【Redis】ziplist压缩列表
压缩列表
压缩列表是列表和哈希表的底层实现之一:
如果一个列表只有少量数据,并且数据类型是整数或者比较短的字符串,redis底层就会使用压缩列表实现。
如果一个哈希表只有少量键值对,并且每个键值对的键和值数据类型是整数或者比较短的字符串,redis底层就会使用压缩列表实现。
Redis压缩列表是由连续的内存块组成的列表,主要包含以下内容:
zlbytes:记录压缩列表占用的总的字节数,占用4个字节(32bits)
zltail:记录压缩列表的起始位置到最后一个节点的字节数,假如知道压缩列表的起始地址,只需要假设zltail记录的偏移量即可定位到压缩列表中最后一个节点的位置,占用4个字节(32bits)
zllen:记录了压缩列表中节点的数量,占用2个字节(16bits)
entry:存储数据的节点,可以有多个
zlend:标记压缩列表的结尾,值为255,占用1个字节(8bits)

压缩列表的创建
列表在初始化的时候会计算需要分配的内存空间大小,然后进行内存分配,之后将内存空间的最后一个字节标记为列表结尾,内存空间的大小计算方式如下:
压缩列表头大小,包括zlbytes、zltail和zllen所占用的大小:32 bits * 2 + 16 bits
压缩列表结尾大小:8bits
// 压缩列表头大小,包括zlbytes、zltail和zllen所占用的大小:32 bits * 2 + 16 bits
#define ZIPLIST_HEADER_SIZE (sizeof(uint32_t)*2+sizeof(uint16_t))
// 压缩列表结尾大小:8bits
#define ZIPLIST_END_SIZE (sizeof(uint8_t))
// 列表结尾标记
#define ZIP_END 255
unsigned char *ziplistNew(void) {
// 计算需要分配的内存大小
unsigned int bytes = ZIPLIST_HEADER_SIZE+ZIPLIST_END_SIZE;
// 分配内存
unsigned char *zl = zmalloc(bytes);
ZIPLIST_BYTES(zl) = intrev32ifbe(bytes);
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(ZIPLIST_HEADER_SIZE);
ZIPLIST_LENGTH(zl) = 0;
// 将内存空间的最后一个字节标记为列表结尾
zl[bytes-1] = ZIP_END;
return zl;
}
所以在创建之后,内存布局如下,此时压缩列表中还没有节点:

之后如果如果需要添加节点,会进行移动,为新节点的插入腾出空间,所以还是占用的连续的空间:
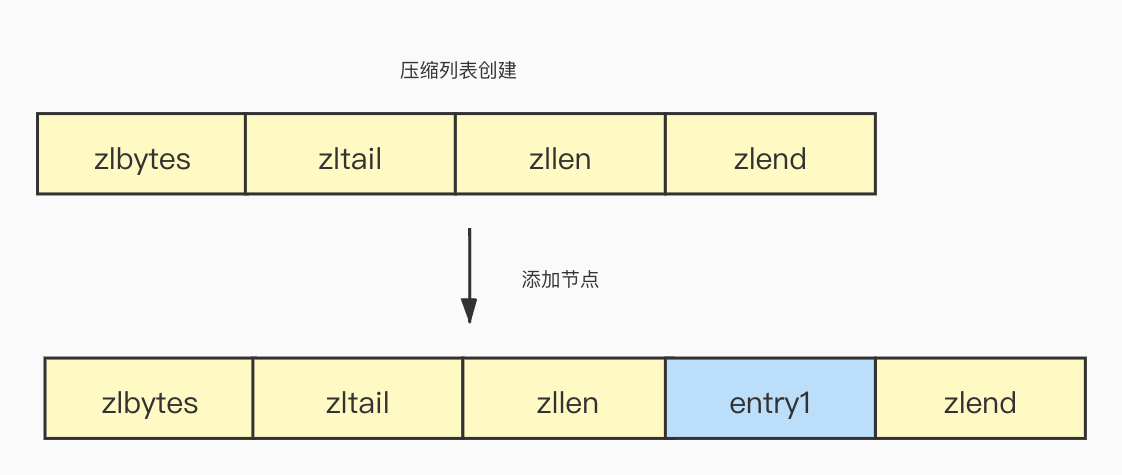
压缩列表节点
压缩列表的节点可以存储字符串或者整数类型的值,为了节省内存,它采用了变长的编码方式,压缩列表的节点的结构定义如下:
typedef struct zlentry {
unsigned int prevrawlensize; /* 前一个节点长度编码所需要的字节数*/
