Elasticsearch:跨集群搜索 Cross-cluster search (CCS)
转载自:https://blog.csdn.net/UbuntuTouch/article/details/104588232
跨集群搜索(cross-cluster search)使您可以针对一个或多个远程集群运行单个搜索请求。 例如,您可以使用跨集群搜索来筛选和分析存储在不同数据中心的集群中的日志数据。

如上面所述,当我们的client向集群cluster_1发送请求时,它可以搜索自己本身的集群,同时也可以向另外的两个集群cluster_2及cluster_3发送请求。最后的结果由cluster_1返回给客户端。

目前支持的APIs:
- Search
- Multi search
- Search template
- Multi search template
跨集群搜索例子
注册remote cluster
要执行跨集群搜索,必须至少配置一个远程集群。在集群设置中配置了远程群集
- 使用cluster.remote属性
- 种子(seeds)是远程集群中的节点列表,用于在注册远程集群时检索集群状态
以下cluster update settings API请求添加了三个远程集群:cluster_one,cluster_two和cluster_three。
PUT _cluster/settings
{
"persistent": {
"cluster": {
"remote": {
"cluster_one": {
"seeds": [
"127.0.0.1:9300"
]
},
"cluster_two": {
"seeds": [
"127.0.0.1:9301"
]
},
"cluster_three": {
"seeds": [
"127.0.0.1:9302"
]
}
}
}
}
}
动手实践
安装集群
在今天的实践中,我们来设置两个集群:

在上面的描述中,我们配置了两个集群:cluster 1及cluster 2。它们位于同一个网路内,可以互相访问。在安装时,我们必须注意的是:
- 把我们的Elasticsearch及Kibana分别解压,并安装于不同的两个目录中。这样它们的安装互相不干扰,从而能形成两个不同的集群,虽然它们集群的名字可以是一样的。为了方便,我们把两个集群的名字分别取为cluster_1及cluster_2。
