1个线程对应一个goroutine)
- 并行执行(每个线程可以在不同的内核上运行)
- 可以工作但是代价太高
- 内存至少〜32k(用户堆栈和内核堆栈的内存)
- 性能问题(系统调用)
- 没有无限堆栈
2、N:1调度(在单个内核线程上多路复用所有 goroutine)
- 没有并行性(即使有更多 CPU 内核可用,也只能使用单个 CPU 内核)
我们看下下面的例子,只为go分配了1个processer去处理2个goroutine:
package main
import (
"fmt"
"runtime"
"sync"
"time"
)
func main() {
// 分配 1 个逻辑处理器供调度程序使用
runtime.GOMAXPROCS(1)
var wg sync.WaitGroup
wg.Add(2)
fmt.Println("Starting Goroutines")
// 开一个go协程打印字母
go func() {
defer wg.Done()
time.Sleep(time.Second)
// 打印3次字母
for count := 0; count < 3; count++ {
for ch := 'a'; ch < 'a'+26; ch++ {
fmt.Printf("%c ", ch)
}
fmt.Println()
}
}()
// 开一个go协程打印数字
go func() {
defer wg.Done()
// 打印3次数字
for count := 0; count < 3; count++ {
for n := 1; n <= 26; n++ {
fmt.Printf("%d ", n)
}
fmt.Println()
}
}()
// 等待返回
fmt.Println("Waiting To Finish")
wg.Wait()
fmt.Println("\nTerminating Program")
}
看下结果:
go run main.go
Starting Goroutines
Waiting To Finish
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
a b c d e f g h i j k l m n o p q r s t u v w x y z
a b c d e f g h i j k l m n o p q r s t u v w x y z
a b c d e f g h i j k l m n o p q r s t u v w x y z
Terminating Program
可以看到这俩个goroutine是串行执行的,要么先完成第一个goroutine,要么先完成第二个goroutine,并不是并发执行的。
那如何去实现并发执行呢?
我们同样设置runtime.GOMAXPROCS为1,但是在goroutine中我们在不同的时机加入阻塞goroutine的时间函数time.Sleep,我们看下会有什么不同的结果。
package main
import (
"fmt"
"runtime"
"sync"
"time"
)
func main() {
// 分配 1 个逻辑处理器供调度程序使用
runtime.GOMAXPROCS(1)
var wg sync.WaitGroup
wg.Add(2)
fmt.Println("Starting Goroutines")
// 开一个go协程打印字母
go func() {
defer wg.Done()
time.Sleep(time.Second)
// 打印3次字母
for count := 0; count < 3; count++ {
for ch := 'a'; ch < 'a'+26; ch++ {
if count == 0 {
time.Sleep(10 * time.Millisecond)
}
if count == 1 {
time.Sleep(30 * time.Millisecond)
}
if count == 2 {
time.Sleep(50 * time.Millisecond)
}
fmt.Printf("%c ", ch)
}
fmt.Println()
}
}()
// 开一个go协程打印数字
go func() {
defer wg.Done()
// 打印3次数字
for count := 0; count < 3; count++ {
for n := 1; n <= 26; n++ {
if count == 0 {
time.Sleep(20 * time.Millisecond)
}
if count == 1 {
time.Sleep(40 * time.Millisecond)
}
if count == 2 {
time.Sleep(60 * time.Millisecond)
}
fmt.Printf("%d ", n)
}
fmt.Println()
}
}()
// 等待返回
fmt.Println("Waiting To Finish")
wg.Wait()
fmt.Println("\nTerminating Program")
}
看下结果:
go run main.go
Starting Goroutines
Waiting To Finish
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
1 2 3 4 5 6 7 8 9 10 11 a 12 b c d e 13 f g h i 14 j k l m 15 n o p 16 q r s t 17 u v w x 18 y z
19 a b 20 c 21 d 22 e f 23 g 24 h 25 i j 26
k l 1 m n 2 o p 3 q r 4 s t 5 u v 6 w x 7 y z
8 a 9 b 10 c 11 d 12 e f 13 g 14 h 15 i 16 j 17 k l 18 m 19 n 20 o 21 p 22 q r 23 s 24 t 25 u 26
v w x y z
Terminating Program
通过上面的结果我们可以看到,当goroutine1阻塞时,go调度器会调度goroutine2执行。
我们可以得出:
- 即使我们将 runtime.GOMAXPROCS(1) 设置为 1,程序也在并发运行
- Running 状态的 Goroutine 数量最大为 1,Block Goroutine 可以多于一个,其他所有 Goroutine 都处于 Runnable 状态
3、线程池
- 在需要时创建一个线程,这意味着如果有 goroutine 要运行但所有其他线程都忙,则创建一个线程
- 一旦线程完成其执行而不是销毁重用它
- 这可以更快的创建goroutine,因为我们可以重用线程
- 但是还有更多的内存消耗,性能问题,并且没有无限堆栈。
4、M: N 线程共享运行队列调度(GMP)
- M代表系统线程的数量
- N代表goroutine的数量
- goroutine 的创建成本很低,我们可以完全控制 goroutine 的整个生命周期,因为它是在用户空间中创建的
- 创建一个操作系统线程很昂贵,我们无法控制它,但是使用多个线程我们可以实现并行
- 在这个模型中,多个 goroutine 被多路复用到内核线程中
我们上面提到过导致goroutine阻塞调用可能是下面一些原因:
- 在channel中收发数据
- 网络IO调用
- 阻塞的系统调用
- 计时器
- 互斥操作(Mutex)
下面看一些goroutine阻塞的例子:
package main
import (
"time"
"fmt"
"sync"
"os"
"net/http"
"io/ioutil"
)
// 全局变量
var worker int
func writeToFile(wg *sync.WaitGroup,){
defer wg.Done()
file, _ := os.OpenFile("file.txt", os.O_RDWR|os.O_CREATE, 0755) // 系统调用阻塞
resp, _ := http.Get("https://blog.waterflow.link/articles/1662706601117") // 网络IO阻塞
body, _ := ioutil.ReadAll(resp.Body) // 系统调用阻塞
file.WriteString(string(body))
}
func workerCount(wg *sync.WaitGroup, m *sync.Mutex, ch chan string) {
// Lock() 给共享资源上锁
// 独占访问状态,
// 增加worker的值,
// Unlock() 释放锁
m.Lock() // Mutex阻塞
worker = worker + 1
ch <- fmt.Sprintf("Worker %d is ready",worker)
m.Unlock()
// 返回, 通知WaitGroup完成
wg.Done()
}
func printWorker(wg *sync.WaitGroup, done chan bool, ch chan string){
for i:=0;i<100;i++{
fmt.Println(<-ch) // Channel阻塞
}
wg.Done()
done <-true
}
func main() {
ch :=make(chan string)
done :=make(chan bool)
var mu sync.Mutex
var wg sync.WaitGroup
for i:=1;i<=100;i++{
wg.Add(1)
go workerCount(&wg,&mu,ch)
}
wg.Add(2)
go writeToFile(&wg)
go printWorker(&wg,done,ch)
wg.Wait()
<-done // Channel阻塞
<-time.After(1*time.Second) // Timer阻塞
close(ch)
close(done)
}
下面我们看看go调度器在上面这些例子中是如何工作的:
- 如果一个 goroutine 在通道上被阻塞,则通道有等待队列,所有阻塞的 goroutine 都列在等待队列中,并且很容易跟踪。 在阻塞调用之后,它们将被放入 schedular 的全局运行队列中,OS Thread 将再次按照 FIFO 的顺序选择 goroutine。
- M1,M2,M3尝试从全局G队列中获取G
- M1获取锁并拿到G1,然后释放锁
- M3获取锁拿到G2,然后释放锁
- M2获取锁拿到G3,然后释放锁
- G1在ch1的channel中阻塞,然后添加到ch1的等待队列。导致M1空闲
- M1不能闲着,从全局队列获取锁拿到G4,然后释放锁
- G3阻塞在ch2的channel中,然后被放到ch2的等待队列。导致M2空闲
- M2获取锁拿到G5,然后释放锁
- 此时G3在ch2结束阻塞,被放到全局队列尾部等待执行
- G1在ch1结束阻塞,被放到全局队列尾部等待执行
- G4,G5,G2执行完成
- M1,M2,M3重复步骤1-4
互斥锁、定时器和网络 IO 使用相同的机制
如果一个 goroutine 在系统调用中被阻塞,那么情况就不同了,因为我们不知道内核空间发生了什么。 通道是在用户空间中创建的,因此我们可以完全控制它们,但在系统调用的情况下,我们没法控制它们。
阻塞系统调用不仅会阻塞 goroutine 还会阻塞内核线程。
假设一个 goroutine 被安排在一个内核线程上的系统调用,当一个内核线程完成执行时,它将唤醒另一个内核线程(线程重用),该线程将拾取另一个 goroutine 并开始执行它。 这是一个理想的场景,但在实际情况下,我们不知道系统调用将花费多少时间,因此我们不能依赖内核线程来唤醒另一个线程,我们需要一些代码级逻辑来决定何时 在系统调用的情况下唤醒另一个线程。 这个逻辑在 golang 中实现为 runtime·entersyscall()和 runtime·exitsyscall()。 这意味着内核线程的数量可以超过核心的数量。
当对内核进行系统调用时,它有两个关键点,一个是进入时机,另一个是退出时机。
- M1,M2试着从全局队列拿G
- M1获取锁并拿到G1,然后释放锁
- M2获取锁并拿到G2,然后释放锁
- M2阻塞在系统调用,没有可用的内核线程,所以go调度器创建一个新的线程M3
- M3获取锁并拿到G3,然后释放锁
- 此时M2结束阻塞状态,重新把G2放到全局队列(G2由阻塞变为可执行状态)。M2虽然是空闲状态,但是go调度器不会销毁它,而是自旋发现新的可执行的goroutine。
- G1,G3执行结束
- M1,M3重复步骤1-3
操作系统可以支持多少内核线程?
在 Linux 内核中,此参数在文件 /proc/sys/kernel/threads-max 中定义,该文件用于特定内核。
sh:~$ cat /proc/sys/kernel/threads-max 94751
这里输出94751表示内核最多可以执行94751个线程
每个 Go 程序可以支持多少个 goroutine?
调度中没有内置对 goroutine 数量的限制。
每个 GO程序 可以支持多少个内核线程?
