IDEA Generate pojo(data first)基于 spring data jpa - code
基于 idea 的 pojo生成
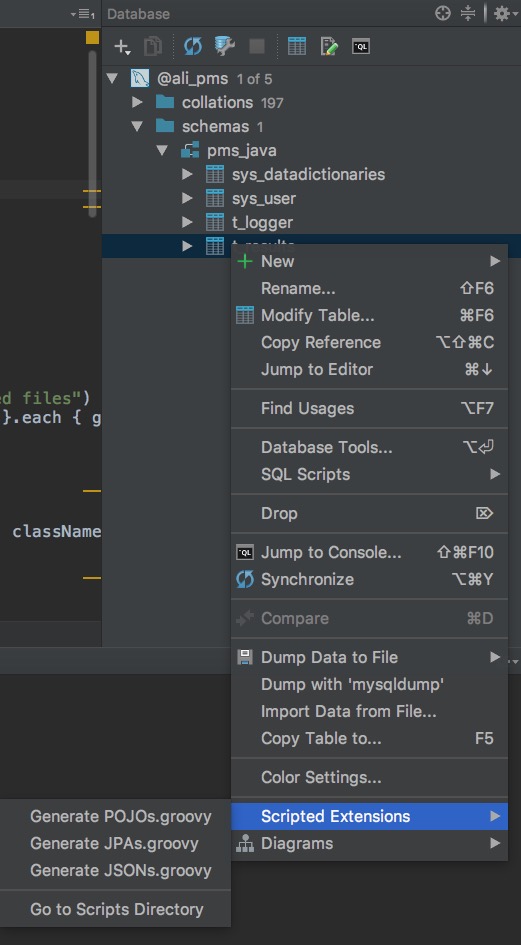
右侧菜单栏 Database->New( + 图标)->Data source-> mysql(根据自己的数据源选择)
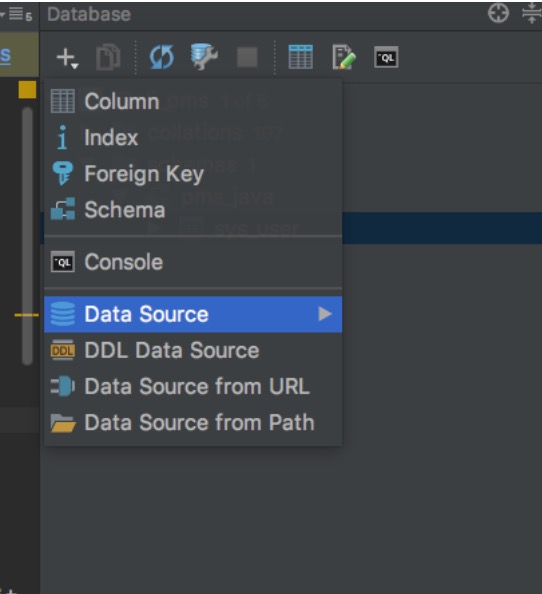

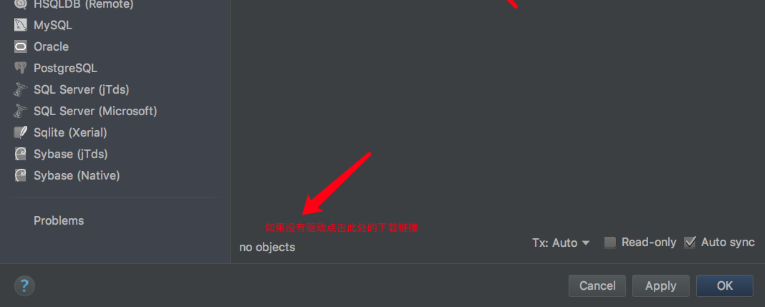
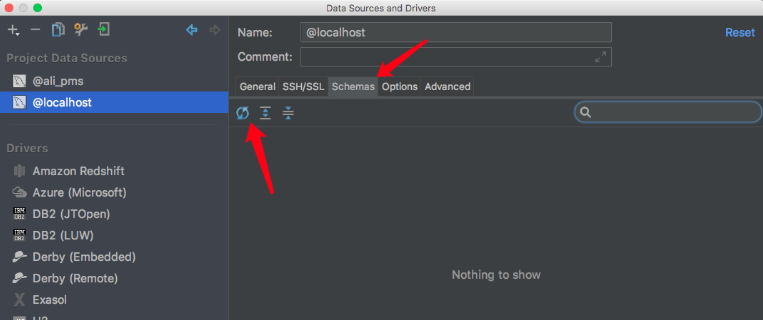
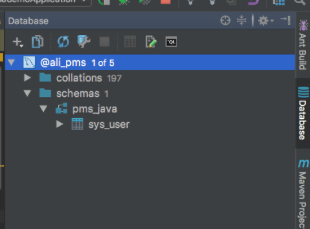
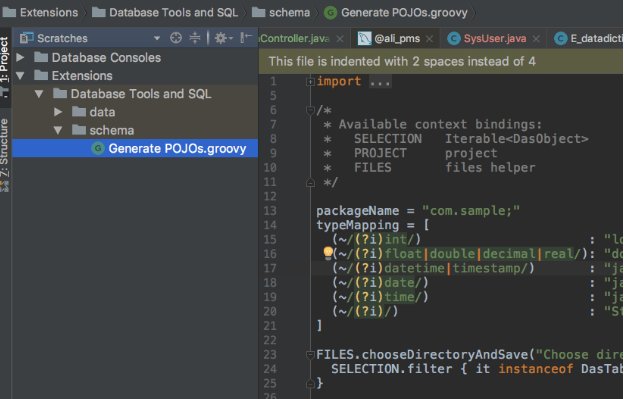
使用:
代码如下: POJOs.groovy
import com.intellij.database.model.DasTable
import com.intellij.database.model.ObjectKind
import com.intellij.database.util.Case
import com.intellij.database.util.DasUtil /*
* Available context bindings:
* SELECTION Iterable<DasObject>
* PROJECT project
* FILES files helper
*/ packageName = "com.sephiroth.jpademo.entity;"
typeMapping = [
(~/(?i)int/) : "long",
(~/(?i)float|double|decimal|real/): "double",
(~/(?i)datetime|timestamp/) : "java.sql.Timestamp",
(~/(?i)date/) : "java.sql.Date",
(~/(?i)time/) : "java.sql.Time",
(~/(?i)/) : "String"
] FILES.chooseDirectoryAndSave("Choose directory", "Choose where to store generated files") { dir ->
SELECTION.filter { it instanceof DasTable && it.getKind() == ObjectKind.TABLE }.each { generate(it, dir) }
} def generate(table, dir) {
def className = javaName(table.getName(), true)
def fields = calcFields(table)
new File(dir, "E_"+className + ".java").withPrintWriter { out -> generate(out, className, fields,table.getName()) }
} def generate(out, className, fields ,tablename) {
out.println "package $packageName"
out.println ""
out.println ""
// 引用映射
out.println "import org.hibernate.annotations.GenericGenerator;"
out.println ""
out.println "import javax.persistence.*;"
out.println "import java.io.Serializable;"
// jpa映射
out.println "@Entity"
out.println "@Table(name = \"$tablename\")"
// jpa映射end
