【Spark】Day01-入门、模块组成、4种运行模式详解及配置、案例实操(spark分析过程)
一、概述
1、概念
基于内存的大数据分析计算引擎
2、特点
快速、通用、可融合性
3、Spark内置模块【腾讯8000台spark集群】
Spark运行在集群管理器(Cluster Manager)上,支持3种集群管理器:Yarn、Standalone(脱机,Spark自带)、Apache Mesos(国外)
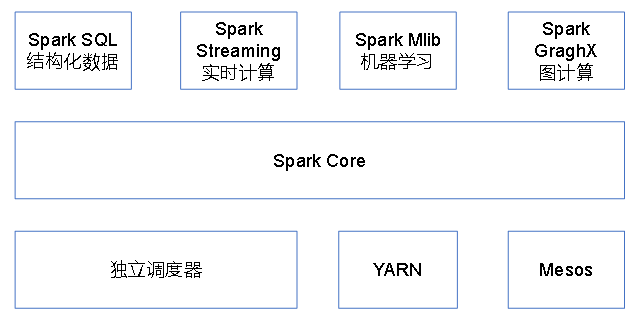
Spark Core:基本功能(任务调度、内存管理、错误恢复、与存储系统交互)、弹性Resilient 分布式数据集RDD的API
Spark SQl:操作结构化数据的程序包,数据查询,并支持多种数据源(Hive 表、Parquet 以及 JSON 等)
Spark Streaming:流式计算,提供用来操作数据流的 API,与Core中的RDD API高度对应
Spark MLlib:机器学习库,以及模型评估、数据导入等功能
Spark GraphX :图计算和挖掘
二、Spark运行模式:单机模式与集群模式
1、概念
(1)分类
Local、Standalone(自带的任务调度)、YARN、Mesos
(2)核心概念
|
Term |
Meaning |
|
Application |
User program built on Spark. Consists of a driver program and executors on the cluster. (构建于 Spark 之上的应用程序. 包含驱动程序和运行在集群上的执行器) |
|
Driver program 驱动程序 |
负责把并行操作发布到集群上,SparkContext对象相当于一个到 Spark 集群的连接(直接与工作节点相连,并受集群管理器的管理) |
|
Cluster manager 集群管理器 |
An external service for acquiring resources on the cluster (e.g. standalone manager, Mesos, YARN) |
|
Deploy mode 运行模式 |
Distinguishes where the driver process runs. In “cluster” mode, the framework launches the driver inside of the cluster. In “client” mode, the submitter launches the driver outside of the cluster. |
|
Worker node |
特有资源调度系统的 Slave,类似于 Yarn 框架中的 NodeManager,功能包括:注册到maser、发送心跳、执行task |
|
Executor 执行器 |
执行计算和为应用程序存储数据,SparkContext对象发送程序代码以及任务到执行器开始执行程序 |
|
Task |