默认情况下,运行时将每个程序限制为最多 10,000 个线程。可以通过调用 runtime/debug 包中的 SetMaxThreads 函数来更改此值。
总结:
- 内核线程数可以多于内核数
- 轻量级 goroutine
- 处理 IO 和系统调用
- goroutine并行执行
- 不可扩展(所有内核级线程都尝试使用互斥锁访问全局运行队列。因此,由于竞争,这不容易扩展)
5、M:N 线程分布式运行队列调度器
为了解决每个线程同时尝试访问互斥锁的可扩展问题,维护每个线程的本地运行队列
- 每个线程状态(本地运行队列)
- 仍然有一个全局运行队列
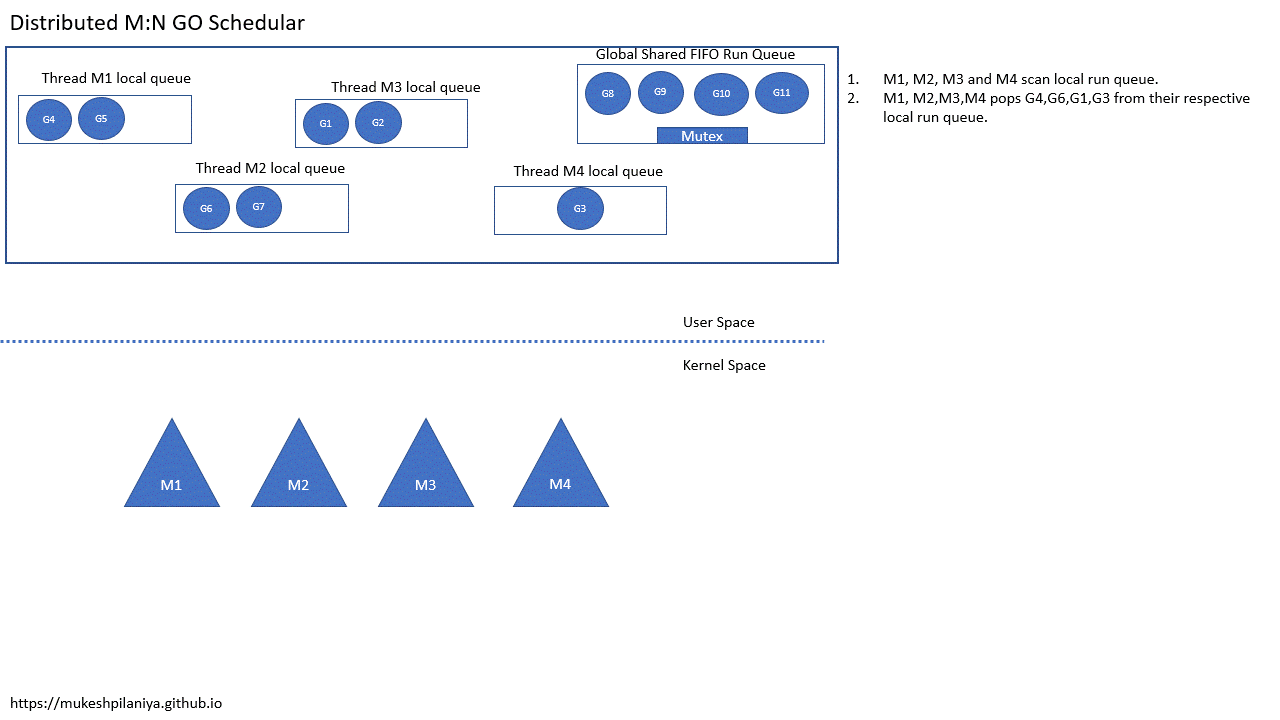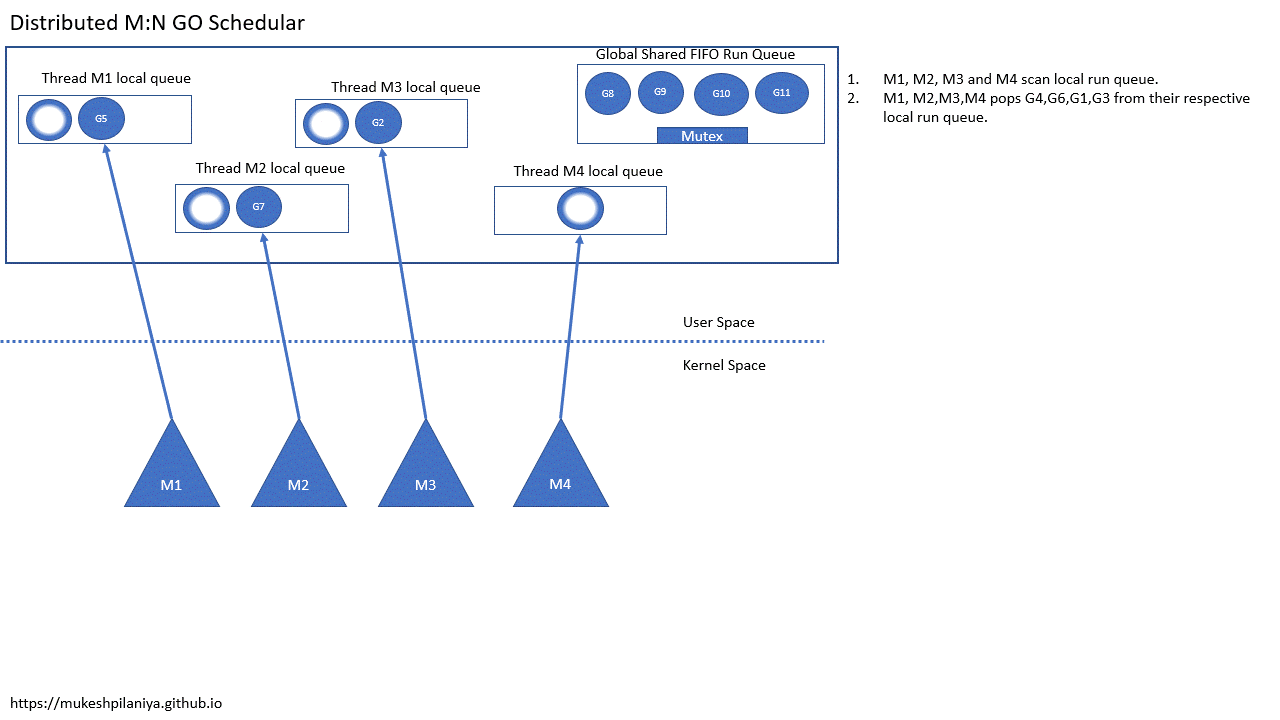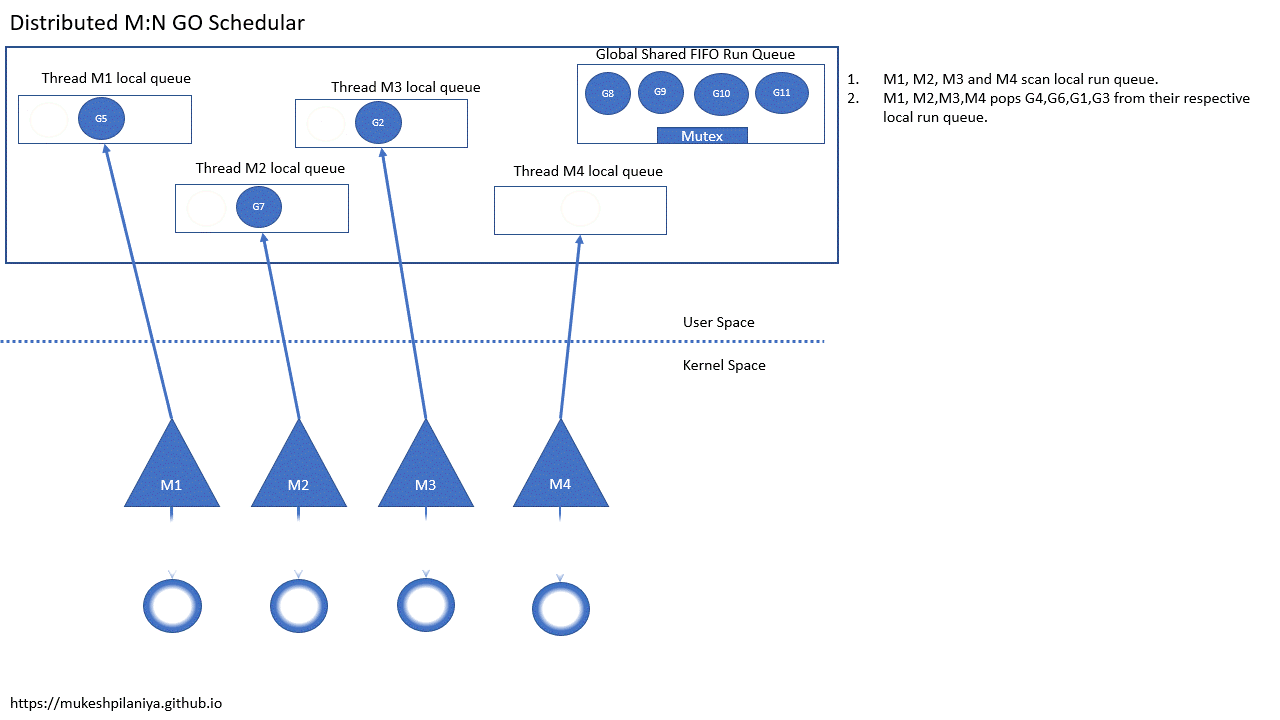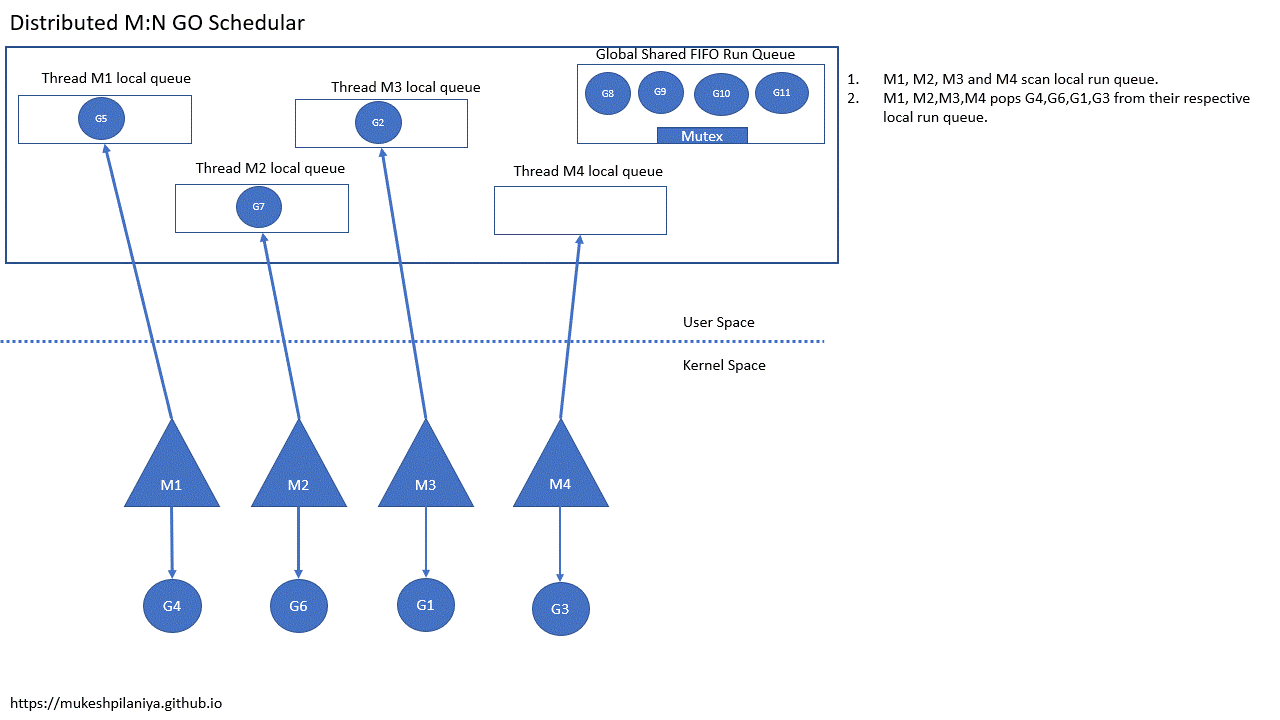
- M1,M2,M3,M4扫描本地可运行队列
- M1,M2,M3,M4从各自的本地队列取出G4,G6,G1,G3
从上面的动图可以看到:
- 从本地队列拿G是不需要加锁的
- 可运行 goroutine 的全局队列需要锁
结论:
- 轻量级 goroutine
- 处理 IO 和 SystemCalls
- goroutine 并行执行
- 可扩展
- 高效
如果线程数大于内核数,那么会有什么问题呢?
在分布式运行队列调度中,我们知道每个线程都有自己的本地运行队列,其中包含有关接下来将执行哪个 goroutine 的信息。 同样由于系统调用,线程数会增加,并且大多数时候它们的本地运行队列是空的。 因此,如果线程数大于核心数,则每个线程必须扫描所有线程本地运行队列,并且大部分时间它们是空的,所以如果线程过多,这个过程是耗时的并且解决方案 效率不高,因此我们需要将线程扫描限制为使用 M:P:N 线程模型求解的常数。
6、M:P: N 线程
- P 代表处理器,它是运行 go 代码所需的资源。 处理器结构详细信息 https://github.com/golang/go/blob/63e129ba1c458db23f0752d106ed088a2cf38360/src/runtime/runtime2.go#L601
- M 代表工作线程或机器。 机器线程结构详细信息 https://github.com/golang/go/blob/63e129ba1c458db23f0752d106ed088a2cf38360/src/runtime/runtime2.go#L519
- G 代表 goroutine。 Goroutine 结构细节 https://github.com/golang/go/blob/63e129ba1c458db23f0752d106ed088a2cf38360/src/runtime/runtime2.go#L407
- 通常,P的数量与逻辑处理器的数量相同
- 逻辑处理器与物理处理器不同(比如我的mac逻辑处理器是8,无力处理器是4)
- 在启动main goroutine之前创建P
如何检查逻辑处理器的数量?
