Prometheus 四种metric类型
Prometheus的4种metrics(指标)类型:
- Counter
- Gauge
- Histogram
- Summary
四种指标类型的数据对象都是数字,如果要监控文本类的信息只能通过指标名称或者 label 来呈现,在 zabbix 一类的监控中指标类型本身支持 Log 和文本,当然在这里我们不是要讨论 Prometheus 的局限性,而是要看一看 Prometheus 是如何把数字玩出花活的。 Counter 与 Gauge 比较好理解,我们简单的过一下 然后主要关注 Histogram 和 Summary
Counter 与 Gauge
Counter
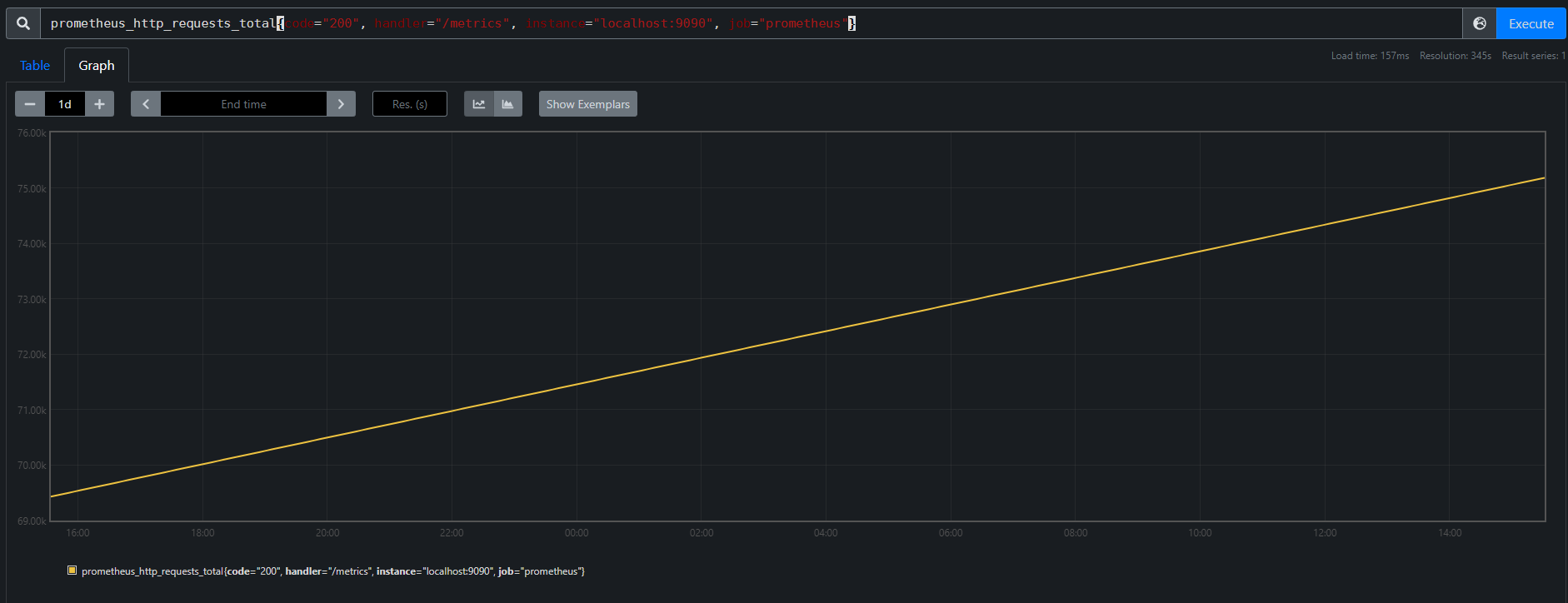
单调递增的计数器。
例如 Prometheus自身 中 metrics 的 http 请求总数
Gauge
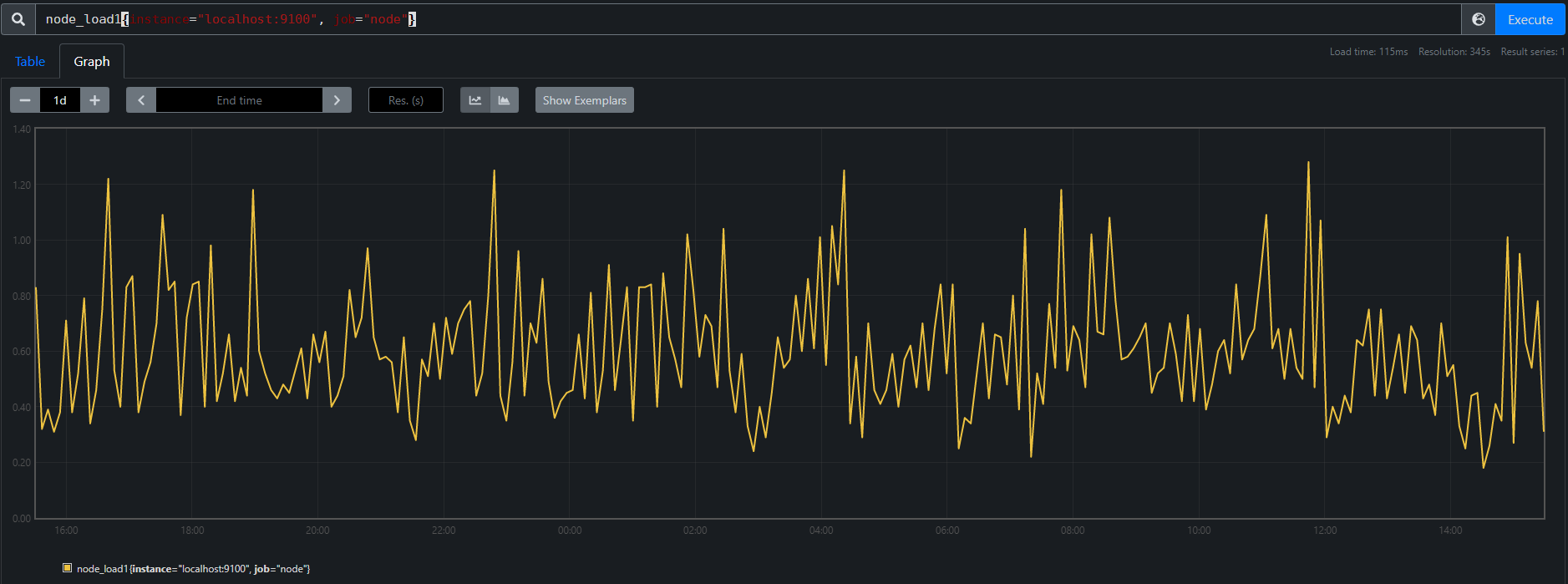
仪表,也可以认为是一种计数器,不过支持加和减。
例如 node 中的负载数据
Histogram 与 Summary
Histogram
直方图常用于请求持续时间或者响应大小采样,然后将结果记录到存储桶(bucket),每个桶为累加数据。
通过三个metrics名称来完整暴露一组Histogram
- 桶累积计数器,
<basename>_bucket{le="<upper inclusive bound>"} - 所有观察值的总和,
<basename>_sum - 已观察到的事件计数,
<basename>_count与上述相同<basename>_bucket{le="+Inf"})
例如K8s中pod启动耗时:
kubelet_pod_start_duration_seconds_bucket
kubelet_pod_start_duration_seconds_count #进行过pod start的数量
kubelet_pod_start_duration_seconds_sum # 总耗时
具体到某个节点中
