多模字符串匹配算法之AC自动机—原理与实现
简介:
本文是博主自身对AC自动机的原理的一些理解和看法,主要以举例的方式讲解,同时又配以相应的图片。代码实现部分也予以明确的注释,希望给大家不一样的感受。AC自动机主要用于多模式字符串的匹配,本质上是KMP算法的树形扩展。这篇文章主要介绍AC自动机的工作原理,并在此基础上用Java代码实现一个简易的AC自动机。
欢迎探讨,如有错误敬请指正
如需转载,请注明出处 http://www.cnblogs.com/nullzx/
1. 应用场景—多模字符串匹配
我们现在考虑这样一个问题,在一个文本串text中,我们想找出多个目标字符串target1,target2,……出现的次数和位置。例如:求出目标字符串集合{"nihao","hao","hs","hsr"}在给定文本"sdmfhsgnshejfgnihaofhsrnihao"中所有可能出现的位置。解决这个问题,我们一般的办法就是在文本串中对每个目标字符串单独查找,并记录下每次出现的位置。显然这样的方式能够解决问题,但是在文本串较大、目标字符串众多的时候效率比较低。为了提高效率,贝尔实验室于1975年发明著名的多模字符串匹配算法——AC自动机。AC自动机在实现上要依托于Trie树(也称字典树)并借鉴了KMP模式匹配算法的核心思想。实际上你可以把KMP算法看成每个节点都仅有一个孩子节点的AC自动机。
2. AC自动机及其运行原理
2.1 初识AC自动机
AC自动机的基础是Trie树。和Trie树不同的是,树中的每个结点除了有指向孩子的指针(或者说引用),还有一个fail指针,它表示输入的字符与当前结点的所有孩子结点都不匹配时(注意,不是和该结点本身不匹配),自动机的状态应转移到的状态(或者说应该转移到的结点)。fail指针的功能可以类比于KMP算法中next数组的功能。
我们现在来看一个用目标字符串集合{abd,abdk, abchijn, chnit, ijabdf, ijaij}构造出来的AC自动机
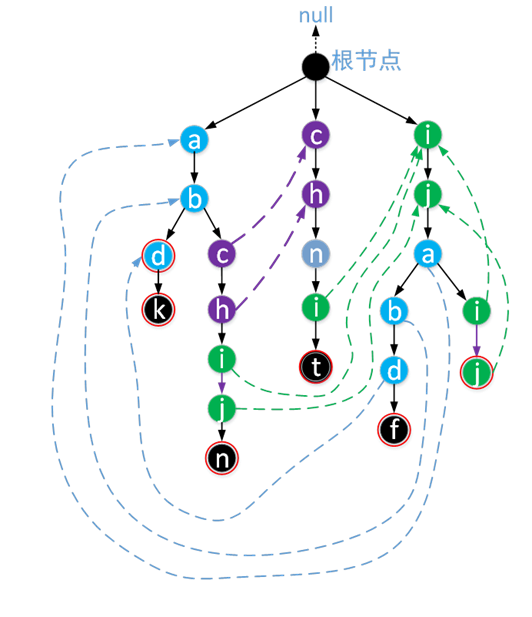
上图是一个构建好的AC自动机,其中根结点不存储任何字符,根结点的fail指针为null。虚线表示该结点的fail指针的指向,所有表示字符串的最后一个字符的结点外部都用红圈表示,我们称该结点为这个字符串的终结结点。每个结点实际上都有fail指针,但为了表示方便,本文约定一个原则,即所有指向根结点的 fail虚线都未画出。
从上图中的AC自动机,我们可以看出一个重要的性质:每个结点的fail指针表示由根结点到该结点所组成的字符序列的所有后缀 和 整个目标字符串集合(也就是整个Trie树)中的所有前缀 两者中最长公共的部分。
比如图中,由根结点到目标字符串“ijabdf”中的 ‘d’组成的字符序列“ijabd”的所有后缀在整个目标字符串集{abd,abdk, abchijn, chnit, ijabdf, ijaij}的所有前缀中最长公共的部分就是abd,而图中d结点(字符串“ijabdf”中的这个d)的fail正是指向了字符序列abd的最后一个字符。
2.2 AC自动机的运行过程:
1)表示当前结点的指针指向AC自动机的根结点,即curr = root
2)从文本串中读取(下)一个字符
3)从当前结点的所有孩子结点中寻找与该字符匹配的结点,
若成功:判断当前结点以及当前结点fail指向的结点是否表示一个字符串的结束,若是,则将文本串中索引起点记录在对应字符串保存结果集合中(索引起点= 当前索引-字符串长度+1)。curr指向该孩子结点,继续执行第2步
若失败:执行第4步。
4)若fail == null(说明目标字符串中没有任何字符串是输入字符串的前缀,相当于重启状态机)curr = root, 执行步骤2,
否则,将当前结点的指针指向fail结点,执行步骤3)
现在,我们来一个具体的例子加深理解,初始时当前结点为root结点,我们现在假设文本串text = “abchnijabdfk”。

图中的实曲线表示了整个搜索过程中的当前结点指针的转移过程,结点旁的文字表示了当前结点下读取的文本串字符。比如初始时,当前指针指向根结点时,输入字符‘a’,则当前指针指向结点a,此时再输入字符‘b’,自动机状态转移到结点b,……,以此类推。图中AC自动机的最后状态只是恰好回到根结点。
需要说明的是,当指针位于结点b(图中曲线经过了两次b,这里指第二次的b,即目标字符串“ijabdf”中的b),这时读取文本串字符下标为9的字符(即‘d’)时,由于b的所有孩子结点(这里恰好只有一个孩子结点)中存在能够匹配输入字符d的结点,那么当前结点指针就指向了结点d,而此时该结点d的fail指针指向的结点又恰好表示了字符串“abc”的终结结点(用红圈表示),所以我们找到了目标字符串“abc”一次。这个过程我们在图中用虚线表示,但状态没有转移到“abd”中的d结点。