package main
import (
"fmt"
"runtime"
)
func main() {
fmt.Println(runtime.NumCPU())
}
分布式 M:P:N 调度例子
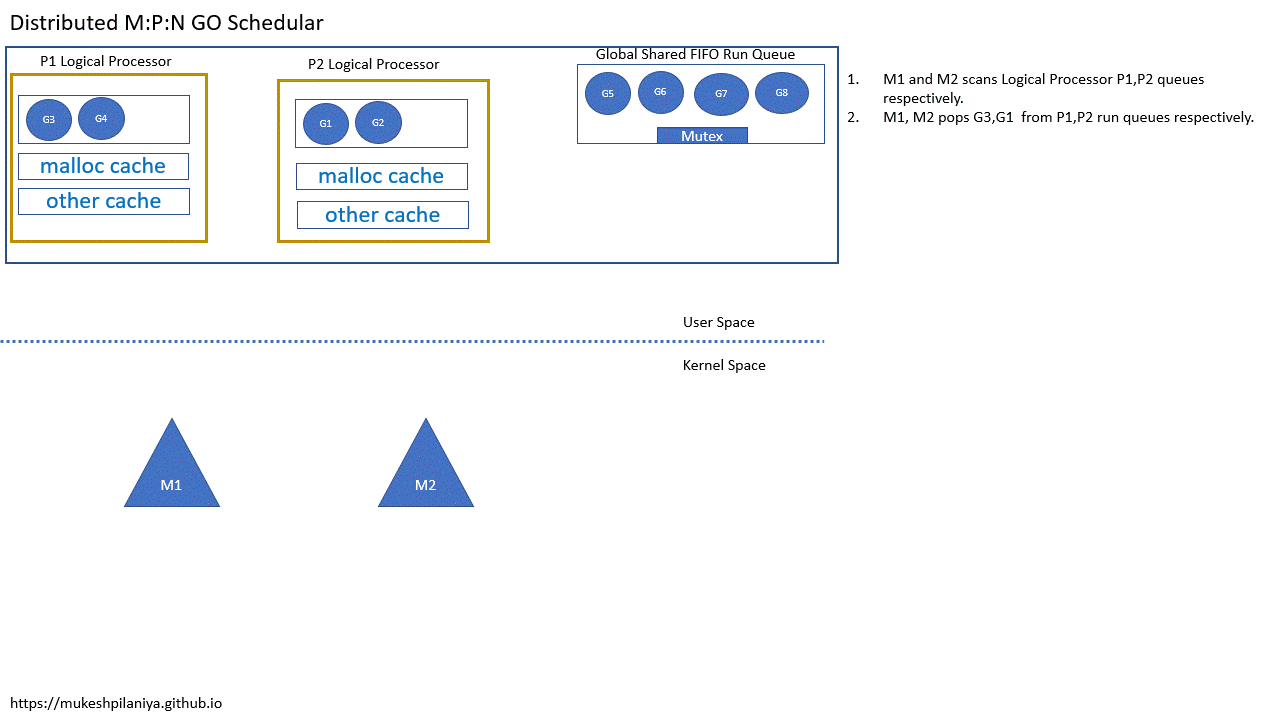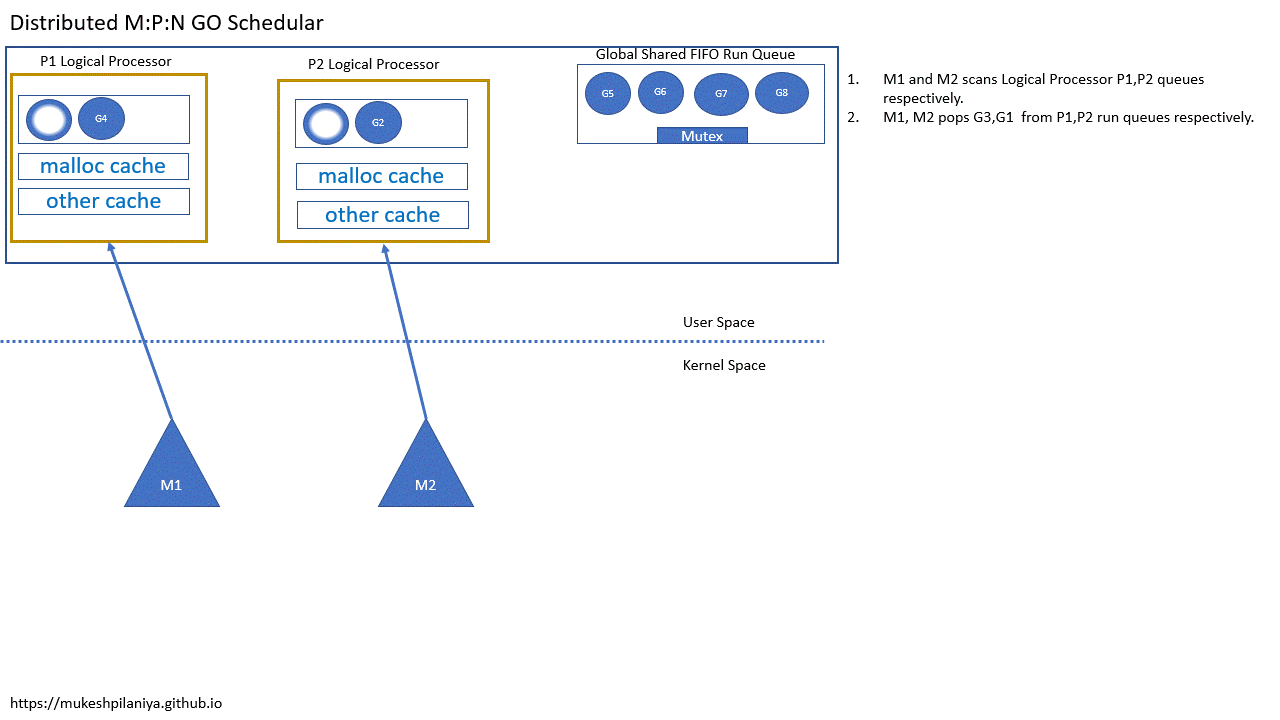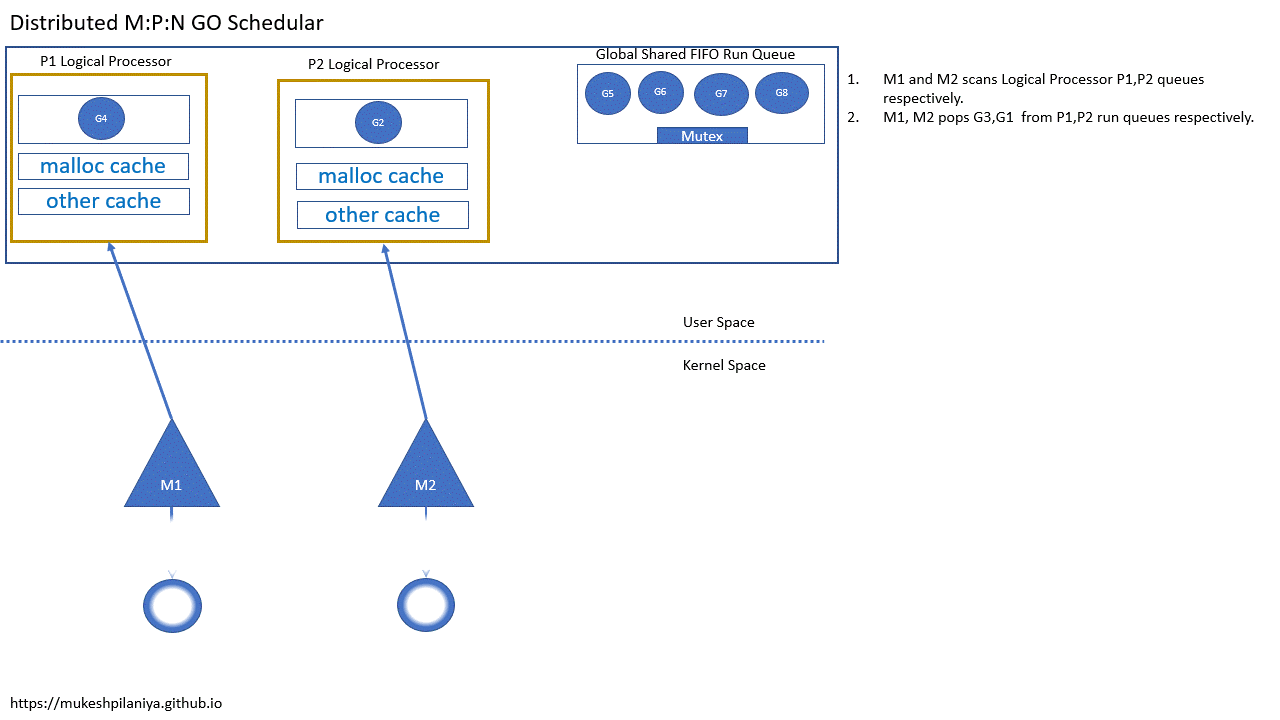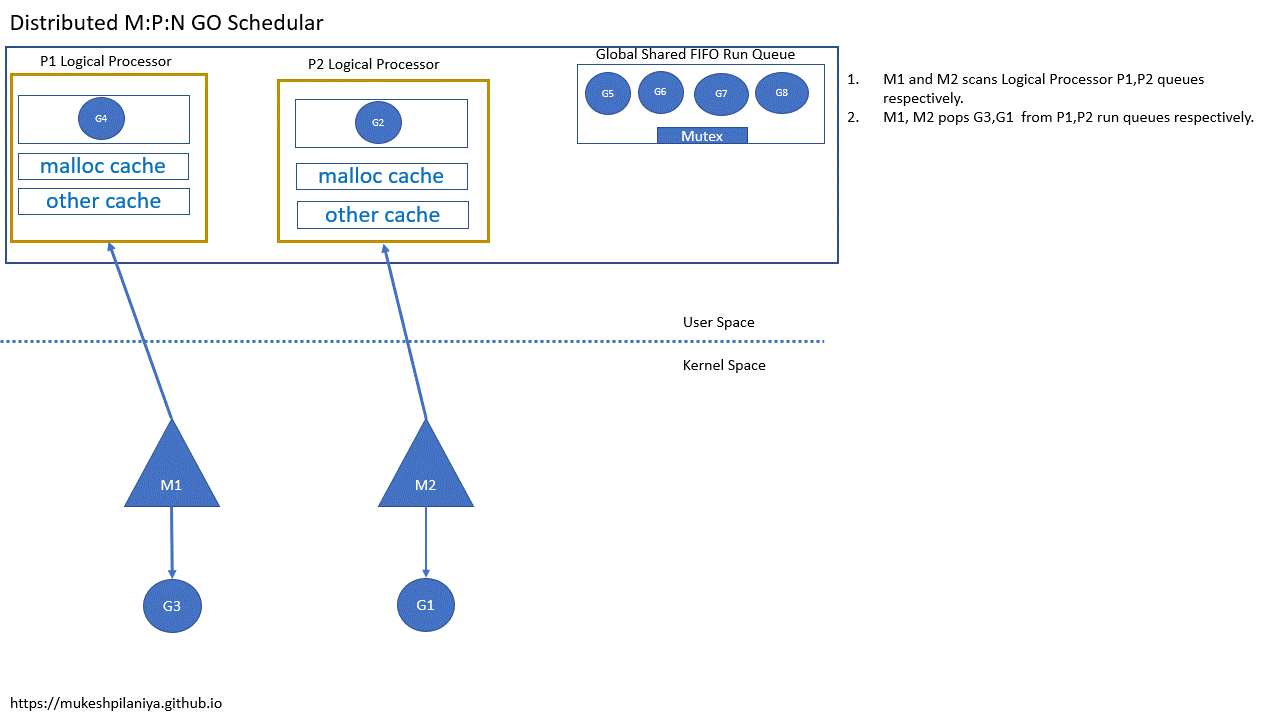