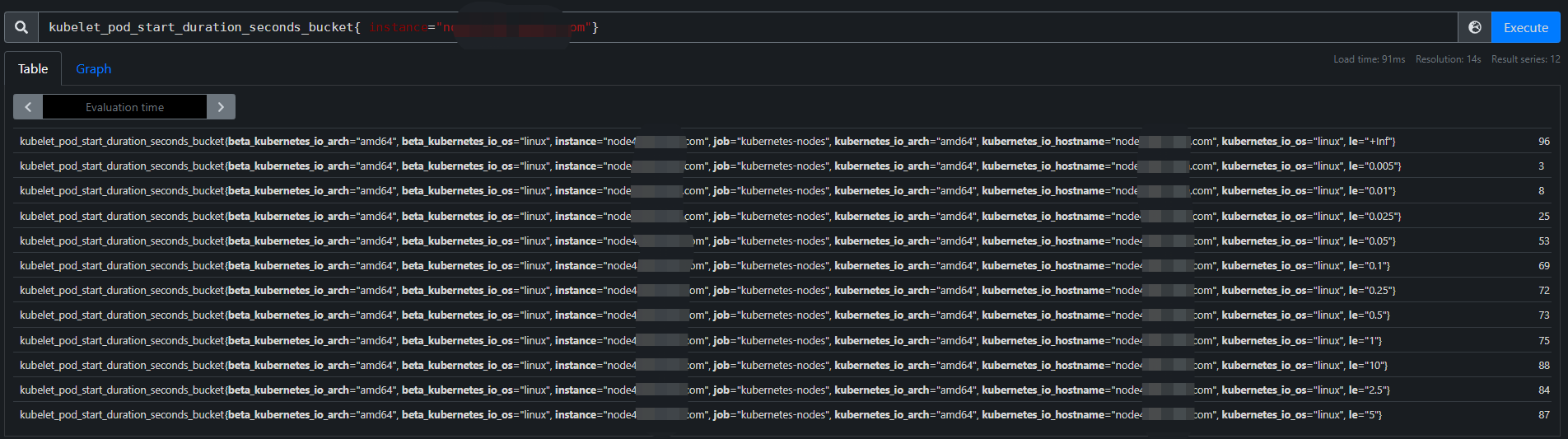
le:小于等于。例如le=”5“,即pod启动耗时<=5s的有87次
+inf:无穷。当启动耗时为无穷时,也就是节点下pod启动过的数量,与kubelet_pod_start_duration_seconds_count相等
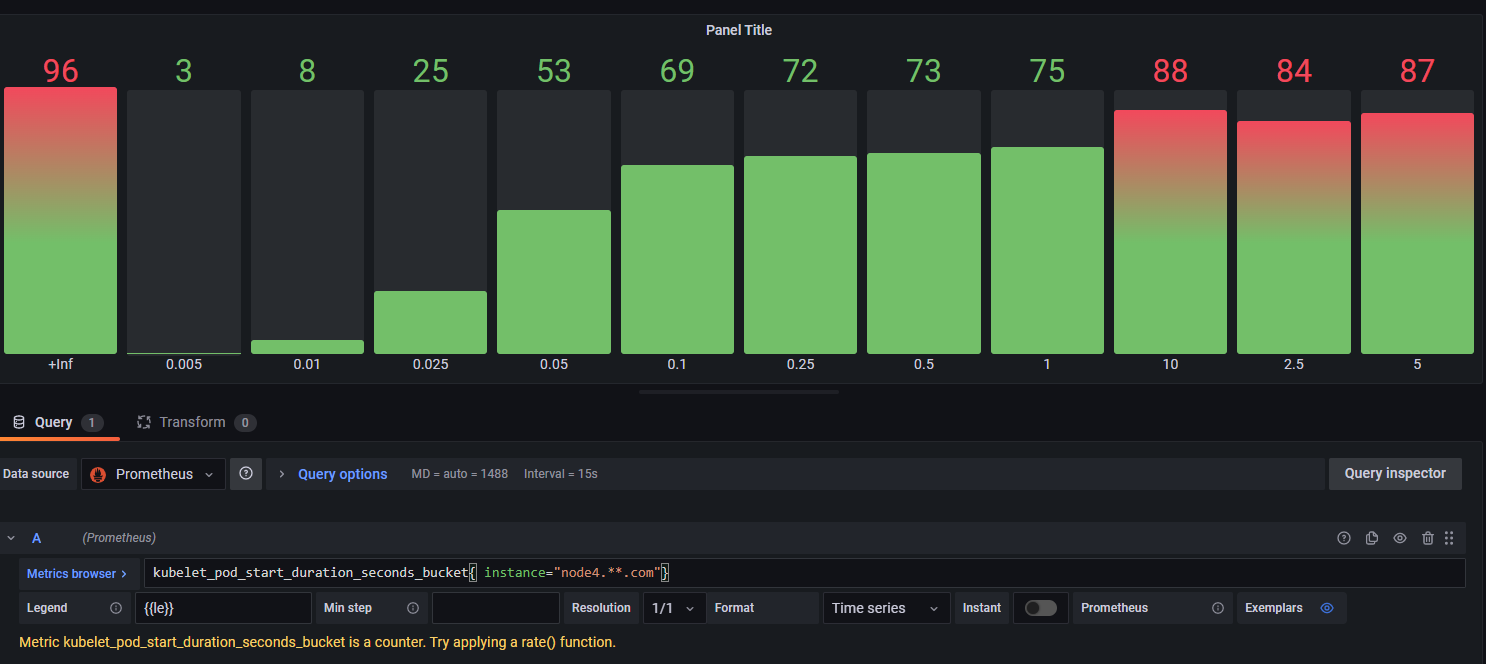
通过grafana 中 Bar gauge呈现桶的分布如下:
有了直方图数据后我们可以做相应的比例计算:
计算pod启动耗时大于1s,小于2.5s的次数
#kubelet_pod_start_duration_seconds_bucket{ instance="node4.**.com",le="2.5"} - ignoring(le) kubelet_pod_start_duration_seconds_bucket{ instance="node4.**.com",le="1"}
9
计算pod启动耗时大于2.5s的比例
#kubelet_pod_start_duration_seconds_bucket{ instance="node4.**.com",le="2.5"} / ignoring(le) kubelet_pod_start_duration_seconds_bucket{ instance="node4.**.com",le="+Inf"}
0.875
使用 PromQL 函数histogram_quantile计算百分位
#histogram_quantile(0.80,kubelet_pod_start_duration_seconds_bucket{ instance="node4.**.com"} )
1.3000000000000018
即80%的pod启动次数中,耗时<=1.3s,histogram_quantile函数计算百分位得到是一个近似值。
通过histogram_quantile函数聚合
计算Prometheus http所有请求中80百分位的值
