1.5.6 NN与2NN-hadoop-最全最完整的保姆级的java大数据学习资料
1.5.6 NN与2NN
1.5.6.1 HDFS元数据管理机制
问题1:NameNode如何管理和存储元数据?
计算机中存储数据两种:内存或者是磁盘
元数据存储磁盘:存储磁盘无法面对客户端对元数据信息的任意的快速低延迟的响应,但是安全性高
元数据存储内存:元数据存放内存,可以高效的查询以及快速响应客户端的查询请求,数据保存在内 存,如果断点,内存中的数据全部丢失。
解决方案:内存+磁盘;NameNode内存+FsImage的文件(磁盘)
新问题:磁盘和内存中元数据如何划分?
两个数据一模一样,还是两个数据合并到一起才是一份完整的数据呢?
一模一样:client如果对元数据进行增删改操作,需要保证两个数据的一致性。FsImage文件操作起来 效率也不高。
两个合并=完整数据:NameNode引入了一个edits文件(日志文件:只能追加写入)edits文件记录的 是client的增删改操作,
不再选择让NameNode把数据dump出来形成FsImage文件(这种操作是比较消耗资源)。
元数据管理流程图
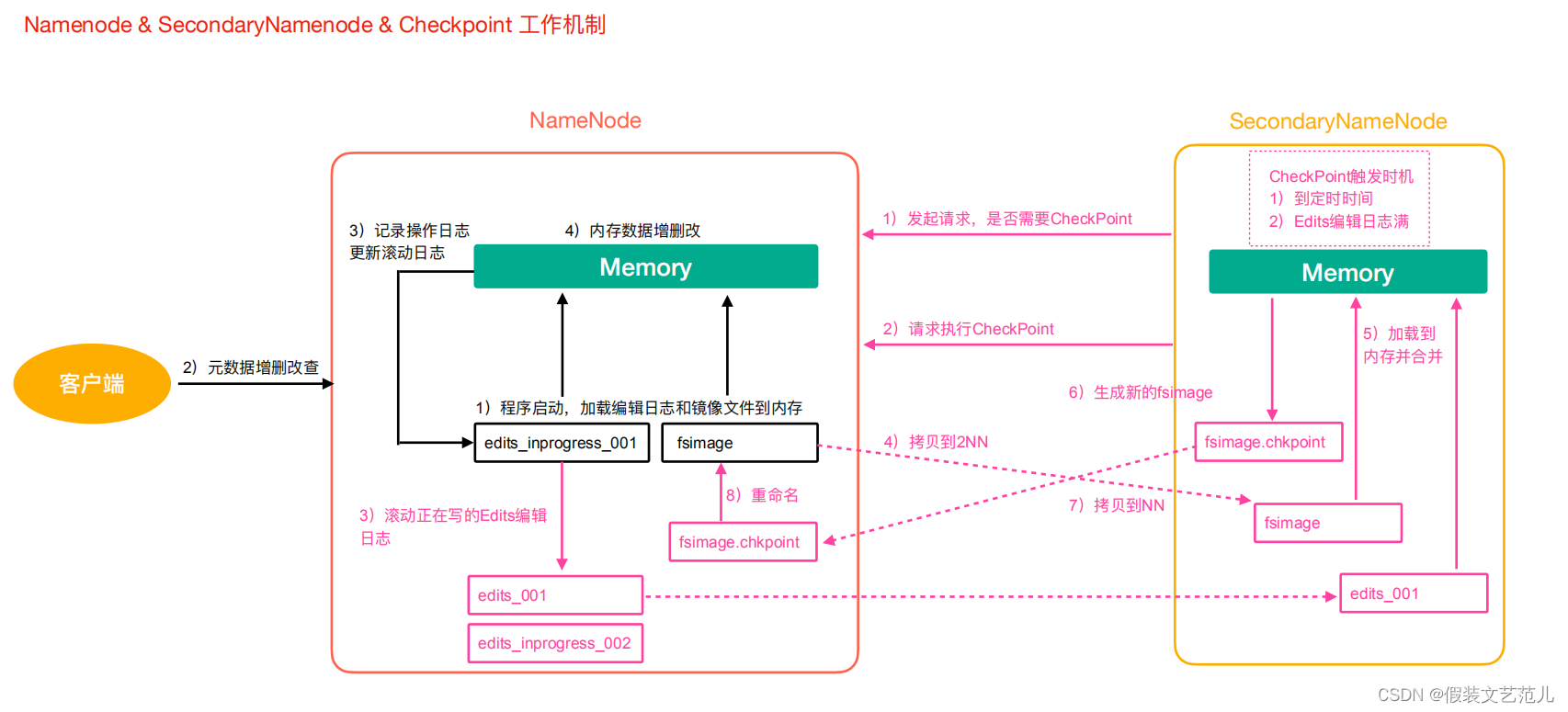
第一阶段:NameNode启动
第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
客户端对元数据进行增删改的请求。
NameNode记录操作日志,更新滚动日志。
NameNode在内存中对数据进行增删改。
第二阶段:Secondary NameNode工作
- Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否执行检查点操作结果。
- Secondary NameNode请求执行CheckPoint。
- NameNode滚动正在写的Edits日志。
- 将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
- Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
- 生成新的镜像文件fsimage.chkpoint。
- 拷贝fsimage.chkpoint到NameNode。
- NameNode将fsimage.chkpoint重新命名成fsimage。
1.5.6.2 Fsimage与Edits文件解析
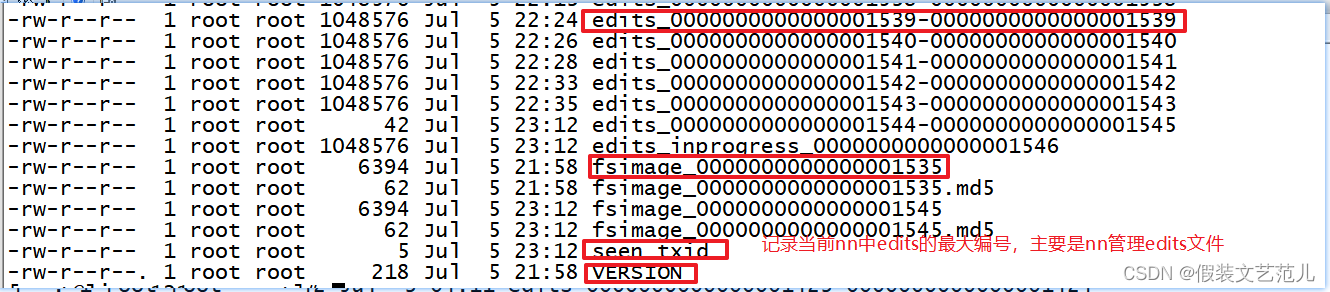
NameNode在执行格式化之后,会在/opt/lagou/servers/hadoop-2.9.2/data/tmp/dfs/name/current目录下产生如下文件

- Fsimage文件:是namenode中关于元数据的镜像,一般称为检查点,这里包含了HDFS文件系统所有目录以及文件相关信息(Block数量,副本数量,权限等信息)
- Edits文件 :存储了客户端对HDFS文件系统所有的更新操作记录,Client对HDFS文件系统所有的更新操作都会被记录到Edits文件中(不包括查询操作)
- seen_txid:该文件是保存了一个数字,数字对应着最后一个Edits文件名的数字
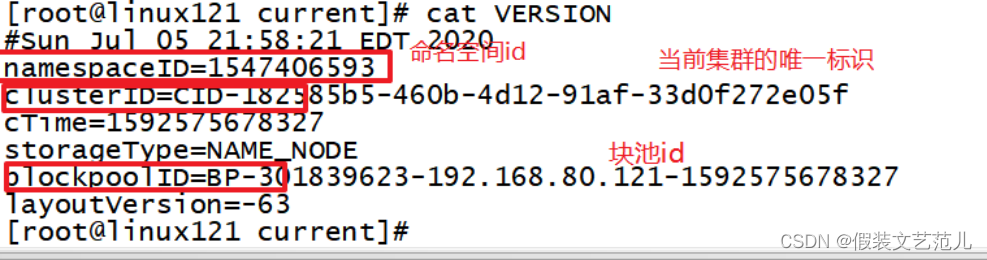
- VERSION:该文件记录namenode的一些版本号信息,比如:CusterId,namespaceID等
1.5.6.2.1 Fsimage文件内容
官方地址https://hadoop.apache.org/docs/r2.9.2/hadoop-project-dist/hadoop-hdfs/HdfsImageViewer.html
查看oiv和oev命令
[root@linux121 current]$ hdfs oiv Offline Image Viewer View a Hadoop fsimage INPUTFILE using the specified PROCESSOR,saving the results in OUTPUTFILE. oev Offline edits viewer Parse a Hadoop edits log file INPUT_FILE and save results in OUTPUT_FILE
基本语法
hdfs oiv -p 文件类型(xml) -i 镜像文件 -o 转换后文件输出路径