A unit of work that will be sent to one executor |
|
Job |
A parallel computation consisting of multiple tasks that gets spawned in response to a Spark action (e.g. save, collect); you’ll see this term used in the driver’s logs. |
|
Stage |
Each job gets divided into smaller sets of tasks called stages that depend on each other (similar to the map and reduce stages in MapReduce); you’ll see this term used in the driver’s logs. |
2、Local模式
(1)使用方式
发布应用程序
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
使用run-examples来运行:bin/run-example SparkPi 100
使用shell:bin/spark-shell(可以通过web查看运行情况)
(2)提交流程
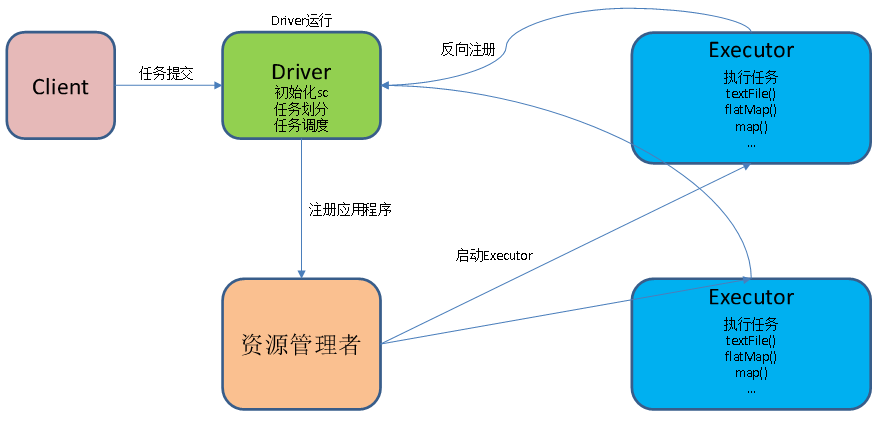
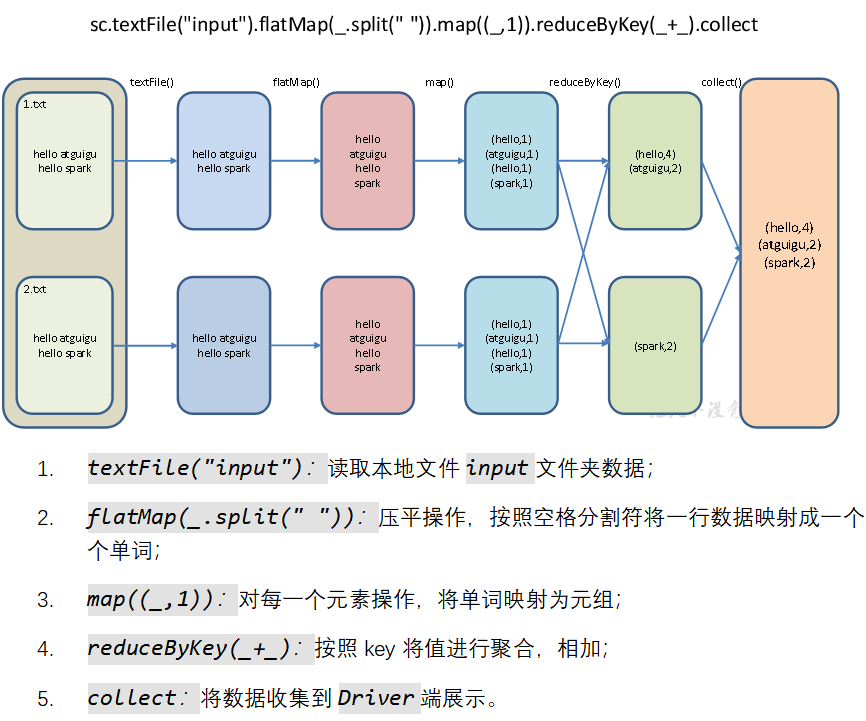
(3)数据流程
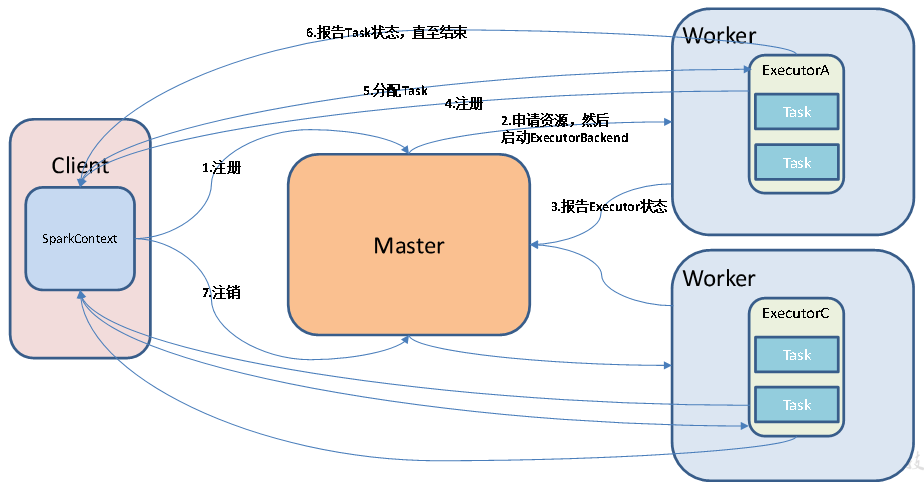
3、Standalone模式
(1)工作模式图解
由master管理
(2)配置
由 Master + Slave 构成的 Spark 集群
修改 slaves 文件,分发启动sbin/start-all.sh
查看集群运行情况:http://hadoop201:8080
运行计算程序bin/spark-submit
启动 Spark-shell:bin/spark-shell --master xxxx
(3)配置Spark任务历史服务器
spark-defaults.conf配置文件中,允许记录日志
spark-env.sh中配置历史服务器端口和日志在hdfs上的目录
分发配置,启动hdfs
启动历史服务器sbin/start-history-server.sh
启动任务并查看
(4)HA 配置(为 Mater 配置)
master单一,存在单点故障问题
方式:启动多个,包含active状态和standby状态
spark-env.sh添加zk配置,移除原有master
分发启动zk,启动全部节点sbin/start-all.sh
杀死master进程,在8080端口查看master的状态
重新启动sbin/start-master.sh
4、Yarn模式:客户端直接连接yarn,无需额外构建spark集群
(1)概述
client 和 cluster 两种模式,区别在于:Driver 程序的运行节点不同