unsigned int prevrawlen; /* 前一个节点的长度(占用的字节数)*/
unsigned int lensize; /* 当前节点长度编码所需要的字节数*/
unsigned int len; /* 当前节点的长度(占用的字节数)*/
unsigned int headersize; /* header的大小,headersize = prevrawlensize + lensize. */
unsigned char encoding; /* 记录了数据的类型和数据长度 */
unsigned char *p; /* 指向数据的指针 */
} zlentry;
prevrawlen:存储前一个节点的长度(占用的字节数),这样如果从后向前遍历,只需要当前节点的起始地址减去长度的偏移量prevrawlen就可以定位到上一个节点的位置,prevrawlen的长度可以是1字节或者5字节:
- 如果前一项节点的长度小于254字节,那么prevrawlen的长度是1字节。
- 如果前一项节点的长度大于254字节,那么prevrawlen的长度是5字节,其中第一个字节会被设置为0xFE(十进制254),之后的四个字节用于保存前一个节点的长度。
为什么没有255字节?
因为255用来标记为压缩列表的结尾。
/* 节点编码所需要的字节数 */
unsigned int zipStorePrevEntryLength(unsigned char *p, unsigned int len) {
if (p == NULL) {
return (len < ZIP_BIG_PREVLEN) ? 1 : sizeof(uint32_t) + 1;
} else {
// 判断长度是否小于254
if (len < ZIP_BIG_PREVLEN) {
p[0] = len;
// 使用1个字节
return 1;
} else {
return zipStorePrevEntryLengthLarge(p,len);
}
}
}
// 节点编码所需要的字节数
int zipStorePrevEntryLengthLarge(unsigned char *p, unsigned int len) {
uint32_t u32;
if (p != NULL) {
// 将prevrawlen的第1个字节设置为254
p[0] = ZIP_BIG_PREVLEN;
u32 = len;
memcpy(p+1,&u32,sizeof(u32));
memrev32ifbe(p+1);
}
// 使用5个字节
return 1 + sizeof(uint32_t);
}
encoding:记录了节点的数据类型和内容的长度,因为压缩列表可以存储字符串或者整型,所以有以下两种情况:
存储内容为字符串
C语言存储字符串底层使用的是字节数组,当内容为字符串时分为三种情况,encoding分别占用1字节、2字节、5字节,encoding占用字节大小的不同,代表存储不同长度的字节数组。
| 编码 | 编码长度 | 数据类型 |
|---|---|---|
| 00xxxxxx | 占用1个字节,也就是8bits | 长度小于等于63(2^6 - 1)字节的字节数组 |