案例实操
[root@linux121 current]$ cd /opt/lagou/servers/hadoop-2.9.2/data/tmp/dfs/name/current
[root@linux121 current]$ hdfs oiv -p XML -i fsimage_0000000000000000265 -o /opt/lagou/servers/fsimage.xml
[root@linux121 current]$ cat /opt/lagou/servers/fsimage.xml
<?xml version="1.0"?>
<fsimage>
<version>
<layoutVersion>-63</layoutVersion>
<onDiskVersion>1</onDiskVersion>
<oivRevision>826afbeae31ca687bc2f8471dc841b66ed2c6704</oivRevision>
</version>
<NameSection>
<namespaceId>1393381414</namespaceId>
<genstampV1>1000</genstampV1>
<genstampV2>1024</genstampV2>
<genstampV1Limit>0</genstampV1Limit>
<lastAllocatedBlockId>1073741848</lastAllocatedBlockId>
<txid>265</txid>
</NameSection>
<INodeSection>
<inode>
<id>16398</id>
<type>DIRECTORY</type>
<name>history</name>
<mtime>1592376391028</mtime>
<permission>root:supergroup:0777</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>16399</id>
<type>DIRECTORY</type>
<name>done_intermediate</name>
<mtime>1592375256896</mtime>
<permission>root:supergroup:1777</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>16400</id>
<type>DIRECTORY</type>
<name>root</name>
<mtime>1592378079208</mtime>
<permission>root:supergroup:0777</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>16413</id>
<type>FILE</type>
<name>job_1592375222804_0001-1592375231176-root-word+count-1592375281926-1-1-SUCCEEDED-default- 1592375261492.jhist</name>
<replication>3</replication>
<mtime>1592375282039</mtime>
<atime>1592375281980</atime>
<preferredBlockSize>134217728</preferredBlockSize>
<permission>root:supergroup:0777</permission>
<blocks>
<block>
<id>1073741834</id>
<genstamp>1010</genstamp>
<numBytes>33584</numBytes>
</block>
</blocks>
<storagePolicyId>0</storagePolicyId>
</inode>
<inode>
<id>16414</id>
<type>FILE</type>
<name>job_1592375222804_0001_conf.xml</name>
<replication>3</replication>
<mtime>1592375282121</mtime>
<atime>1592375282053</atime>
<preferredBlockSize>134217728</preferredBlockSize>
