ElasticSearch7.3学习(二十四)----相关度评分机制详解
1、算法介绍
relevance score(相关性分数) 算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度。Elasticsearch使用的是 term frequency/inverse document frequency算法,简称为TF/IDF算法。TF词频(Term Frequency),IDF逆向文件频率(Inverse Document Frequency)
1.1 Term frequency
搜索文本中的各个词条在field文本中出现了多少次,出现次数越多,就越相关。

数学公司并不重要,看下面例子就清楚了
搜索请求:阿莫西林
doc1:阿莫西林胶囊是什么。。。阿莫西林胶囊能做什么。。。。阿莫西林胶囊结构
doc2:本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。很容易发现对于阿莫西林关键词来说在doc1中出现的次数大于doc2的,所以doc1的优先级高于doc2
1.2 Inverse document frequency
搜索文本中的各个词条在整个索引的所有文档中出现了多少次,出现的次数越多,就越不相关.
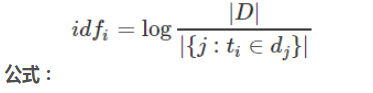

首先看下面内容
搜索请求:阿莫西林胶囊
doc1:A市健康大药房简介。本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。
doc2:B市民生大药房简介。本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。
doc3:C市未来大药房简介。本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。可以看到,对于关键词阿莫西林来说,所有的doc里面都包含这个关键词,那说明这个关键词不是那么重要,说明这个关键词所占的权重很低。再看下面内容
搜索请求:A市 阿莫西林胶囊
doc1:A市健康大药房简介。本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。
doc2:B市民生大药房简介。本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。
doc3:C市未来大药房简介。本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。再加上A市这个关键词,这样的话只有doc1里面才存在,这样的话权重才高,所以可以得出结论:整个索引库中出现的词的频率越小,那么相关度权重越高。
1.3 Field-length norm
除了上面两个因素影响相关度评分的计算之外,还有一个就是字段长度也会影响评分的计算。具体来说就是,field的长度越长,相关度越弱
搜索请求:A市 阿莫西林胶囊
doc1:{"title":"A市健康大药房简介。","content":"本药店有、红霉素胶囊、青霉素胶囊。。。(一万字)"}
doc2:{"title":"B市民生大药房简介。","content":"本药店有阿莫西林胶囊、红霉素胶囊、青霉素胶囊。。。(一万字)"}两个文档均只有一个字段被命中。为啥doc1>doc2,因为title字段的长度小于content的字段,几个字就命中相比于一万字才命中,当然几个字就命中的排在前面
2、 _score是如何被计算出来的
步骤如下:
- 对用户输入的关键词分词
- 每个分词分别计算对每个匹配文档的TF和IDF值
- 综合每个分词的TF/IDF值,利用公式计算每个文档总分
- 最后按照score降序返回
可以举个例子来看一下。这里使用explain关键字来解释排序的过程。
首先创建索引
PUT /book/
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"description": {
"type": "text",
"analyzer": "ik_max_word",
"search_analyzer": "ik_smart"
},
