python爬取大众点评并写入mongodb数据库和redis数据库
抓取大众点评首页左侧信息,如图:
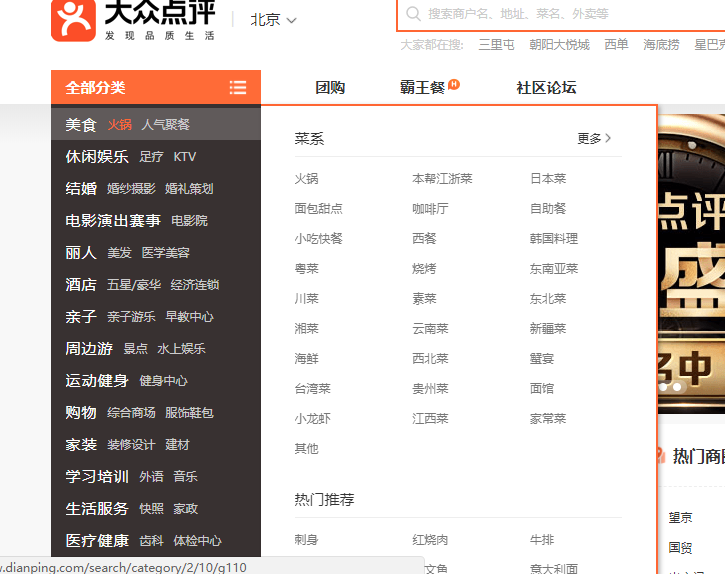
我们要实现把中文名字都存到mongodb,而每个链接存入redis数据库。
因为将数据存到mongodb时每一个信息都会有一个对应的id,那样就方便我们存入redis可以不出错。
# -*- coding: utf-8 -*-
import re
from urllib.request import urlopen
from urllib.request import Request
from bs4 import BeautifulSoup
from lxml import etree
import pymongo client = pymongo.MongoClient(host="127.0.0.1")
db = client.dianping #库名dianping
collection = db.classification #表名classification import redis #导入redis数据库
r = redis.Redis(host='127.0.0.1', port=6379, db=0) # client = pymongo.MongoClient(host="192.168.60.112")
# myip = client['myip'] # 给数据库命名
def secClassFind(selector, classid):
secItems = selector.xpath('//div[@class="sec-items"]/a')
for secItem in secItems:
url = secItem.get('href') #得到url
title = secItem.text
classid = collection.insert({'classname': title, 'pid': classid})
classurl = '%s,%s' % (classid, url) #拼串
r.lpush('classurl', classurl) #入库 def Public(url):
headers = {'User-Agent': 'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6'} #协议头
req_timeout = 5
req = Request(url=url, headers=headers)
f = urlopen(req, None, req_timeout)
s = f.read()
s = s.decode("utf-8")
# beautifulsoup提取
soup = BeautifulSoup(s, 'html.parser')
links = soup.find_all(name='li', class_="first-item")
for link in links:
selector = etree.HTML(str(link))
# indexTitleUrls = selector.xpath('//a[@class="index-title"]/@href')
# # 获取一级类别url和title
# for titleurl in indexTitleUrls:
# print(titleurl)
indexTitles = selector.xpath('//a[@class="index-title"]/text()')
for title in indexTitles:
# 第二级url
print(title)
classid = collection.insert({'classname': title, 'pid': None})
secClassFind(selector, classid)
print('---------')
# secItems = selector.xpath('//div[@class="sec-items"]/a')
# for secItem in secItems:
# print(secItem.get('href'))
# print(secItem.text)
print('-----------------------------')
#
# myip.collection.insert({'name':secItem.text})
# r.lpush('mylist', secItem.get('href')) # collection.find_one({'_id': ObjectId('5a14c8916d123842bcea5835')}) # connection = pymongo.MongoClient(host="192.168.60.112") # 连接MongDB数据库 # post_info = connection.myip # 指定数据库名称(yande_test),没有则创建
# post_sub = post_info.test # 获取集合名:test
Public('http://www.dianping.com/')
python爬取大众点评并写入mongodb数据库和redis数据库的更多相关文章
- python爬取大众点评
拖了好久的代码 1.首先进入页面确定自己要抓取的数据(我们要抓取的是左侧分类栏-----包括美食.火锅)先爬取第一级分类(美食.婚纱摄影.电影),之后根据第一级链接爬取第二层(火锅).要注意第二级的p ...
