局部异常因子(Local Outlier Factor, LOF)算法详解及实验
局部异常因子(Local Outlier Factor, LOF)通过计算样本点的局部相对密度来衡量这个样本点的异常情况,可以算是一类无监督学习算法。下面首先对算法的进行介绍,然后进行实验。
LOF算法
下面介绍LOF算法的每个概念,以样本点集合中的样本点$P$为例。下面的概念名称中都加了一个k-,实际上部分名称原文没有加,但是感觉这样更严谨一些。
k-邻近距离(k-distance):样本点$P$与其最近的第$k$个样本点之间的距离,表示为$d_k(P)$。其中距离可以用各种方式度量,通常使用欧氏距离。
k-距离邻域:以$P$为圆心,$d_k(P)$为半径的邻域,表示为$N_k(P)$。
k-可达距离:$P$到某个样本点$O$的k-可达距离,取$d_k(O)$或$P$与$O$之间距离的较大值,表示为
$reach\_dist_k(P,O)=\max\{d_k(O),d(P,O)\}$
也就是说,如果$P$在$N_k(O)$内部,$reach\_dist_k(P,O)$取$O$的k-邻近距离$d_k(O)$,在$N_k(O)$外部则取$P$与$O$之间距离$d(P,O)$。需要注意k-可达距离不是对称的。
k-局部可达密度(local reachability density, lrd):$P$的k-局部可达密度表示为
$\displaystyle lrd_k(P)=\left(\frac{\sum\limits_{O\in N_k(P)}reach\_dist_k(P,O)}{|N_k(P)|}\right)^{-1}$
括号内,分子计算了$P$到其k-距离邻域内所有样本点$O$的k-可达距离之和,然后除以$P$的k-距离邻域内部的样本点个数进行平均。再加一个倒数,表示为密度,即$P$到每个点的平均距离越小,密度越大。可以推理出,如果$P$在所有$O$的k-邻域内部,其局部可达密度即为
$\displaystyle lrd_k(P)=\left(\frac{\sum\limits_{O\in N_k(P)}d_k(O)}{|N_k(P)|}\right)^{-1}$
可以看出,如果$P$是一个离群点,那么它不太可能存在于$N_k(P)$中各点的k-距离邻域内,从而导致其局部可达密度偏小;如果$P$不是离群点,其局部可达密度最大取为上式。
实际上我有点奇怪为什么要用一个最大值来将距离作一个限制,也就是使用k-可达距离,而不是直接使用距离,即定义局部密度为下式
$\displaystyle ld_k(P)=\left(\frac{\sum\limits_{O\in N_k(P)}d(O,P)}{|N_k(P)|}\right)^{-1}$
k-局部异常因子(Local Outlier Factor, LOF):$P$的k-局部异常因子表示为
$\displaystyle LOF_k(P)=\frac{\frac{1}{|N_k(P)|}\sum\limits_{O\in N_k(P)}lrd_k(O)}{lrd_k(P)}$
从直觉上理解:当$LOF_k(P)\le1$时,表明$P$处密度比其周围点大或相当,则$P$是内点;当$LOF_k(P)>1$时,表明$P$处密度比其周围点小,可以判别为离群(异常)点。
实验
LOF算法实现
实验设置样本维度为2以便可视化。由于样本点只包含连续值,实验默认设置$|N_k(P)|=k$。设置$k=5$,并将阈值设为1.2,即将LOF大于1.2的样本点视作异常。函数定义、抽样、计算以及可视化代码如下。
#%% 定义函数
import torch
import matplotlib.pyplot as plt #计算所有样本点[N, M]之间的距离,得到[N, N]
def get_dists(points:torch.Tensor):
x = torch.sum(points**2, 1).reshape(-1, 1)
y = torch.sum(points**2, 1).reshape(1, -1)
dists = x + y - 2 * torch.mm(points, points.permute(1,0))
#数值计算问题,防止对角线小于0
dists = dists - torch.diag_embed(torch.diag(dists))
return torch.sqrt(dists) #计算所有样本点到其k-邻域点的k-可达距离
def get_LOFs(dists:torch.Tensor, k):
#距离排序,获取所有样本点的k-临近距离
sorted_dists, sorted_inds = torch.sort(dists, 1, descending=False)