- 我们可以分别对Elasticsearch的配置文件config/elasticsearch.yml做如上的配置。同时我们也需要对Kibana之中的config/kibana.yml做配置,这样使得cluster_1对应的Kibana的口地址为5601,而对于cluster_2的Kibana的口地址为5602。
在上面可能有很多人感到疑问:为啥我们还需要配置端口地址9300及9301?事实上,Elasticsearch中有两种重要的网络通信机制需要了解:
- HTTP:用于HTTP通信绑定的地址和端口,这是Elasticsearch REST API公开的方式
- transport:用于集群内节点之间的内部通信

等我们安装好我们的两个集群我们可以通过如下的方法来查看:
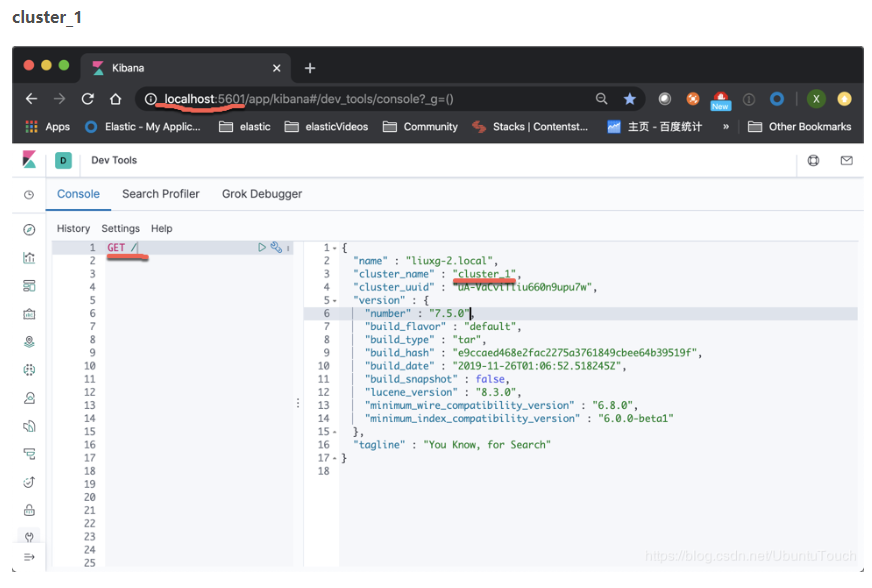
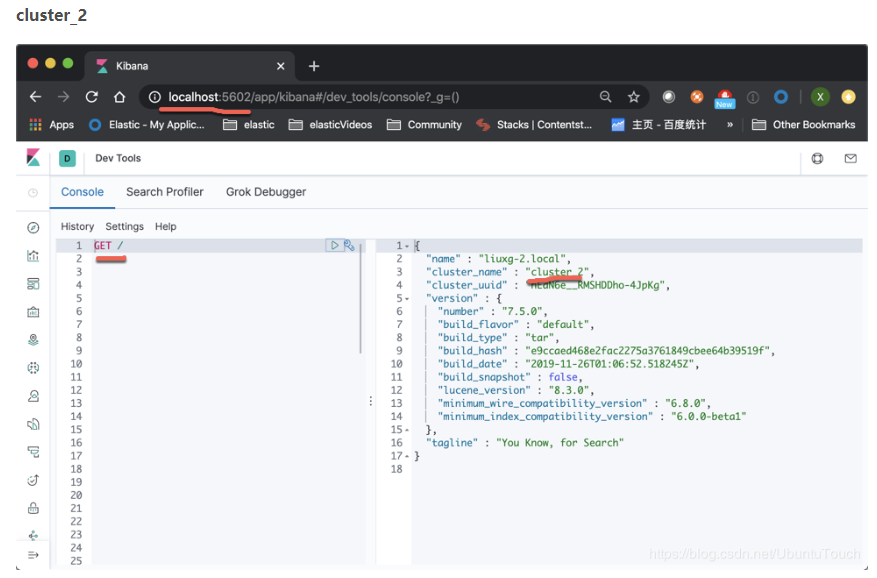
如果我们能够同时看到上面的两个集群的画面,则表明我们的集群已经设置正确。
搜索
我们接下来进行配置。我们在kibana_2,也既是端口地址为5602的Kibana。我们打入如下的命令:
PUT _cluster/settings
{
"persistent": {
"cluster.remote": {
"remote_cluster": {
"seeds": [
"127.0.0.1:9300"
]
}
}
}
}
在上面,我们在cluster_2里配置可以连接到cluster_1的这样设置。因为cluster_1的transport口地址是9300。
我们可以看到如下的返回信息:
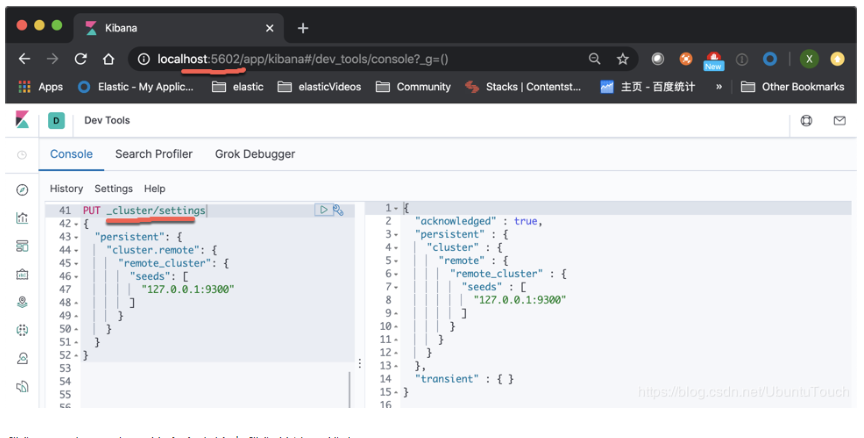
我们接下来使用如下的命令来检查我们的连接状态:
GET _remote/info
我们可以看到如下的响应信息:
{
"remote_cluster" : {
"seeds" : [
"127.0.0.1:9300"
],
"connected" : true,
"num_nodes_connected" : 1,