- Python 爬取大众点评 50 页数据,最好吃的成都火锅竟是它!
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 胡萝卜酱 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- 用Python爬取大众点评数据,推荐火锅店里最受欢迎的食品
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:有趣的Python PS:如有需要Python学习资料的小伙伴可以加点 ...
- python爬虫实战---爬取大众点评评论
python爬虫实战—爬取大众点评评论(加密字体) 1.首先打开一个店铺找到评论 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经 ...
- python爬虫爬取大众点评并导入redis
直接上代码,导入redis的中文编码没有解决,日后解决了会第一时间上代码!新手上路,多多包涵! # -*- coding: utf-8 -*- import re import requests fr ...
- python 爬取段子网段子写入文件
import requests import re 进入网址 for i in range(1,5): page_url = requests.get(f"http://duanziwang ...
- 利用Python爬取豆瓣电影
目标:使用Python爬取豆瓣电影并保存MongoDB数据库中 我们先来看一下通过浏览器的方式来筛选某些特定的电影: 我们把URL来复制出来分析分析: https://movie.douban.com ...
- Python爬取豆瓣音乐存储MongoDB数据库(Python爬虫实战1)
1. 爬虫设计的技术 1)数据获取,通过http获取网站的数据,如urllib,urllib2,requests等模块: 2)数据提取,将web站点所获取的数据进行处理,获取所需要的数据,常使用的技 ...
- Python:将爬取的网页数据写入Excel文件中
Python:将爬取的网页数据写入Excel文件中 通过网络爬虫爬取信息后,我们一般是将内容存入txt文件或者数据库中,也可以写入Excel文件中,这里介绍关于使用Excel文件保存爬取到的网页数据的 ...
随机推荐
- WCF、WebAPI、WCFREST、WebService之间的区别和选择
转载翻译,原文:http://www.dotnet-tricks.com/Tutorial/webapi/JI2X050413-Difference-between-WCF-and-Web-API-a ...
- DC 辅域转主域
DC 辅域转主域 #dc2辅域 角色转移为主域 #查看 netdom query fsmo ntdsutil roles connections #连接主机dc2 connect to server ...
- javascript面向对象系列第四篇——OOP中的常见概念
前面的话 面向对象描述了一种代码的组织结构形式——一种在软件中对真实世界中问题领域的建模方法.本文将从理论层面,介绍javascript面向对象程序程序(OOP)中一些常见的概念 对象 所谓对象,本质 ...
- java变量和作用域以及成员变量的默认初始化
Java中的变量有成员变量和局部变量,定义在类中方法之外的变量成为成员变量或者成员字段(域),表示一个类所具有的属性,定义为类的成员变量的变量的作用于是整个类,该变量在定义的时候不需要初始化,在使用前 ...
- 浅谈 Integer 类
在讲解 Integer 之前,我们先看下面这段代码: public static void main(String[] args) { Integer i = 10; Integer j = 10; ...
- python 序列:字符串、列表、元组
python 序列:字符串.列表.元组 序列:包含一定顺序排列的对象的一个结构 内建函数:str() list() tuple() 可以使用str(obj)可以把对象obj转换成字符串 list( ...
- nginx HTTP/2.0 配置
1.前言 最近无意中看到http2.0消息,发现自己的博客虽然配了https,但并没有配置http2.0,所以搞了个玩玩,本以为配个参数就搞定了,结果还是折腾了一个小时. 2.过程 nginx并没有默 ...
- Windows和Linux环境下搭建SVN服务器
--------------------------Windows下搭建SVN服务器----------------------------- 一.安装SVN服务端 软件包Setup-Subversi ...
- ArrayList与数组间的转换
关键句:String[] array = (String[])list.toArray(new String[size]); public class Test { public static voi ...
- 赵雅智:service与訪问者之间进行通信,数据交换
服务类 中间人:service服务中的bind对象 创建中间人并通过onBinder方法的return暴露出去 watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQ ...