Hadoop(七)HDFS容错机制详解
前言
HDFS(Hadoop Distributed File System)是一个分布式文件系统。它具有高容错性并提供了高吞吐量的数据访问,非常适合大规模数据集上的应用,它提供了一个高度容错性和高吞吐量的海量数据存储解决方案。
优点是:
高吞吐量访问:HDFS的每个Block分布在不同的Rack上,在用户访问时,HDFS会计算使用最近和访问量最小的服务器给用户提供。
由于Block在不同的Rack上都有备份,所以不再是单数据访问,所以速度和效率是非常快的。另外HDFS可以并行从服务器集群中读写,增加了文件读写的访问带宽。
高容错性:系统故障是不可避免的,如何做到故障之后的数据恢复和容错处理是至关重要的。
HDFS通过多方面保证数据的可靠性,多份复制并且分布到物理位置的不同服务器上,数据校验功能、后台的连续自检数据一致性功能都为高容错提供了可能。
线性扩展:因为HDFS的Block信息存放到NameNode上,文件的Block分布到DataNode上,当扩充的时候仅仅添加DataNode数量,系统可以在不停止服务的情况下做扩充,不需要人工干预。
一、HDFS容错机制

1.1、故障类型(三类故障)
1)节点失败
2)网络故障
3)数据损坏(脏数据)
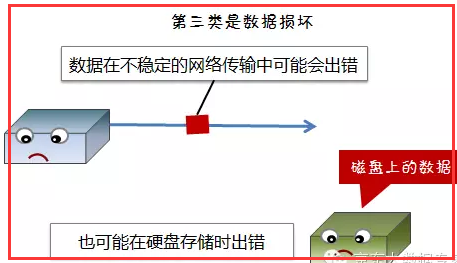
1.2、故障检测机制
1)节点失败检测机制

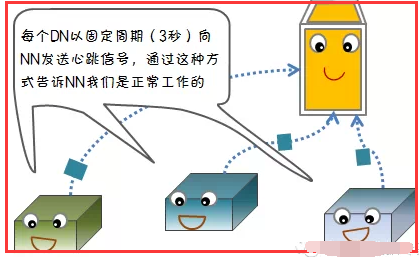
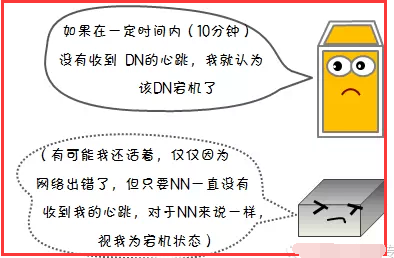
2)通信故障检测机制

3)数据错误检测机制


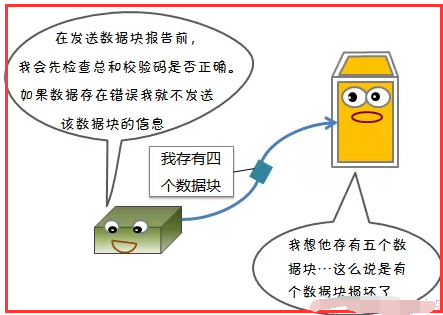
1.3、回复:心跳信息和数据块报告
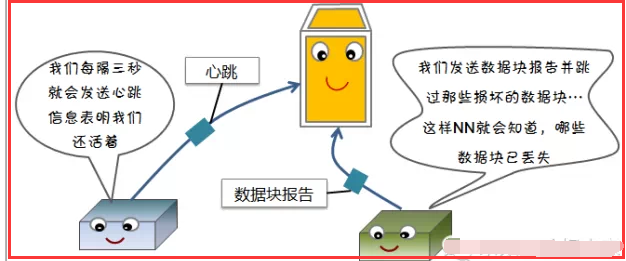
HDFS存储理念是以最少的钱买最烂的机器并实现最安全、难度高的分布式文件系统(高容错性低成本)。
从上可以看出,HDFS认为机器故障是种常态,所以在设计时充分考虑到单个机器故障,单个磁盘故障,单个文件丢失等情况。
1.4、读写容错
1)写容错
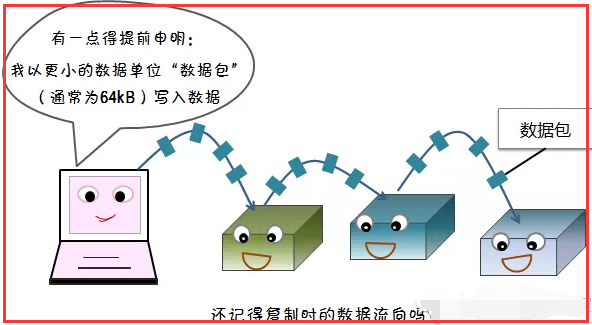
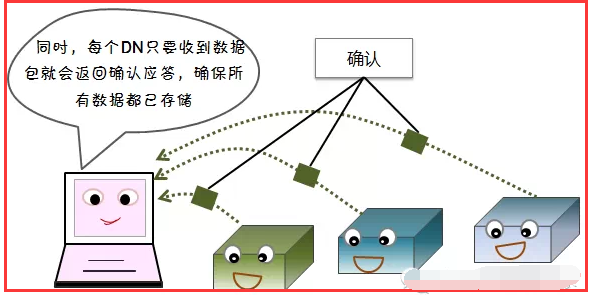
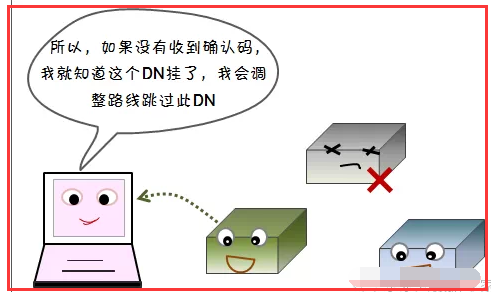
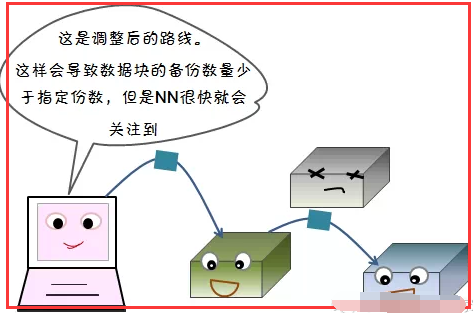
2)读容错

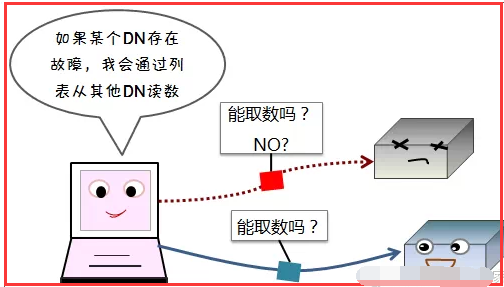
1.5、数据节点(DN)失效
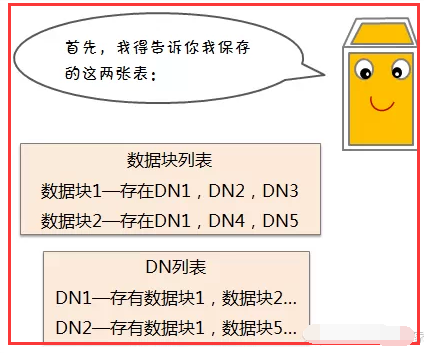
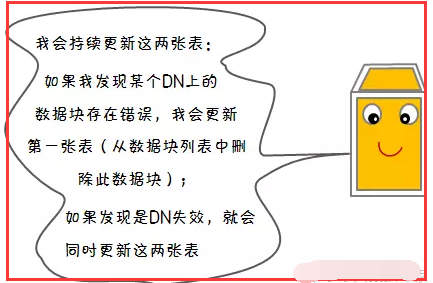


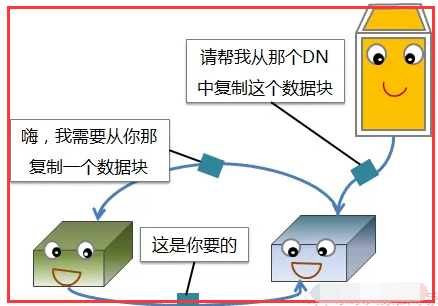

二、HDFS备份规则

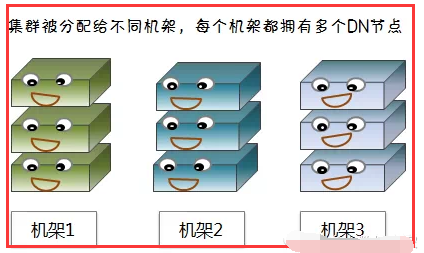
1)机架与数据节点
2)副本放置策略

数据块的第一个副本优先放在写入数据块的客户端所在的节点上,但是如果这个客户端上的数据节点空间不足或者是当前负载过重,则应该从该数据节点所在的机架中选择一个合适的数据节点作为本地节点。
如果客户端上没有一个数据节点的话,则从整个集群中随机选择一个合适的数据节点作为此时这个数据块的本地节点。

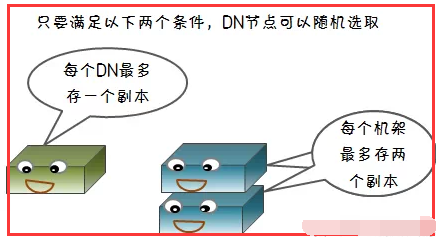
HDFS的存放策略是将一个副本存放在本地机架节点上,另外两个副本放在不同机架的不同节点上。
这样集群可在完全失去某一机架的情况下还能存活。同时,这种策略减少了机架间的数据传输,提高了写操作的效率,因为数据块只存放在两个不同的机架上,
减少了读取数据时需要的网络传输总带宽。这样在一定程度上兼顾了数据安全和网络传输的开销。