| 01xxxxxx xxxxxxxx | 占用2个字节,也就是16bits | 长度小于等于16383(2^14 - 1)字节的字节数组 |
| 10xxxxxx xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx | 占用5个字节,40bits | 长度小于等于4294967295(2^32 - 1)字节的字节数组 |
- 存储内容为整数
存储内容为整数时,encoding占用1个字节,最高位是11开头,后六位代表整数值的长度,其中当编码为1111xxxx时情况比较特殊,
后四位的值在0001和1101之间,此时直接代表数据的内容,是0到12之间的一个数字,并不是数据长度,因为它代表了数据内容,所以也不需要额外的空间存储数据内容。
| 编码 | 编码长度 | 数据类型 |
|---|---|---|
| 11000000 | 1个字节 | int16_t类型的整数 |
| 11010000 | 1个字节 | uint32_t类型的整数 |
| 11100000 | 1个字节 | uint64_t类型的整数 |
| 11110000 | 1个字节 | 24位有符号整数 |
| 11111110 | 1个字节 | 8位有符号整数 |
| 1111xxxx | 1个字节 | 特殊情况,后四位的值在0001和1101之间,此时代表的是数据内容,并不是数据长度 |
zipStoreEntryEncoding
// 节点编码所需字节数判断
unsigned int zipStoreEntryEncoding(unsigned char *p, unsigned char encoding, unsigned int rawlen) {
unsigned char len = 1, buf[5];
// 如果是字符串
if (ZIP_IS_STR(encoding)) {
/* 根据字符串的长度判断使用几个字节数 */
if (rawlen <= 0x3f) { // 小于等于63字节
if (!p) return len;
buf[0] = ZIP_STR_06B | rawlen;
} else if (rawlen <= 0x3fff) { // 小于等于16383字节
len += 1; // 使用2个字节
if (!p) return len;
buf[0] = ZIP_STR_14B | ((rawlen >> 8) & 0x3f);
buf[1] = rawlen & 0xff;
} else { // 字符串长度大于16383字节
len += 4; // 使用5个字节
if (!p) return len;
buf[0] = ZIP_STR_32B;
buf[1] = (rawlen >> 24) & 0xff;
buf[2] = (rawlen >> 16) & 0xff;
buf[3] = (rawlen >> 8) & 0xff;
buf[4] = rawlen & 0xff;
}
} else {
// 如果是整数,使用1个字节
if (!p) return len;
buf[0] = encoding;
}
/* 保存长度 */
memcpy(p,buf,len);
return len;
}
节点的插入
// 添加节点
// zl:指向压缩列表的指针
// s:数据内容
