IDEA Generate pojo(data first)基于 spring data jpa - code
基于 idea 的 pojo生成
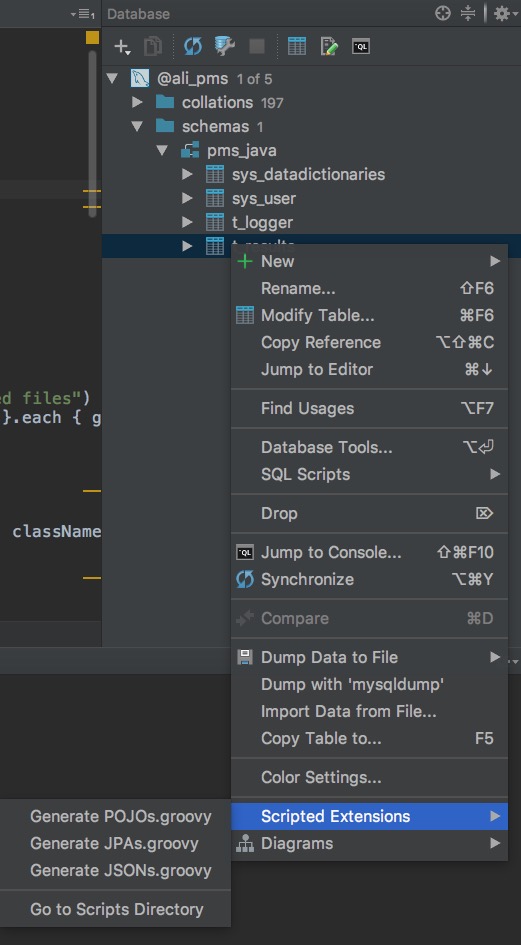
右侧菜单栏 Database->New( + 图标)->Data source-> mysql(根据自己的数据源选择)
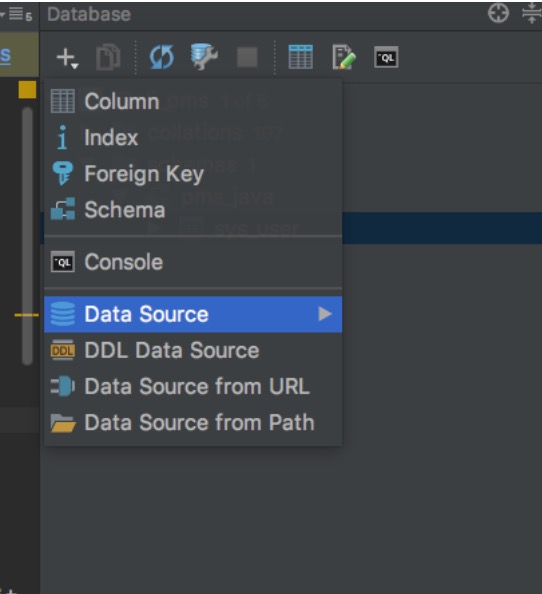

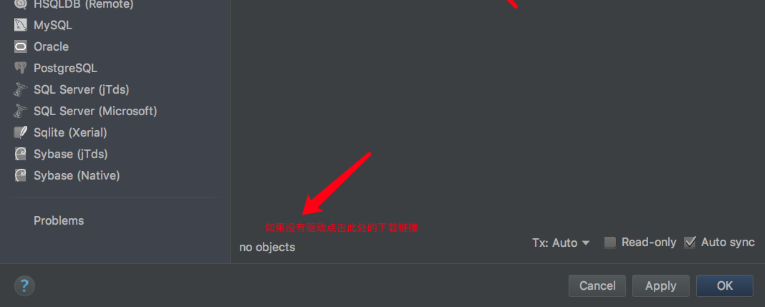
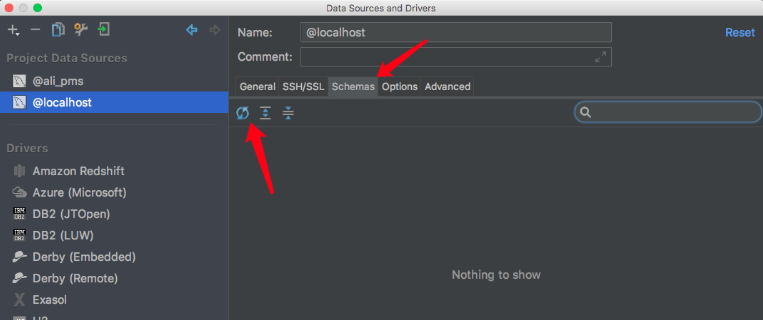
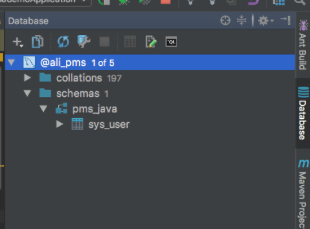
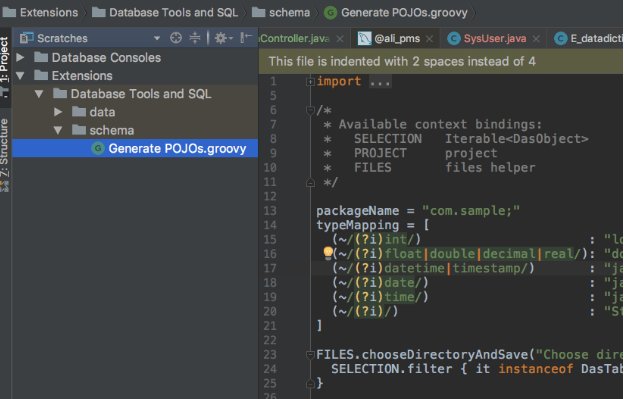
使用:
代码如下: POJOs.groovy
import com.intellij.database.model.DasTable
import com.intellij.database.model.ObjectKind
import com.intellij.database.util.Case
import com.intellij.database.util.DasUtil /*
* Available context bindings:
* SELECTION Iterable<DasObject>
* PROJECT project
* FILES files helper
*/ packageName = "com.sephiroth.jpademo.entity;"
typeMapping = [
(~/(?i)int/) : "long",
(~/(?i)float|double|decimal|real/): "double",
(~/(?i)datetime|timestamp/) : "java.sql.Timestamp",
(~/(?i)date/) : "java.sql.Date",
(~/(?i)time/) : "java.sql.Time",
(~/(?i)/) : "String"
] FILES.chooseDirectoryAndSave("Choose directory", "Choose where to store generated files") { dir ->
SELECTION.filter { it instanceof DasTable && it.getKind() == ObjectKind.TABLE }.each { generate(it, dir) }
} def generate(table, dir) {
def className = javaName(table.getName(), true)
def fields = calcFields(table)
new File(dir, "E_"+className + ".java").withPrintWriter { out -> generate(out, className, fields,table.getName()) }
} def generate(out, className, fields ,tablename) {
out.println "package $packageName"
out.println ""
out.println ""
// 引用映射
out.println "import org.hibernate.annotations.GenericGenerator;"
out.println ""
out.println "import javax.persistence.*;"
out.println "import java.io.Serializable;"
// jpa映射
out.println "@Entity"
out.println "@Table(name = \"$tablename\")"
// jpa映射end
out.println "public class E_$className implements Serializable {"
out.println ""
fields.each() {
if (it.annos != "") out.println " ${it.annos}"
// 列映射
// 主键映射
if (it.name == "id" && it.type == "String") {
out.println """ @GenericGenerator(name = "user-uuid", strategy = "uuid")
@GeneratedValue(generator = "user-uuid")
@Column(name = "id", nullable = false, length = 64)"""
}
else if(it.name == "id") {
out.println """ @GeneratedValue
@Column(name = \"$it.colname\")"""
}
else {
out.println " @Column(name = \"$it.colname\")"
}
out.println " private ${it.type} ${it.name};"
}
out.println ""
fields.each() {
out.println ""
out.println " public ${it.type} get${it.name.capitalize()}() {"
out.println " return ${it.name};"
out.println " }"
out.println ""
out.println " public void set${it.name.capitalize()}(${it.type} ${it.name}) {"
out.println " this.${it.name} = ${it.name};"
out.println " }"
out.println ""
}
out.println "}"
} def calcFields(table) {
DasUtil.getColumns(table).reduce([]) { fields, col ->
def spec = Case.LOWER.apply(col.getDataType().getSpecification())
def typeStr = typeMapping.find { p, t -> p.matcher(spec).find() }.value
fields += [[
name : javaName(col.getName(), false),
colname : col.getName(),
type : typeStr,
annos: """
/**
* $col.comment
*/"""]]
}
} def javaName(str, capitalize) {
def s = com.intellij.psi.codeStyle.NameUtil.splitNameIntoWords(str)
.collect { Case.LOWER.apply(it).capitalize() }
.join("")
.replaceAll(/[^\p{javaJavaIdentifierPart}[_]]/, "_")
capitalize || s.length() == 1? s : Case.LOWER.apply(s[0]) + s[1..-1]
}
IDEA Generate pojo(data first)基于 spring data jpa - code的更多相关文章
- 【Spring Data 系列学习】Spring Data JPA 基础查询
[Spring Data 系列学习]Spring Data JPA 基础查询 前面的章节简单讲解了 了解 Spring Data JPA . Jpa 和 Hibernate,本章节开始通过案例上手 S ...
