JAVA提高十四:HashSet深入分析
前面我们介绍了HashMap,Hashtable,那么还有一个hash家族,那就是HashSet;在讲解HashSet前,大家先要知道的是HashSet是单值集合的接口,即是Collection下面的,而HashMap是Map下面的,但是它和HashMap又是有关系的,所以在使用的时候大家需求要注意,重点还是要对下面的图需要熟悉,好了,我们开始分析。
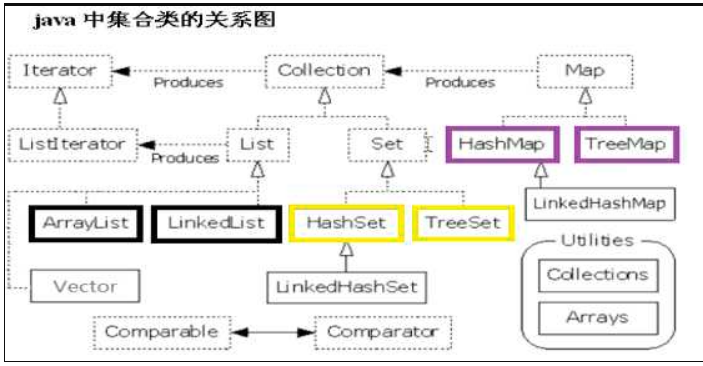
一、HashSet 定义
翻看源码,HashSet的定义如下:
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
HashSet 是一个没有重复元素的集合。HashSet继承AbstractSet类,实现Set、Cloneable、Serializable接口。其中AbstractSet提供 Set 接口的骨干实现,从而最大限度地减少了实现此接口所需的工作。
它是由HashMap实现的,不保证元素的顺序,而且HashSet允许使用 null 元素。
HashSet是非同步的。如果多个线程同时访问一个哈希 set,而其中至少一个线程修改了该 set,那么它必须 保持外部同步。这通常是通过对自然封装该 set 的对象执行同步操作来完成的。如果不存在这样的对象,则应该使用 Collections.synchronizedSet 方法来“包装” set。最好在创建时完成这一操作,以防止对该 set 进行意外的不同步访问:
Set s = Collections.synchronizedSet(new HashSet(...));
HashSet通过iterator()返回的迭代器是fail-fast的。
HashSet和Map之间的关系:
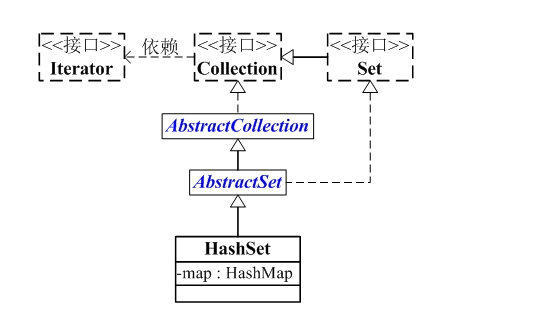
它是通过HashMap实现的。HashSet中含有一个"HashMap类型的成员变量"map,HashSet的操作函数,实际上都是通过map实现的。
二、构造方法
/**
* 默认构造函数
* 初始化一个空的HashMap,并使用默认初始容量为16和加载因子0.75。
*/
public HashSet() {
map = new HashMap<>();
} /**
* 构造一个包含指定 collection 中的元素的新 set。
*/
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
} /**
* 构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和指定的加载因子
*/
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
} /**
* 构造一个新的空 set,其底层 HashMap 实例具有指定的初始容量和默认的加载因子(0.75)。
*/
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
} /**
* 在API中我没有看到这个构造函数,今天看源码才发现(原来访问权限为包权限,不对外公开的)
* 以指定的initialCapacity和loadFactor构造一个新的空链接哈希集合。
* dummy 为标识 该构造函数主要作用是对LinkedHashSet起到一个支持作用
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
从构造函数中可以看出HashSet所有的构造都是构造出一个新的HashMap,其中最后一个构造函数,为包访问权限是不对外公开,仅仅只在使用LinkedHashSet时才会发生作用。
HashSet的主要API
boolean add(E object)
void clear()
Object clone()
boolean contains(Object object)
boolean isEmpty()
Iterator<E> iterator()
boolean remove(Object object)
int size()
三、源码分析
对于 HashSet 而言,它是基于 HashMap 实现的,HashSet 底层使用 HashMap 来保存所有元素,因此 HashSet 的实现比较简单,相关 HashSet 的操作,基本上都是直接调用底层 HashMap 的相关方法来完成,我们应该为保存到 HashSet 中的对象覆盖 hashCode() 和 equals()
add 方法
/** * @param e 将添加到此set中的元素。
* @return 如果此set尚未包含指定元素,则返回true。
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
如果此 set 中尚未包含指定元素,则添加指定元素。更确切地讲,如果此 set 没有包含满足(e==null ? e2==null : e.equals(e2)) 的元素 e2,则向此 set 添加指定的元素 e。如果此 set 已包含该元素,则该调用不更改 set 并返回 false。但底层实际将将该元素作为 key 放入 HashMap。思考一下为什么?