"max_connections_per_cluster" : 3,
"initial_connect_timeout" : "30s",
"skip_unavailable" : false
}
}
它表明我们的连接是成功的。
这个时候我们在Kibana_1中创建如下的twitter索引:
POST _bulk
{"index":{"_index":"twitter","_id":1}}
{"user":"张三","message":"今儿天气不错啊,出去转转去","uid":2,"age":20,"city":"北京","province":"北京","country":"中国","address":"中国北京市海淀区","location":{"lat":"39.970718","lon":"116.325747"}, "DOB": "1999-04-01"}
{"index":{"_index":"twitter","_id":2}}
{"user":"老刘","message":"出发,下一站云南!","uid":3,"age":22,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区台基厂三条3号","location":{"lat":"39.904313","lon":"116.412754"}, "DOB": "1997-04-01"}
{"index":{"_index":"twitter","_id":3}}
{"user":"李四","message":"happy birthday!","uid":4,"age":25,"city":"北京","province":"北京","country":"中国","address":"中国北京市东城区","location":{"lat":"39.893801","lon":"116.408986"}, "DOB": "1994-04-01"}
{"index":{"_index":"twitter","_id":4}}
{"user":"老贾","message":"123,gogogo","uid":5,"age":30,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区建国门","location":{"lat":"39.718256","lon":"116.367910"}, "DOB": "1989-04-01"}