在输入完所有文本串字符后,我们在文本串中找到了目标字符串集合中的abd一次,位于文本串中下标为7的位置;目标字符串ijabdf一次,位于文本串中下标为5的位置。
3. 构造AC自动机的方法与原理
3.1 构造的基本方法
首先我们将所有的目标字符串插入到Trie树中,然后通过广度优先遍历为每个结点的所有孩子节点的fail指针找到正确的指向。
确定fail指针指向的问题和KMP算法中构造next数组的方式如出一辙。具体方法如下
1)将根结点的所有孩子结点的fail指向根结点,然后将根结点的所有孩子结点依次入列。
2)若队列不为空:
2.1)出列,我们将出列的结点记为curr, failTo表示curr的fail指向的结点,即failTo = curr.fail
2.2) a.判断curr.child[i] == failTo.child[i]是否成立,
成立:curr.child[i].fail = failTo.child[i],
不成立:判断 failTo == null是否成立
成立: curr.child[i].fail == root
不成立:执行failTo = failTo.fail,继续执行2.2)
b.curr.child[i]入列,再次执行再次执行步骤2)
若队列为空:结束
3.2 通过一个例子来理解构造AC自动机的原理
每个结点fail指向的解决顺序是按照广度优先遍历的顺序完成的,或者说层序遍历的顺序进行的,也就是说我们是在解决当前结点的孩子结点fail的指向时,当前结点的fail指针一定已指向了正确的位置。
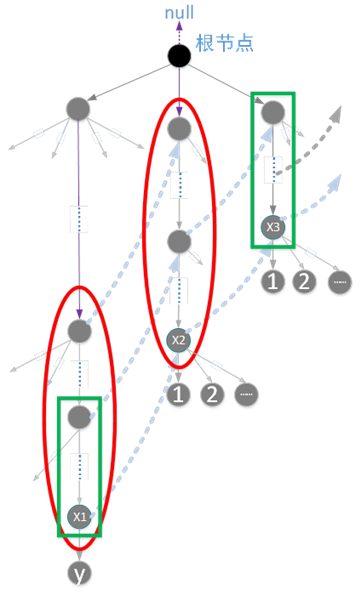
为了说明问题,我们再次强调“每个结点的fail指针表示:由根结点到该结点所组成的字符序列的所有后缀 和 整个目标字符串集合(也就是整个Trie树)中的所有前缀 两者中最长公共的部分”。
以上图所示为例,我们要解决结点x1的某个孩子结点y的fail的指向问题。已知x1.fail指向x2,依据x1结点的fail指针的含义,我们可知红色实线椭圆框内的字符序列必然相等,且表示了最长公共部分。依据y.fail的含义,如果x2的某个孩子结点和结点y表示的字符相等,那么y.fail就该指向它。
如果x2的孩子结点中不存在结点y表示的字符,这个时候该怎么办?由于x2.fail指向x3,根据x2.fail的含义,我们可知绿色方框内的字符序列必然相等。显然,如果x3的某个孩子结点和结点y表示的字符相等,那么y.fail就该指向它。
如果x3的孩子结点中不存在结点y表示的字符,我们可以依次重复这个步骤,直到xi结点的fail指向null,这时说明我们已经到了最顶层的根结点,这时,我们只需要让y.fail = root即可。
构造的过程的核心本质就是,已知当前结点的最长公共前缀的前提下,去确定孩子结点的最长公共前缀。这完全可以类比于KMP算法的next数组的求解过程。
3.2.1 确定图中h结点fail指向的过程
现在我们假设我们要确定图中结点c的孩子结点h的fail指向。图中每个结点都应该有表示fail的虚线,但为了表示方便,按照本文约定的原则,所有指向根结点的 fail虚线均未画出。


左图表示h.fail确定之前, 右图表示h.fail确定之后
左图中,蓝色实线框住的结点的fail都已确定。现在我们应该怎样找到h.fail的正确指向?由于且结点c的fail已知(c结点为h结点的父结点),且指向了Trie树中所有前缀与字符序列‘a’‘b’‘c’的所有后缀(“bc”和“c”)的最长公共部分。现在我们要解决的问题是目标字符串集合的所有前缀中与字符序列‘a’‘b’‘c’ ‘h’的所有后缀的最长公共部分。显然c.fail指向的结点的孩子结点中存在结点h,那么h.fail就应该指向c.fail的孩子结点h,所以右图表示了h.fail确定后的情况。
3.2.2 确定图中i.fail指向的过程
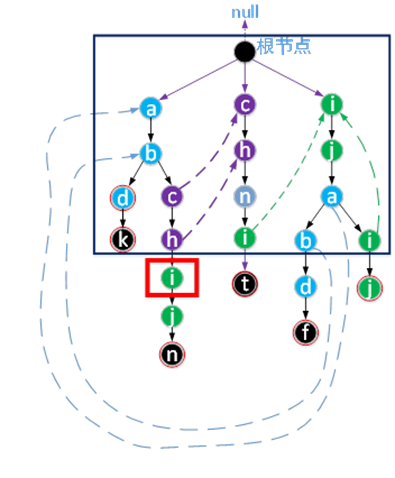

左图表示i.fail确定之前, 右图表示i.fail确定之后
确定i.fail的指向时,显然h.fail(h指图中i的父结点的那个h)已指向了正确的位置。也就是说我们现在知道了目标字符串集合所有前缀中与字符序列‘a’‘b’‘c’ ‘h’的所有后缀在Trie树中的最长前缀是‘c’‘h’。显然从图中可知h.fail的孩子结点是没有i结点(这里h.fail只有一个孩子结点n)。字符序列‘c’‘h’的所有后缀在Trie树中的最长前缀可由h.fail的fail得到,而h.fail的fail指向root(依据本博客中画图的原则,这条fail虚线并未画出),root的孩子结点中存在表示字符i的结点,所以结果如右图所示。