// slen:数据的长度
// where:在哪个位置添加
// 调用例子:zl = ziplistPush(zl, (unsigned char*)"foo", 3, ZIPLIST_TAIL);
unsigned char *ziplistPush(unsigned char *zl, unsigned char *s, unsigned int slen, int where) {
unsigned char *p;
// 判断是在头部或者尾部进行添加
p = (where == ZIPLIST_HEAD) ? ZIPLIST_ENTRY_HEAD(zl) : ZIPLIST_ENTRY_END(zl);
// 插入节点
return __ziplistInsert(zl,p,s,slen);
}
// 插入节点
// zl:指向压缩列表的指针
// p:添加的位置
// s:数据内容
// slen:数据的长度
unsigned char *__ziplistInsert(unsigned char *zl, unsigned char *p, unsigned char *s, unsigned int slen) {
size_t curlen = intrev32ifbe(ZIPLIST_BYTES(zl)), reqlen, newlen;
unsigned int prevlensize, prevlen = 0;
size_t offset;
int nextdiff = 0;
unsigned char encoding = 0;
long long value = 123456789;
zlentry tail;
// 判断要添加的位置是否是结尾处
if (p[0] != ZIP_END) {// 如果不是尾部
// 计算前一个节点的长度prevlen
ZIP_DECODE_PREVLEN(p, prevlensize, prevlen);
} else { // 如果是在尾部
unsigned char *ptail = ZIPLIST_ENTRY_TAIL(zl);
if (ptail[0] != ZIP_END) {
// 计算前一个节点的长度
prevlen = zipRawEntryLengthSafe(zl, curlen, ptail);
}
}
// 判断节点是否可以被Encoding
if (zipTryEncoding(s,slen,&value,&encoding)) {
// 计算将字符串转换为整数后的长度
reqlen = zipIntSize(encoding);
} else {
// 直接使用原始长度
reqlen = slen;
}
// reqlen用来保存当前节点所占用的长度
// 加上前一个节点编码所需要的字节数
reqlen += zipStorePrevEntryLength(NULL,prevlen);
// 加上当前节点编码所需要的字节数
reqlen += zipStoreEntryEncoding(NULL,encoding,slen);
/* 这里用于判断节点加入的时候,后面的节点prevrawlen的字节数是否可以满足要插入节点的长度*/
int forcelarge = 0;
