MapReduce输入输出的处理流程及combiner
MapReduce 的输入输出
MapReduce 框架运转在<key,value> 键值对上,也就是说,框架把作业的输入看成是一组<key,value>键值对,同样也产生一组<key,value>键值对作为作业的输出,这两组键值对可能是不同的。
一个 MapReduce 作业的输入和输出类型如下图所示:可以看出在整个标准的流程中,会有三组<key,value>键值对类型的存在。

MapReduce的处理流程
1. Mapper任务执行过程详解
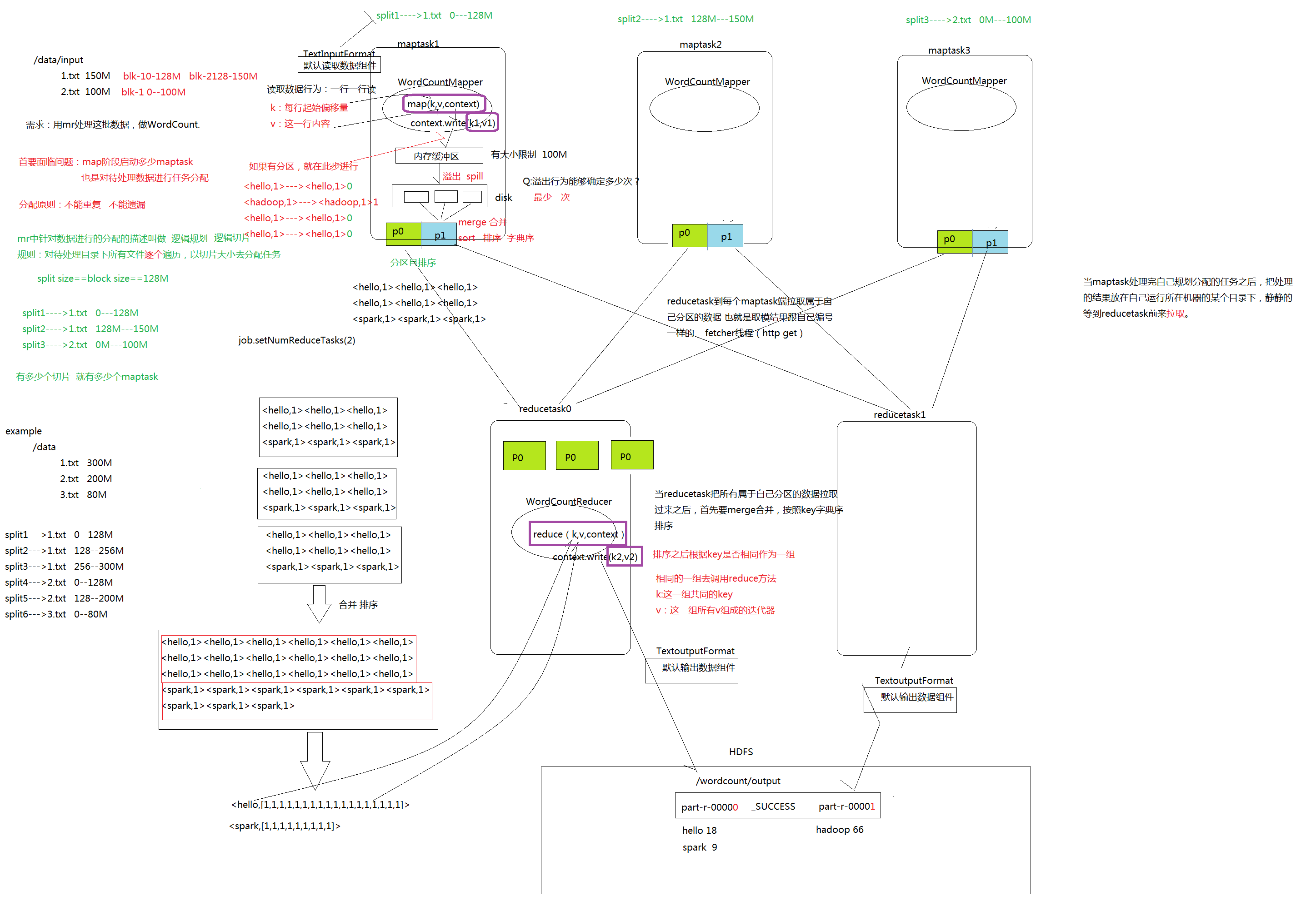
第一阶段是把输入目录下文件按照一定的标准逐个进行逻辑切片,形成切片规划。默认情况下,Split size = Block size。每一个切片由一个MapTask 处理。(getSplits)
第二阶段是对切片中的数据按照一定的规则解析成<key,value>对。默认规则是把每一行文本内容解析成键值对。key 是每一行的起始位置(单位是字节),value 是本行的文本内容。(TextInputFormat)
第三阶段是调用 Mapper 类中的 map 方法。上阶段中每解析出来的一个<k,v>,调用一次 map 方法。每次调用 map 方法会输出零个或多个键值对。
第四阶段是按照一定的规则对第三阶段输出的键值对进行分区。默认是只有一个区。分区的数量就是 Reducer 任务运行的数量。默认只有一个Reducer 任务。
