最近在学习Oracle的统计信息这一块,收集统计信息的方法如下:
DBMS_STATS.GATHER_TABLE_STATS (
ownname VARCHAR2, ---所有者名字
tabname VARCHAR2, ---表名
partname VARCHAR2 DEFAULT NULL, ---要分析的分区名
estimate_percent NUMBER DEFAULT NULL, ---采样的比例
block_sample BOOLEAN DEFAULT FALSE, ---是否块分析
method_opt VARCHAR2 DEFAULT ‘FOR ALL COLUMNS SIZE 1’,---分析的方式
degree NUMBER DEFAULT NULL, ---分析的并行度
granularity VARCHAR2 DEFAULT ‘DEFAULT’, ---分析的粒度
cascade BOOLEAN DEFAULT FALSE, ---是否分析索引
stattab VARCHAR2 DEFAULT NULL, ---使用的性能表名
statid VARCHAR2 DEFAULT NULL, ---性能表标识
statown VARCHAR2 DEFAULT NULL, ---性能表所有者
no_invalidate BOOLEAN DEFAULT FALSE, ---是否验证游标依存关系
force BOOLEAN DEFAULT FALSE); ---强制分析,即使锁表
本文主要对参数granularity进行了一下验证,
granularity:数据分析的力度
--global ---全局
--partition ---只在分区级别做分析
--subpartition --只在子分区级别做分析
验证步骤如下:
一、创建一个分区表并插入两条数据,同时在字段ID上创建索引
drop table test purge;
create table test(id number) partition by range(id)
(partition p1 values less than (5),
partition p2 values less than (10)
) ;
insert into test values(1);
insert into test values(6);
commit;
create index ind_id on test(id);
二、收集表的统计信息
exec dbms_stats.gather_table_stats(user,'TEST',cascade=>true);
三、查询表的统计信息
select num_rows,blocks,last_analyzed from user_tables where table_name = 'TEST';
结果如下:

num_rows:表数据行数
blocks:数据块数
last_analyzed:最近分析时间
四、查询表分区信息
select partition_name,num_rows,blocks,last_analyzed from dba_tab_partitions where table_name ='TEST';

PARTITION_NAME:分区名称
NUM_ROWS:数据行数
BLOCKS:数据块数
last_analyzed:最近分析时间
五、查询索引统计信息
select num_rows,blevel,last_analyzed from user_indexes where index_name = 'IND_ID';

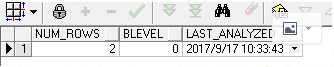
num_rows:索引数据行数
blevel:索引高度
last_analyzed:分析时间
六、新增一个分区
alter table test add partition pmax values less than(maxvalue);
七、往新的分区中插入10000条数据
begin for i in 1..10000 loop ---插入10000条数据
insert into test values(100);
end loop;
commit;
end;
八、创建一个倾斜度非常大的分区
update test set id=10000 where id=100 and rownum=1; ---创造一个非常倾斜的Pmax分区
Commit;
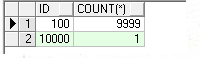
九、查询分区数据
select id,count(*) from test partition(pmax) group by id;
十、不做分析,再次查询表的统计信息
select num_rows,blocks,last_analyzed from user_tables where table_name = 'TEST';
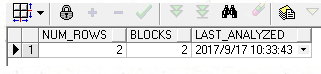
发现数据行数量和数据块数量没有发现变化
十一、查询id=100时执行计划
set autotrace traceonly
set linesize 1000
select * from test where id=100;
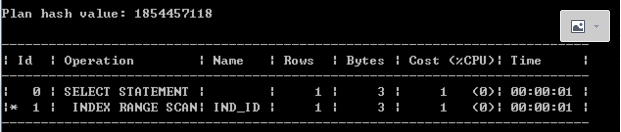
发现走了索引,正常情况下,因为id=100的数据在一个倾斜度非常高的分区pmax中,id为100的数据有9999条,走索引的代价会比走全表的代价还要高(因为走索引需要回表),如果统计信息正确,优化器应该会选择走全表,但是这里没走全表而是走了索引,这里怀疑是统计信息不正确导致,后面验证
十二、收集分区统计信息
exec dbms_stats.gather_table_stats(user,'TEST',partname => 'PMAX',granularity => 'PARTITION');
十三、再次查询表的统计信息和分区统计信息
select partition_name,num_rows,blocks,last_analyzed from dba_tab_partitions where table_name ='TEST';

发现和步骤四比较,分区信息有了变化,说明对分区进行统计信息收集后,分区信息进行了更新
select num_rows,blocks,last_analyzed from user_tables where table_name = 'TEST';

发现和步骤三想比,表的统计信息并没有发生变化,说明统计了分区信息后,表的统计信息么有更新
十四、再次查询id=100的数据

仍然走索引,说明在评估查询的时候,表的统计信息依然陈旧
十五、查询索引的统计信息
select num_rows,blevel,last_analyzed from user_indexes where index_name = 'IND_ID';

发现索引统计信息较步骤五没有变化,说明收集了分区的统计信息后,表的索引信息没有更新
十六、重新再次收集表的统计信息
exec dbms_stats.gather_table_stats(user,'TEST',cascade =>true);
十七、查询表的统计信息以及索引的统计信息
select num_rows,blocks,last_analyzed from user_tables where table_name = 'TEST';