histogram_quantile(0.8, sum(rate(prometheus_http_request_duration_seconds_bucket[5m])) by (le))

即80%的请求响应时间<=0.08s
通过histogram计算网站性能指标 - Apdex指数
Apdex 指数 =( 满意数量 + 0.5 * 可容忍数量 ) / 总样本数,假设请求满意时间为0.3s,则可容忍时间为1.2s(4倍)
(
sum(rate(http_request_duration_seconds_bucket{le="0.3"}[5m])) by (job)
+
sum(rate(http_request_duration_seconds_bucket{le="1.2"}[5m])) by (job)
) / 2 / sum(rate(http_request_duration_seconds_count[5m])) by (job)
Summary
Summary与Histogram相似,也是通过三个metrics名称来完整暴露一组Summary,不过Summary是直接在客户端帮我们计算出了百分位数(Histogram 则使用上面提到的histogram_quantile函数计算)
- φ 分位数(0 ≤ φ ≤ 1),
<basename>{quantile="<φ>"} - 所有观察值的总和,
<basename>_sum - 已观察到的事件计数,
<basename>_count
例如cgroup操作延迟:
kubelet_cgroup_manager_latency_microseconds
kubelet_cgroup_manager_latency_microseconds_sum
kubelet_cgroup_manager_latency_microseconds_count

Summary和Histogram都可以使用rate函数计算平均数
计算cgroup update操作的平均延迟:
rate(kubelet_cgroup_manager_latency_microseconds_sum{ instance="node4.**.com",operation_type="update"}[10m]) / rate(kubelet_cgroup_manager_latency_microseconds_count{ instance="node4.**.com",operation_type="update"}[10m])
最后我们对比一下Summary与Histogram
| Histogram | Summary | |
|---|---|---|
| 配置要求 | 选择符合预期观测值范围(le)的存储桶 | 选择所需的分位数φ和窗口范围,其他φ无法再被计算 |
| 客户端性能影响 | 低,仅需增加计数器 | 高,在客户端计算分位数 |
| 服务端性能影响 | 高,服务端需计算分位数 | 服务端成本低 |
时间序列的数量(除了_sum和_count序列) |
每添加一个存储桶增加一个时间序列 | 每添加一个分位数φ 值增加一个时间序列 |
| 分位数误差 | 受限于相关桶的宽度 | 误差在 φ 值的限制 |
| φ分位数和窗口范围 | 取决于histogram_quantile函数中φ | 由客户端预先添加 |
| 聚合 | histogram_quantile函数聚合 | 不聚合 |
通过博客阅读:iqsing.github.io
参考:
Prometheus 四种metric类型的更多相关文章
- MySQL表的四种分区类型
MySQL表的四种分区类型 一.什么是表分区 通俗地讲表分区是将一大表,根据条件分割成若干个小表.mysql5.1开始支持数据表分区了. 如:某用户表的记录超过了600万条,那么就可以根据入库日期将表 ...
- C++中四种转换类型的区别
一.四种转换类型比较: 类型转换有c风格的,当然还有c++风格的.c风格的转换的格式很简单(TYPE)EXPRESSION,但是c风格的类型转换有不少的缺点,有的时候用c风格的转换是不合适的,因为它可 ...
- RabbitMQ四种交换机类型介绍
RabbitMQ 原文地址: https://baijiahao.baidu.com/s?id=1577456875919174629&wfr=spider&for=pc 最新版本的 ...
- ASP.NET MVC中有四种过滤器类型
在ASP.NET MVC中有四种过滤器类型
- python 四种数值类型(int,long,float,complex)介绍
Python支持四种不同的数值类型,包括int(整数)long(长整数)float(浮点实际值)complex (复数),本文章向码农介绍python 四种数值类型,需要的朋友可以参考一下. 数字数据 ...
- Delphi中定义了四种布尔类型:Boolean,ByteBool,WordBool和LongBool。后面三种布尔类型是为了与其他语言兼容而引入的
bool是LongBool类型. Delphi中定义了四种布尔类型:Boolean,ByteBool,WordBool和LongBool.后面三种布尔类型是为了与其他语言兼容而引入的,一般情况下建议使 ...
- JDBC 学习笔记(二)—— 详解 JDBC 的四种驱动类型
JDBC 有四种驱动类型,分别是: JDBC-ODBC 桥(JDBC-ODBC bridge driver plus ODBC driver) 本地 API 驱动(Native-API partly ...
- MySQL有四种BLOB类型
先说明一下Blob的类型,直接从网上摘抄了!!!1.MySQL有四种BLOB类型: ·tinyblob:仅255个字符 ·blob:最大限制到65K字节 ·mediumblob:限制到16M字节 ·l ...
- java gRPC四种服务类型简单示例
一.gRPC 简介 gRPC 是Go实现的:一个高性能,开源,将移动和HTTP/2放在首位通用的RPC框架.使用gRPC可以在客户端调用不同机器上的服务端的方法,而客户端和服务端的开发语言和 运行环境 ...
随机推荐
- 轻量化安装 TKEStack:让已有 K8s 集群拥有企业级容器云平台的能力
关于我们 更多关于云原生的案例和知识,可关注同名[腾讯云原生]公众号~ 福利: ①公众号后台回复[手册],可获得<腾讯云原生路线图手册>&<腾讯云原生最佳实践>~ ②公 ...
- MySQL发展历史
MySQL(发音为"my ess cue el")是一种关系型数据库管理系统, MySQL数据库管理系统由瑞典的DataKonsultAB公司研发,该公司被Sun公司收购,现在Su ...
- re模块、collections模块、time模块、datetime模块
正则表达式之re模块 re.findall用法(重要) re.findall( '正则表达式' , '待匹配的字符' ) 找出所有的目标字符,用列表的形式展现,如果找不到返回空列表. import r ...
- 使用Camera API https://developer.mozilla.org/zh-CN/docs/Web/Guide/API/Camera
使用Camera API 在本文章中 获取到所拍摄照片的引用 在网页中展示图片 完整的示例代码 HTML页面: JavaScript文件: 浏览器兼容性 通过Camera API,你可以使用手机的摄像 ...
- Blazor Bootstrap 组件库地理定位/移动距离追踪组件介绍
地理定位/移动距离追踪组件 通过浏览器 API 获取定位信息 DEMO https://www.blazor.zone/geolocations 小提示 注意: 出于安全考虑,当网页请求获取用户位置信 ...
- docker基础_Dockerfile
Dockerfile []: https://docs.docker.com/language/python/build-images/ "docker官方文档" 以python为 ...
- Android 12(S) 图像显示系统 - 基础知识之 BitTube
必读: Android 12(S) 图像显示系统 - 开篇 一.基本概念 在Android显示子系统中,我们会看到有使用BitTube来进行跨进程数据传递.BitTube的实现很简洁,就是一对&quo ...
- Day 001:PAT练习--1091 N-自守数 (15 分)
体验了一阵子现代生活后,朕发现敲代码还是挺有意思的.所以从今天开始,小编秦始皇开始记录朕做PAT题目的过程辣,那话不多说,开始今天的题目了: 题目描述: 如果某个数 K 的平方乘以 N 以后, ...
- XCTF练习题---WEB---Cookie
XCTF练习题---WEB---Cookie flag:cyberpeace{dc6a6799546a3e0fbfeacb8650b55ff0} 解题步骤: 1.观察题目,打开场景 2.观察场景内容, ...
- ubuntu 16.04,ros kinetic 使用husy_gazebo
我当前使用的是ubuntu 16.04,ros kinetic ,Gazebo版本为7.0.protoc需要确保版本为2.6.1,而我当前的为3.4.0,因此需要将系统中的protoc替换为2.6.1 ...