nextdiff = (p[0] != ZIP_END) ? zipPrevLenByteDiff(p,reqlen) : 0;
if (nextdiff == -4 && reqlen < 4) {
nextdiff = 0;
forcelarge = 1;
}
offset = p-zl;
newlen = curlen+reqlen+nextdiff;
// 调整压缩列表的长度
zl = ziplistResize(zl,newlen);
p = zl+offset;
// 如果p不指向链表结尾,说明新加入的节点不是最后一个
if (p[0] != ZIP_END) {
/* 将p指向的节点和它之后的节点向后移动,为新节点腾出空间*/
memmove(p+reqlen,p-nextdiff,curlen-offset-1+nextdiff);
/* 当前节点的长度编码后存储到后一个节点的prevrawlen*/
if (forcelarge)
zipStorePrevEntryLengthLarge(p+reqlen,reqlen);
else
zipStorePrevEntryLength(p+reqlen,reqlen);
/* 更新结尾的OFFSET */
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+reqlen);
assert(zipEntrySafe(zl, newlen, p+reqlen, &tail, 1));
if (p[reqlen+tail.headersize+tail.len] != ZIP_END) {
ZIPLIST_TAIL_OFFSET(zl) =
intrev32ifbe(intrev32ifbe(ZIPLIST_TAIL_OFFSET(zl))+nextdiff);
}
} else {
/* 新加入的节点是列表的最后一个节点时 */
ZIPLIST_TAIL_OFFSET(zl) = intrev32ifbe(p-zl);
}
/* 这里判断是否需要连锁更新 */
if (nextdiff != 0) {
offset = p-zl;
zl = __ziplistCascadeUpdate(zl,p+reqlen);
p = zl+offset;
}
/* 插入节点*/
p += zipStorePrevEntryLength(p,prevlen);
p += zipStoreEntryEncoding(p,encoding,slen);
if (ZIP_IS_STR(encoding)) {
memcpy(p,s,slen);
} else {
zipSaveInteger(p,value,encoding);
}
// 修改压缩列表节点的数量
ZIPLIST_INCR_LENGTH(zl,1);
return zl;
}
连锁更新
因为压缩列表中每个节点记录了前一个节点的长度:
- 如果前一项节点的长度小于254字节,那么prevrawlen的长度是1字节。
- 如果前一项节点的长度大于254字节,那么prevrawlen的长度是5字节,其中第一个字节会被设置为0xFE(十进制154),之后的四个字节用于保存前一个节点的长度。