"studymodel": {
"type": "keyword"
},
"price": {
"type": "double"
},
"timestamp": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
},
"pic": {
"type": "text",
"index": false
}
}
}
}接着添加测试数据
PUT /book/_doc/1
{
"name": "Bootstrap开发",
"description": "Bootstrap是一个非常流行的开发框架。此开发框架可以帮助不擅长css页面开发的程序人员轻松的实现一个css,不受浏览器限制的精美界面css效果。",
"studymodel": "201002",
"price": 38.6,
"timestamp": "2019-08-25 19:11:35",
"pic": "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [
"bootstrap",
"dev"
]
}
PUT /book/_doc/2
{
"name": "java编程思想",
"description": "java语言是世界第一编程语言,在软件开发领域使用人数最多。",
"studymodel": "201001",
"price": 68.6,
"timestamp": "2019-08-25 19:11:35",
"pic": "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [
"java",
"dev"
]
}
PUT /book/_doc/3
{
"name": "spring开发基础",
"description": "spring 在java领域非常流行,java程序员都在用。",
"studymodel": "201001",
"price": 88.6,
"timestamp": "2019-08-24 19:11:35",
"pic": "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags": [
"spring",
"java"
]
}然后在使用如下命令查看_score的计算
GET /book/_search?explain=true
{
"query": {
"match": {
"description": "java程序员"
}
}
}返回的内容太多,这里只展示第一条的数据的内容
查看代码
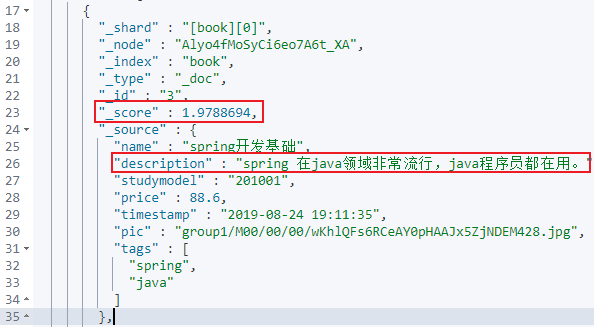
{
"_shard" : "[book][0]",
"_node" : "Alyo4fMoSyCi6eo7A6t_XA",
"_index" : "book",
"_type" : "_doc",
"_id" : "3",
"_score" : 1.9788694,
"_source" : {
"name" : "spring开发基础",
"description" : "spring 在java领域非常流行,java程序员都在用。",
"studymodel" : "201001",
"price" : 88.6,
"timestamp" : "2019-08-24 19:11:35",
"pic" : "group1/M00/00/00/wKhlQFs6RCeAY0pHAAJx5ZjNDEM428.jpg",
"tags" : [
"spring",
"java"
]
},
"_explanation" : {
"value" : 1.9788694,
"description" : "sum of:",
"details" : [
{
"value" : 0.7502767,
"description" : "weight(description:java in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.7502767,