<permission>root:supergroup:0777</permission>
<blocks>
<block>
<id>1073741835</id>
<genstamp>1011</genstamp>
<numBytes>196027</numBytes>
</block>
</blocks>
<storagePolicyId>0</storagePolicyId>
</inode>
<inode>
<id>16415</id>
<type>DIRECTORY</type>
<name>done</name>
<mtime>1592376776670</mtime>
<permission>root:supergroup:0777</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode> <inode>
<id>16427</id>
<type>DIRECTORY</type>
<name>logs</name>
<mtime>1592378009623</mtime>
<permission>root:root:0770</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>16428</id>
<type>DIRECTORY</type>
<name>application_1592376944601_0001</name>
<mtime>1592378045481</mtime>
<permission>root:root:0770</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>16430</id>
<type>DIRECTORY</type>
<name>wcoutput</name>
<mtime>1592378037463</mtime>
<permission>root:supergroup:0755</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>16436</id>
<type>FILE</type>
<name>part-r-00000</name>
<replication>3</replication>
<mtime>1592378037264</mtime>
<atime>1592378037074</atime>
<preferredBlockSize>134217728</preferredBlockSize>
<permission>root:supergroup:0644</permission>
<blocks>
<block>
<id>1073741842</id>
<genstamp>1018</genstamp>
<numBytes>43</numBytes>
</block>
</blocks>
<storagePolicyId>0</storagePolicyId>
</inode>
<inode>
<id>16445</id>
<type>FILE</type>
<name>linux123_39919</name>
<replication>3</replication>
<mtime>1592378045469</mtime>
<atime>1592378045331</atime>
<preferredBlockSize>134217728</preferredBlockSize>
<permission>root:root:0640</permission>
<blocks>
<block>
<id>1073741848</id>
<genstamp>1024</genstamp>
<numBytes>56910</numBytes>
</block>
</blocks>
<storagePolicyId>0</storagePolicyId>
</inode>
<inode>
<id>16446</id>
<type>DIRECTORY</type>
<name>0617</name>
<mtime>1592387393490</mtime>
<permission>root:supergroup:0755</permission>
<nsquota>-1</nsquota>
<dsquota>-1</dsquota>