cluster:Driver程序运行在由 RM(ResourceManager)启动的 AM(AplicationMaster)
由RM管理
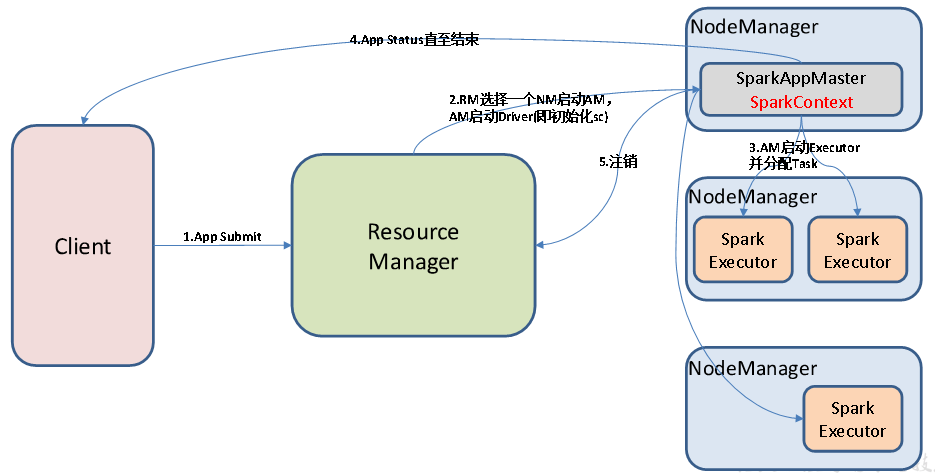
(2)Yarn模式配置
修改yarn-site.xml,避免杀死nm进程
修改spark-evn.sh,去掉 master 的 HA 配置
执行程序并在8088端口进行查看
在spark-default.conf中配置历史服务器
5、Mesos 模式:客户端直接连接 Mesos;不需要额外构建 Spark 集群
6、比较
|
模式 |
Spark安装机器数 |
需启动的进程 |
所属者 |
|
Local |
1 |
无 |
Spark |
|
Standalone |
多台 |
Master及Worker |
Spark |
|
Yarn |
1 |
Yarn及HDFS |
Hadoop |
三、WordCount案例实操
1、概述
利用 Maven 来管理 jar 包的依赖
2、步骤
创建 maven 项目, 导入依赖
编写 WordCount 程序(创建WordCount.scala)
3、测试
(1)打包到 Linux 测试
bin/spark-submit --class day01.WordCount --master yarn input/spark_test-1.0-SNAPSHOT.jar
查询结果
hadoop fs -cat /output/*
(2)idea 本地直接提交应用(使用local模式执行)
package day01
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
// 1. 创建 SparkConf对象, 并设置 App名字, 并设置为 local 模式
val conf: SparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]")
// 2. 创建SparkContext对象
val sc = new SparkContext(conf)
// 3. 使用sc创建RDD并执行相应的transformation和action
val wordAndCount: Array[(String, Int)] = sc.textFile(ClassLoader.getSystemResource("words.txt").getPath)
.flatMap(_.split(" "))
.map((_, 1))
.reduceByKey(_ + _)
.collect()
wordAndCount.foreach(println)
// 4. 关闭连接
sc.stop()
}
}
【Spark】Day01-入门、模块组成、4种运行模式详解及配置、案例实操(spark分析过程)的更多相关文章
- ST MCU_GPIO的八种工作模式详解。
补充: N.P型的区别,就是一个为正电压启动(NMOS),一个为负电压启动(PMOS) GPIO的八种工作模式详解 浮空输入_IN_FLOATING带上拉输入_IPU带下拉输入_IPD模拟输入_AIN ...
- Spark的 运行模式详解
Spark的运行模式是多种多样的,那么在这篇博客中谈一下Spark的运行模式 一:Spark On Local 此种模式下,我们只需要在安装Spark时不进行hadoop和Yarn的环境配置,只要将S ...
- Android Activity的4种启动模式详解(示例)
转载请注明出处:http://www.cnblogs.com/Joanna-Yan/p/5233269.html 先介绍下Android对Activity的管理,Android采用Task来管理多个A ...
- apache两种工作模式详解
prefork模式 这个多路处理模块(MPM)实现了一个非线程型的.预派生的web服务器,它的工作方式类似于Apache 1.3.它适合于没有线程安全库,需要避免线程兼容性问题的系统.它是要求将每个请 ...
- vmware虚拟机三种网络模式详解_转
原文来自http://note.youdao.com/share/web/file.html?id=236896997b6ffbaa8e0d92eacd13abbf&type=note 由于L ...
- Vmware虚拟机三种网络模式详解
原文来自http://note.youdao.com/share/web/file.html?id=236896997b6ffbaa8e0d92eacd13abbf&type=note 我怕链 ...
- 四、Vmware虚拟机三种网络模式详解
转载自: http://note.youdao.com/share/web/file.html?id=236896997b6ffbaa8e0d92eacd13abbf&type=note 1. ...
- 【转】VMware虚拟机三种网络模式详解
由于Linux目前很热门,越来越多的人在学习Linux,但是买一台服务放家里来学习,实在是很浪费.那么如何解决这个问题?虚拟机软件是很好的选择,常用的虚拟机软件有VMware Workstations ...
- Vmware虚拟机三种网络模式详解(转)
原文来自http://note.youdao.com/share/web/file.html?id=236896997b6ffbaa8e0d92eacd13abbf&type=note 我怕链 ...
- Vmware虚拟机三种网卡模式详解
由于Linux目前很热门,越来越多的人在学习linux,但是买一台服务放家里来学习,实在是很浪费.那么如何解决这个问题?虚拟机软件是很好的选择,常用的虚拟机软件有vmware workstations ...
随机推荐
- Redis 监控指标
监控指标 性能指标:Performance 内存指标: Memory 基本活动指标:Basic activity 持久性指标: Persistence 错误指标:Error 性能指标:Performa ...
- Elasticsearch中的一些重要概念:cluster, node, index, document, shards及replica
首先,我们来看下一下如下的这个图: Cluster Cluster也就是集群的意思.Elasticsearch集群由一个或多个节点组成,可通过其集群名称进行标识.通常这个Cluster 的名字是可以在 ...
- spring cron表达式源码分析
spring cron表达式源码分析 在springboot中,我们一般是通过如下的做法添加一个定时任务 上面的new CronTrigger("0 * * * * *")中的参数 ...
- 研一入坑Go 文件操作
1 package main 2 3 import ( 4 "fmt" 5 "os" 6 "path" 7 "path/filep ...
- 齐博x1云市场注意事项
安装云市场应用注意事项 大到频道,小到插件甚至钩子及风格都可以在线安装,在线升级. 但是有一个大家务必注意的地方,就是重装系统后,再安装有可能导致重复收费. 这个问题是可以解决的.当然如果不是重装系统 ...
- 齐博x1内容页中下一页上一页的标签
在模板中分别插入如下代码即可 前一页 {:fun('content@prev',$info,20)} 后一页 {:fun('content@next',$info,20)} 复制 其中20代表取标题多 ...
- Sentinel 介绍与下载使用
sentinel 前方参考 计算QPS-Sentinel限流算法 https://www.cnblogs.com/yizhiamumu/p/16819497.html Sentinel 介绍与下载使用 ...
- 《HelloGitHub》第 79 期
兴趣是最好的老师,HelloGitHub 让你对编程感兴趣! 简介 HelloGitHub 分享 GitHub 上有趣.入门级的开源项目. https://github.com/521xueweiha ...
- pta第一次博客
目录 pta第一次博客 1.前言 2.设计与分析 第二次作业第二题 第三次作业第一题 第三次作业第二题 第三次作业第三题 3.踩坑心得: 4.改进建议 5.总结 pta第一次博客 1.前言 这三次pt ...
- 十五、资源控制之Deployment
资源控制器之Deployment Deployment 为 Pod 和 ReplicaSet 提供了一个声明式定义(declarative)方法,用来替代以前的ReplicationControlle ...