Streamlit:快速数据可视化界面工具
目录
Streamlit简介
Streamlit是一个基于Python的可视化工具,和其他可视化工具不同的是,它生成的是一个可交互的站点(页面)。但同时它又不是我们常接触的类似Django、Flask这样的WEB框架。当前使用下来的感受:
缺点:
- 自带服务器,且需要从命令行启动服务方能查看页面,不能通过直接运行Python代码的方式启动应用。即不能集成到其他系统及框架中
- 当前只支持单页面,不能通过URL传参等方式生成多页面。Github有人提了Issues,但是目前还没支持,部分人给了一些临时的Hack
- 目前不支持登录验证,且由于自带服务器的原因,很难集成其他第三方的登录验证等,不能做很好的数据权限控制
优点:
- 无需编写任何HTML、CSS或JS代码就可以生成界面不错的页面
整体评价:优势明显,定位于只熟悉Python代码的算法人员。虽然目前的功能比较简陋,问题较多,但随着不断的开发,相信功能也会也来越强大。
Streamlit带来的改变
原先的数据展示页面开发流程:
- 在Jupyter中开发演示
- 将Python代码复制到文件
- 编写Flask应用,包括考虑HTTP请求、HTML代码、JS和回调等

而当展示页面非常重要时,通常的流程是这样的:
- 收集用户需求
- 定义展示框架与原型
- 使用HTML、CSS、Python、React、Javascript等进行编码
- 一个月以后才能看到最终的页面
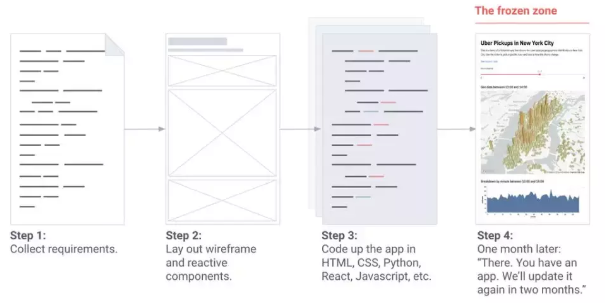
Streamlit的流程:
- 稍微改下Python代码即可生成展示界面

而能够快速生成应用,主要原因是Streamlit兼容以下Python库或框架:
- 数据处理:Numpy、Pandas
- 机器学习框架或库:Scilit-Learn、TensorFlow、Keras、PyTorch
- 数据可视化工具:matplotlib、seaborn、poltly、boken、Altair、GL、Vega-Lite
- 文本处理:Markdown、LaTeX
Streamlit使用指南
上面介绍的感觉有些摸不着头脑,接下来直接用代码来演示。
常用命令
显示文本
展现内容如下:
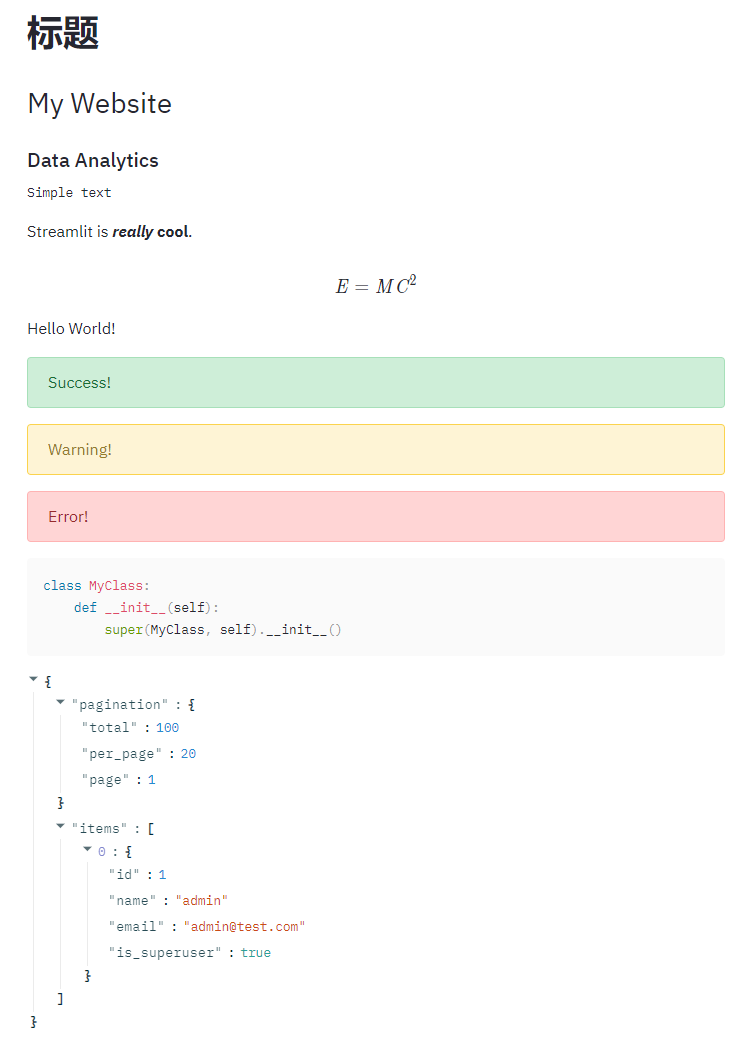
从上面可以看到,Streamlit可以非常方便的相似不同层级的title(目前只支持3种,类似H1~H3),同时支持文本、LaTeX、Markdown、Code和JSON、Emoji的输出。也支持信息的反馈的支持(成功、警告、错误)。
另外st.write()支持各种类型的数据:
- write(string):显示字符串或Markdown 字符串,同时支持LaTeX、emoji shortcodes
- write(data_frame) : 显示DataFrame表格
- write(error) : 显示错误信息
- write(func) : 显示function信息
- write(module) : 显示module的信息
- write(dict) : Displays dict in an interactive widget.
- write(obj) : 打印字符串对象
- write(mpl_fig) : 显示Matplotlib图片
- write(altair) : 显示Altair图表
- write(keras) : 显示Keras模型
- write(graphviz) : 显示Graphviz图片
- write(plotly_fig) : 显示Plotly图片
- write(bokeh_fig) : 显示Bokeh图片
- write(sympy_expr) : 使用LaTeX 显示SymPy语法
显示数据
显示内容:
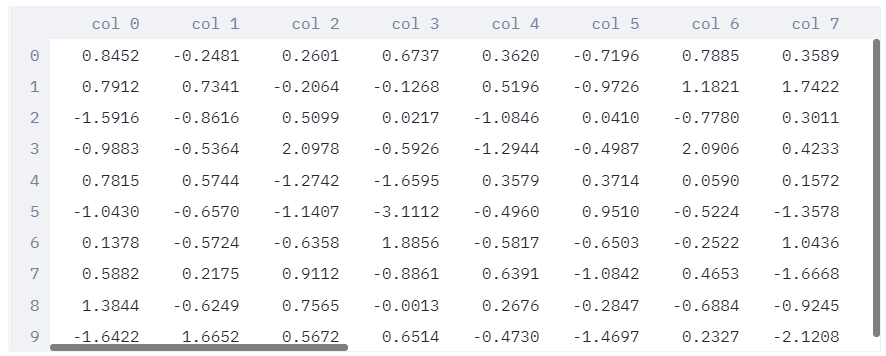
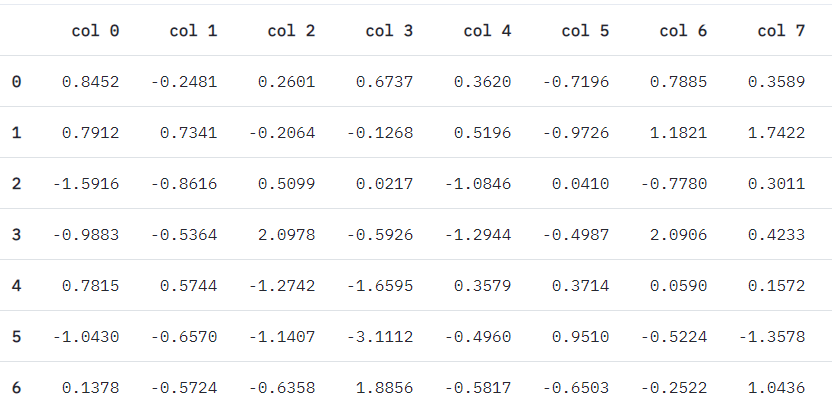
可以看到,使用st.dataframe(df)相比st.table(df)界面要好看些。
显示图表
可以看到这里支持目前市面上的各种图表的Python库。
显示媒体
这里的媒体包括:图片、音频、视频。
这里不详细介绍,具体可以见官方文档
交互组件