"description" : "score(freq=2.0), product of:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.47000363,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 2,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 3,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.7256004,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 2.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 12.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 23.666666,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 1.2285928,
"description" : "weight(description:程序员 in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 1.2285928,
"description" : "score(freq=1.0), product of:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.98082924,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 1,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 3,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.56936646,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 12.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 23.666666,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
}
]
}
},对于上面的返回结果,我们先看第一部分,首先就是返回的数据
接着就是对评分计算的解释,按照上面给出的4个步骤分析,首先对关键词分词,这里分为了java 程序员两个关键词,先来看看java关键词的解释
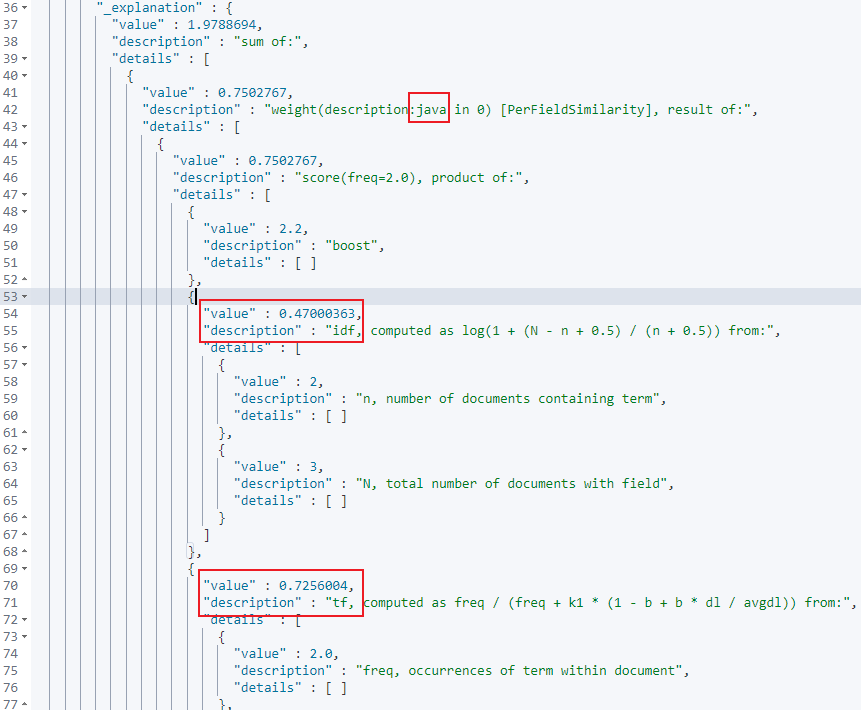
可以看到计算java关键词的tf,idf的值,同理在下方也能看到计算程序员关键词的tf,idf的值。
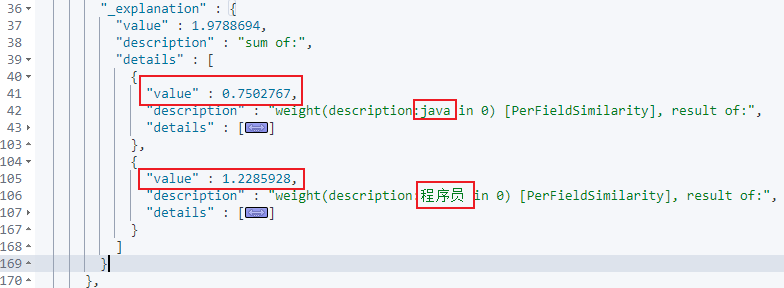
最后将两个关键词合并起来在计算整个doc的总分,即得到最终的_score值,如下所示。
3、document判断是否被匹配
测试判断一个文档能不能被搜索到,适用于生产环境
例如
GET /book/_explain/1
{
"query": {
"match": {
"description": "java程序员"
}
}
}返回
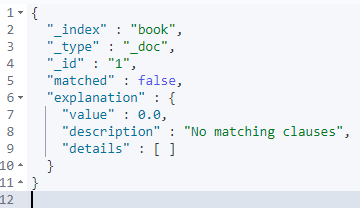
可以看到对于id为1的doc,并不能匹配到该文档,再来试一下id为3的数据
GET /book/_explain/3
{
"query": {
"match": {
"description": "java程序员"
}
}
}返回
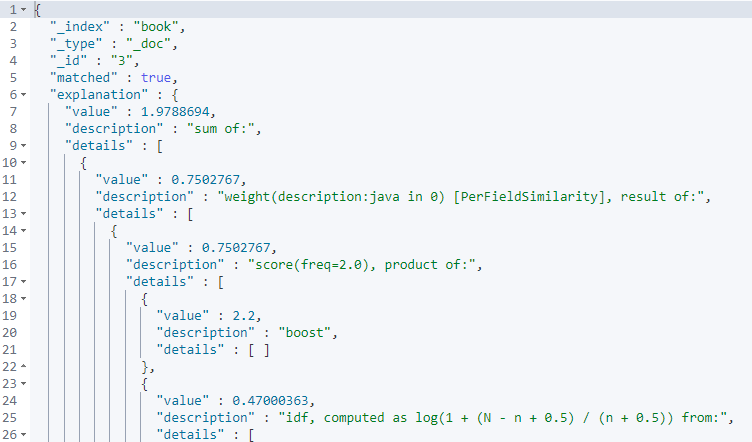
可以看到能够被匹配到,并且能够根据内容来分析为什么该文档能够被匹配到。
ElasticSearch7.3学习(二十四)----相关度评分机制详解的更多相关文章
- ElasticSearch7.3学习(二十)----采用restful风格查询详解
1.Query DSL入门 1.1 DSL DSL:Domain Specified Language,特定领域的语言.es特有的搜索语言,可在请求体中携带搜索条件,功能强大. 查询全部 GET /b ...