在知道i.fail的情况下,大家可以尝试在纸上画出j.fail的指向,以加深AC自动机构造过程的理解。
4. AC自动机的java代码实现
package datastruct; import java.util.ArrayList;
import java.util.HashMap;
import java.util.LinkedList;
import java.util.List;
import java.util.Map.Entry; public class AhoCorasickAutomation {
/*本示例中的AC自动机只处理英文类型的字符串,所以数组的长度是128*/
private static final int ASCII = 128; /*AC自动机的根结点,根结点不存储任何字符信息*/
private Node root; /*待查找的目标字符串集合*/
private List<String> target; /*表示在文本字符串中查找的结果,key表示目标字符串, value表示目标字符串在文本串出现的位置*/
private HashMap<String, List<Integer>> result; /*内部静态类,用于表示AC自动机的每个结点,在每个结点中我们并没有存储该结点对应的字符*/
private static class Node{ /*如果该结点是一个终点,即,从根结点到此结点表示了一个目标字符串,则str != null, 且str就表示该字符串*/
String str; /*ASCII == 128, 所以这里相当于128叉树*/
Node[] table = new Node[ASCII]; /*当前结点的孩子结点不能匹配文本串中的某个字符时,下一个应该查找的结点*/
Node fail; public boolean isWord(){
return str != null;
} } /*target表示待查找的目标字符串集合*/
public AhoCorasickAutomation(List<String> target){
root = new Node();
this.target = target;
buildTrieTree();
build_AC_FromTrie();
} /*由目标字符串构建Trie树*/
private void buildTrieTree(){
for(String targetStr : target){
Node curr = root;
for(int i = 0; i < targetStr.length(); i++){
char ch = targetStr.charAt(i);
if(curr.table[ch] == null){
curr.table[ch] = new Node();
}
curr = curr.table[ch];
}
/*将每个目标字符串的最后一个字符对应的结点变成终点*/
curr.str = targetStr;
}
} /*由Trie树构建AC自动机,本质是一个自动机,相当于构建KMP算法的next数组*/
private void build_AC_FromTrie(){
/*广度优先遍历所使用的队列*/
LinkedList<Node> queue = new LinkedList<Node>(); /*单独处理根结点的所有孩子结点*/
for(Node x : root.table){
if(x != null){
/*根结点的所有孩子结点的fail都指向根结点*/
x.fail = root;
queue.addLast(x);/*所有根结点的孩子结点入列*/
}
} while(!queue.isEmpty()){
/*确定出列结点的所有孩子结点的fail的指向*/
Node p = queue.removeFirst();
for(int i = 0; i < p.table.length; i++){
if(p.table[i] != null){
/*孩子结点入列*/
queue.addLast(p.table[i]);
/*从p.fail开始找起*/
Node failTo = p.fail;
while(true){
/*说明找到了根结点还没有找到*/
if(failTo == null){
p.table[i].fail = root;
break;
} /*说明有公共前缀*/
if(failTo.table[i] != null){
p.table[i].fail = failTo.table[i];