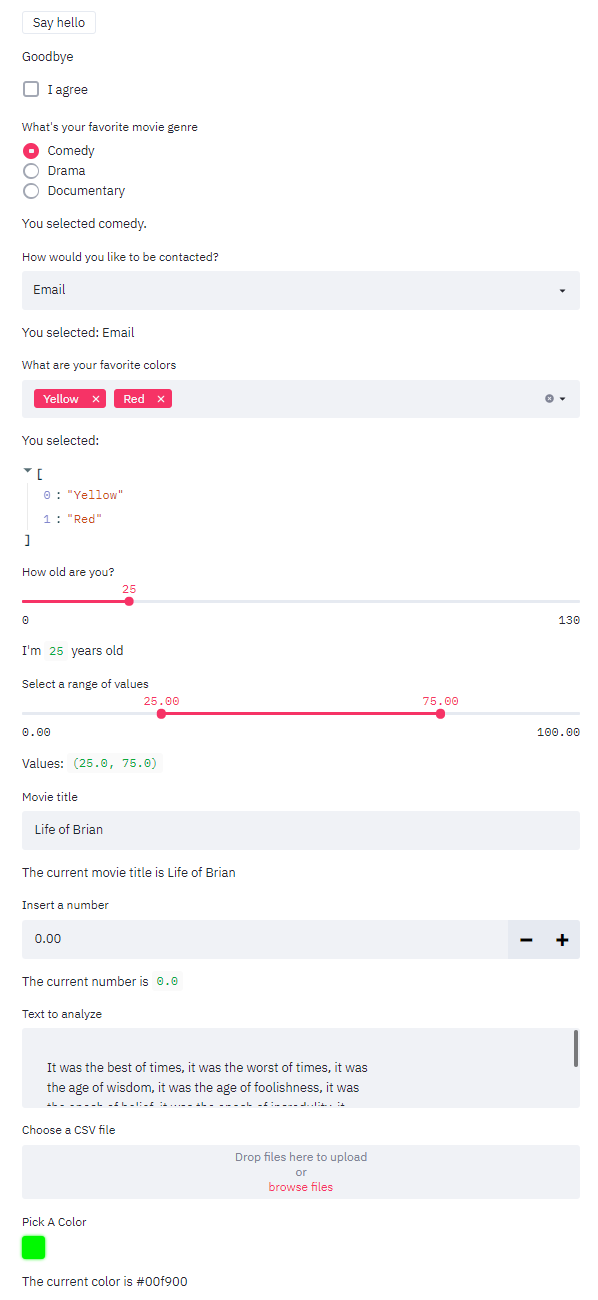
侧边栏
缓存机制
Streamlit遵循由上至下的运行顺序,所以每次代码中有进行任何更改,都会重新开始运行一遍,会十分耗时。@st.cache会对封装起来的函数进行缓存,避免二次加载。如果函数中的代码发生变动,cache会重新加载一遍并缓存起来。假如将代码还原到上一次版本,由于先前的数据已经缓存起来了,所以不会进行二次加载。
当使用@st.cache 装饰器标记一个函数时,这将告诉steamlit在此函数被调用的时候应当检查以下事情:
- 缓存函数的输入参数
- 缓存函数使用的外部变量的值
- 缓存函数主体
- 缓存函数中调用到的函数的主题
若streamlit是初次看到这四个部分的确切值,组合方法和顺序,那么streamlit将执行这个函数并将结果保存在本地缓存中。下次当缓存函数被调用的时候,若这些部分没有变化,streamlit将直接返回之前缓存中的结果作为输出。
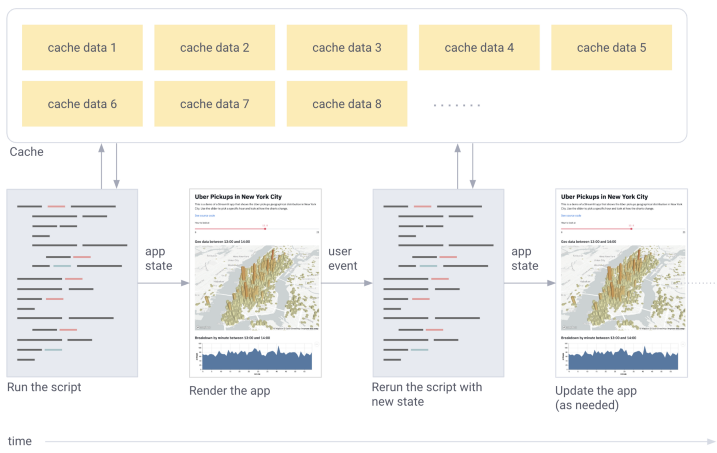
举个例子,当函数 expensive_computation(a, b), 被 @st.cache装饰时,并以 a=2 和 b=21执行, Streamlit会进行以下操作:
- 计算缓存的key
- 若key可以在缓存中找到,则:
- 提取出以前的缓存元组(缓存输出和缓存输出的hash)
- 执行输出突变检查, 计算输出的新哈希并将其与存储的output_hash进行比较。
- 若两hash不同,显示告警Cached Object Mutated。(Note: 设置allow_output_mutation=True 可以禁用这步)。
- 若输入的hash在缓存中找不到:
- 执行缓存函数 (i.e. output = expensive_computation(2, 21))
- 根据函数的output计算output_hash
- 将key → (output, output_hash)存入缓存
- 返回输出
如果遇到错误,则会引发异常。.如果在对键或输出进行哈希处理时发生错误,则会引发UnhashableTypeError 错误。