第五阶段是对每个分区中的键值对进行排序。首先,按照键进行字典序排序,对于键相同的键值对,按照值进行排序。比如三个键值对<2,2>、<1,3>、<2,1>,键和值分别是整数。那么排序后的结果是<1,3>、<2,1>、<2,2>。
如果有第六阶段,那么进入第六阶段;如果没有,直接输出到文件中。
第六阶段是对数据进行局部聚合处理,也就是 combiner 处理。键相等的键值对会调用一次 reduce 方法。经过这一阶段,数据量会减少。 本阶段默认是没有的
2. Reducer 任务 任务 执行过程详解
第一阶段是 Reducer 任务会主动从 Mapper 任务复制其输出的键值对。Mapper 任务可能会有很多,因此 Reducer 会复制多个 Mapper 的输出。
第二阶段是把复制到 Reducer 本地数据,全部进行合并,即把分散的数据合并成一个大的数据。再对合并后的数据排序。
第三阶段是对排序后的键值对调用 reduce 方法。键相等的键值对调用一次reduce 方法,每次调用会产生零个或者多个键值对。最后把这些输出的键值对写入到 HDFS 文件中。
在整个MapReduce 程序的开发过程中,我们最大的工作量是覆盖map 函数和覆盖reduce 函数。
Mapreduce的combiner
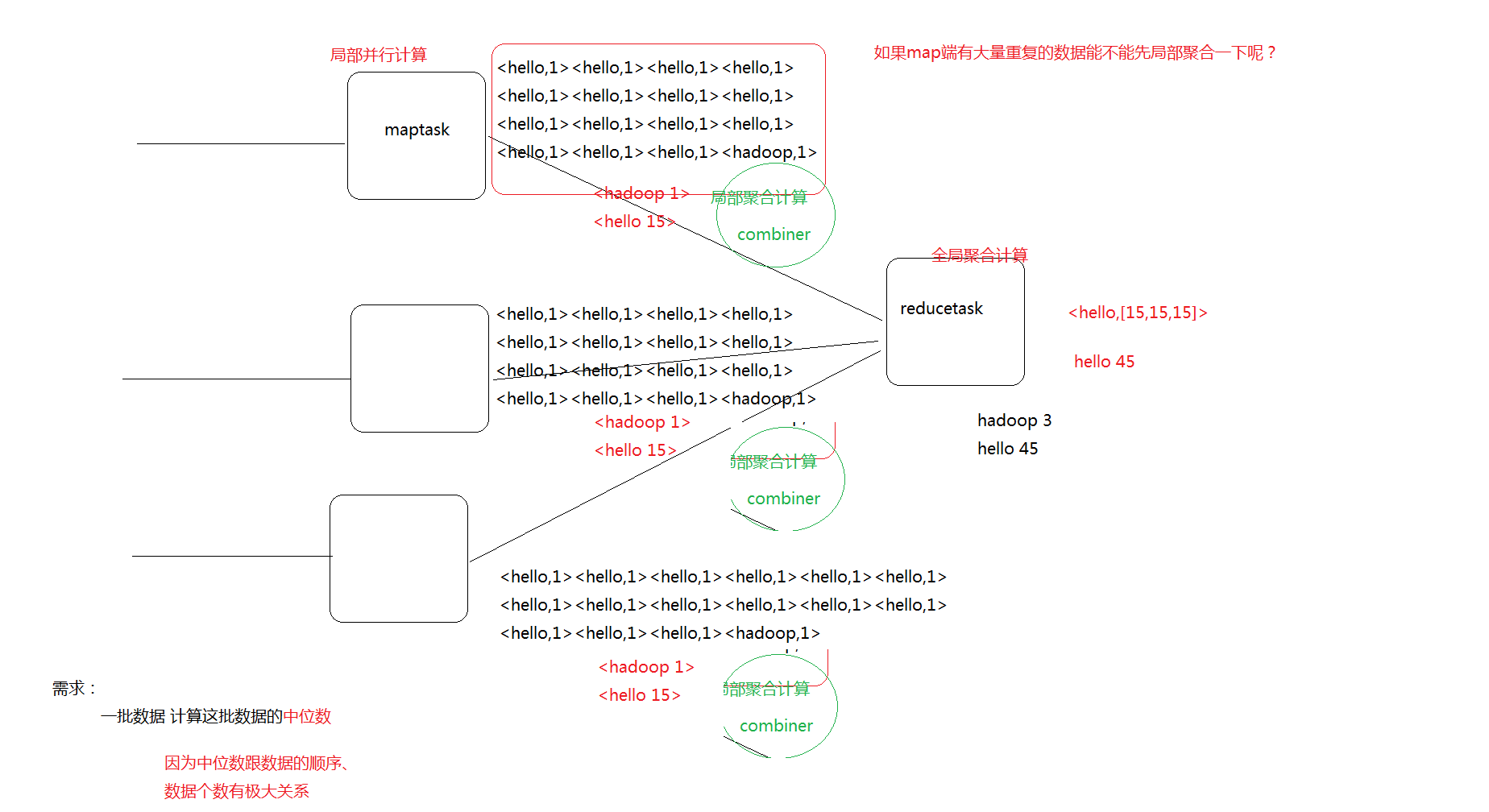
每一个 map 都可能会产生大量的本地输出,Combiner 的作用就是对 map 端的输出先做一次合并,以减少在 map 和 reduce 节点之间的数据传输量,以提高网络 IO 性能,是 MapReduce 的一种优化手段之一。
- combiner 是 MR 程序中 Mapper 和 Reducer 之外的一种组件