{"index":{"_index":"twitter","_id":5}}
{"user":"老王","message":"Happy BirthDay My Friend!","uid":6,"age":26,"city":"北京","province":"北京","country":"中国","address":"中国北京市朝阳区国贸","location":{"lat":"39.918256","lon":"116.467910"}, "DOB": "1993-04-01"}
{"index":{"_index":"twitter","_id":6}}
{"user":"老吴","message":"好友来了都今天我生日,好友来了,什么 birthday happy 就成!","uid":7,"age":28,"city":"上海","province":"上海","country":"中国","address":"中国上海市闵行区","location":{"lat":"31.175927","lon":"121.383328"}, "DOB": "1991-04-01"}
我们可以在Kibana_1中通过如下的命令来检查twitter索引是否已经被成功创建:
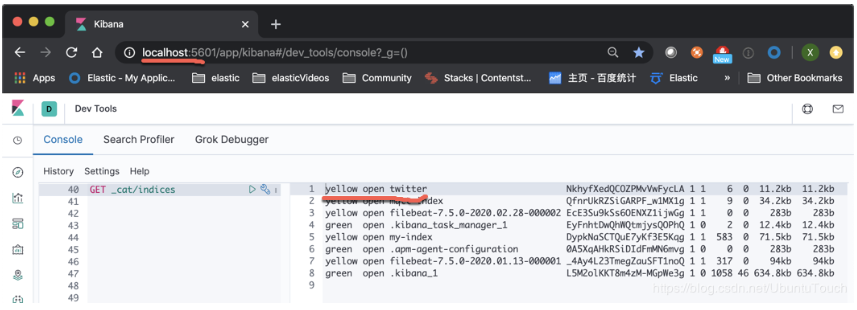
在上面,我们可以看到我们已经成功地在cluster_1上创建了twitter索引,那么我们怎么在cluster_2上对这个进行搜索呢?
我们在Kibana_2里,打入如下的命令:
GET remote_cluster:twitter/_search
我们将看到如下的输出:
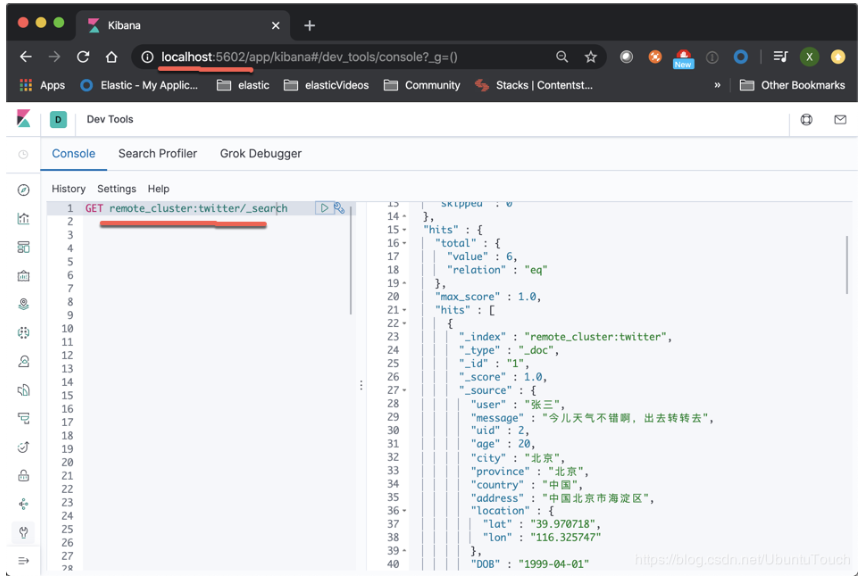
从上面我们可以看出来,我们可以对位于cluster_1的twitter索引进行搜索。
对remote索引进行分析
cluster_1
在Kibana_1中,我们通过如下的方法来加载我们的测试数据:
然后点击“Add data”:
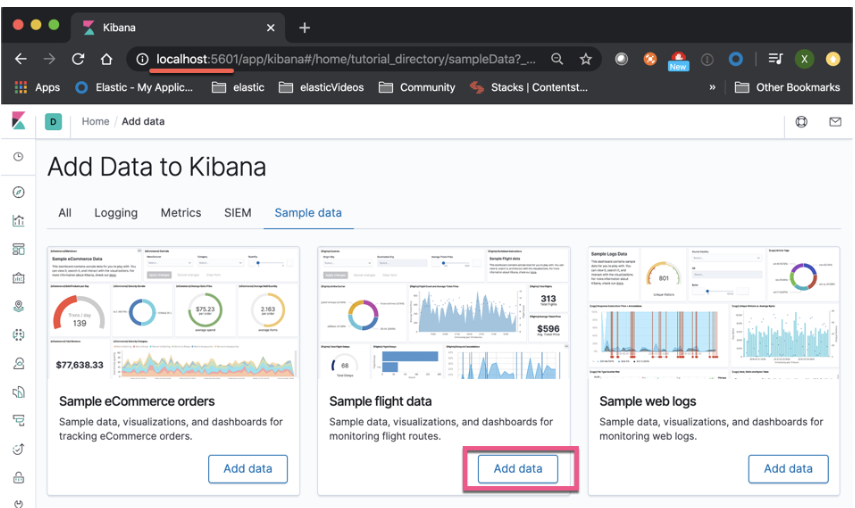