如上所述,Streamlit的缓存功能依赖于散列来计算缓存对象的键,并检测缓存结果中的意外变化。为了增强表达能力,Streamlit允许您使用hash_funcs参数覆盖此哈希过程。比如函数打开一个文件,默认情况下,它的hash是属性filename的hash。只要文件名不变,哈希值将保持不变。可以使用@st.cache装饰器的 hash_funcs 参数:
Streamlit使用Hack
掩藏底部链接
支持使用folium展示地图
如下报错:(地图不能显示)
Make this Notebook Trusted to load map: File -> Trust Notebook
解决方案:pip install branca==3.1.0
支持通过URL获取参数
备注:仅在0.58.0版本测试通过,新版本应该已经支持获取URL参数了。
1、找到tornado的安装路径
2、修改tornado下的routing.py文件
3、重启应用后进行测试:https://127.0.0.1:8501/?mypara1=99
DataFrame支持样式定义问题
通过以上方法可以控制dataframe中字段的显示精度问题或按百分比显示等,但往往会报错,原因是pandas 1.1.0升级后导致的。
解决方案是退回老版本:pip install pandas==1.0.0
支持不同URL类型的不同页面共存
上面URL获取参数存在一定的Bug,即当访问一个带参数的URL过后,再刷新其他的页面,以前带的参数会还保存下来,解决方式是部署不同页面,不同页面使用不同的端口。然后再通过Nginx进行URL映射:
支持账号密码登录
Stremlit本身不带登录验证,对于一些数据型的应用可能需要权限才能查看,一种简单的方法是每个应用最外层加上输入框,在用户输入的字符不等于代码中支付时,不显示内容。另外一种方案是,可以使用nginx的auth:
Streamlit的替代品
Streamlit最大的竞争敌手主要是Plotly Dash,相对Streamlit目前的功能更加完善,但是学习曲线相比Streamlit会稍微高一些。但从整体上对Streamlit的前景会更看好些。主要是Plotly Dash把其主要限制在了Plot.ly。两者在Github上的表现如下:
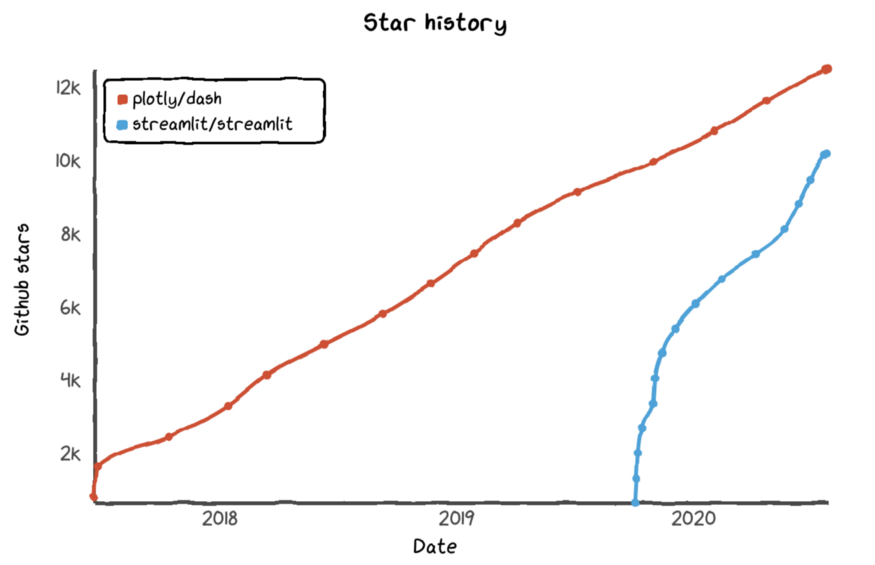
关于Plotly Dash的更多资料,期待下次有时间可以做更多的系统化整理。
参考资料:
- 官方网站:https://www.streamlit.io/
- Awesome Streamlit
- Turn Python Scripts into Beautiful ML Tools
- Plotly Dash vs Streamlit — Which is the best library for building data dashboard web apps
- Dash, Shiny, and Streamlit compare
Streamlit:快速数据可视化界面工具的更多相关文章
- 开源 Web 相册程序: Photoview 和数据可视化生成工具:Datawrapper
Photoview Photoview是一个开源 Web 相册程序,Go 语言写的,使用 Docker 安装,可以用来快速架设个人相册. github地址:https://github.com/pho ...
- 大数据可视化呈现工具LightningChart的用法
LightningChart (LightningChart Ultimate) 软件开发工具包是微软VisualStudio 的一个插件,专攻大数据可视化呈现问题,用于WPF(WindowsPres ...
- 开源数据可视化BI工具SuperSet(使用)
上一篇介绍了Linux 下如何安装SuperSet ,本篇简单介绍一下如何使用 1.输入安装时设置的用户名密码登录控制台 2.控制界面如下 3.第一步添加数据源(已安装好的mysql) 点击 da ...
- Docker容器和数据可视化管理工具Flocker
Flocker 可轻松实现 Docker 容器及其数据的管理.这是一个数据卷管理器和多主机的 Docker 集群管理工具,你可以通过它来控制数据.可用来在 Docker 中运行你的数据库.查询和 K/ ...