- combiner 组件的父类就是 Reducer
- combiner 和 reducer 的区别在于运行的位置:
- Combiner 是在每一个 maptask 所在的节点运行
- Reducer 是接收全局所有 Mapper 的输出结果;
- combiner 的意义就是对每一个 maptask 的输出进行局部汇总,以减小网络传输量
- 具体实现步骤:
1、自定义一个 combiner 继承 Reducer,重写 reduce 方法
- combiner 能够应用的前提是不能影响最终的业务逻辑,而且,combiner 的输出 kv 应该跟 reducer 的输入 kv 类型要对应起来
- 2、在 job 中设置: job.setCombinerClass(CustomCombiner.class)
如果业务中 涉及中位数等跟数据顺序 个数相关的 不要使用
combiner本质上就是reduce 只不过是局部的reduce 进行局部汇总
MapReduce输入输出的处理流程及combiner的更多相关文章
- MapReduce作业的执行流程
MapReduce任务执行总流程 一个MapReduce作业的执行流程是:代码编写 -> 作业配置 -> 作业提交 -> Map任务的分配和执行 -> 处理中间结果 -> ...
- MapReduce简述、工作流程及新旧API对照
什么是MapReduce? 你想数出一摞牌中有多少张黑桃.直观方式是一张一张检查而且数出有多少张是黑桃. MapReduce方法则是: 1. 给在座的全部玩家中分配这摞牌. 2. 让每一个玩家数自己手 ...