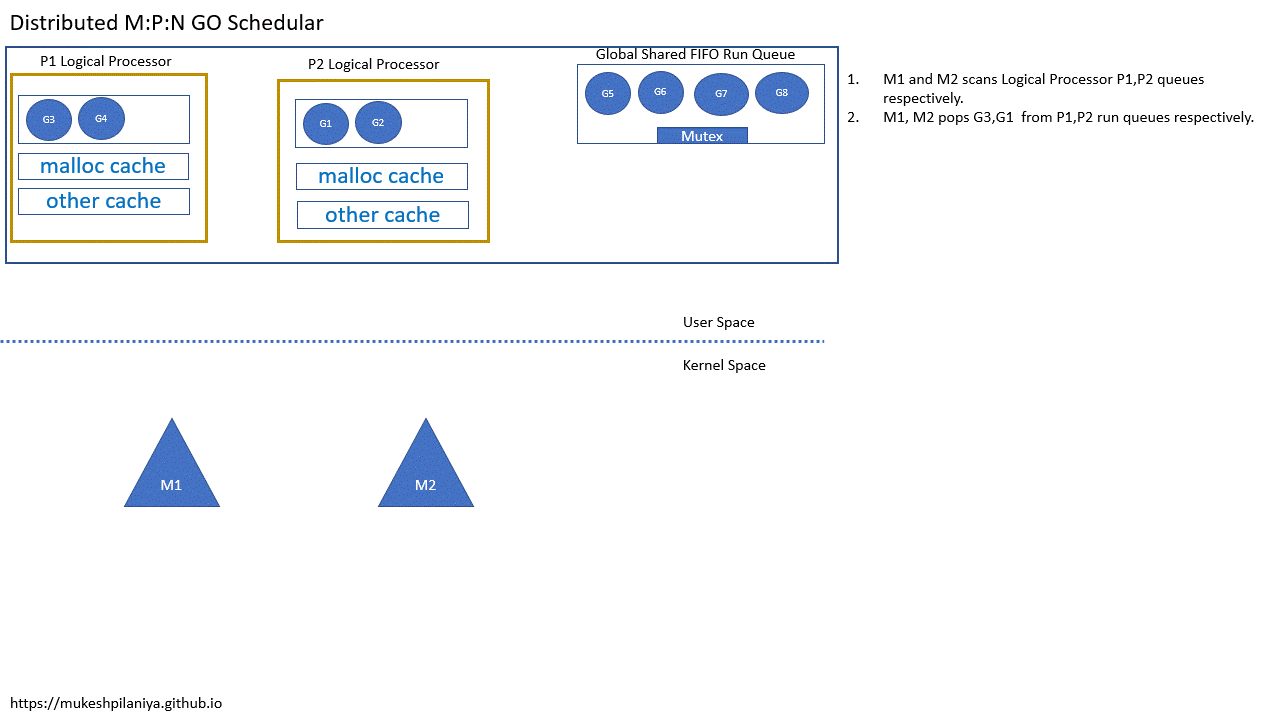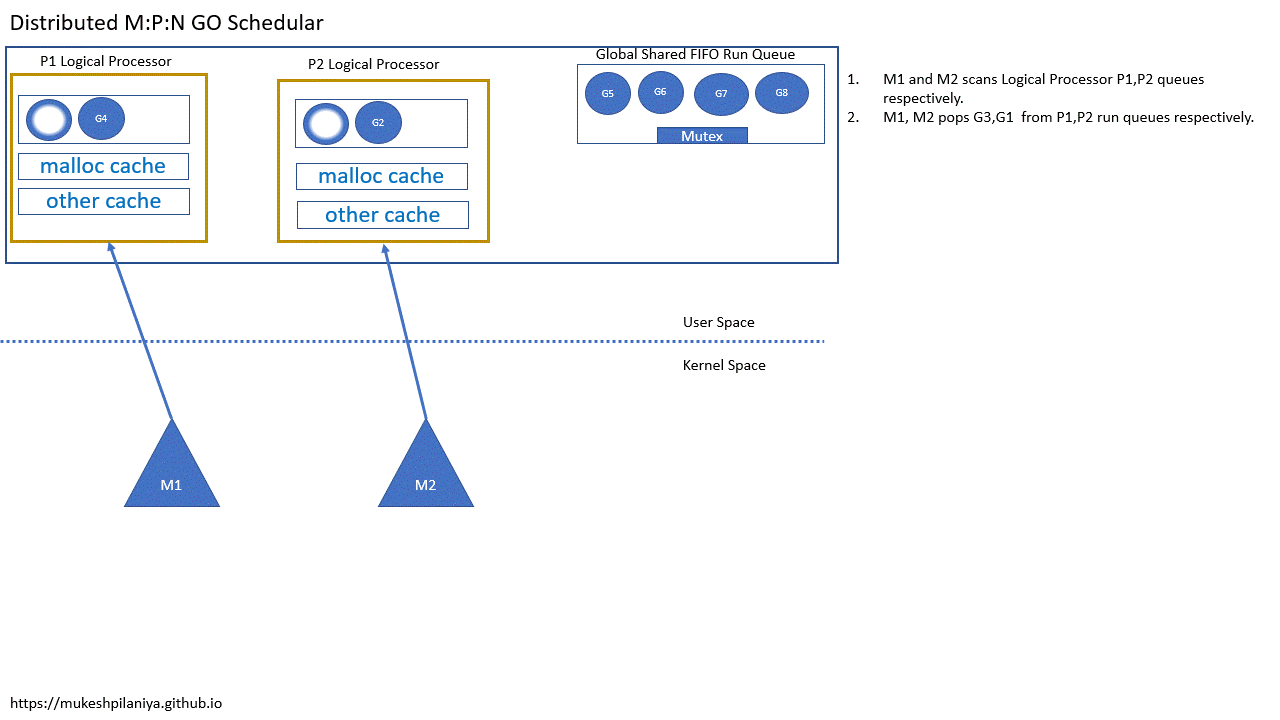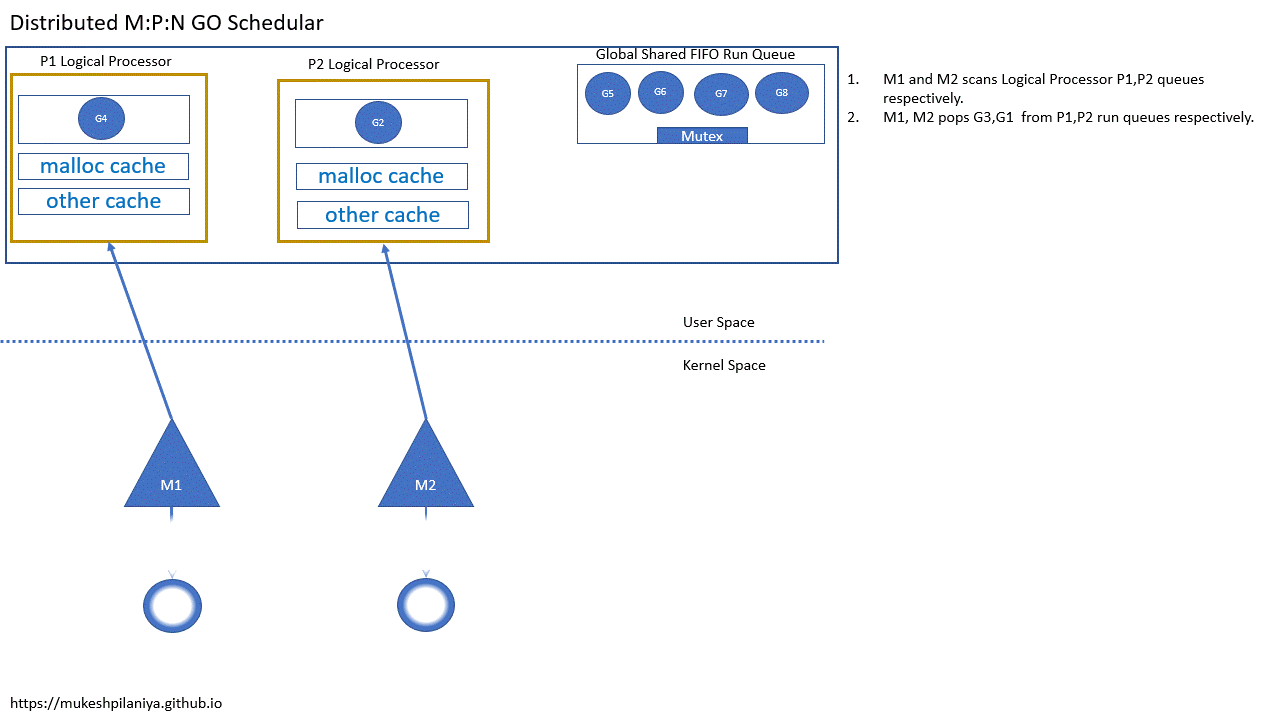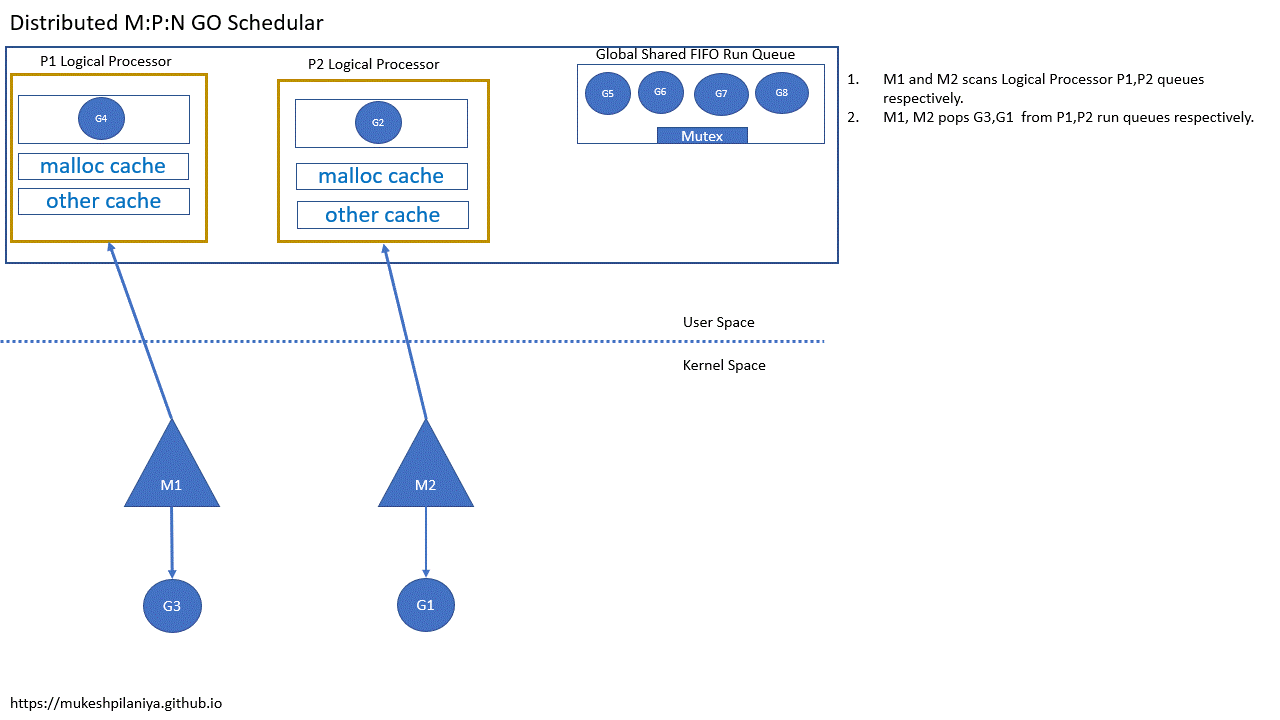
- M1,M2各自扫描P1,P2的队列
- M1,M2从各自的P1,P2中取出G3,G1执行
在系统调用期间执行P的切换
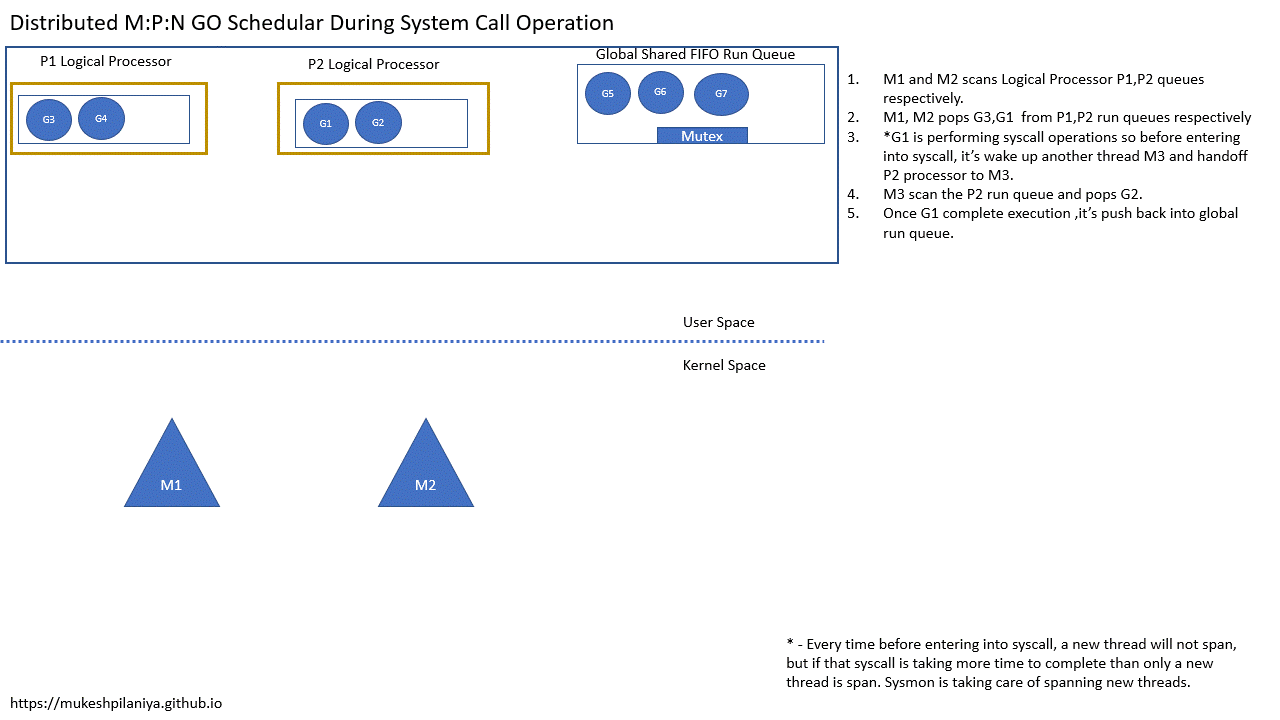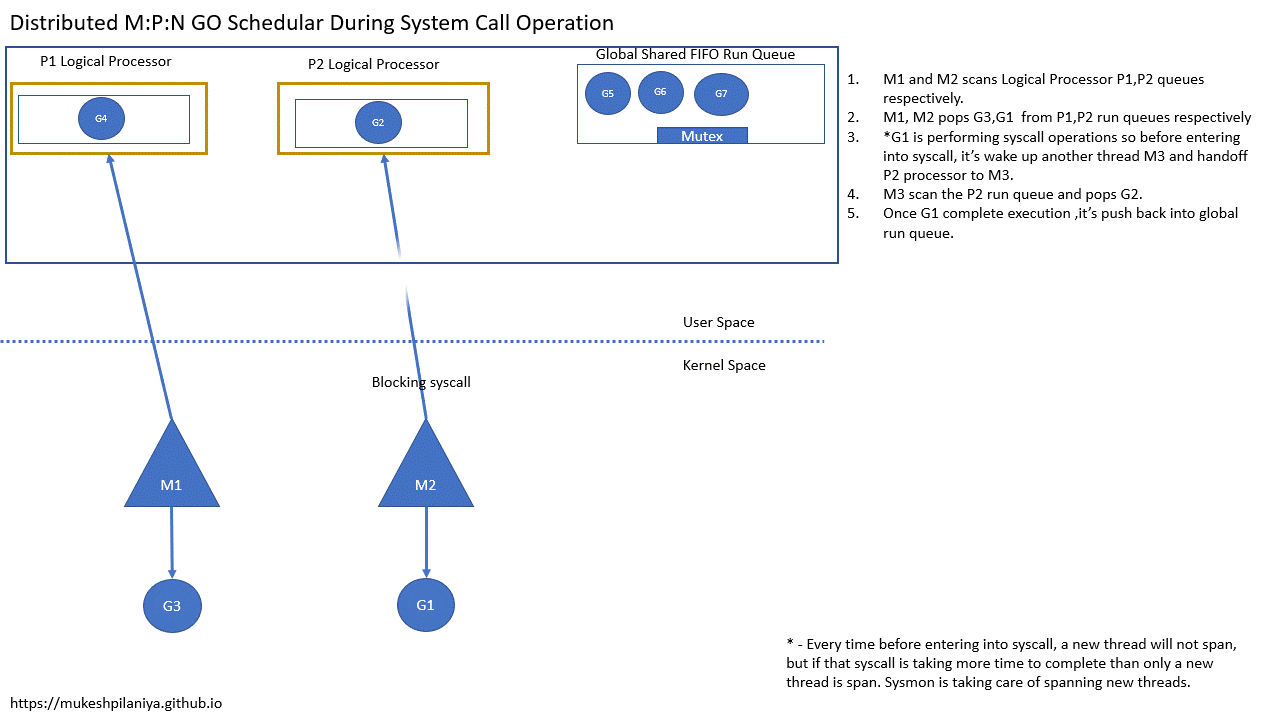