由于 HashMap 的 put() 方法添加 key-value 对时,当新放入 HashMap 的 Entry 中 key 与集合中原有 Entry 的 key 相同(hashCode()返回值相等,通过 equals 比较也返回 true),新添加的 Entry 的 value 会将覆盖原来 Entry 的 value(HashSet 中的 value 都是PRESENT),但 key 不会有任何改变,因此如果向 HashSet 中添加一个已经存在的元素时,新添加的集合元素将不会被放入 HashMap中,原来的元素也不会有任何改变,这也就满足了 Set 中元素不重复的特性。
该方法如果添加的是在 HashSet 中不存在的,则返回 true;如果添加的元素已经存在,返回 false。其原因在于我们之前提到的关于 HashMap 的 put 方法。该方法在添加 key 不重复的键值对的时候,会返回 null。如下:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
其余方法
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
4{
static final long serialVersionUID = -5024744406713321676L; // 底层使用HashMap来保存HashSet中所有元素。
private transient HashMap<E,Object> map; // 定义一个虚拟的Object对象作为HashMap的value,将此对象定义为static final。
private static final Object PRESENT = new Object(); /**
* 默认的无参构造器,构造一个空的HashSet。
*
* 实际底层会初始化一个空的HashMap,并使用默认初始容量为16和加载因子0.75。
*/
public HashSet() {
map = new HashMap<E,Object>();
} /**
* 构造一个包含指定collection中的元素的新set。
*
* 实际底层使用默认的加载因子0.75和足以包含指定
* collection中所有元素的初始容量来创建一个HashMap。
* @param c 其中的元素将存放在此set中的collection。
*/
public HashSet(Collection<? extends E> c) {
map = new HashMap<E,Object>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
} /**
* 以指定的initialCapacity和loadFactor构造一个空的HashSet。
*
* 实际底层以相应的参数构造一个空的HashMap。
* @param initialCapacity 初始容量。
* @param loadFactor 加载因子。
*/
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<E,Object>(initialCapacity, loadFactor);
} /**
* 以指定的initialCapacity构造一个空的HashSet。
*
* 实际底层以相应的参数及加载因子loadFactor为0.75构造一个空的HashMap。
* @param initialCapacity 初始容量。
*/
public HashSet(int initialCapacity) {
map = new HashMap<E,Object>(initialCapacity);
} /**
* 以指定的initialCapacity和loadFactor构造一个新的空链接哈希集合。
* 此构造函数为包访问权限,不对外公开,实际只是是对LinkedHashSet的支持。
*
* 实际底层会以指定的参数构造一个空LinkedHashMap实例来实现。
* @param initialCapacity 初始容量。
* @param loadFactor 加载因子。
* @param dummy 标记。
*/
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<E,Object>(initialCapacity, loadFactor);
} /**
* 返回对此set中元素进行迭代的迭代器。返回元素的顺序并不是特定的。
*
* 底层实际调用底层HashMap的keySet来返回所有的key。
* 可见HashSet中的元素,只是存放在了底层HashMap的key上,
* value使用一个static final的Object对象标识。
* @return 对此set中元素进行迭代的Iterator。
*/
public Iterator<E> iterator() {
return map.keySet().iterator();
} /**
* 返回此set中的元素的数量(set的容量)。
*
* 底层实际调用HashMap的size()方法返回Entry的数量,就得到该Set中元素的个数。
* @return 此set中的元素的数量(set的容量)。
*/
public int size() {
return map.size();
} /**
* 如果此set不包含任何元素,则返回true。