这样在cluster_1中,我们已经成功地加载了Sample flight data索引。
cluster_2
我们打开Kibana_2,并创建一个为cluster_1中的Sample flight data的index pattern
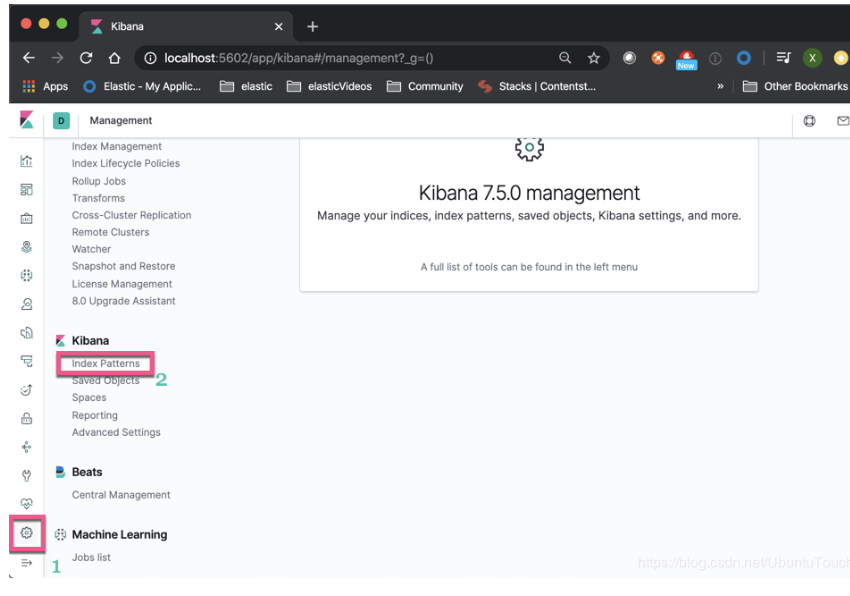
点击“Create index pattern”:
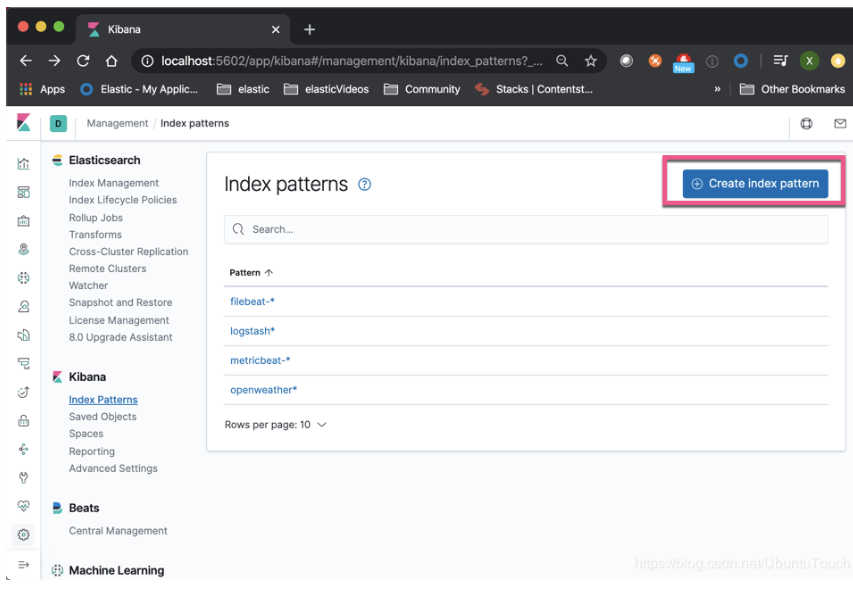
输入我们想要的索引。注意在前面加上remote_cluster:
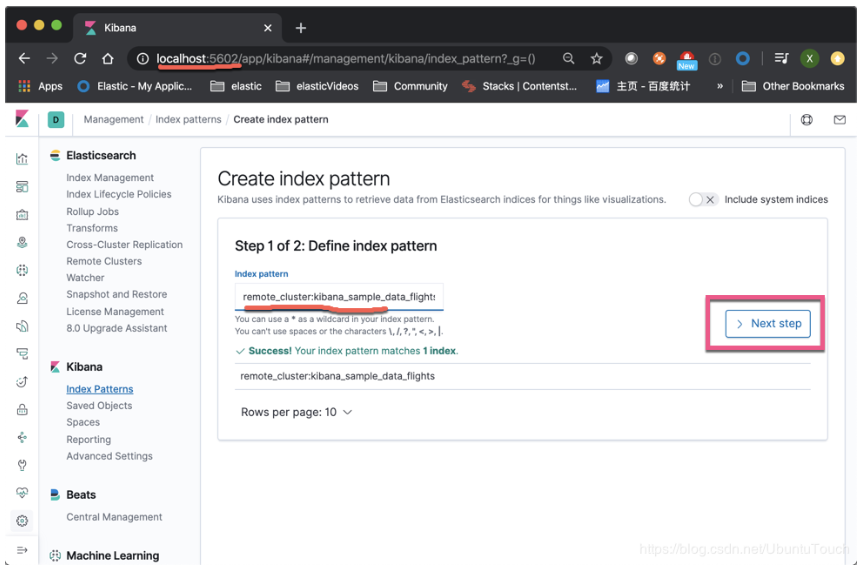
在上面,如果我们有本地和远程相同类型的索引(比如,我们针对不同地区的服务器来收集数据),我们可以使用逗号“,”把所有的索引放在一起做成一个index pattern,比如就像:remote_cluster:kibana_sample_data_flights, my_local_index。

点击“Create index pattern”:

这样,我们就创建了位于cluster_1里的索引的一个index pattern。我们点击右上角的星号,并使之成为我们的默认的index。
我们点击Kibana_2左上角的Discover:
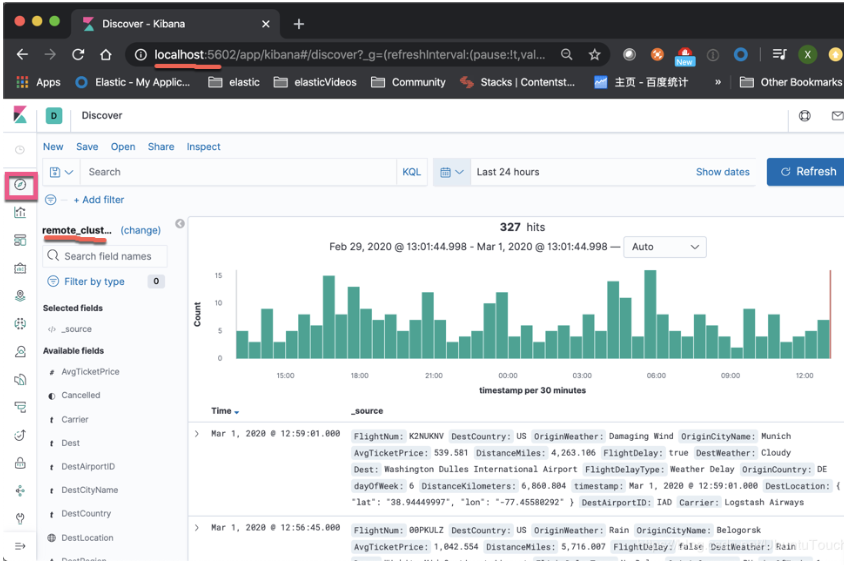
因为我们的默认的index是remote_cluster:kibana_sample_data_flights,所以我们的Discover默认的情况先显示的是所有关于位于cluster_1上的kibana_sample_data_flights索引数据。我们可以在cluster_2对这些数据进行分析。
Elasticsearch:跨集群搜索 Cross-cluster search (CCS)的更多相关文章
- Elasticsearch跨集群搜索(Cross Cluster Search)
1.简介 Elasticsearch在5.3版本中引入了Cross Cluster Search(CCS 跨集群搜索)功能,用来替换掉要被废弃的Tribe Node.类似Tribe Node,Cros ...