</inode>
<inode>
<id>16449</id>
<type>FILE</type>
<name>banzhang.txt</name>
<replication>1</replication>
<mtime>1592388309046</mtime>
<atime>1592388309026</atime>
<preferredBlockSize>134217728</preferredBlockSize>
<permission>root:supergroup:0644</permission>
<storagePolicyId>0</storagePolicyId>
</inode>
</INodeSection> </fsimage>
问题:Fsimage中为什么没有记录块所对应DataNode?
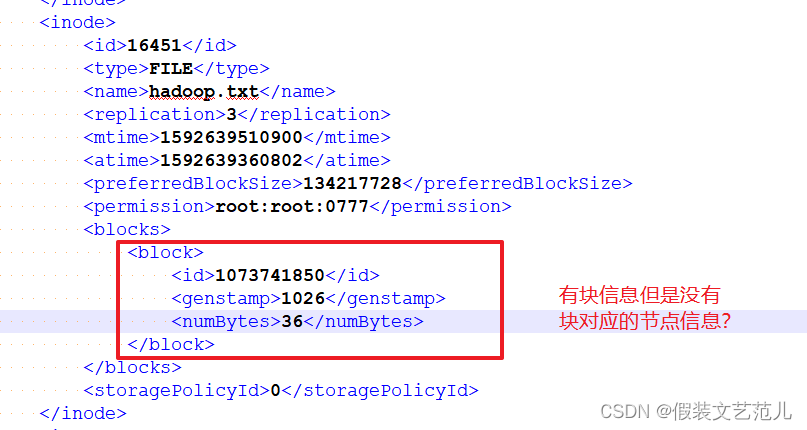
在内存元数据中是有记录块所对应的dn信息,但是fsimage中就剔除了这个信息;HDFS集群在启动的 时候会加载image以及edits文件,block对应的dn信息
都没有记录,集群启动时会有一个安全模式 (safemode),安全模式就是为了让dn汇报自己当前所持有的block信息给nn来补全元数据。后续每隔一段时间dn
都要汇报自己持有的block信息。
1.5.6.2.2 Edits文件内容
- 基本语法
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
案例实操
[root@linux121 current]$ hdfs oev -p XML -i edits_0000000000000000266- 0000000000000000267 -o /opt/lagou/servers/hadoop-2.9.2/edits.xml
[root@linux121 current]$ cat /opt/lagou/servers/hadoop-2.9.2/edits.xml
<?xml version="1.0" encoding="UTF-8"?>
<EDITS>
<EDITS_VERSION>-63</EDITS_VERSION>
<RECORD>
<OPCODE>OP_START_LOG_SEGMENT</OPCODE>
<DATA>
<TXID>113</TXID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_SET_PERMISSIONS</OPCODE>
<DATA>
<TXID>114</TXID>
<SRC>/wcoutput/_SUCCESS</SRC>
<MODE>493</MODE>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_SET_PERMISSIONS</OPCODE>
<DATA>
<TXID>115</TXID>
<SRC>/wcoutput/part-r-00000</SRC>
<MODE>493</MODE>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_SET_PERMISSIONS</OPCODE>
<DATA>
<TXID>116</TXID>
<SRC>/wcoutput</SRC>
<MODE>511</MODE>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_SET_PERMISSIONS</OPCODE>
<DATA>
<TXID>117</TXID>
<SRC>/wcoutput/_SUCCESS</SRC>
<MODE>511</MODE>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_SET_PERMISSIONS</OPCODE>
<DATA>
<TXID>118</TXID>
<SRC>/wcoutput/part-r-00000</SRC>
<MODE>511</MODE>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_DELETE</OPCODE>
<DATA>
<TXID>119</TXID>
<LENGTH>0</LENGTH>
<PATH>/wcoutput/part-r-00000</PATH>
