最近在学习Oracle的统计信息这一块,收集统计信息的方法如下:
DBMS_STATS.GATHER_TABLE_STATS (
ownname VARCHAR2, ---所有者名字
tabname VARCHAR2, ---表名
partname VARCHAR2 DEFAULT NULL, ---要分析的分区名
estimate_percent NUMBER DEFAULT NULL, ---采样的比例
block_sample BOOLEAN DEFAULT FALSE, ---是否块分析
method_opt VARCHAR2 DEFAULT ‘FOR ALL COLUMNS SIZE 1’,---分析的方式
degree NUMBER DEFAULT NULL, ---分析的并行度
granularity VARCHAR2 DEFAULT ‘DEFAULT’, ---分析的粒度
cascade BOOLEAN DEFAULT FALSE, ---是否分析索引
stattab VARCHAR2 DEFAULT NULL, ---使用的性能表名
statid VARCHAR2 DEFAULT NULL, ---性能表标识
statown VARCHAR2 DEFAULT NULL, ---性能表所有者
no_invalidate BOOLEAN DEFAULT FALSE, ---是否验证游标依存关系
force BOOLEAN DEFAULT FALSE); ---强制分析,即使锁表
本文主要对参数granularity进行了一下验证,
granularity:数据分析的力度
--global ---全局
--partition ---只在分区级别做分析
--subpartition --只在子分区级别做分析
验证步骤如下:
一、创建一个分区表并插入两条数据,同时在字段ID上创建索引
drop table test purge;
create table test(id number) partition by range(id)
(partition p1 values less than (5),
partition p2 values less than (10)
) ;
insert into test values(1);
insert into test values(6);
commit;
create index ind_id on test(id);
二、收集表的统计信息
exec dbms_stats.gather_table_stats(user,'TEST',cascade=>true);
三、查询表的统计信息
select num_rows,blocks,last_analyzed from user_tables where table_name = 'TEST';
结果如下:

num_rows:表数据行数
blocks:数据块数
last_analyzed:最近分析时间
四、查询表分区信息
select partition_name,num_rows,blocks,last_analyzed from dba_tab_partitions where table_name ='TEST';

PARTITION_NAME:分区名称
NUM_ROWS:数据行数
BLOCKS:数据块数
last_analyzed:最近分析时间
五、查询索引统计信息
select num_rows,blevel,last_analyzed from user_indexes where index_name = 'IND_ID';

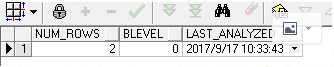
num_rows:索引数据行数
blevel:索引高度
last_analyzed:分析时间
六、新增一个分区
alter table test add partition pmax values less than(maxvalue);
七、往新的分区中插入10000条数据
begin for i in 1..10000 loop ---插入10000条数据
insert into test values(100);
end loop;
commit;
end;
八、创建一个倾斜度非常大的分区
update test set id=10000 where id=100 and rownum=1; ---创造一个非常倾斜的Pmax分区
Commit;
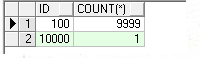
九、查询分区数据
select id,count(*) from test partition(pmax) group by id;
十、不做分析,再次查询表的统计信息
select num_rows,blocks,last_analyzed from user_tables where table_name = 'TEST';
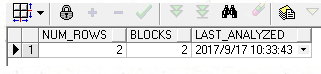
发现数据行数量和数据块数量没有发现变化
十一、查询id=100时执行计划
set autotrace traceonly
set linesize 1000
select * from test where id=100;
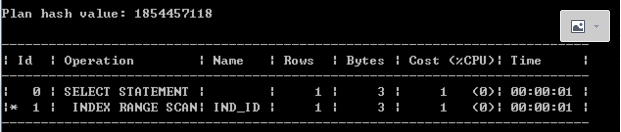
发现走了索引,正常情况下,因为id=100的数据在一个倾斜度非常高的分区pmax中,id为100的数据有9999条,走索引的代价会比走全表的代价还要高(因为走索引需要回表),如果统计信息正确,优化器应该会选择走全表,但是这里没走全表而是走了索引,这里怀疑是统计信息不正确导致,后面验证
十二、收集分区统计信息
exec dbms_stats.gather_table_stats(user,'TEST',partname => 'PMAX',granularity => 'PARTITION');
十三、再次查询表的统计信息和分区统计信息
select partition_name,num_rows,blocks,last_analyzed from dba_tab_partitions where table_name ='TEST';

发现和步骤四比较,分区信息有了变化,说明对分区进行统计信息收集后,分区信息进行了更新
select num_rows,blocks,last_analyzed from user_tables where table_name = 'TEST';

发现和步骤三想比,表的统计信息并没有发生变化,说明统计了分区信息后,表的统计信息么有更新
十四、再次查询id=100的数据

仍然走索引,说明在评估查询的时候,表的统计信息依然陈旧
十五、查询索引的统计信息
select num_rows,blevel,last_analyzed from user_indexes where index_name = 'IND_ID';

发现索引统计信息较步骤五没有变化,说明收集了分区的统计信息后,表的索引信息没有更新
十六、重新再次收集表的统计信息
exec dbms_stats.gather_table_stats(user,'TEST',cascade =>true);
十七、查询表的统计信息以及索引的统计信息
select num_rows,blocks,last_analyzed from user_tables where table_name = 'TEST';