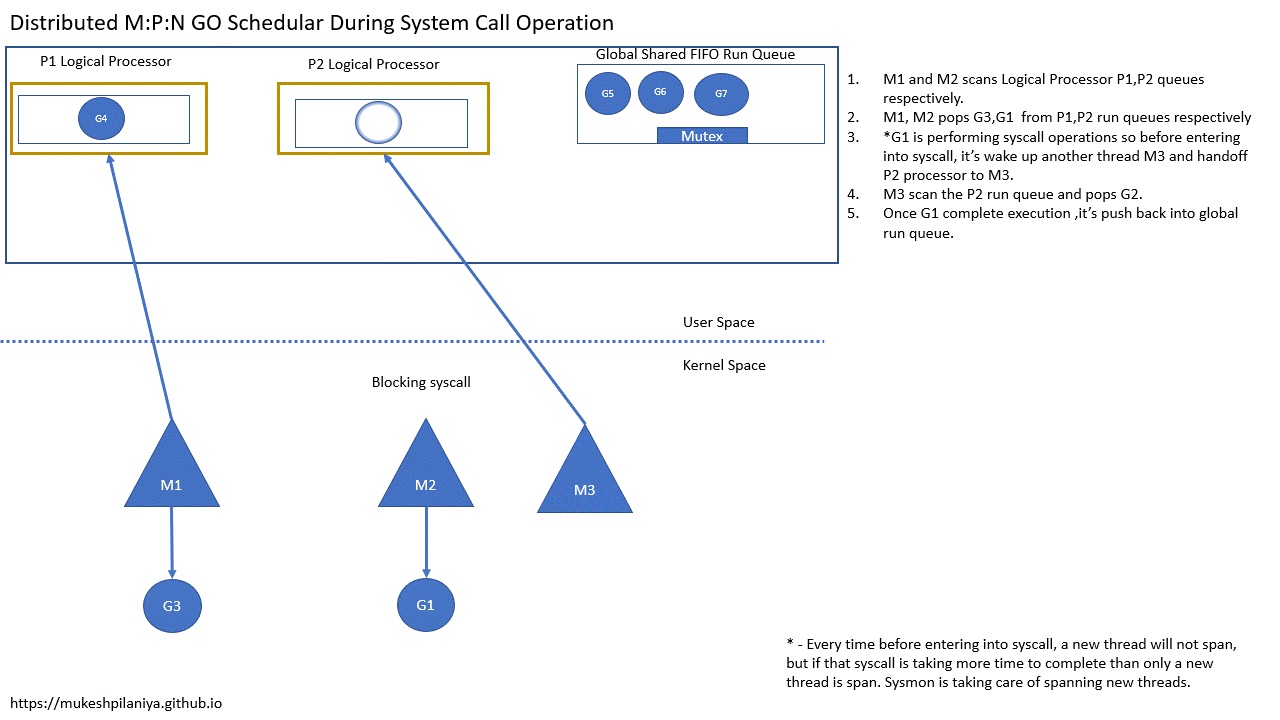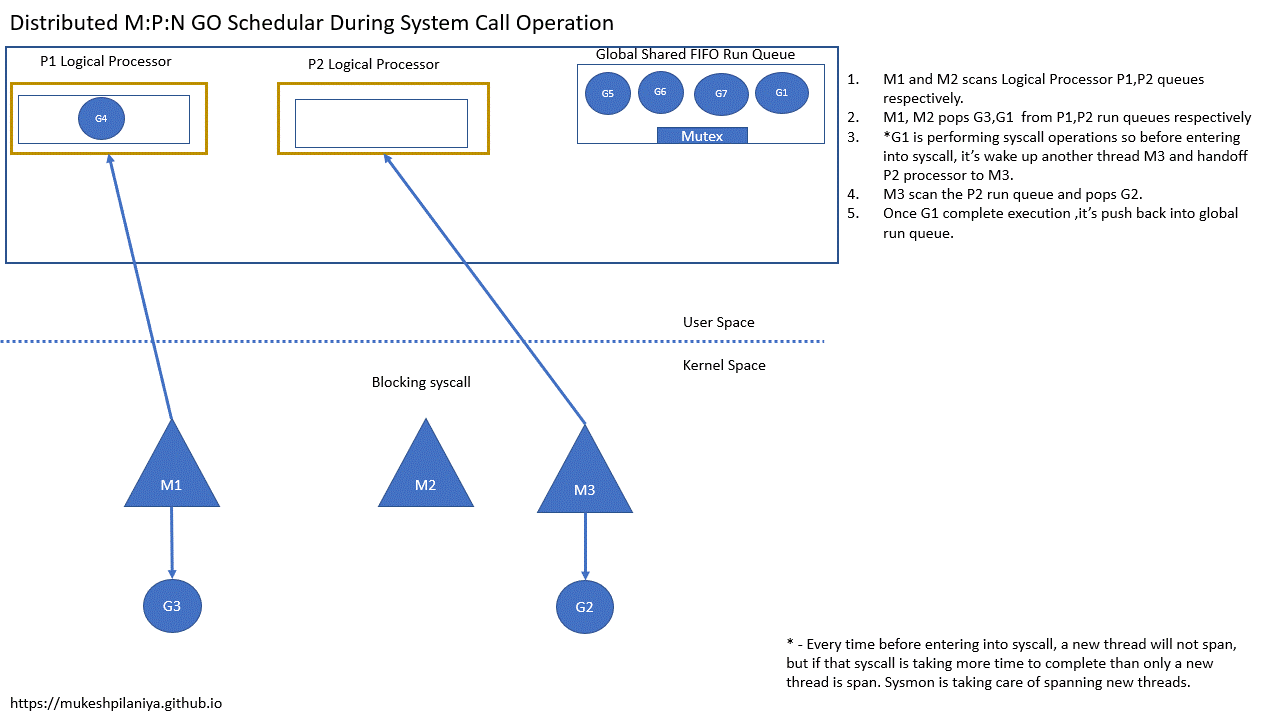
- M1,M2各自扫描P1,P2的队列
- M1,M2从各自的P1,P2中取出G3,G1执行
- G1即将进入系统调用,所以在这之前G1会唤醒另一个线程M3,并将P2切换到M3
- M3扫描P2并取出G2运行
- 一旦G1变为非阻塞,它将被推送到全局队列等待运行
在work-stealing期间,只需要扫描固定数量的队列,因为逻辑处理器的数量是有限的。
如何选择下一个要运行的 goroutine ?