<TIMESTAMP>1592377324171</TIMESTAMP>
<RPC_CLIENTID></RPC_CLIENTID>
<RPC_CALLID>-2</RPC_CALLID>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_SET_PERMISSIONS</OPCODE>
<DATA>
<TXID>120</TXID>
<SRC>/</SRC>
<MODE>511</MODE>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_SET_PERMISSIONS</OPCODE>
<DATA>
<TXID>121</TXID>
<SRC>/tmp</SRC>
<MODE>511</MODE>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_SET_PERMISSIONS</OPCODE>
<DATA>
<TXID>122</TXID>
<SRC>/tmp/hadoop-yarn</SRC>
<MODE>511</MODE>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_SET_PERMISSIONS</OPCODE>
<DATA>
<TXID>123</TXID>
<SRC>/tmp/hadoop-yarn/staging</SRC>
<MODE>511</MODE>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_SET_PERMISSIONS</OPCODE>
<DATA>
<TXID>124</TXID>
<SRC>/tmp/hadoop-yarn/staging/history</SRC>
<MODE>511</MODE>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_SET_PERMISSIONS</OPCODE>
<DATA>
<TXID>125</TXID>
<SRC>/tmp/hadoop-yarn/staging/history/done</SRC>
<MODE>511</MODE>
</DATA>
</RECORD>
<RECORD>
<OPCODE>OP_SET_PERMISSIONS</OPCODE>
<DATA>
<TXID>126</TXID>
<SRC>/tmp/hadoop-yarn/staging/history/done/2020</SRC>
<MODE>511</MODE>
</DATA>
</RECORD>
<RECORD>
备注:Edits中只记录了更新相关的操作,查询或者下载文件并不会记录在内!!
问题:NameNode启动时如何确定加载哪些Edits文件呢?
nn启动时需要加载fsimage文件以及那些没有被2nn进行合并的edits文件,nn如何判断哪些edits已经被合并了呢?
可以通过fsimage文件自身的编号来确定哪些已经被合并。

1.5.6.3 checkpoint周期
[hdfs-default.xml]
<!-- 定时一小时 -->
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600</value>
</property>
<!-- 一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次 -->
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60</value>
<description>1分钟检查一次操作次数</description>
</property>
1.5.6 NN与2NN-hadoop-最全最完整的保姆级的java大数据学习资料的更多相关文章
- 大数据学习之Hadoop快速入门
1.Hadoop生态概况 Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠.高效 ...
- 大数据学习(一) | 初识 Hadoop
作者: seriouszyx 首发地址:https://seriouszyx.top/ 代码均可在 Github 上找到(求Star) 最近想要了解一些前沿技术,不能一门心思眼中只有 web,因为我目 ...