表的统计信息已经更新
select num_rows,blevel,last_analyzed from user_indexes where index_name = 'IND_ID';

索引的统计信息也已经更新
十八、再次查询id=100的执行计划

这次发现走了全表,说明收集了全局的统计信息后,表的统计信息准确了,评估也就准确了。
- Oracle 分区表 收集统计信息 参数granularity
GRANULARITY Determines the granularity of statistics to collect. This value is only relevant for par ...
- ORACLE收集统计信息
1. 理解什么是统计信息 优化器统计信息就是一个更加详细描述数据库和数据库对象的集合,这些统计信息被用于查询优化器,让其为每条SQL语句选择最佳的执行计划.优化器统计信息包括: · ...
- ORACLE 收集统计信息
1. 理解什么是统计信息优化器统计信息就是一个更加详细描述数据库和数据库对象的集合,这些统计信息被用于查询优化器,让其为每条SQL语句选择最佳的执行计划.优化器统计信息包括: · ...
- Oracle收集统计信息的一些思考
一.问题 Oracle在收集统计信息时默认的采样比例是DBMS_STATS.AUTO_SAMPLE_SIZE,那么AUTO_SAMPLE_SIZE的值具体是多少? 假设采样比例为10%,那么在计算单个 ...
- Oracle 收集统计信息11g和12C在差异
Oracle 基于事务临时表11g和12C下,能看到临时表后收集的统计数据,前者记录被清除,后者没有,这是一个很重要的不同. 关于使用企业环境12C,11g,使用暂时表会造成时快时慢.之前我有帖子ht ...
- Oracle重建表索引及手工收集统计信息
Oracle重建所有表的索引的sql: SELECT 'alter index ' || INDEX_NAME || ' rebuild online nologging;' FROM USER_IN ...
- Oracle 手动收集统计信息
收集oracle统计信息 优化器统计范围: 表统计: --行数,块数,行平均长度:all_tables:NUM_ROWS,BLOCKS,AVG_ROW_LEN: 列统计: --列中唯一值的数量(NDV ...
- Oracle 判断 并 手动收集 统计信息 脚本
CREATE OR REPLACE PROCEDURE SchameB.PRC_GATHER_STATS AUTHID CURRENT_USER IS BEGIN SYS.DBMS_STATS.GAT ...
- oracle的统计信息的查看与收集
查看某个表的统计信息 SQL> alter session set NLS_DATE_FORMAT='YYYY-MM-DD HH24:MI:SS'; Session altered. SQL&g ...
随机推荐
- 微信小程序开发之微信支付
微信支付是小程序开发中很重要的一个环节,下面会结合实战进行分析总结 环境准备 https服务器 微信小程序只支持https请求,因此需要配置https的单向认证服务(请参考 另一篇文章https受信证 ...
- Head First 设计模式 第6章 命令模式
第6章 命令模式 在本章,我们将把封装带到一个全新的境界,把方法调用封装起来.没错,通过方法调用,我们可以把运算块包装成型.所以,调用此运算的对象不需要关心运算是如何进行的,只要知道如何使用包装成型的 ...
- 安徽省2016“京胜杯”程序设计大赛_I_恶魔A+B
恶魔A+B Time Limit: 1000 MS Memory Limit: 65536 KB Total Submissions: 73 Accepted: 17 Description 相信大家 ...
- .NET Core 2.0 是您的最好选择吗?
本月14日,微软发布.NET Core 2.0 正式版,它的发布意味着.NET Core平台更加成熟,也预示其更美好的未来.本文将分析.NET Core 的特性以及未来发展方向,为开发人员选择在何种平 ...
- python3 接口测试 一般方法
第一步: 导入相关包 import http.client 第二步: 将ip和端口号,使用如下命令,赋值给变量. conn = http.client.HTTPConnection("124 ...
- axios.js
Vue 原本有一个官方推荐的 ajax 插件 vue-resource,但是自从 Vue 更新到 2.0 之后,官方就不再更新 vue-resource 目前主流的 Vue 项目,都选择 axios ...
- .NET 体系结构(.net core、.net framework、xamarin之间的关系)
这是一张来自官方的图. 图中.NET FRAMEWORK..NET CORE和XAMARIN是三个不同的运行时,这三个运行时在.NET STANDARD LIBRARY之上,它们都包含一些基础的组件, ...
- 零碎的JS基础
一.js的三种弹窗: 警告框 弹出警告alert() 确认框 有确认内容的框confirm()有两个值,true和false 当用户按下确认键后,打印tru ...
- 8.13.2 TreeSet实现Comparable接口的两种方式
推荐使用第二种方式,编写比较器可以使数据类的程序耦合度降低,同时比较器也可以重复利用! 第一种方式:数据类实现Comparable接口,实现其中的compareTo方法 创建对象时,使用TreeSet ...
- Android笔记: 播放提示音 的简单方法
public static void sendSound(Context mContext) { //上下文 Uri mUri= RingtoneManager.getDefaultUri(Ringt ...