out.println "public class E_$className implements Serializable {"
out.println ""
fields.each() {
if (it.annos != "") out.println " ${it.annos}"
// 列映射
// 主键映射
if (it.name == "id" && it.type == "String") {
out.println """ @GenericGenerator(name = "user-uuid", strategy = "uuid")
@GeneratedValue(generator = "user-uuid")
@Column(name = "id", nullable = false, length = 64)"""
}
else if(it.name == "id") {
out.println """ @GeneratedValue
@Column(name = \"$it.colname\")"""
}
else {
out.println " @Column(name = \"$it.colname\")"
}
out.println " private ${it.type} ${it.name};"
}
out.println ""
fields.each() {
out.println ""
out.println " public ${it.type} get${it.name.capitalize()}() {"
out.println " return ${it.name};"
out.println " }"
out.println ""
out.println " public void set${it.name.capitalize()}(${it.type} ${it.name}) {"
out.println " this.${it.name} = ${it.name};"
out.println " }"
out.println ""
}
out.println "}"
} def calcFields(table) {
DasUtil.getColumns(table).reduce([]) { fields, col ->
def spec = Case.LOWER.apply(col.getDataType().getSpecification())
def typeStr = typeMapping.find { p, t -> p.matcher(spec).find() }.value
fields += [[
name : javaName(col.getName(), false),
colname : col.getName(),
type : typeStr,
annos: """
/**
* $col.comment
*/"""]]
}
} def javaName(str, capitalize) {
def s = com.intellij.psi.codeStyle.NameUtil.splitNameIntoWords(str)
.collect { Case.LOWER.apply(it).capitalize() }
.join("")
.replaceAll(/[^\p{javaJavaIdentifierPart}[_]]/, "_")
capitalize || s.length() == 1? s : Case.LOWER.apply(s[0]) + s[1..-1]
}
IDEA Generate pojo(data first)基于 spring data jpa - code的更多相关文章
- 【Spring Data 系列学习】Spring Data JPA 基础查询
[Spring Data 系列学习]Spring Data JPA 基础查询 前面的章节简单讲解了 了解 Spring Data JPA . Jpa 和 Hibernate,本章节开始通过案例上手 S ...