*
* 底层实际调用HashMap的isEmpty()判断该HashSet是否为空。
* @return 如果此set不包含任何元素,则返回true。
*/
public boolean isEmpty() {
return map.isEmpty();
} /**
* 如果此set包含指定元素,则返回true。
* 更确切地讲,当且仅当此set包含一个满足(o==null ? e==null : o.equals(e))
* 的e元素时,返回true。
*
* 底层实际调用HashMap的containsKey判断是否包含指定key。
* @param o 在此set中的存在已得到测试的元素。
* @return 如果此set包含指定元素,则返回true。
*/
public boolean contains(Object o) {
return map.containsKey(o);
} /**
* 如果此set中尚未包含指定元素,则添加指定元素。
* 更确切地讲,如果此 set 没有包含满足(e==null ? e2==null : e.equals(e2))
* 的元素e2,则向此set 添加指定的元素e。
* 如果此set已包含该元素,则该调用不更改set并返回false。
*
* 底层实际将将该元素作为key放入HashMap。
* 由于HashMap的put()方法添加key-value对时,当新放入HashMap的Entry中key
* 与集合中原有Entry的key相同(hashCode()返回值相等,通过equals比较也返回true),
* 新添加的Entry的value会将覆盖原来Entry的value,但key不会有任何改变,
* 因此如果向HashSet中添加一个已经存在的元素时,新添加的集合元素将不会被放入HashMap中,
* 原来的元素也不会有任何改变,这也就满足了Set中元素不重复的特性。
* @param e 将添加到此set中的元素。
* @return 如果此set尚未包含指定元素,则返回true。
*/
public boolean add(E e) {
return map.put(e, PRESENT)==null;
} /**
* 如果指定元素存在于此set中,则将其移除。
* 更确切地讲,如果此set包含一个满足(o==null ? e==null : o.equals(e))的元素e,
* 则将其移除。如果此set已包含该元素,则返回true
* (或者:如果此set因调用而发生更改,则返回true)。(一旦调用返回,则此set不再包含该元素)。
*
* 底层实际调用HashMap的remove方法删除指定Entry。
* @param o 如果存在于此set中则需要将其移除的对象。
* @return 如果set包含指定元素,则返回true。
*/
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
} /**
* 从此set中移除所有元素。此调用返回后,该set将为空。
*
* 底层实际调用HashMap的clear方法清空Entry中所有元素。
*/
public void clear() {
map.clear();
} /**
* 返回此HashSet实例的浅表副本:并没有复制这些元素本身。
*
* 底层实际调用HashMap的clone()方法,获取HashMap的浅表副本,并设置到 HashSet中。
*/
public Object clone() {
try {
HashSet<E> newSet = (HashSet<E>) super.clone();
newSet.map = (HashMap<E, Object>) map.clone();
return newSet;
} catch (CloneNotSupportedException e) {
throw new InternalError();
}
}
}
由于HashSet底层使用了HashMap实现,使其的实现过程变得非常简单,如果你对HashMap比较了解,那么HashSet简直是小菜一碟。有两个方法对HashMap和HashSet而言是非常重要的,请注意正确重写其 equals 和 hashCode 方法,以保证放入的对象的唯一性。这两个方法是比较重要的,希望大家在以后的开发过程中需要注意一下。
JAVA提高十四:HashSet深入分析的更多相关文章
- JAVA提高十:ArrayList 深入分析
前面一章节,我们介绍了集合的类图,那么本节将学习Collection 接口中最常用的子类ArrayList类,本章分为下面几部分讲解(说明本章采用的JDK1.6源码进行分析,因为个人认为虽然JDK1. ...
- “全栈2019”Java第九十四章:局部内部类详解
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- “全栈2019”Java第十四章:二进制、八进制、十六进制
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- “全栈2019”Java第二十四章:流程控制语句中决策语句switch下篇
难度 初级 学习时间 10分钟 适合人群 零基础 开发语言 Java 开发环境 JDK v11 IntelliJ IDEA v2018.3 文章原文链接 "全栈2019"Java第 ...