k_dists = sorted_dists[:, k]
neighbor_inds = sorted_inds[:, 1:k+1].reshape(-1)
neighbor_k_dists = k_dists[neighbor_inds].reshape(-1, k)
neighbor_k_reach_dists = torch.max(neighbor_k_dists, dists[:, 1:k+1])
lrds = (neighbor_k_reach_dists.sum(1)/k)**-1
neighbor_lrds = lrds[neighbor_inds].reshape(-1, k)
LOFs = neighbor_lrds.sum(1)/k/lrds
return LOFs #%% 随机生成聚集点和异常点
from torch.distributions import MultivariateNormal
torch.manual_seed(0) crowd_mu_covs = [
[[0.0, 0.0], [[1.0, 0.0], [0.0, 2.0]], 10],
[[-10.0, -1.0], [[2.0, 0.8], [0.8, 2.0]], 10],
[[-10.0, -20.0], [[5.0, -2], [-2, 3.0]], 50],
[[5.0, -10.0], [[5.0, -2], [-2, 3.0]], 50],
[[-3.0, -10.0], [[5.0, -2], [-2, 3.0]], 50],
[[-13.0, -10.0], [[0.3, -0.1], [-0.1, 0.5]], 10],
[[-4.0, -10.0], [[0.3, -0.1], [-0.1, 0.1]], 100],
]#正态分布点的均值和方差
outliers = [[5, 5.], [3, 4], [5, -3], [4, -30], [-2, -35], [-10, -35]] #异常点 points = []
for i in crowd_mu_covs:
mu = torch.tensor(i[0])
cov = torch.tensor(i[1])
ps = MultivariateNormal(mu, cov).sample([i[2]]).to('cuda')
points.append(ps)
for o in outliers:
points.append(torch.tensor([o]).to('cuda'))
points = torch.cat(points) #%% 计算LOFs并可视化可视化
k, threshold = 5, 1.2
dists = get_dists(points)
LOFs = get_LOFs(dists, k)
for i, p in enumerate(points.cpu().numpy()):
shape, color = '.', 'black'
if len(points) - i <= len(outliers):
shape = '^'
plt.annotate("%.2f"%LOFs[i].cpu().numpy(), (p[0], p[1]))
if LOFs[i] > threshold:
color = 'red'
plt.annotate("%.2f"%LOFs[i].cpu().numpy(), (p[0], p[1]), color='blue')
plt.plot(p[0], p[1], shape, color=color)
plt.show()
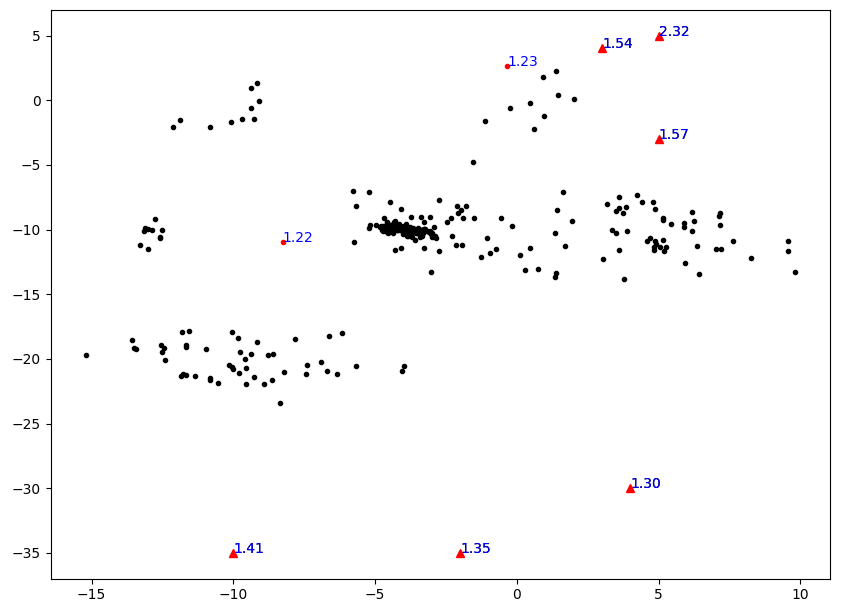
实验可视化结果如下图所示,其中红色点表示被标为异常的点,三角点表示实验设置的真实异常点。可以看出LOF的确能有效将异常离群点找出。但是,发现下面三个人眼看来非常离群的点的LOF值还不到1.5,比上面异常点的LOF低得多,这说明算法还有些不合理之处。
距离代替局部可达距离
根据前面的疑问,用距离代替局部可达距离进行相应实验。仅在get_LOFs函数处做了相关改动,并将阈值threshold改为2。代码如下。
#%% 定义函数
import torch
import matplotlib.pyplot as plt #计算所有样本点[N, M]之间的距离,得到[N, N]
def get_dists(points:torch.Tensor):
x = torch.sum(points**2, 1).reshape(-1, 1)
y = torch.sum(points**2, 1).reshape(1, -1)
dists = x + y - 2 * torch.mm(points, points.permute(1,0))