Go 调度器 将按以下顺序检查以选择下一个要执行的 goroutine
本地运行队列
全局运行队列
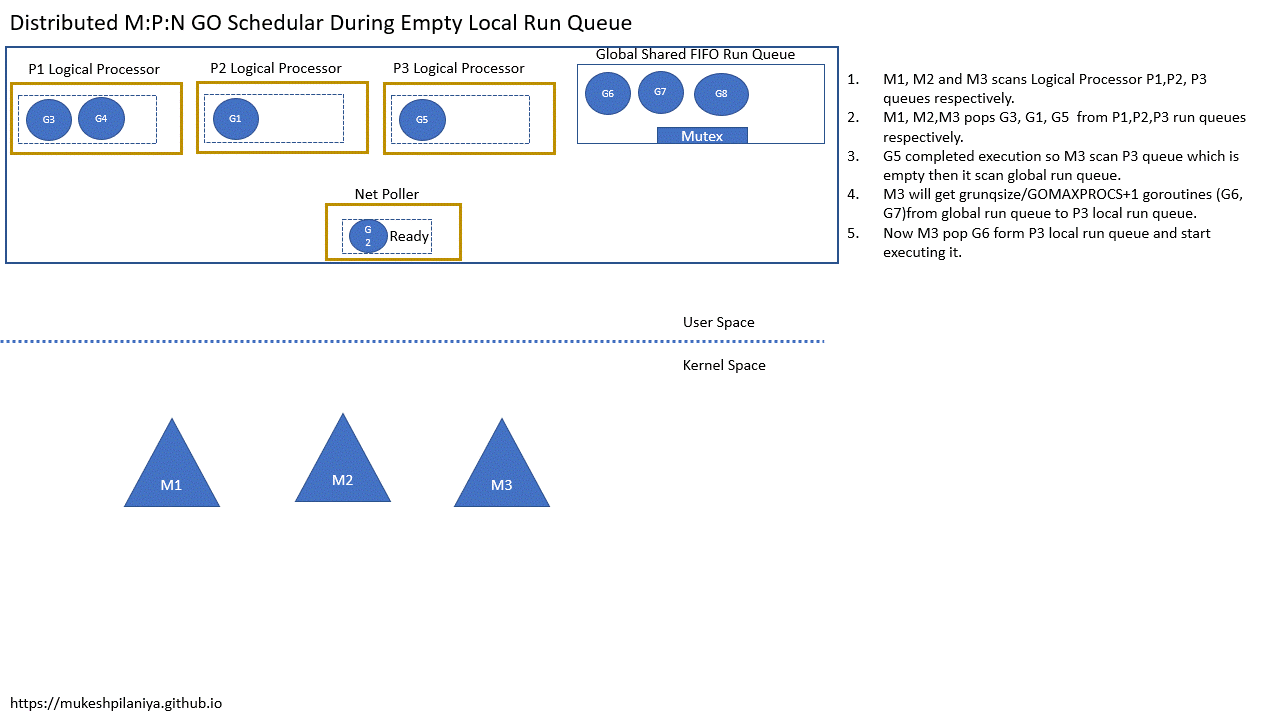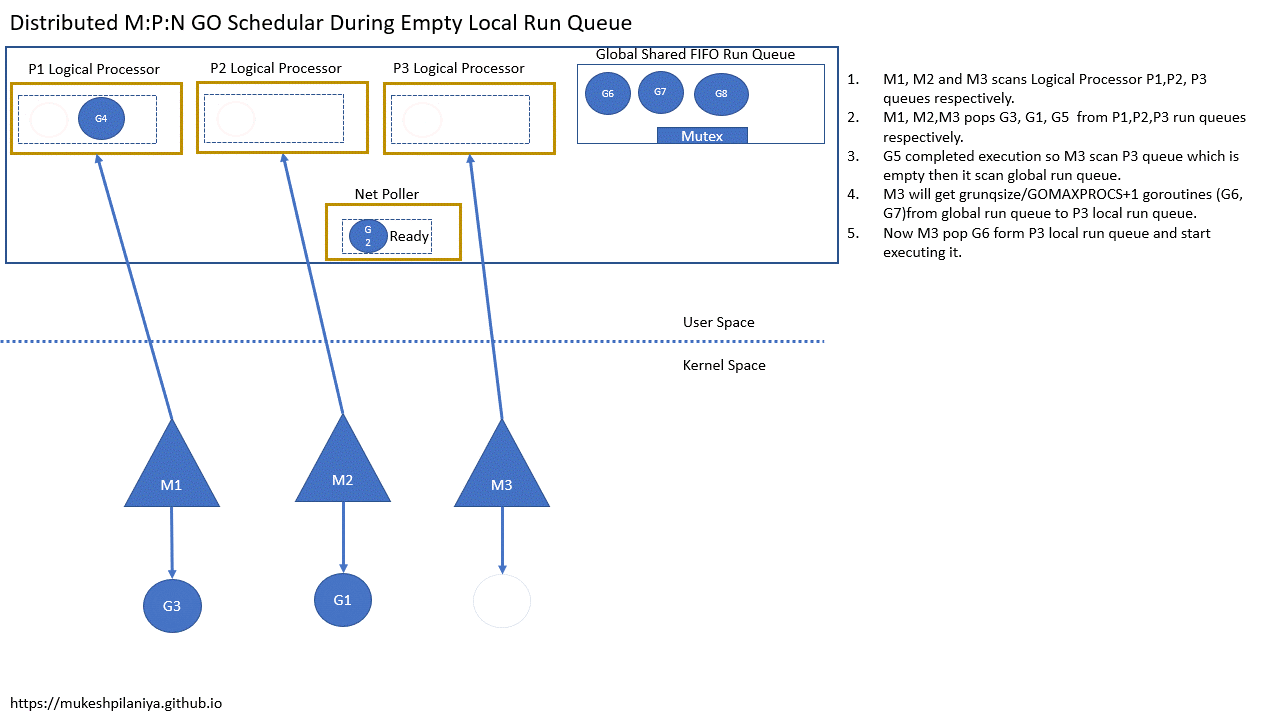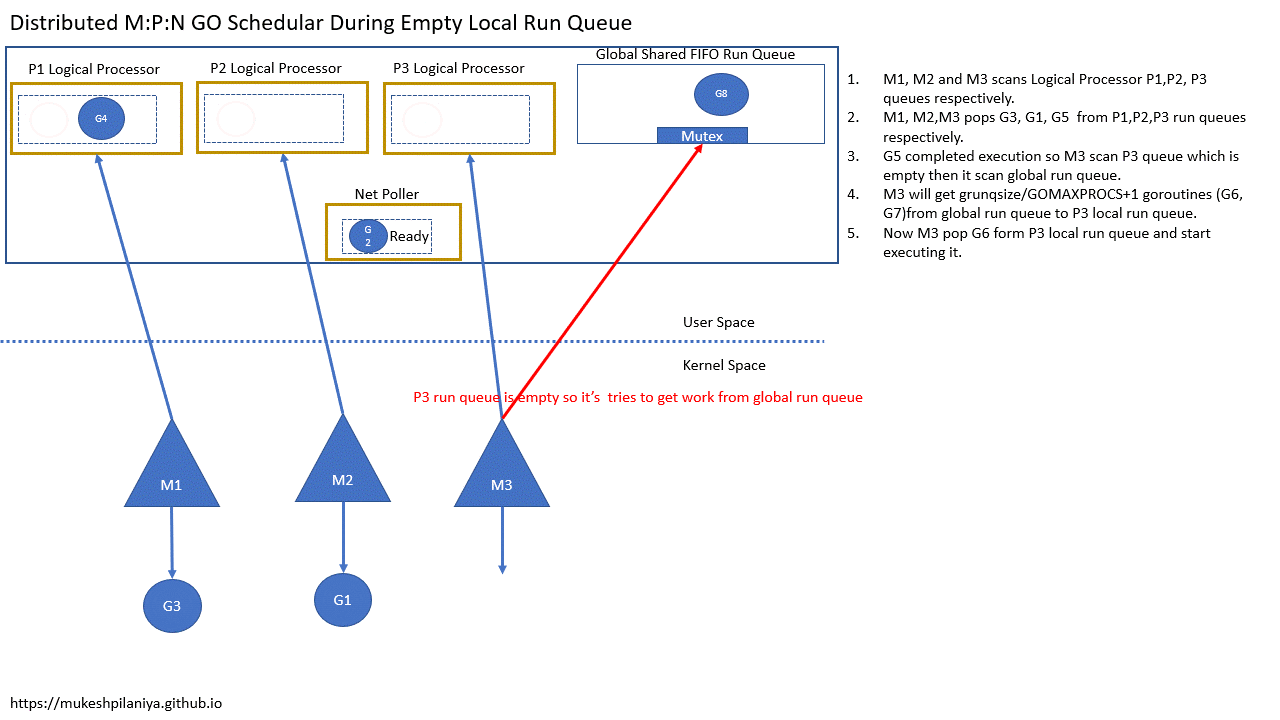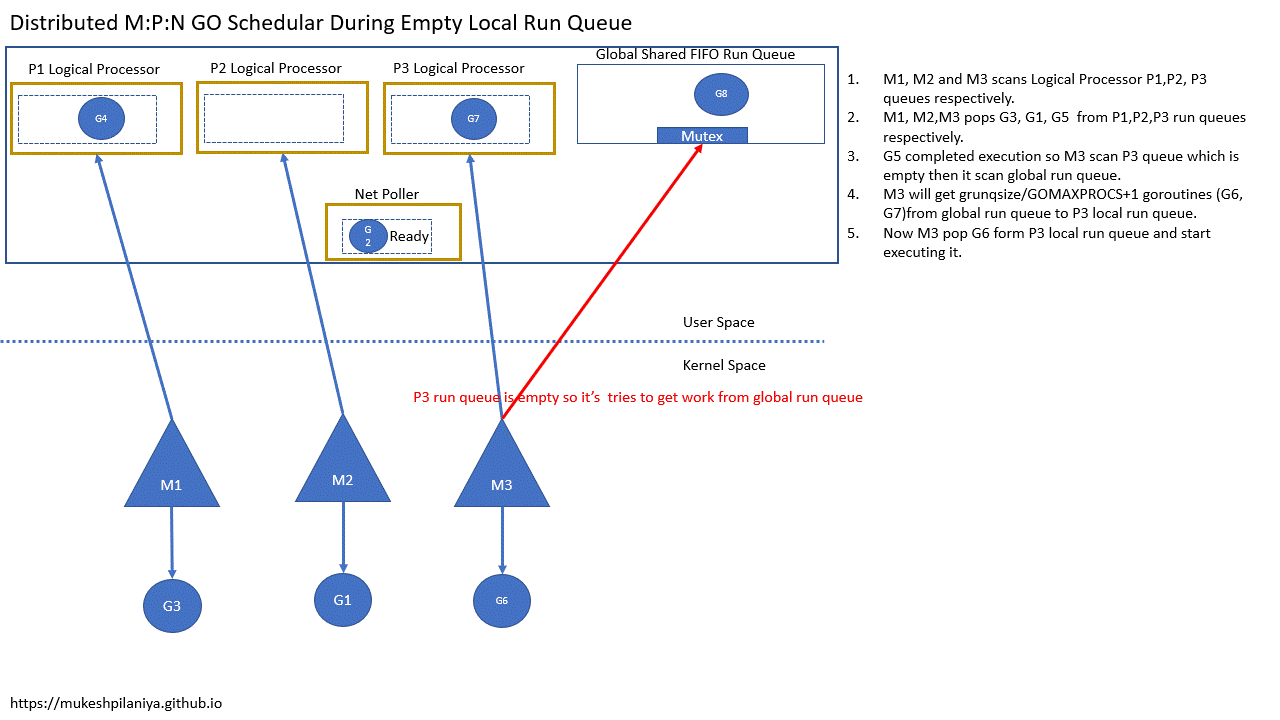
- M1,M2,M3各自扫描本地队列P1,P2,P3
- M1,M2,M3各自从P1,P2,P3取出G3,G1,G5
- G5完成,M3扫描本地队列P3发现空,然后扫描全局队列
- M3将从全局队列获取一定数量的G(G6,G7),保存到本地队列P3
- 现在M3从本地队列P3取出G6执行
Network poller
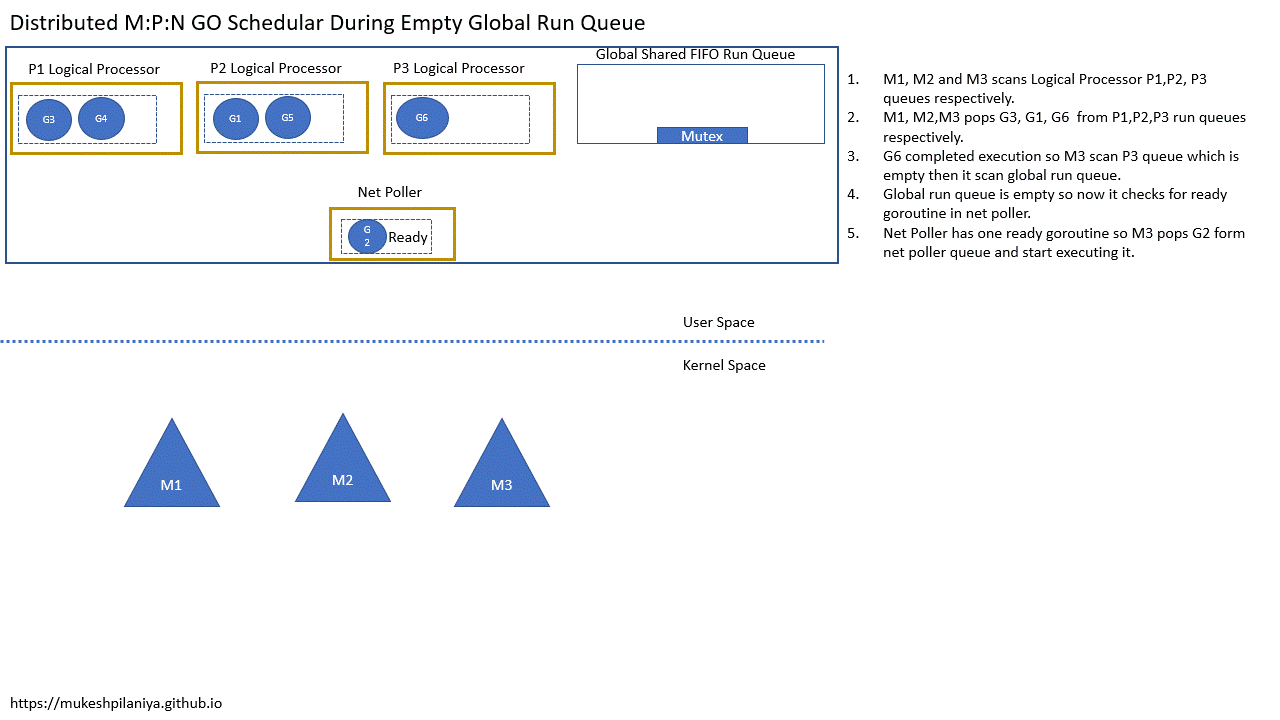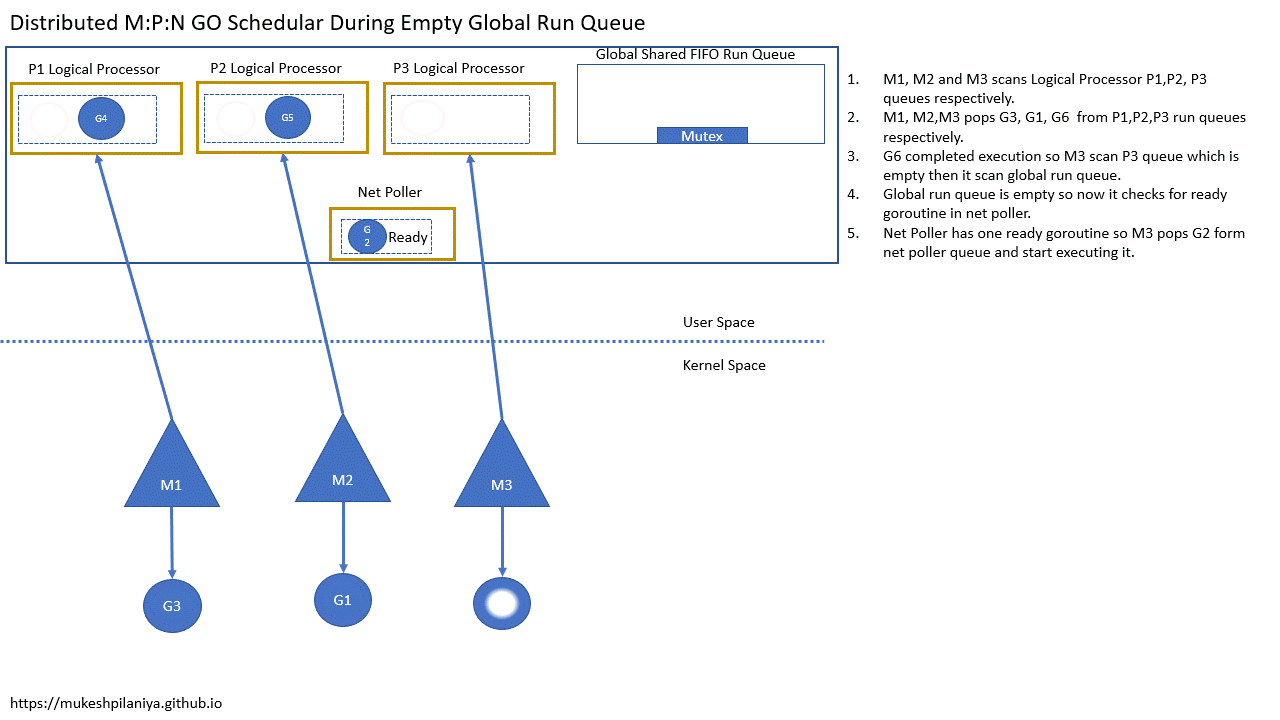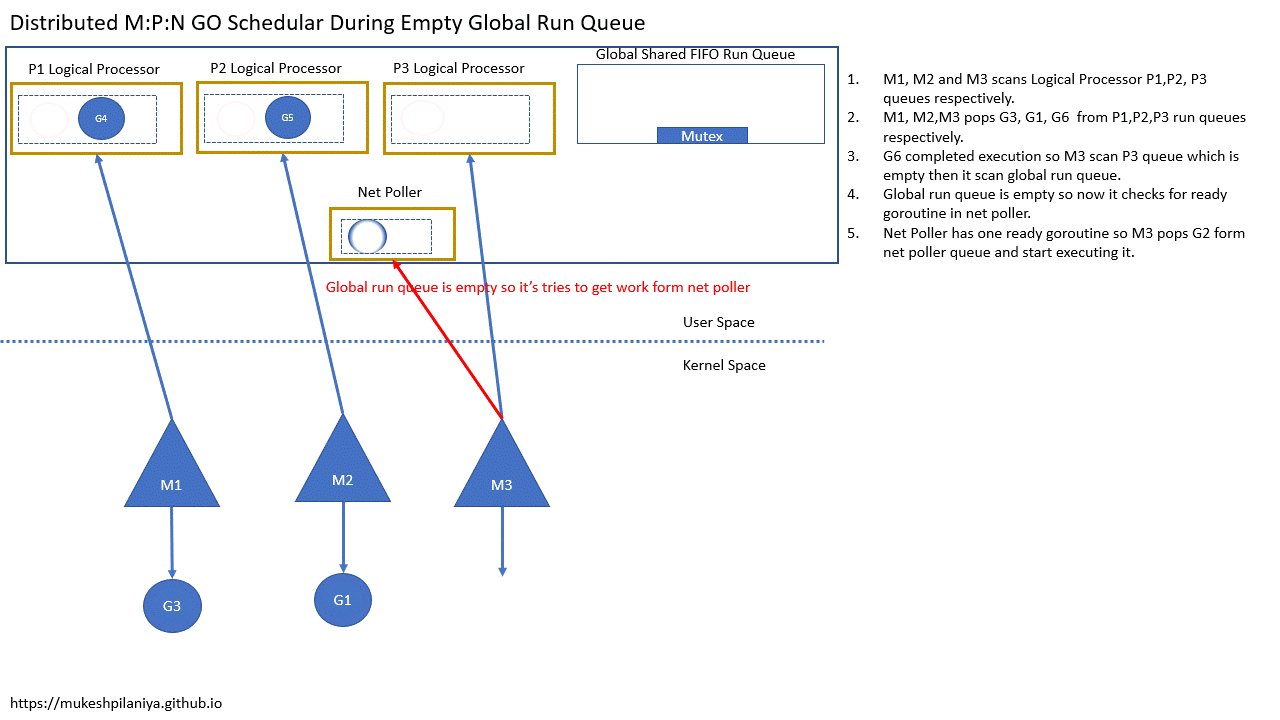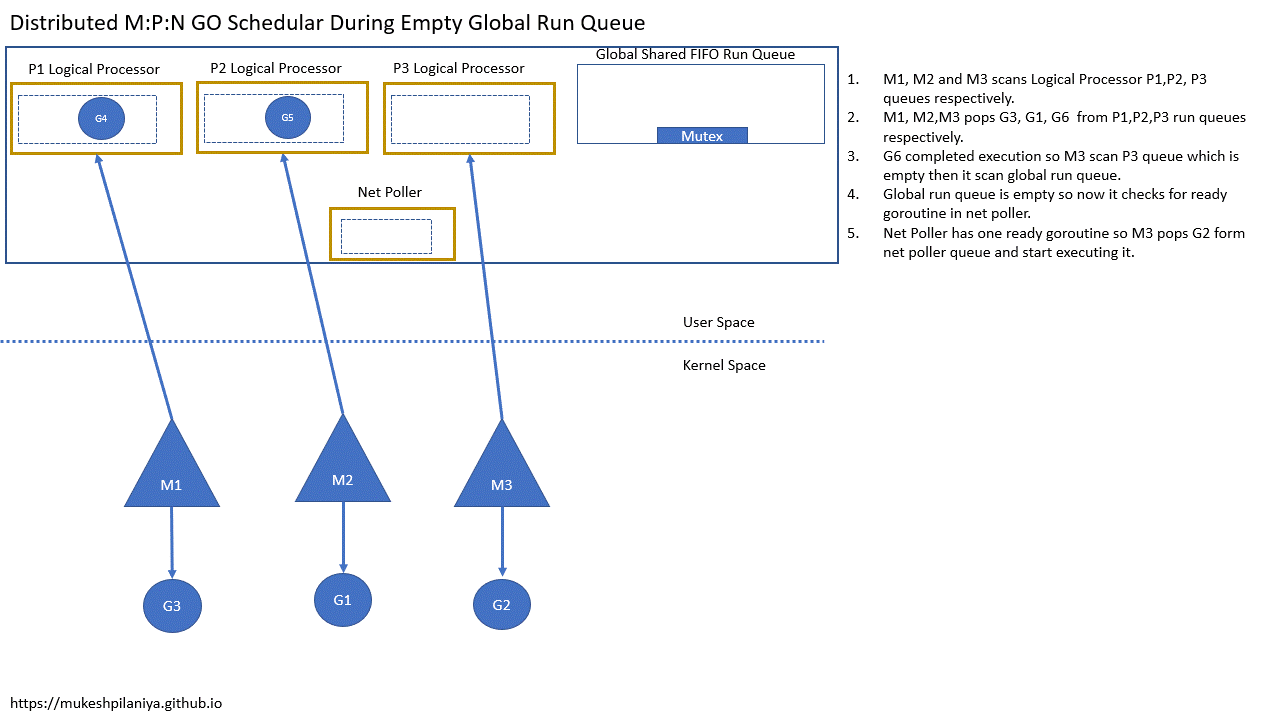
- M1,M2,M3各自扫描本地队列P1,P2,P3
- M1,M2,M3各自从P1,P2,P3取出G3,G1,G6
- G6执行完成,M3扫描P3发现是空的,然后扫描全局队列
- 但是全局队列也是空的,然后就检查网络轮询中已就绪的G
- 网络轮询中有一个已就绪的G2,所以M3取出G2并执行
Work Stealing
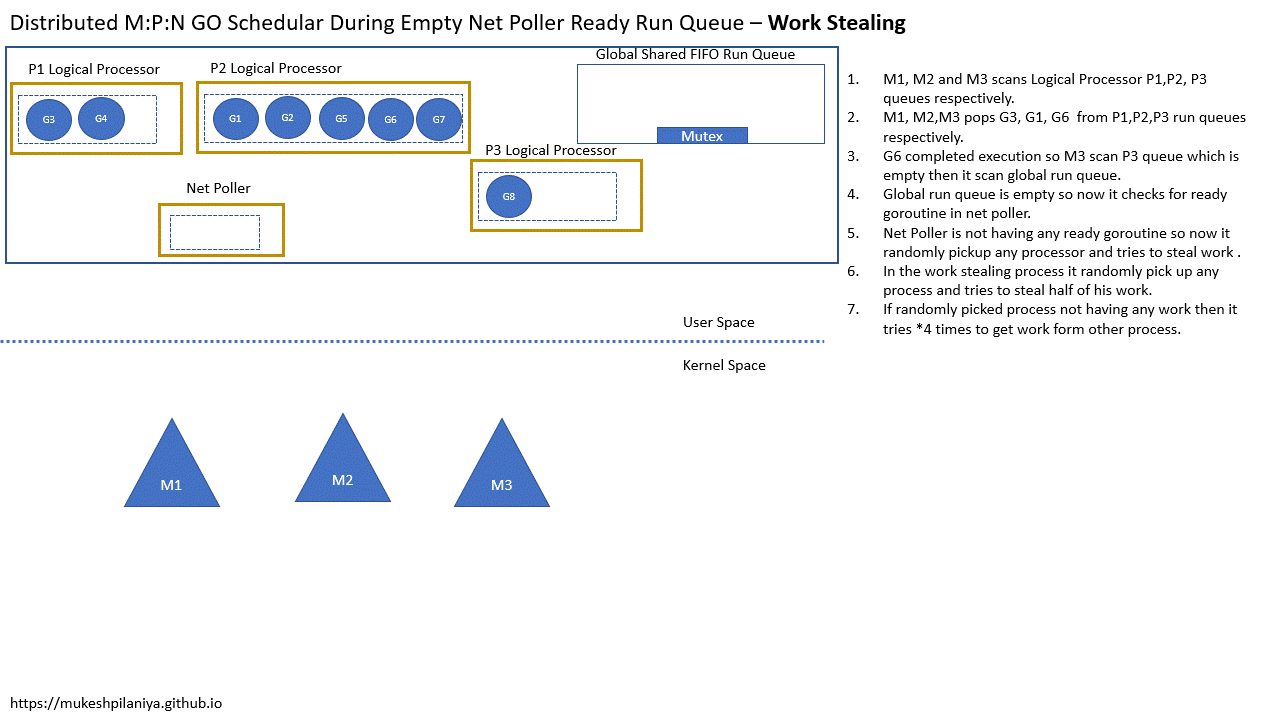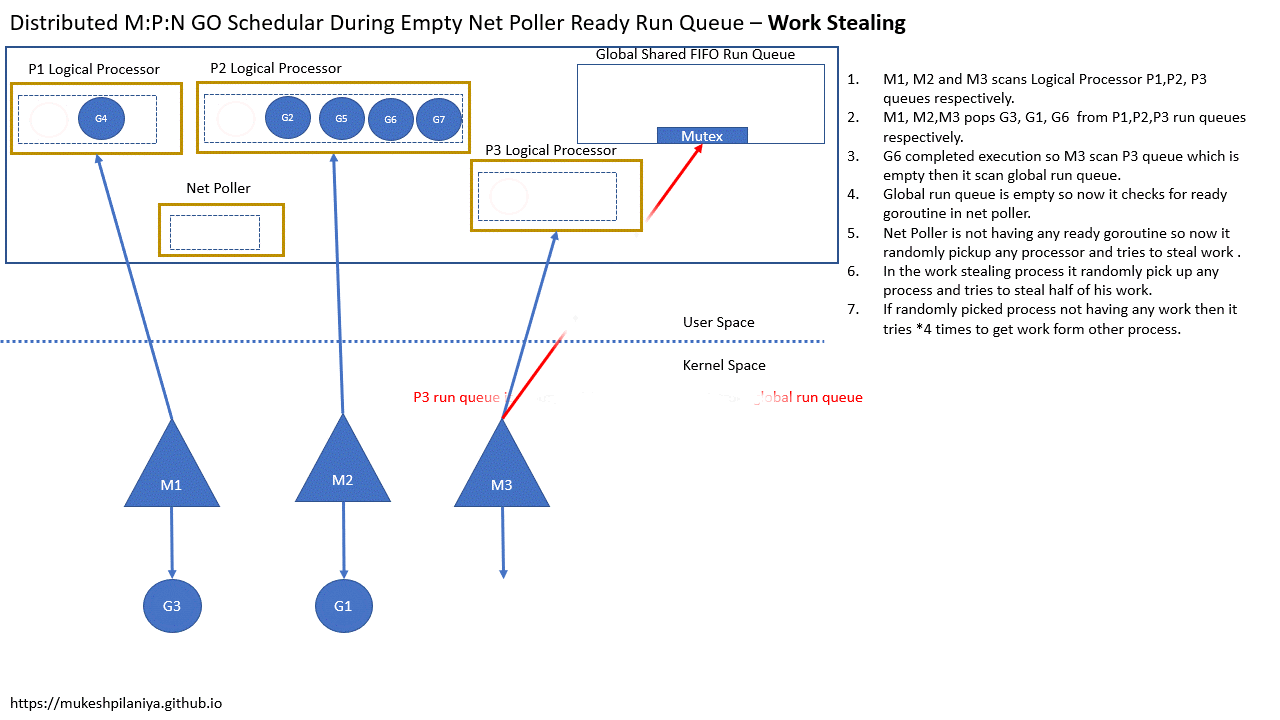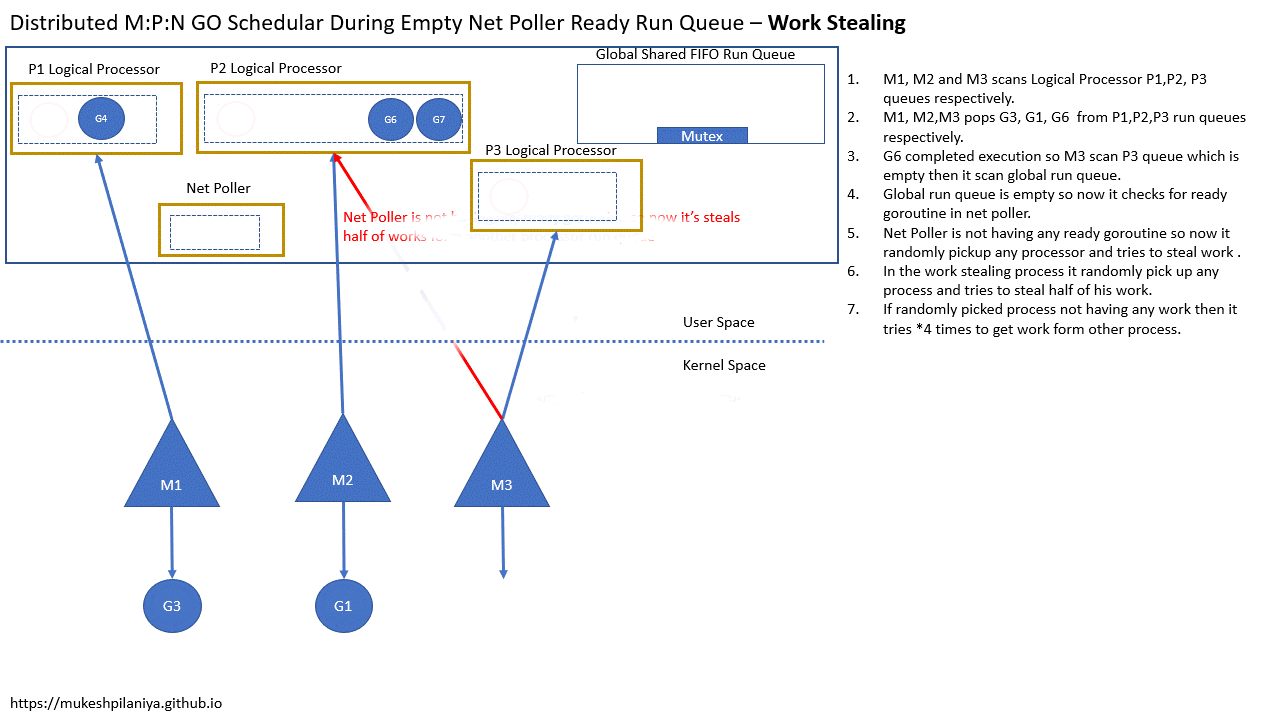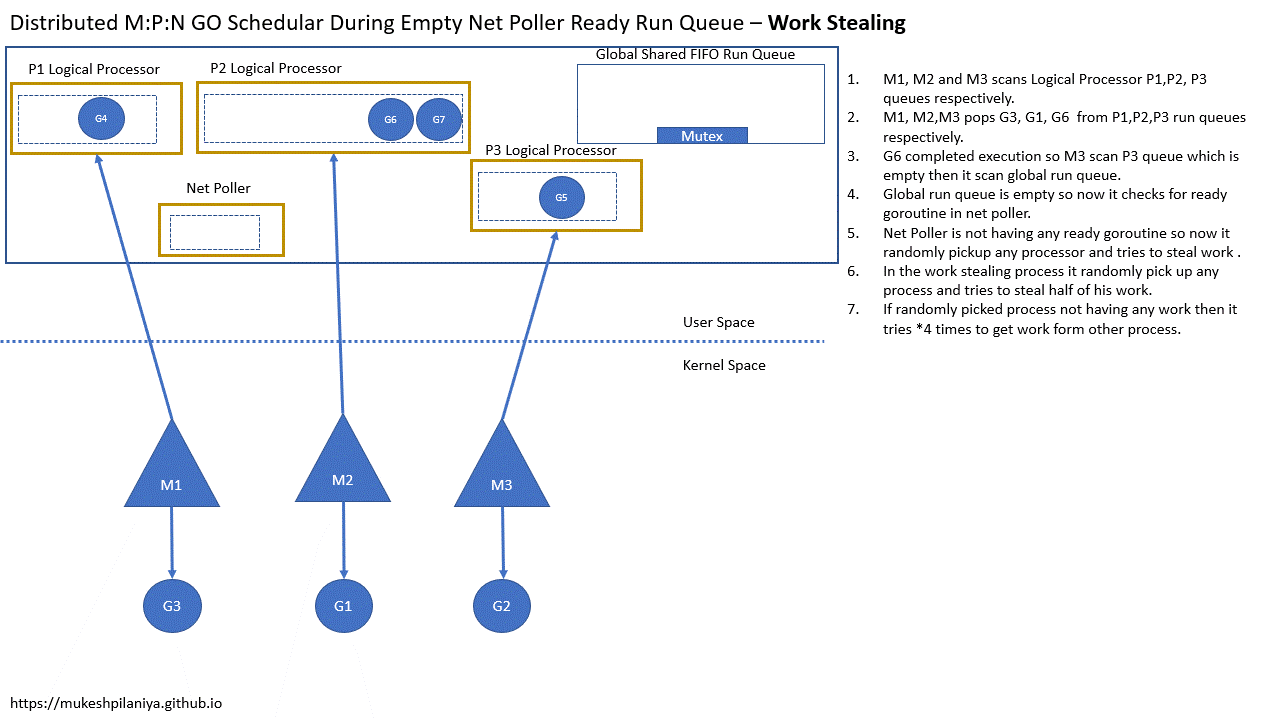
- M1,M2,M3各自扫描本地队列P1,P2,P3
- M1,M2,M3各自从P1,P2,P3取出G3,G1,G6
- G6执行完成,M3扫描P3发现是空的,然后扫描全局队列
- 但是全局队列也是空的,然后就检查网络轮询中已就绪的G
- 但是网络轮询中没有已就绪的G,所以M3随机的从其他P中窃取一半的G到P3
- 如果随机选中的P中没有要执行的G,就会重试4次,从其他P获取
总结:
- 轻量级 goroutine
- 处理 IO 和系统调用
- goroutine 的并行执行
- 可扩展
- 高效/工作窃取
Go 调度的局限性
- FIFO 对局部性原则不利
- 没有 goroutine 优先级的概念(不像 Linux 内核)
- 没有强抢占 -> 没有强公平或延迟保证
- 它没有意识到系统拓扑 -> 没有真实的位置。有一个旧的 NUMA 感知调度程序提案。此外,建议使用 LIFO 队列,这样 CPU 内核缓存中更有可能有数据。
翻译自:
https://mukeshpilaniya.github.io/posts/Go-Schedular/