- JAVA提高十九:WeakHashMap&EnumMap&LinkedHashMap&LinkedHashSet深入分析
因为最近工作太忙了,连续的晚上支撑和上班,因此没有精力来写下这篇博客,今天上午正好有一点空,因此来复习一下不太常用的集合体系大家族中的几个类:WeakHashMap&EnumMap&L ...
- java提高篇(四)-----理解java的三大特性之多态
面向对象编程有三大特性:封装.继承.多态. 封装隐藏了类的内部实现机制,可以在不影响使用的情况下改变类的内部结构,同时也保护了数据.对外界而已它的内部细节是隐藏的,暴露给外界的只是它的访问方法. 继承 ...
- JAVA提高十二:HashMap深入分析
首先想说的是关于HashMap源码的分析园子里面应该有很多,并且都是分析得很不错的文章,但是我还是想写出自己的学习总结,以便加深自己的理解,因此就有了此文,另外因为小孩过来了,因此更新速度可能放缓了, ...
- Java提高十五:容器元素比较Comparable&Comparator深入分析
我们经常用容器来存放元素,通常而言我们是不关系容器中的元素是否有序,但有些场景可能要求容器中的元素是有序的,这个时候用ArrayList LinkedList Hashtable HashMap ...
- Java提高十六:TreeMap深入分析
上一篇容器元素比较Comparable&Comparator分析的时候,我们提到了TreeMap,但没有去细致分析它,只是说明其在添加元素的时候可以进行比较,从而使得集合有序,但是怎么做的呢? ...
随机推荐
- python模拟登陆 pixiv
##---author:wuhao##在QQ群看到有群友在模拟登陆 pivix.cn 这个网站,闲来无事,我也写了一个测试一下,起初我把它想的复杂了,认为我需要获取服务器返回过来的Set-Cookie ...
- 【转载】CSS3 filter:drop-shadow滤镜与box-shadow区别应用
文章转载自 张鑫旭-鑫空间-鑫生活 http://www.zhangxinxu.com/wordpress/ 原文链接:http://www.zhangxinxu.com/wordpress/?p=5 ...
- mysql分表场景分析与简单分表操作
为什么要分表 首先要知道什么情况下,才需要分表个人觉得单表记录条数达到百万到千万级别时就要使用分表了,分表的目的就在于此,减小数据库的负担,缩短查询时间. 表分割有两种方式: 1水平分割:根据一列或多 ...
- Java限流策略
概要 在大数据量高并发访问时,经常会出现服务或接口面对暴涨的请求而不可用的情况,甚至引发连锁反映导致整个系统崩溃.此时你需要使用的技术手段之一就是限流,当请求达到一定的并发数或速率,就进行等待.排队. ...
- CURL常用命令记录--用于简单测试接口
curl命令是一个利用URL规则在命令行下工作的文件传输工具.它支持文件的上传和下载,所以是综合传输工具,但按传统,习惯称curl为下载工具.作为一款强力工具,curl支持包括HTTP.HTTPS.f ...
- RandomAccessFile类进行文件加密
文件加密/解密示例. package io; import java.io.*; public class encrypt { private File file; //存储文件对象信息 byte[] ...
- xmanager 打开centos7图形化窗口
centos7 最小化安装后,个别时候需要执行一些带图形界面的命令.比如安装oracle,打开xclock等. 前置条件:centos7系统 ,xmanager 已安装 用xclock做测试 1.因为 ...
- swift之函数式编程(二)
本文的主要内容来自<Functional Programming in Swift>这本书,有点所谓的观后总结 在本书的Introduction章中: we will try to foc ...
- trait与policy模板应用简单示例
trait与policy模板应用简单示例 accumtraits.hpp // 累加算法模板的trait // 累加算法模板的trait #ifndef ACCUMTRAITS_HPP #define ...
- 原生JS实现图片放大镜插件
前 言 我们大家经常逛各种电商类的网站,商品的细节就需要用到放大镜,这个大家一定不陌生,今天我们就做一个图片放大镜的插件,来看看图片是如何被放大的…… 先看一下我们要是实现的最终效果是怎么样的 ...