- 【Spring Data 系列学习】Spring Data JPA @Query 注解查询
[Spring Data 系列学习]Spring Data JPA @Query 注解查询 前面的章节讲述了 Spring Data Jpa 通过声明式对数据库进行操作,上手速度快简单易操作.但同时 ...
- 【Spring Data 系列学习】Spring Data JPA 自定义查询,分页,排序,条件查询
Spring Boot Jpa 默认提供 CURD 的方法等方法,在日常中往往时无法满足我们业务的要求,本章节通过自定义简单查询案例进行讲解. 快速上手 项目中的pom.xml.application ...
- Spring Data ElasticSearch的使用
1.什么是Spring Data Spring Data是一个用于简化数据库访问,并支持云服务的开源框架.其主要目标是使得对数据的访问变得方便快捷,并支持map-reduce框架和云计算数据服务. S ...
- Spring Data JPA例子[基于Spring Boot、Mysql]
关于Spring Data Spring社区的一个顶级工程,主要用于简化数据(关系型&非关系型)访问,如果我们使用Spring Data来开发程序的话,那么可以省去很多低级别的数据访问操作,如 ...
- 转:使用 Spring Data JPA 简化 JPA 开发
从一个简单的 JPA 示例开始 本文主要讲述 Spring Data JPA,但是为了不至于给 JPA 和 Spring 的初学者造成较大的学习曲线,我们首先从 JPA 开始,简单介绍一个 JPA 示 ...
- 深入浅出学Spring Data JPA
第一章:Spring Data JPA入门 Spring Data是什么 Spring Data是一个用于简化数据库访问,并支持云服务的开源框架.其主要目标是使得对数据的访问变得方便快捷,并支持map ...
- 使用 Spring Data JPA 简化 JPA 开发
从一个简单的 JPA 示例开始 本文主要讲述 Spring Data JPA,但是为了不至于给 JPA 和 Spring 的初学者造成较大的学习曲线,我们首先从 JPA 开始,简单介绍一个 JPA 示 ...
- Spring Data Redis 让 NoSQL 快如闪电 (1)
[编者按]本文作者为 Xinyu Liu,详细介绍了 Redis 的特性,并辅之以丰富的用例.在本文的第一部分,将重点概述 Redis 的方方面面.文章系国内 ITOM 管理平台 OneAPM 编译呈 ...
随机推荐
- C++中的内存区[译文]
C++ 中的内存区 Const Data: The const data area stores string literals and other data whose values are kno ...
- python——动态类型简介
动态类型简介 类型属于对象,而不是变量 每一个对象都有两个标准的头部信息:类型标志符和引用计数器. 对象的垃圾收集,就是通过引用计数器实现的.可以在脚本中任意使用对象而不需要考虑释放内存空间. 循环饮 ...
- ubuntu16.04的anacoda内置的spyder不支持中文【学习笔记】
执行下面的语句:将libfcitxplatforminputcontextplugin.so复制到anaconda2的安装目录下的platforminputcontexts目录重启生效 cp /usr ...
- hadoop 2.7.3 源码编译教程
1.工具准备,最靠谱的是hadoop说明文档里要求具备的那些工具. 到hadoop官网,点击source下载hadoop-2.7.3-src.tar.gz. 解压之 tar -zxvf hadoop- ...
- python技术
要把zabbix弄成自动监控,下发任务,部署,事件恢复得功能
- 解析CEPH: 存储引擎实现之一 filestore
Ceph作为一个高可用和强一致性的软件定义存储实现,去使用它非常重要的就是了解其内部的IO路径和存储实现.这篇文章主要介绍在IO路径中最底层的ObjectStore的实现之一FileStore. Ob ...
- MySQL 入门篇
历史 MySQL 是由 David Axmark.Allan Larsson 和 Michael Widenius 3 个瑞典人于 20 世纪 90 年代开发的一个关系型数据库.MySQL 之名取自创 ...
- 公共域名服务DNS 114.114.114.114和8.8.8.8
一.两者的联系 114.114.114.114和8.8.8.8,这两个IP地址都属于公共域名解析服务DNS其中的一部分,而且由于不是用于商业用途的,这两个DNS都很纯净,不用担心因ISP运营商导致的D ...
- 四 web爬虫,scrapy模块标签选择器下载图片,以及正则匹配标签
标签选择器对象 HtmlXPathSelector()创建标签选择器对象,参数接收response回调的html对象需要导入模块:from scrapy.selector import HtmlXPa ...
- <mvc:default-servlet-handler/>的作用
优雅REST风格的资源URL不希望带 .html 或 .do 等后缀.由于早期的Spring MVC不能很好地处理静态资源,所以在web.xml中配置DispatcherServlet的请求映射,往往 ...