goroutine调度的更多相关文章
- [转]golang的goroutine调度机制
golang的goroutine调度机制 版权声明:本文为博主原创文章,未经博主允许不得转载. 目录(?)[-] 一直对goroutine的调度机制很好奇最近在看雨痕的golang源码分析基于go ...
- 弄懂goroutine调度原理
goroutine简介 golang语言作者Rob Pike说,"Goroutine是一个与其他goroutines 并发运行在同一地址空间的Go函数或方法.一个运行的程序由一个或更多个go ...
- Go语言goroutine调度器概述(11)
本文是<go调度器源代码情景分析>系列的第11篇,也是第二章的第1小节. goroutine简介 goroutine是Go语言实现的用户态线程,主要用来解决操作系统线程太“重”的问题,所谓 ...
- Golang/Go goroutine调度器原理/实现【原】
Go语言在2016年再次拿下TIBOE年度编程语言称号,这充分证明了Go语言这几年在全世界范围内的受欢迎程度.如果要对世界范围内的gopher发起一次“你究竟喜欢Go的哪一点”的调查,我相信很多Gop ...
- Goroutine调度器
前言 并发(并行)一致都是编程语言的核心主题,不同于其他语言,例如C/C++语言用户序自行借助pthread创建线程,Golang天然就给出了并发解决方案:goroutine. Goroutine 写 ...
- goroutine调度源码阅读笔记
以下为本人阅读goroutine调度源码随手记的笔记,现在还是一个个知识点的形式,暂时还没整理,先发到这里,一点点更新: 1). runq [256]guintptr P 的runable队列最大 ...
- [golang学习] goroutine调度
这两天有些闲功夫, 学习下golang, 确实非常简洁. 不过有些缺憾. 在我的测试中. golang的调度(goroutine)似乎不是非常好. func say(k int) { fmt.Prin ...
- go语言之行--golang核武器goroutine调度原理、channel详解
一.goroutine简介 goroutine是go语言中最为NB的设计,也是其魅力所在,goroutine的本质是协程,是实现并行计算的核心.goroutine使用方式非常的简单,只需使用go关键字 ...
- [GO语言的并发之道] Goroutine调度原理&Channel详解
并发(并行),一直以来都是一个编程语言里的核心主题之一,也是被开发者关注最多的话题:Go语言作为一个出道以来就自带 『高并发』光环的富二代编程语言,它的并发(并行)编程肯定是值得开发者去探究的,而Go ...
- Go语言goroutine调度器初始化(12)
本文是<Go语言调度器源代码情景分析>系列的第12篇,也是第二章的第2小节. 本章将以下面这个简单的Hello World程序为例,通过跟踪其从启动到退出这一完整的运行流程来分析Go语言调 ...
随机推荐
- C#《原CSharp》第四回 人常见岁月更替 却难知人文相继