- Redis 可视化界面工具:Fastoredis
下载地址:https://sourceforge.net/projects/fastoredis/
- 数据可视化界面UI设计大屏展示
- 开源数据可视化BI工具SuperSet(安装)
本次安装教程共分两大步骤,因为Superset 基于python3编写的web应用(flask) 所以要求python3环境,故首先要将linux系统自带的环境进行升级,已经是python3的可跳过- ...
- BI数据可视化工具怎么选?用这款就够了!
任何一项产品的选择都需要谨慎而全面,BI数据可视化工具的选择就更不用说了.作为企业的IT部门,如果没有良好的BI工具支持,IT部门将会十分容易陷入困境.那么面对多元化的BI工具市场,IT部门该如何选择 ...
- 超级干货 :一文读懂数据可视化 ZT
前言 数据可视化,是指将相对晦涩的的数据通过可视的.交互的方式进行展示,从而形象.直观地表达数据蕴含的信息和规律. 早期的数据可视化作为咨询机构.金融企业的专业工具,其应用领域较为单一,应用形态较为保 ...
随机推荐
- H5点击不同按钮跳转显示不同分页
预期效果(页面1): 点击后显示对应的内容(页面2): HTML(页面1): 添加 onclick 跟 data-index <!-- 3我的订单 --> <div ...
- html页面跳转出现中文乱码
一般html的<meta charset="UTF-8">默认都是utf-8的编码格式,直接在网页中打开是正常的,但是有的时候在页面跳转时就会出现中文乱码问题,忘了参考 ...
- ROS中msg和srv文件的区别
1.msg和srv究竟有什么区别?? msg只是单向的发送和接受. srv包含两个部分:请求和响应. 2.msg和srv简介 msg:msg文件是描述ROS消息字段的简单文本文件.它们用于为不同语言( ...
- 『现学现忘』Docker基础 — 13、通过脚本安装Docker
Docker官方提供方便用户操作的安装脚本,用起来是非常方便.但是要注意的是,使用脚本安装Docker,是安装最新版本的Docker. 注意:不建议在生产环境中使用安装脚本.因为在生产环境中一定不要最 ...
- 矩池云 | Tony老师解读Kaggle Twitter情感分析案例
今天Tony老师给大家带来的案例是Kaggle上的Twitter的情感分析竞赛.在这个案例中,将使用预训练的模型BERT来完成对整个竞赛的数据分析. 导入需要的库 import numpy as np ...
- Java入土---Java运行机制及IDEA的安装使用
Java运行机制及IDEA的安装使用 java程序运行机制 计算机高级语言分为编译型语言跟解释型语言,而java同时具有两者的特点. 可能对于新手来说,什么是编译,什么是解释; 简单来说,编译就是将代 ...
- CF587F&CF547E题解
这两道题好像啊 贡献一种使用SAM和ACAM草两道题的方法 下面假装有 \(O(\sum |S|=m)=O(n)\). 你看看,这CF换过多少个出题人啦?换汤不换药啦!其实这两道题是同一个人出的 CF ...
- ENVI提取水系并进行生态敏感性分析
4 具体步骤 4.1 DEM数据拼接 (1)打开ENVI软件,选择[File][Open],添加文件夹DEM数据中的影像,操作如图4.1.1所示,结果如图4.1.2. 图4.1.1 添加DEM数据影像 ...
- [Java编程思想] 第二章 一切都是对象
第二章 一切都是对象 2.1 用引用操纵对象 创建一个String引用: String s; 这里所创建的只是引用,并不是对象. 创建一个引用的同时便初始化: String s = &qu ...
- 获取bing首页的每日一图
从必应(bing)首页抓取他的每日一图 以前上学时,曾经用python写过一个每天抓取bing每日一图的小工具. 现在想用java来重构一下. 抓取图片的思路 首先获取网页源码 从网页源码中,我们可以 ...