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习之路之Hadoop
Hadoop介绍 一.简介 Hadoop是一个开源的分布式计算平台,用于存储大数据,并使用MapReduce来处理.Hadoop擅长于存储各种格式的庞大的数据,任意的格式甚至非结构化的处理.两个核心: ...
- 大数据学习笔记之Hadoop(一):Hadoop入门
文章目录 大数据概论 一.大数据概念 二.大数据的特点 三.大数据能干啥? 四.大数据发展前景 五.企业数据部的业务流程分析 六.企业数据部的一般组织结构 Hadoop(入门) 一 从Hadoop框架 ...
- java大数据最全课程学习笔记(1)--Hadoop简介和安装及伪分布式
Hadoop简介和安装及伪分布式 大数据概念 大数据概论 大数据(Big Data): 指无法在一定时间范围内用常规软件工具进行捕捉,管理和处理的数据集合,是需要新处理模式才能具有更强的决策力,洞察发 ...
- 大数据学习系列之八----- Hadoop、Spark、HBase、Hive搭建环境遇到的错误以及解决方法
前言 在搭建大数据Hadoop相关的环境时候,遇到很多了很多错误.我是个喜欢做笔记的人,这些错误基本都记载,并且将解决办法也写上了.因此写成博客,希望能够帮助那些搭建大数据环境的人解决问题. 说明: ...
随机推荐
- 使用Logstash把MySQL数据导入到Elasticsearch中
总结:这种适合把已有的MySQL数据导入到Elasticsearch中 有一个csv文件,把里面的数据通过Navicat Premium 软件导入到数据表中,共有998条数据 文件下载地址:https ...
- switch分支
说明: 当表达式的值等于case中的常量,则会执行其中包含的语句块 break用于跳出循环,如果不写,则直接执行下一个常量的语句块,不再去判断表达式的值是否等于下一个case的常量(case穿透) 最 ...
- 欢迎来到ktq_cpp的cnblog
欢迎来到ktq_cpp的cnblog 初学html,可能排版有一些问题,望指教 我的洛谷博客 我的AtCoder账号
- 洛谷P6033 [NOIP2004 提高组] 合并果子 加强版 (单调队列)
数据加强了,原来nlogn的复杂度就不行了...... 首先对原来的n个数排序(注意不能用快排),因为值域是1e5,所以可以开桶排序,开两个队列,一个存原来的n个数(已经满足单增),另一队列存两两合并 ...
- kafka详解(二)--kafka为什么快
前言 Kafka 有多快呢?我们可以使用 OpenMessaging Benchmark Framework 测试框架方便地对 RocketMQ.Pulsar.Kafka.RabbitMQ 等消息系统 ...
- 微信小程序js-时间转换函数使用
最近在做云开发博客小程序 采集微信发布的信息放入数据库会有createTime因此发现了不一样的地方 云函数可以直接使用 但是放到引导全局的app.js文件却是找不到该方法-->dateform ...
- ifram父页面、子页面元素及方法的获取调用
page1 父页面 <div id="ifram" class="parent1"> <iframe frameborder="0& ...
- Hive之命令
Hive之命令 说明:此博客只记录了一些常见的hql,create/select/insert/update/delete这些基础操作是没有记录的. 一.时间级 select day -- 时间 ,d ...
- Linux实战笔记_CentOS7_无法识别NTFS格式的U盘
注:因为CentOS 默认不识别NTFS的磁盘格式,所以我们要借助另外一个软件ntfs-3g来挂载.自带的yum源没有这个软件,要用第三方的软件源,比如阿里的epel. #安装ntfs-3g cd / ...
- 学生管理系统(C语言简单实现)
仅供借鉴.仅供借鉴.仅供借鉴(整理了一下大一C语言每个章节的练习题.没得题目.只有程序了) 文章目录 1 .实训名称 2.实训目的及要求 3. 源码 4.实验小结 1 .实训名称 实训12:文件 2. ...