break;
}else{/*继续向上寻找*/
failTo = failTo.fail;
}
}
}
}
}
} /*在文本串中查找所有的目标字符串*/
public HashMap<String, List<Integer>> find(String text){
/*创建一个表示存储结果的对象*/
result = new HashMap<String, List<Integer>>();
for(String s : target){
result.put(s, new LinkedList<Integer>());
} Node curr = root;
int i = 0;
while(i < text.length()){
/*文本串中的字符*/
char ch = text.charAt(i); /*文本串中的字符和AC自动机中的字符进行比较*/
if(curr.table[ch] != null){
/*若相等,自动机进入下一状态*/
curr = curr.table[ch]; if(curr.isWord()){
result.get(curr.str).add(i - curr.str.length()+1);
} /*这里很容易被忽视,因为一个目标串的中间某部分字符串可能正好包含另一个目标字符串,
* 即使当前结点不表示一个目标字符串的终点,但到当前结点为止可能恰好包含了一个字符串*/
if(curr.fail != null && curr.fail.isWord()){
result.get(curr.fail.str).add(i - curr.fail.str.length()+1);
} /*索引自增,指向下一个文本串中的字符*/
i++;
}else{
/*若不等,找到下一个应该比较的状态*/
curr = curr.fail; /*到根结点还未找到,说明文本串中以ch作为结束的字符片段不是任何目标字符串的前缀,
* 状态机重置,比较下一个字符*/
if(curr == null){
curr = root;
i++;
}
}
}
return result;
} public static void main(String[] args){
List<String> target = new ArrayList<String>();
target.add("abcdef");
target.add("abhab");
target.add("bcd");
target.add("cde");
target.add("cdfkcdf"); String text = "bcabcdebcedfabcdefababkabhabk"; AhoCorasickAutomation aca = new AhoCorasickAutomation(target);
HashMap<String, List<Integer>> result = aca.find(text); System.out.println(text);
for(Entry<String, List<Integer>> entry : result.entrySet()){
System.out.println(entry.getKey()+" : " + entry.getValue());
} }
}
运行结果如下,从结果中我们可以看出文本串中bcd出现了二次,分别是文本串下标为3和下标为13的位置,……。
bcabcdebcedfabcdefababkabhabk
bcd : [3, 13]
cdfkcdf : []
cde : [4, 14]
abcdef : [12]
abhab : [23]
5. 参考内容
[1] AC自动机算法
多模字符串匹配算法之AC自动机—原理与实现的更多相关文章
- 【字符串算法】AC自动机
国庆后面两天划水,甚至想接着发出咕咕咕的叫声.咳咳咳,这些都不重要!最近学习了一下AC自动机,发现其实远没有想象中的那么难. AC自动机的来历 我知道,很多人在第一次看到这个东西的时侯是非常兴奋的.( ...
- 多模字符串匹配算法-Aho–Corasick
背景 在做实际工作中,最简单也最常用的一种自然语言处理方法就是关键词匹配,例如我们要对n条文本进行过滤,那本身是一个过滤词表的,通常进行过滤的代码如下 for (String document : d ...
- Aho-Corasick 多模式匹配算法、AC自动机详解
Aho-Corasick算法是多模式匹配中的经典算法,目前在实际应用中较多. Aho-Corasick算法对应的数据结构是Aho-Corasick自动机,简称AC自动机. 搞编程的一般都应该知道自动机 ...