Hadoop(七)HDFS容错机制详解的更多相关文章
- 【史上最全】Hadoop 核心 - HDFS 分布式文件系统详解(上万字建议收藏)
1. HDFS概述 Hadoop 分布式系统框架中,首要的基础功能就是文件系统,在 Hadoop 中使用 FileSystem 这个抽象类来表示我们的文件系统,这个抽象类下面有很多子实现类,究竟使用哪 ...
- Hadoop(10)-HDFS的DataNode详解
1.DataNode工作机制 1)一个数据块在DataNode上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳. 2)DataNode启 ...
- Elasticsearch和HDFS 容错机制 备忘
1.Elasticsearch 横向扩容以及容错机制http://www.bubuko.com/infodetail-2499254.html 2.HDFS容错机制详解https://www.cnbl ...
- Hadoop(四)HDFS集群详解
前言 前面几篇简单介绍了什么是大数据和Hadoop,也说了怎么搭建最简单的伪分布式和全分布式的hadoop集群.接下来这篇我详细的分享一下HDFS. HDFS前言: 设计思想:(分而治之)将大文件.大 ...
- adoop(四)HDFS集群详解
阅读目录(Content) 一.HDFS概述 1.1.HDFS概述 1.2.HDFS的概念和特性 1.3.HDFS的局限性 1.4.HDFS保证可靠性的措施 二.HDFS基本概念 2.1.HDFS主从 ...
- Hadoop 新 MapReduce 框架 Yarn 详解
Hadoop 新 MapReduce 框架 Yarn 详解: http://www.ibm.com/developerworks/cn/opensource/os-cn-hadoop-yarn/ Ap ...
- hdfs文件系统架构详解
hdfs文件系统架构详解 官方hdfs分布式介绍 NameNode *Namenode负责文件系统的namespace以及客户端文件访问 *NameNode负责文件元数据操作,DataNode负责文件 ...
- Hadoop 发行版本 Hortonworks 安装详解(一) 准备工作
一.前言 目前Hadoop发行版非常多,所有这些发行版均是基于Apache Hadoop衍生出来的,之所以有这么多的版本,完全是由Apache Hadoop的开源协议决定的:任何人可以对其进行修改,并 ...
- java面试题之----JVM架构和GC垃圾回收机制详解
JVM架构和GC垃圾回收机制详解 jvm,jre,jdk三者之间的关系 JRE (Java Run Environment):JRE包含了java底层的类库,该类库是由c/c++编写实现的 JDK ( ...
随机推荐
- 201521123016《Java设计与程序》第6周学习总结
1. 本周学习总结 1.1 面向对象学习暂告一段落,请使用思维导图,以封装.继承.多态为核心概念画一张思维导图,对面向对象思想进行一个总结. 2. 书面作业 1.clone方法 1.1 Object对 ...
- 201521123017 《Java程序设计》第5周学习总结
1. 本周学习总结 2. 书面作业 1.代码阅读:Child压缩包内源代码 1.1 com.parent包中Child.java文件能否编译通过?哪句会出现错误?试改正该错误.并分析输出结果. 1.2 ...
- 201521123029《Java程序设计》第四周学习总结
1. 本周学习总结 1.1 尝试使用思维导图总结有关继承的知识点. 1.2 使用常规方法总结其他上课内容. 答:1. 多态性,多态性是相同的形态,不同的行为(定义),其中父类类型变量可以引用子类对象. ...
- 201521123122 《java程序设计》 第三周学习总结
1. 本章学习总结 你对于本章知识的学习总结 链接点击此处 2. 书面作业 代码阅读 public class Test1 { private int i = 1;//这行不能修改 private s ...
- 201521123054《JAVA程序设计》第三周学习总结
本周学习总结 书面作业 代码阅读 public class Test1 { private int i = 1;//这行不能修改 private static int j = 2; public st ...
- 201521123002《Java程序设计》第14周学习总结
本次作业参考文件 1. 本周学习总结 1.1 以你喜欢的方式(思维导图或其他)归纳总结多数据库相关内容. MySql数据库简单操作: 库操作: 显示所有数据库: show databases; 创建数 ...
- 笔记2 linux多线程 读写锁
//read write lock #include<stdio.h> #include<unistd.h> #include<pthread.h> struct ...
- MySQL的数据备份以及pymysql的使用
一.MySQL的数据备份 语法: # mysqldump -h 服务器 -u用户名 -p密码 数据库名 > 备份文件.sql #示例: #单库备份 mysqldump -uroot -p123 ...
- 在linux环境下搭建java web测试环境(非常详细!!)
一.项目必备软件及基本思路 项目必备:虚拟机:VMware Workstation (已安装linux的 CentOS6.5版本) 项目:java web项目 (必须在本地部署编译后选择项目的webR ...
- JPA关系映射之many-to-many
@ManyToMany Board表实体类 @Entity @Cache(usage=CacheConcurrencyStrategy.NONSTRICT_READ_WRITE) @Table(nam ...