- [Hadoop]浅谈MapReduce原理及执行流程
MapReduce MapReduce原理非常重要,hive与spark都是基于MR原理 MapReduce采用多进程,方便对每个任务资源控制和调配,但是进程消耗更多的启动时间,因此MR时效性不高.适 ...
- MapReduce:Shuffle过程的流程
Shuffle过程是MapReduce的核心,Shuffle描述着数据从map task输出到reduce task输入的这段过程. 1.map端
- Hadoop2.4.1 MapReduce通过Map端shuffle(Combiner)完成数据去重
package com.bank.service; import java.io.IOException; import org.apache.hadoop.conf.Configuration;im ...
- map-reduce的八个流程
下面讲解这八个流程 Inputformat-->map-->(combine)-->partition-->copy&merge-->sort-->red ...
- MapReduce输入输出类型、格式及实例
输入格式 1.输入分片与记录 2.文件输入 3.文本输入 4.二进制输入 5.多文件输入 6.数据库格式输入 1.输入分片与记录 1.JobClient通过指定的输入文件的格式来生成数据分片Input ...
- MapReduce架构与执行流程
一.MapReduce是用于解决什么问题的? 每一种技术的出现都是用来解决实际问题的,否则必将是昙花一现,那么MapReduce是用来解决什么实际的业务呢? 首先来看一下MapReduce官方定义: ...
- mapreduce 输入输出类型
默认的mapper是IdentityMapper,默认的reducer是IdentityReducer,它们将输入的键和值原封不动地写到输出中. 默认的partitioner是HashPartitin ...
随机推荐
- Log4Net使用教程
简介 为方便跟踪程序运行情况,我们可以记录系统运行异常日志,winform和web都可以通过继承异常或者try来实现. 官方网站:http://logging.apache.org/log4net/ ...
- Hadoop Federation联邦
背景概述 单 NameNode 的架构使得 HDFS 在集群扩展性和性能上都有潜在的问题,当集群大到一定程度后,NameNode 进程使用的内存可能会达到上百 G,NameNode 成为了性能的瓶颈. ...
- leetcode-distinct sequences
Solution: when see question about two strings , DP should be considered first. We can abstract this ...
- eclipse tomcat jdk 版本引用
今日遇到一个问题,因为比较难找,所以记录下来,方便日后查阅,也许也可以帮助同行. 一个Java project工程,使用了solr6.2,所以需要引用jdk8才可以正常使用. 代码编写好了,已经提交s ...
- TaskScheduler内幕天机解密:Spark shell案例运行日志详解、TaskScheduler和SchedulerBackend、FIFO与FAIR、Task运行时本地性算法详解等
本课主题 通过 Spark-shell 窥探程序运行时的状况 TaskScheduler 与 SchedulerBackend 之间的关系 FIFO 与 FAIR 两种调度模式彻底解密 Task 数据 ...
- Vue、PHP、Bootstrap联手打造简单数据管理表格
这是一个用Vue.Bootstrap和PHP一起写的小实例,回顾总结了一下之前学习的知识,顺带添加点学习乐趣. 先上效果图: 用到的知识有:Vue数据绑定及组件.Bootstrap界面.PHP-AJA ...
- 一.Mysql主从复制配置
在我之前的文章四·安装mysql-5.7.16-linux-glibc2.5-x86_64.tar.gz(基于Centos7源码安装 和 九.mysql数据库多实例安装mysqld_multi [st ...
- UVa 10491 - Cows and Cars(全概率)
链接: https://uva.onlinejudge.org/index.php?option=com_onlinejudge&Itemid=8&page=show_problem& ...
- 使用@AspectJ注解开发Spring AOP
一.实体类: Role public class Role { private int id; private String roleName; private String note; @Overr ...
- 【题解】洛谷P1283 平板涂色(搜索+暴力)
思路 看到n<16 整个坐标<100 肯定想到暴力啊 蒟蒻来一发最简单易懂的题解(因为不会DP哈 首先我们用map数组来存坐标图 注意前面的坐标需要加1 因为输入的是坐标 而我们需要的是格 ...