- Codeforces963C Frequency of String 【字符串】【AC自动机】
题目大意: 给一个串s和很多模式串,对每个模式串求s的一个最短的子串使得这个子串中包含至少k个该模式串. 题目分析: 均摊分析,有sqrt(n)种长度不同的模式串,所以有关的串只有msqrt(n)种. ...
- 【字符串处理】AC自动机知识点&代码
代码: #include<iostream> #include<vector> #include<cstdio> #include<queue> #in ...
- [Alg] 文本匹配-多模匹配-AC自动机
1. 简介 AC自动机是一种多模匹配的文本匹配算法. 如果采用naive的方法,即依次比较文本串s中是否包含模式串p1, p2,...非常耗时.考虑到这些模式串中可能具有相同子串,可以利用已经比较过的 ...
- 浅析 AC 自动机
目录 简述 AC 自动机是什么 AC 自动机有什么用 AC 自动机·初探 AC 自动机·原理分析 AC 自动机·代码实现 AC 自动机·更进一步 第一题 第二题 第三题 从 AC 自动机到 fail ...
- 算法模板——AC自动机
实现功能——输入N,M,提供一个共计N个单词的词典,然后在最后输入的M个字符串中进行多串匹配(关于AC自动机算法,此处不再赘述,详见:Aho-Corasick 多模式匹配算法.AC自动机详解.考虑到有 ...
- AC自动机算法详解 (转载)
首先简要介绍一下AC自动机:Aho-Corasick automation,该算法在1975年产生于贝尔实验室,是著名的多模匹配算法之一.一个常见的例子就是给出n个单词,再给出一段包含m个字符的文章, ...
随机推荐
- Java 9 揭秘(19. 平台和JVM日志)
Tips 做一个终身学习的人. 在这章中,主要介绍以下内容: 新的平台日志(logging)API JVM日志的命令行选项 JDK 9已经对平台类(JDK类)和JVM组件的日志系统进行了大整. 有一个 ...
- DDD理论学习系列(12)-- 仓储
DDD理论学习系列--案例及目录 1. 引言 DDD中Repository这个单词,主要有两种翻译:资源库和仓储,本文取仓储之译. 说到仓储,我们肯定就想到了仓库,仓库一般用来存放货物,而仓库一般由仓 ...
- LigerUI LigerGrid getSelectedRows() 多选顺序 不是从上到下修改方法
1.问题 LigreGrid内部是选中一个,往selected里塞一个, 当执行getSelectedRows() 的时候,会把selected以选中的顺序,返回出来,所以是按照选择顺序返回. 原生代 ...
- 学生问的一道javascript面试题[来自腾讯]
function Parent() { this.a = 1; this.b = [1, 2, this.a]; this.c = { demo: 5 }; this.show = function ...
- 第二棵树:Splay
Splay这东西神难打--什么都没动板子敲上就直逼200行了,而且非常难记(仿佛是模板长的必然结果).但是为什么还要学呢?据说是因为它可以实现区间操作.但是自从我得知无旋Treap也能做到这些,默默对 ...
- 【.net 深呼吸】导出 Office 文档中的图片
我们常用的 Office 文档其实就三种——Word.Excel.PowerPoint,分别对应的扩展名为:.docx..pptx..xlsx. 许多教程都告诉我们,要提取这些文件中的图片(其实像视频 ...
- NYOJ--541--最强DE 战斗力(递推)
最强DE 战斗力 时间限制:1000 ms | 内存限制:65535 KB 难度:3 描述 春秋战国时期,赵国地大物博,资源非常丰富,人民安居乐业.但许多国家对它虎视眈眈,准备联合起来对赵国发 ...
- C#使用Xamarin开发可移植移动应用(2.Xamarin.Forms布局,本篇很长,注意)附源码
前言 系列目录 C#使用Xamarin开发可移植移动应用目录 源码地址:https://github.com/l2999019/DemoApp 可以Star一下,随意 - - 一点感想 很意外的,第一 ...
- Nodejs package.json文件介绍
每个npm的安装包里面都会包含一个package.json,通常这个文件会在包的根目录下. 这个文件很类似于.net项目中的.csproj+AssemblyInfo.cs+App.config文件,主 ...
- Activity中finish()和onDestroy()的区别
finish()方法用于结束一个Activity的生命周期,而onDestory()方法则是Activity的一个生命周期方法,其作用是在一个Activity对象被销毁之前,Android系统会调用该 ...