表的统计信息已经更新
select num_rows,blevel,last_analyzed from user_indexes where index_name = 'IND_ID';

索引的统计信息也已经更新
十八、再次查询id=100的执行计划

这次发现走了全表,说明收集了全局的统计信息后,表的统计信息准确了,评估也就准确了。
- Oracle 分区表 收集统计信息 参数granularity
GRANULARITY Determines the granularity of statistics to collect. This value is only relevant for par ...
- ORACLE收集统计信息
1. 理解什么是统计信息 优化器统计信息就是一个更加详细描述数据库和数据库对象的集合,这些统计信息被用于查询优化器,让其为每条SQL语句选择最佳的执行计划.优化器统计信息包括: · ...
- ORACLE 收集统计信息
1. 理解什么是统计信息优化器统计信息就是一个更加详细描述数据库和数据库对象的集合,这些统计信息被用于查询优化器,让其为每条SQL语句选择最佳的执行计划.优化器统计信息包括: · ...
- Oracle收集统计信息的一些思考
一.问题 Oracle在收集统计信息时默认的采样比例是DBMS_STATS.AUTO_SAMPLE_SIZE,那么AUTO_SAMPLE_SIZE的值具体是多少? 假设采样比例为10%,那么在计算单个 ...
- Oracle 收集统计信息11g和12C在差异
Oracle 基于事务临时表11g和12C下,能看到临时表后收集的统计数据,前者记录被清除,后者没有,这是一个很重要的不同. 关于使用企业环境12C,11g,使用暂时表会造成时快时慢.之前我有帖子ht ...
- Oracle重建表索引及手工收集统计信息
Oracle重建所有表的索引的sql: SELECT 'alter index ' || INDEX_NAME || ' rebuild online nologging;' FROM USER_IN ...
- Oracle 手动收集统计信息
收集oracle统计信息 优化器统计范围: 表统计: --行数,块数,行平均长度:all_tables:NUM_ROWS,BLOCKS,AVG_ROW_LEN: 列统计: --列中唯一值的数量(NDV ...
- Oracle 判断 并 手动收集 统计信息 脚本
CREATE OR REPLACE PROCEDURE SchameB.PRC_GATHER_STATS AUTHID CURRENT_USER IS BEGIN SYS.DBMS_STATS.GAT ...
- oracle的统计信息的查看与收集
查看某个表的统计信息 SQL> alter session set NLS_DATE_FORMAT='YYYY-MM-DD HH24:MI:SS'; Session altered. SQL&g ...
随机推荐
- LindAgile~大叔新宠~一个无所不能框架
关于她 LindAgile是大叔在这两年里的新宠儿,它主推模块化,插件化,敏捷化,主要于LindAgile基础项目,LindAgile.Http项目,LindAgile.Modules项目和几个扩展模 ...
- hdu--1013--Digital Roots(字符串)
Digital Roots Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others)Tot ...
- uiautomator +python 实现安卓自动化
很多人看到这个题目我相信他们可能会说,uiautomator不是java开发的吗?python怎么用呢,其实呢 ,一开始我也是这么想的,看了金阳光老师的视频,也是用java写的,我表示不服,我要科学上 ...
- mysql中varchar和char区别(思维导图整理)
由于mysql一直是我的弱项(其实各方面我都是很弱的),所以最近在看msyql,正好看到varchar和char区别,所以整理一下,便于以后遗忘. 0.0图片已经说明一切,但是系统说我字数不够,我真能 ...
- Akka(19): Stream:组合数据流,组合共用-Graph modular composition
akka-stream的Graph是一种运算方案,它可能代表某种简单的线性数据流图如:Source/Flow/Sink,也可能是由更基础的流图组合而成相对复杂点的某种复合流图,而这个复合流图本身又可以 ...
- java核心技术之流与文件
InputStream和OutputStream构成了输入/输出类层次结构的基础.用于按字节进行读写.而与之处在同一等级的Reader/Writer同样作为抽象类定义了用于对字符进行读取的类层次结构, ...
- 一个基于JRTPLIB的轻量级RTSP客户端(myRTSPClient)——收流篇:(四)example代码解析
一.example逻辑伪码 myRTSPClient附带3个example程序:simple_example.complete_example.common_example.后两个example都是从 ...
- MySQL Linux压缩版安装方法
在诸多开源数据库中,MySQL是目前应用行业,特别是互联网行业发展最好的一个.借助灵活的架构特点和适应不同应用系统场景的Storage Engine,MySQL在很多方面已经有不次于传统商用数据库的表 ...
- 【LCT】一步步地解释Link-cut Tree
简介 Link-cut Tree,简称LCT. 干什么的?它是树链剖分的升级版,可以看做是动态的树剖. 树剖专攻静态树问题:LCT专攻动态树问题,因为此时的树剖面对动态树问题已经无能为力了(动态树问题 ...
- A* a=new B ,会不会产生内存泄露了,露了B-A的部分?
A* a=new B ,delete a;会不会产生内存泄露了,露了B-A的部分.其中B为A的子类 析构函数在下边3种情况时被调用:1.对象生命周期结束,被销毁时:2.delete指向对象的指针时,或 ...