- Elasticsearch 搜索模块之Cross Cluster Search(跨集群搜索)
Cross Cluster Search简介 cross-cluster search功能允许任何节点作为跨多个群集的federated client(联合客户端),与tribe node不同的是cr ...
- elasticsearch跨集群数据迁移
写这篇文章,主要是目前公司要把ES从2.4.1升级到最新版本7.8,不过现在是7.9了,官方的文档:https://www.elastic.co/guide/en/elasticsearch/refe ...
- Elasticsearch:跨集群搜索 Cross-cluster search(CCS)及安全
文章转载自:https://elasticstack.blog.csdn.net/article/details/116569527
- ES cross cluster search跨集群查询
ES 5.3以后出的新功能.测试demo如下: 下载ES 5.5版本,然后分别本机创建2个实例,配置如下: cluster.name: xx1 network.host: 127.0.0.1 http ...
- 分布式搜索ElasticSearch构建集群与简单搜索实例应用
分布式搜索ElasticSearch构建集群与简单搜索实例应用 关于ElasticSearch不介绍了,直接说应用. 分布式ElasticSearch集群构建的方法. 1.通过在程序中创建一个嵌入es ...
- Elasticsearch 主从同步之跨集群复制
文章转载自:https://mp.weixin.qq.com/s/alHHxXont6XFm_m9PfsGfw 1.什么是跨集群复制? 跨集群复制(Cross-cluster replication, ...
- PB级数据实时查询,滴滴Elasticsearch多集群架构实践
PB级数据实时查询,滴滴Elasticsearch多集群架构实践 mp.weixin.qq.com 点击上方"IT牧场",选择"设为星标"技术干货每日送达 点 ...
- Elastic Stack之ElasticSearch分布式集群yum方式搭建
Elastic Stack之ElasticSearch分布式集群yum方式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.搜索引擎及Lucene基本概念 1>.什么 ...
随机推荐
- Windows安装face_recognition
安装提供的python和cmake,最好都添加一下环境变量 安装dlib,pip install dlib-19.7.0-cp36-cp36m-win_amd64.whl 安装face_recogni ...
- windows配置skywalking集群
一.zookeeper 准备配置三个zookeeper,因为我是单台模拟,所以需要使用不同的端口,使用版本是apache-zookeeper-3.6.3-bin (必须是3.5+) 1.第1个zook ...
- C#金额数字转换中文繁体
/// <summary> /// 数字转换中文繁体金钱 /// </summary> /// <param name="Digital">&l ...
- 【有用的SQL】查Greenplum的数据字典
Greenplum 查询哪个表的分布键 ( Greenplum ) SELECT att.nspname AS 模式名 , att.relname AS 表名 , table_comment AS 表 ...
- Winsock Client Code
以下代码来自MSDN:https://msdn.microsoft.com/en-us/library/windows/desktop/ms737591(v=vs.85).aspx #define W ...
- 部署yum仓库
YUM介绍 YUM(全称为 Yellow dog Updater, Modified)是一个在Fedora和RedHat以及CentOS中的Shell前端软件包管理器. 基于RPM包管理,能够从指定的 ...
- 启动docker报错Failed to listen on Docker Socket for the API.
1.启动时报错查看日志发现 # journalctl -xe Failed to listen on Docker Socket for the API. 查找socket这个配置文件,修改如下 # ...
- HBase学习(二) 基本命令 Java api
一.Hbase shell 1.Region信息观察 创建表指定命名空间 在创建表的时候可以选择创建到bigdata17这个namespace中,如何实现呢? 使用这种格式即可:'命名空间名称:表名' ...
- golang拾遗:自定义类型和方法集
golang拾遗主要是用来记录一些遗忘了的.平时从没注意过的golang相关知识. 很久没更新了,我们先以一个谜题开头练练手: package main import ( "encoding ...
- NOI / 1.4编程基础之逻辑表达式与条件分支讲解-01:判断数正负
总时间限制: 1000ms 内存限制: 65536kB 题目: 描述 给定一个整数N,判断其正负. 输入 一个整数N(-109 <= N <= 109) 输出 如果N > 0, 输出 ...