#数值计算问题,防止对角线小于0
dists = dists - torch.diag_embed(torch.diag(dists))
return torch.sqrt(dists) #计算所有样本点到其k-邻域点的k-可达距离
def get_LOFs(dists:torch.Tensor, k):
#距离排序,获取所有样本点的k-临近距离
sorted_dists, sorted_inds = torch.sort(dists, 1, descending=False)
densities = (sorted_dists[:, 1:k+1].sum(1)/k)**-1
neighbor_inds = sorted_inds[:, 1:k+1].reshape(-1)
neighbor_densities = densities[neighbor_inds].reshape(-1, k)
LOFs = neighbor_densities.sum(1)/k/densities
return LOFs #%% 随机生成聚集点和异常点
from torch.distributions import MultivariateNormal
torch.manual_seed(0) crowd_mu_covs = [
[[0.0, 0.0], [[1.0, 0.0], [0.0, 2.0]], 10],
[[-10.0, -1.0], [[2.0, 0.8], [0.8, 2.0]], 10],
[[-10.0, -20.0], [[5.0, -2], [-2, 3.0]], 50],
[[5.0, -10.0], [[5.0, -2], [-2, 3.0]], 50],
[[-3.0, -10.0], [[5.0, -2], [-2, 3.0]], 50],
[[-13.0, -10.0], [[0.3, -0.1], [-0.1, 0.5]], 10],
[[-4.0, -10.0], [[0.3, -0.1], [-0.1, 0.1]], 100],
]#正态分布点的均值和方差
outliers = [[5, 5.], [3, 4], [5, -3], [4, -30], [-2, -35], [-10, -35]] #异常点 points = []
for i in crowd_mu_covs:
mu = torch.tensor(i[0])
cov = torch.tensor(i[1])
ps = MultivariateNormal(mu, cov).sample([i[2]]).to('cuda')
points.append(ps)
for o in outliers:
points.append(torch.tensor([o]).to('cuda'))
points = torch.cat(points) #%% 计算LOFs并可视化可视化
k, threshold = 5, 2
dists = get_dists(points)
LOFs = get_LOFs(dists, k)
for i, p in enumerate(points.cpu().numpy()):
shape, color = '.', 'black'
if len(points) - i <= len(outliers):
shape = '^'
plt.annotate("%.2f"%LOFs[i].cpu().numpy(), (p[0], p[1]))
if LOFs[i] > threshold:
color = 'red'
plt.annotate("%.2f"%LOFs[i].cpu().numpy(), (p[0], p[1]), color='blue')
plt.plot(p[0], p[1], shape, color=color)
plt.show()
可视化结果如下图所示。
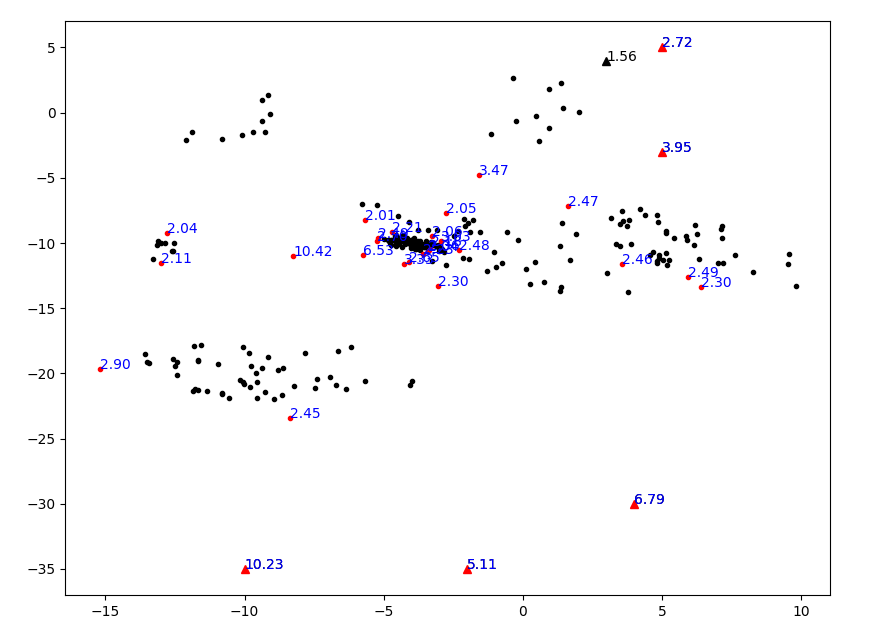
部分离群点的确能被有效找出,但是看起来似乎这个算法对“相对”的概念太显著了,导致一个聚集的点群里面也有很多不是那么聚集的点被划分为离群点。看来用距离代替局部可达距离是不行的。但是如何从理论上来解释,本文不再作深究,欢迎前来讨论。
局部异常因子(Local Outlier Factor, LOF)算法详解及实验的更多相关文章
- 异常检测——局部异常因子(Local Outlier Factor ,LOF)算法
在中等高维数据集上执行异常值检测的另一种有效方法是使用局部异常因子(Local Outlier Factor ,LOF)算法.1.算法思想 LOF通过计算一个数值score来反映一个样本的异常程度.这 ...