假设有一种情况,一个压缩列表中,存储了多个长度是253字节的节点,因为节点的长度都在254字节以内,所以每个节点的prevrawlen只需要1个字节去存储长度的值:
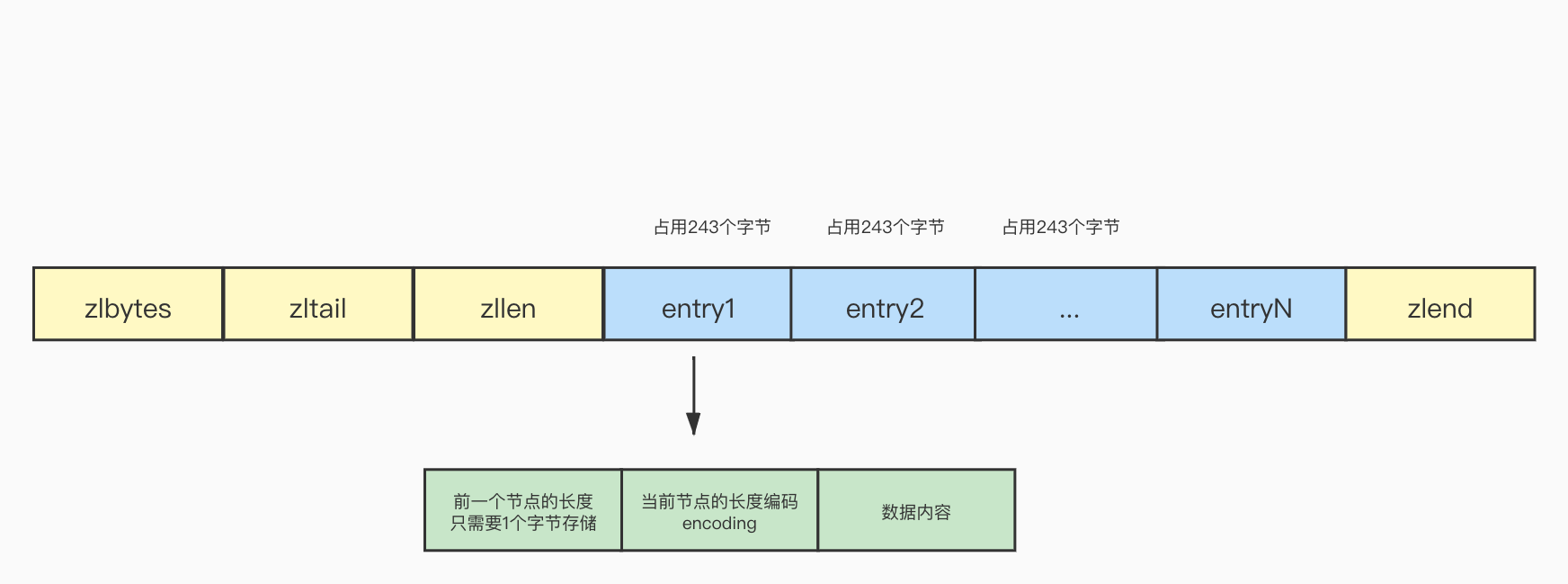
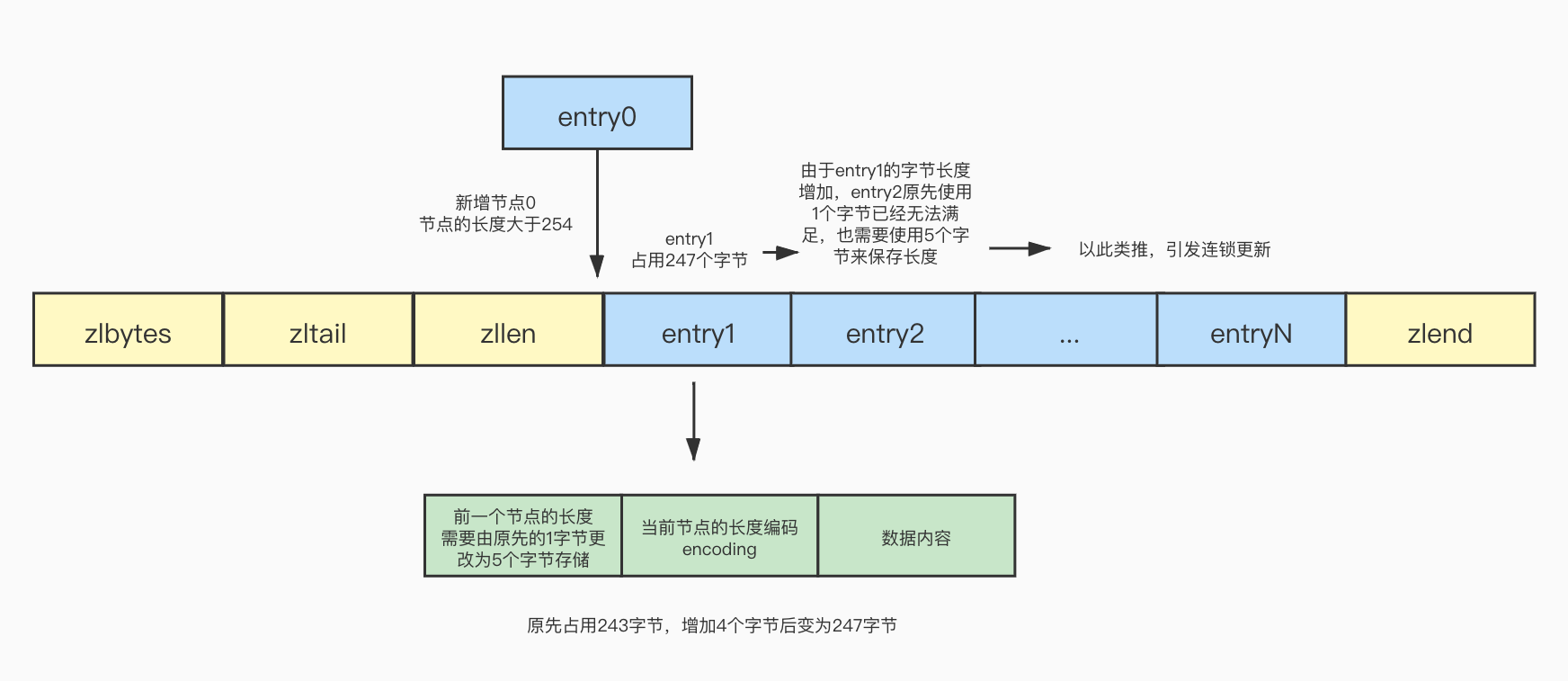
此时在列表的头部需要新增加一个节点,并且节点的长度大于254,这个时候原先的头结点entry1 prevrawlen使用1字节已经不能满足当前的情况了,必须要使用5字节存储,因此entry1的prevrawlen变成了5字节,entry1的长度也会跟着增加4个字节,已经超过了254字节,因为大于254就需要使用5个字节存储,所以entry2的prevrawlen也需要改变为5字节,后面的以此类推,引发了连锁更新,这种情况称之为连锁更新:
总结
(1)Redis压缩列表使用了一块连续的内存,来节约内存空间。
(2)压缩列表的节点可以存储字符串或者整数类型的值,它采用了变长的编码方式,根据数据类型的不同以及数据长度的不同,选择不同的编码方式,每种编码占用的字节大小不同,以此来节约内存。
(3)压缩列表的每个节点中存储了前一个节点的字节长度,如果知道某个节点的地址,可以使用地址减去字节长度定位到上一个节点,不过新增节点的时候,由于前一个节点的长度大于254使用5个字节,小于254使用1个字节存储,在一些极端的情况下由于长度的变化会引起连锁更新。
参考
黄健宏《Redis设计与实现》
【张铁蕾】Redis内部数据结构详解(4)——ziplist
【_HelloBug】Redis-压缩表-__ziplistInsert详解
Redis版本:redis-6.2.5
【Redis】ziplist压缩列表的更多相关文章
- Redis学习之ziplist压缩列表源码分析
一.压缩列表ziplist在redis中的应用 1.做列表键 当一个列表键只包含少量列表项,并且每个列表项要么是小整数,要么是短字符串,那么redis会使用压缩列表作为列表键的底层实现 2.哈希键 当 ...
- Redis 源码简洁剖析 05 - ziplist 压缩列表
ziplist 是什么 Redis 哪些数据结构使用了 ziplist? ziplist 特点 优点 缺点 ziplist 数据结构 ziplist 节点 pre_entry_length encod ...
- Redis源代码分析(六)--- ziplist压缩列表
ziplist和之前我解析过的adlist列表名字看上去的非常像.可是作用却全然不同.之前的adlist主要针对的是普通的数据链表操作. 而今天的ziplist指的是压缩链表.为什么叫压缩链表呢.由于 ...
- redis 5.0.7 源码阅读——压缩列表ziplist
redis中压缩列表ziplist相关的文件为:ziplist.h与ziplist.c 压缩列表是redis专门开发出来为了节约内存的内存编码数据结构.源码中关于压缩列表介绍的注释也写得比较详细. 一 ...
- Redis压缩列表原理与应用分析
摘要 Redis是一款著名的key-value内存数据库软件,同时也是一款卓越的数据结构服务软件.它支持字符串.列表.哈希表.集合.有序集合五种数据结构类型,同时每种数据结构类型针对不同的应用场景又支 ...