- 渗透测试学习 二十八、WAF绕过详解
大纲: WAF防护原理讲解 目录扫描绕过WAF 手工注入绕过WAF sqlmap绕过WAF 编写salmap绕过WAF 过WAF一句话编写讲解 菜刀连接绕过WAF webshell上传绕过WAF 提权 ...
- “全栈2019”Java第五十四章:多态详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- ElasticSearch7.3学习(二十六)----搜索(Search)参数总结、结果跳跃(bouncing results)问题解析
1.preference 首先引入一个bouncing results问题,两个document排序,field值相同:不同的shard上,可能排序不同:每次请求轮询打到不同的replica shar ...
- ElasticSearch7.3学习(二十五)----Doc value、query phase、fetch phase解析
1.Doc value 搜索的时候,要依靠倒排索引: 排序的时候,需要依靠正排索引,看到每个document的每个field,然后进行排序. 所谓的正排索引,其实就是doc values. 在建立索引 ...
- Java开发学习(二十四)----SpringMVC设置请求映射路径
一.环境准备 创建一个Web的Maven项目 参考Java开发学习(二十三)----SpringMVC入门案例.工作流程解析及设置bean加载控制中环境准备 pom.xml添加Spring依赖 < ...
- Redis进阶实践之二十 Redis的配置文件使用详解
一.引言 写完上一篇有关redis使用lua脚本的文章,就有意结束Redis这个系列的文章了,当然了,这里的结束只是我这个系列的结束,但是要学的东西还有很多.但是,好多天过去了,总是感觉好像还缺点什么 ...
- Python3.5 学习二十四
本节课程大纲: -------------------------------------------------------------------------------------------- ...
- JavaWeb学习 (二十四)————Filter(过滤器)常见应用
一.统一全站字符编码 通过配置参数charset指明使用何种字符编码,以处理Html Form请求参数的中文问题 1 package me.gacl.web.filter; 2 3 import ja ...
随机推荐
- 简述 Memcached 内存管理机制原理?
早期的 Memcached 内存管理方式是通过 malloc 的分配的内存,使用完后通过 free 来回收内存,这种方式容易产生内存碎片,并降低操作系统对内存的管理效 率.加重操作系统内存管理器的负担 ...
- 是否可以继承 String 类?
String 类是 final 类,不可以被继承. 补充:继承 String 本身就是一个错误的行为,对 String 类型最好的重用方式是关 联关系(Has-A)和依赖关系(Use-A)而不是继承关 ...
- 什么是通知Advice?
特定 JoinPoint 处的 Aspect 所采取的动作称为 Advice.Spring AOP 使用一个 Advice 作为拦截器,在 JoinPoint "周围"维护一系列的 ...
- Python - 文档格式转换(CSV与JSON)
- MTK平台电路设计01
一.资料 获取途径MTK官网.一牛网 二.
- [C/C++基础知识] main函数的参数argc和argv
该篇文章主要是关于C++\C语言最基础的main函数的参数知识,是学习C++或C语言都必备的知识点.不知道你是否知道该知识?希望对大家有所帮助.一.main()函数参数通常我们在写主函数时都是void ...
- 4_ 比例控制器_燃烧卡路里(2)_Matlab/Simulink_Proportional Control
- Exchange批量删除邮件
在实际工作中经常遇到以下问题:邮件发送给错误的收件人,简而言之就是邮件发错了,如果遇到群发更麻烦.Exchange中提供了批量删除邮件功能,当用户发现发送错误后,管理员可以检索并删除指定的邮件. 案例 ...
- FreeSql的各种工程demo上新啦
FreeSql的各种工程demo GitHub | Gitee console,winforms nf461,vb,wpf,webapi,workerSevice,signalIR xamarinFo ...
- Java 实例 - 读取文件内容
原文作者:菜鸟教程 原文链接:Java 实例 - 读取文件内容(建议前往原文以获得最佳体验) 按行读取文本文件 import java.io.*; public class Main { public ...