- 机器学习经典算法详解及Python实现--基于SMO的SVM分类器
原文:http://blog.csdn.net/suipingsp/article/details/41645779 支持向量机基本上是最好的有监督学习算法,因其英文名为support vector ...
- EM算法详解
EM算法详解 1 极大似然估计 假设有如图1的X所示的抽取的n个学生某门课程的成绩,又知学生的成绩符合高斯分布f(x|μ,σ2),求学生的成绩最符合哪种高斯分布,即μ和σ2最优值是什么? 图1 学生成 ...
- 安全体系(二)——RSA算法详解
本文主要讲述RSA算法使用的基本数学知识.秘钥的计算过程以及加密和解密的过程. 安全体系(零)—— 加解密算法.消息摘要.消息认证技术.数字签名与公钥证书 安全体系(一)—— DES算法详解 1.概述 ...
- 【目标检测】Faster RCNN算法详解
Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with region proposal network ...
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
- kmp算法详解
转自:http://blog.csdn.net/ddupd/article/details/19899263 KMP算法详解 KMP算法简介: KMP算法是一种高效的字符串匹配算法,关于字符串匹配最简 ...
- [转] KMP算法详解
转载自:http://www.matrix67.com/blog/archives/115 KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的K ...
- 【转】AC算法详解
原文转自:http://blog.csdn.net/joylnwang/article/details/6793192 AC算法是Alfred V.Aho(<编译原理>(龙书)的作者),和 ...
- KMP算法详解(转自中学生OI写的。。ORZ!)
KMP算法详解 如果机房马上要关门了,或者你急着要和MM约会,请直接跳到第六个自然段. 我们这里说的KMP不是拿来放电影的(虽然我很喜欢这个软件),而是一种算法.KMP算法是拿来处理字符串匹配的.换句 ...
随机推荐
- 使用vue3在element plus中在el-table中拖拽
1.安装 vuedraggable npm i -S vuedraggable 2.在使用的组件,引入.sortablejs包含在vuedraggable import Sortable from & ...
- css实现图片在div中居中的效果
利用图片的margin属性将图片水平居中,利用div的padding属性将图片垂直居中. 结构代码同上: css代码如下: div {width:300px; height:150px; paddin ...
- iOS界面横屏竖屏随意切换
转https://www.jianshu.com/p/ea1682e80003 先讲需求: APP中所有界面支持竖屏,只有在一个界面,点击一个btn之后变成横屏,再点就是竖屏.在网上找了一些方法,发现 ...
- Jmeter一、开源软件的崛起
一.jmeter自身特点: 1.开源,轻量级,更适合自动化和持续集成. 2.学习难度大. 3.资料少.多英文. 二.性能测试工具选型的原则 1.成本: a.工具成本 b.学习成本 2.通信协议: a. ...
- 在 Linux 上使用《算法》第4版官网中的 algs4.jar 包
使用<算法>第4版( Algorithms Fourth Edition ) 中的 algs4.jar 包 下载 algs4.jar 官网网址: https://algs4.cs.prin ...
- 贪心算法_Leetcode刷题_7/100
贪心算法 采用贪心策略,保证每次操作是局部最优的,从而使随后结果是全局最优的. 455.分配饼干 贪心策略:尽量把最小的饼干分配给胃口最小的孩子. 我的代码: 算法描述: 将孩子的胃口值g和拥有的饼干 ...
- 线程池使用、countDownLatch、以及数据库批量插入 添加配置优化插入与计算
//新建线程池ThreadPoolExecutor cpuThreadPoolExecutor = ThreadUtil.getCpuThreadPoolExecutor(); //使用Countdo ...
- jetson TX2 + opencv3.4 + python3 + 双目 +人脸检测
淘宝看到一款很便宜的双目,150元,就买了.想着用它学习一下opencv,好换个工作.当然,也想着能否用它做一些好玩的,比如三维重建之类高大上的东西.先用便宜的入个门,等以后眼界高了再看是不是买那些更 ...
- Android Native Code 手动调试
调试启动过程中的 Android Native Code Crash 记录一下,最后成功使用的工具是 lldb + lldb-server,不需要 root 权限.我最先尝试使用的是,gdb + gd ...
- git push错误failed to push some refs to的解决
问题说明 当我们在github版本库中发现一个问题后,你在github上对它进行了在线的修改:或者你直接在github上的某个库中添加readme文件或者其他什么文件,但是没有对本地库进行同步.这个时 ...