纪芾显然此时并不是很能理解纪老爷子口中是也不是这句话的意思,不过他依然将这个要点记在了心里,方便以后悟出其最终门道的时候进行比对. "今天,我在璃月港北边的一户人家,遇到了一个挺有意思的后生 ...
- DolphinScheduler JSON拆解详解
本次活动邀请DolphinScheduler社区活跃贡献者,开源积极分子,现就职于政采云大数据部门,从事大数据平台架构工作的李进勇同学给大家分享相关内容. 同时也特别感谢示说网对本次直播活动的大力支持 ...
- P2501 [HAOI2006]数字序列 (LIS,DP)(未完成)
第二问好迷... #include "Head.cpp" #include <vector> const int N = 35007; vector<int> ...
- Luogu2783 有机化学之神偶尔会做作弊 (树链剖分,缩点)
当联通块size<=2时不管 #include <iostream> #include <cstdio> #include <cstring> #includ ...
- Docker 11 自定义镜像
参考源 https://www.bilibili.com/video/BV1og4y1q7M4?spm_id_from=333.999.0.0 https://www.bilibili.com/vid ...
- docker compose搭建redis7.0.4高可用一主二从三哨兵集群并整合SpringBoot【图文完整版】
一.前言 redis在我们企业级开发中是很常见的,但是单个redis不能保证我们的稳定使用,所以我们要建立一个集群. redis有两种高可用的方案: High availability with Re ...
- JedisConnectionException: java.net.SocketException: Broken pipe (Write failed) 问题排查
问题描述 笔者有2个应用会不定时请求redis,其中一个应用大约每分钟请求一次,可以正常请求,但是另一个大约每小时请求一次的应用,经常出现Broken pipe (Write failed)报错,具体 ...
- jbd2的死锁分析
已经运行多年的jbd2,它还是死锁了 背景:这个是在centos7的环境上复现的,内核版本为3.10.0-957.27.2.el7 下面列一下我们是怎么排查并解这个问题的. 一.故障现象 oppo云内 ...
- 【java】学习路径32-绝对路径与相对路径
获取文件路径的时候,我们发现有两个方法,getAbsolutePath和getPath两个方法. 前者是获取绝对路径,后者是相对路径. 绝对路径指的是完整路径,从盘符开始. 相对路径指的是从java当 ...
- AtCoder Beginner Contest 260 (D-E)
AtCoder Beginner Contest 260 - AtCoder D - Draw Your Cards 题意:N张卡牌数字 1-n,以某种顺序排放,每次拿一张,如果这一张比前面某一张小( ...