- 【Spring Data 系列学习】Spring Data JPA @Query 注解查询
[Spring Data 系列学习]Spring Data JPA @Query 注解查询 前面的章节讲述了 Spring Data Jpa 通过声明式对数据库进行操作,上手速度快简单易操作.但同时 ...
- 【Spring Data 系列学习】Spring Data JPA 自定义查询,分页,排序,条件查询
Spring Boot Jpa 默认提供 CURD 的方法等方法,在日常中往往时无法满足我们业务的要求,本章节通过自定义简单查询案例进行讲解. 快速上手 项目中的pom.xml.application ...
- Spring Data ElasticSearch的使用
1.什么是Spring Data Spring Data是一个用于简化数据库访问,并支持云服务的开源框架.其主要目标是使得对数据的访问变得方便快捷,并支持map-reduce框架和云计算数据服务. S ...
- Spring Data JPA例子[基于Spring Boot、Mysql]
关于Spring Data Spring社区的一个顶级工程,主要用于简化数据(关系型&非关系型)访问,如果我们使用Spring Data来开发程序的话,那么可以省去很多低级别的数据访问操作,如 ...
- 转:使用 Spring Data JPA 简化 JPA 开发
从一个简单的 JPA 示例开始 本文主要讲述 Spring Data JPA,但是为了不至于给 JPA 和 Spring 的初学者造成较大的学习曲线,我们首先从 JPA 开始,简单介绍一个 JPA 示 ...
- 深入浅出学Spring Data JPA
第一章:Spring Data JPA入门 Spring Data是什么 Spring Data是一个用于简化数据库访问,并支持云服务的开源框架.其主要目标是使得对数据的访问变得方便快捷,并支持map ...
- 使用 Spring Data JPA 简化 JPA 开发
从一个简单的 JPA 示例开始 本文主要讲述 Spring Data JPA,但是为了不至于给 JPA 和 Spring 的初学者造成较大的学习曲线,我们首先从 JPA 开始,简单介绍一个 JPA 示 ...
- Spring Data Redis 让 NoSQL 快如闪电 (1)
[编者按]本文作者为 Xinyu Liu,详细介绍了 Redis 的特性,并辅之以丰富的用例.在本文的第一部分,将重点概述 Redis 的方方面面.文章系国内 ITOM 管理平台 OneAPM 编译呈 ...
随机推荐
- offset,client,scroll,style,getBoundingClientRect相关笔记
1.offsetTop 功能:获取元素上外缘与最近的定位父元素内壁的距离,如果没有定位父元素,则是与文档上内壁的距离 使用方法:js document.querySelector(...).offse ...
- error C2665: “std::locale::facet::operator new”: 2 个重载中没有一个可以转换所有参数类型
qt项目 qt creator项目由插件自动转换成的vs2015项目,为了发布少带些dll ,切换成vs2013项目,在更改了一些vs2013不支持的c++新标准写法之后,release可正常编过,但 ...
- 求最长不下降子序列(nlogn)
最长递增子序列问题:在一列数中寻找一些数,这些数满足:任意两个数a[i]和a[j],若i<j,必有a[i]<a[j],这样最长的子序列称为最长递增子序列. 设dp[i]表示以i为结尾的最长 ...
- [翻译]PostCSS简介
许多开发人员花时间在使用CSS的预处理器上如less,sass和stylus.这些工具已经成为Web开发的重要组成部分.写一个网站的样式,不使用嵌套,变量或混入等功能很少见.它们每个都是非常实用的,让 ...
- Spring Boot 设置启动时banner
Spring Boot项目再启动的时候默认会在控制台输出一个字符banner图案,如下图: 我们可以通过下面的方法关闭启动时显示字符banner图案: 关闭banner方法一: public stat ...
- LeetCode——Longest Consecutive Sequence
LeetCode--Longest Consecutive Sequence Question Given an unsorted array of integers, find the length ...
- MFC clist 学习设计
最近想设计一款WEBSHELL的综合破解工具. 然后设计到了日志输出那儿,因为MFC不熟悉,刚学.所以一直在想用edit控件好还是clist比较好. 今天设计了一下日志输出界面,然后记录一下学习笔记. ...
- JNIjw01
1.VC6(CPP)的DLL代码: #include<stdio.h> #include "jniZ_JNIjw01.h" JNIEXPORT void JNICALL ...
- Oracle cmd乱码
查看下环境变量的设置,查看是否有变量NLS_LANG,没有则新建该变量.新建变量,设置变量名:NLS_LANG,变量值根据以上字符集确定,一般都是中文简体SIMPLIFIED CHINESE_CHIN ...
- Django进阶Model篇006 - 多表关联查询
接着前面的例子,举例多表查询实例如下: 1.查询作战的所有完整信息. >>> AuthorDetail.objects.values('sex','email','address', ...