- Redis底层探秘(四):整数集合及压缩列表
整数集合 整数集合(intset)是集合键的底层实现之一,当一个集合只包含 整数值元素,并且这个集合的元素数量不多时,Redis就会使用郑书记和作为集合键的底层实现. 整数集合的实现 整数集合是red ...
- Redis 的底层数据结构(压缩列表)
上一篇我们介绍了 redis 中的整数集合这种数据结构的实现,也谈到了,引入这种数据结构的一个很大的原因就是,在某些仅有少量整数元素的集合场景,通过整数集合既可以达到字典的效率,也能使用远少于字典的内 ...
- redis源码之压缩列表ziplist
压缩列表ziplist1.简介连续,无序的数据结构.压缩列表是 Redis 为了节约内存而开发的, 由一系列特殊编码的连续内存块组成的顺序型(sequential)数据结构. 2.组成 属性 类型 长 ...
- redis 底层数据结构 压缩列表 ziplist
压缩列表是列表键和哈希键的底层实现之一.当一个列表键只包含少量列表项,并且每个列表项要么就是小整数,要么就是长度比较短的字符串,redis就会使用压缩列表来做列表键的底层实现 当一个哈希键只包含少量键 ...
随机推荐
- JavaSE常用类之File类
File类 只用于表示文件或目录的信息,不能对文件内容进行访问. java.io.File类∶代表文件和目录.在开发中,读取文件.生成文件.删除文件.修改文件的属性时经常会用到本类. File类不能访 ...
- 【技术积累】Eclipse使用系列【第一版】
Eclipse安装(Neon版本) Eclipse 最新版本 Eclipse Neon,这个首次鼓励用户使用 Eclipse Installer 来做安装,这是一种由Eclipse Oomph提供的新 ...
- 在边缘计算场景中使用Dapr
Dapr 是分布式应用程序可移植.事件驱动的运行时, 这里有几个关键字,我们拆开来看一下: 分布式: 代表共享或是分散,在云原生应用上体现为微服务,在边缘计算场景中代表分散的模块,可以做积木式拼接. ...
- [译]ng指令中的compile与link函数解析 转
通常大家在使用ng中的指令的时候,用的链接函数最多的是link属性,下面这篇文章将告诉大家complie,pre-link,post-link的用法与区别. 原文地址 angularjs里的指令非常神 ...
- Dockerfile 命令详解及最佳实践
Dockerfile 命令详解 FROM 指定基础镜像(必选) 所谓定制镜像,那一定是以一个镜像为基础,在其上进行定制.就像我们之前运行了一个 nginx 镜像的容器,再进行修改一样,基础镜像是必须指 ...
- Aop踩坑!记一次模板类调用注入属性为空的问题
问题起因 在做一个需求的时候,发现原来的代码逻辑都是基于模板+泛型的设计模式,模板用于规整逻辑处理流程,泛型用来转换参数和选取实现类.听上去是不是很nice! 类目录结构 AbstractTestAo ...
- PHP入门-Window 下利用Nginx+PHP 搭建环境
前言 最近公司有个PHP项目需要开发维护,之前一直都是跟着巨硬混的,现在要接触PHP项目.学习一门新语言之前,先搭建好环境吧,鉴于公司项目是基于php 7.1.33 版本的,所以以下我使用的都是基于这 ...
- XCTF练习题---MISC---功夫再高也怕菜刀
XCTF练习题---MISC---功夫再高也怕菜刀 flag:flag{3OpWdJ-JP6FzK-koCMAK-VkfWBq-75Un2z} 解题步骤: 1.观察题目,下载附件 2.下载到电脑后发现 ...
- .NET LoongArch64 正式合并进入.NET
国内自主的龙芯,在做龙芯技术生态就把 .NET 作为其中一部分考虑进去,这也将对接下来国内.NET应用场景充满了期待.通过dotnet/runtime 可以知道现在龙芯版本的 .NET 已经合并到.N ...
- 《HelloGitHub》第 73 期
兴趣是最好的老师,HelloGitHub 让你对编程感兴趣! 简介 HelloGitHub 分享 GitHub 上有趣.入门级的开源项目. https://github.com/521xueweiha ...