ElasticSearch 学习记录之集群分片内部原理
分片内部原理
- 分片是如何工作的
- 为什么ES搜索是近实时性的
- 为什么CRUD 操作也是实时性
- ES 是怎么保证更新被持久化时断电也不丢失数据
- 为什么删除文档不会立即释放空间
- refresh, flush, 和 optimize API 作用
使文本可被搜索
倒排索引的结构词项 文档列表
Term | Doc 1 | Doc 2 | Doc 3 | ...
------------------------------------
brown | X | | X | ...
fox | X | X | X | ...
quick | X | X | | ...
the | X | | X | ...- 倒排索引的不变性
- 不需要锁
- 可被内核的文件系统缓存,停留在内存中,大部分请求会直接请求到内存,不会落到磁盘上
- filter缓存,在索引的生命周期始终有效。不需要再每次数据改变时重建
- 写入单个较大的倒排索引使允许数据被压缩
- 如何在索引不变情况下 动态更新索引
- 使用更多的索引,来解决这个问题
- 通过增加新的补充索引来反映新近的修改,而不是直接重写整个倒排索引
一个 Lucene 索引包含一个提交点和三个段
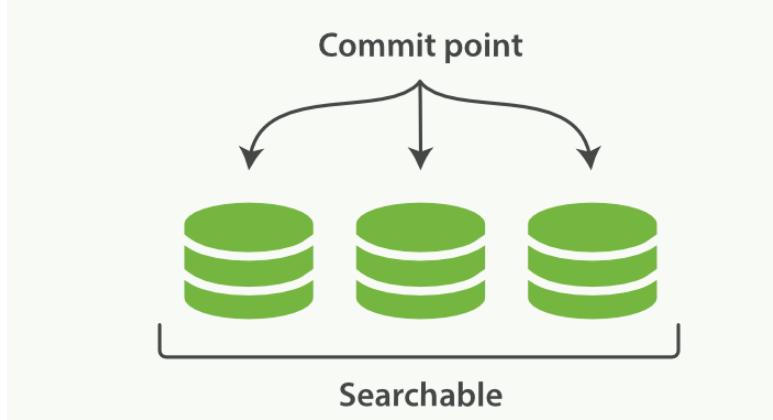
- 逐段搜索的流程
- 新文档被收集到内存索引缓存
- 不时地, 缓存被 提交
- 一个新的段----一个追加的倒排索引--被写入磁盘
- 一个新的包含新段名字的 提交点 被写入磁盘
- 磁盘进行 同步 — 所有在文件系统缓存中等待的写入都刷新到磁盘
- 新的段被开启,让它包含的文档可见以被搜索
- 内存缓存被清空,等待接收新的文档
- 一个在内存缓存中包含新文档的 Lucene 索引

- 在一次提交后,一个新的段被添加到提交点而且缓存被清空
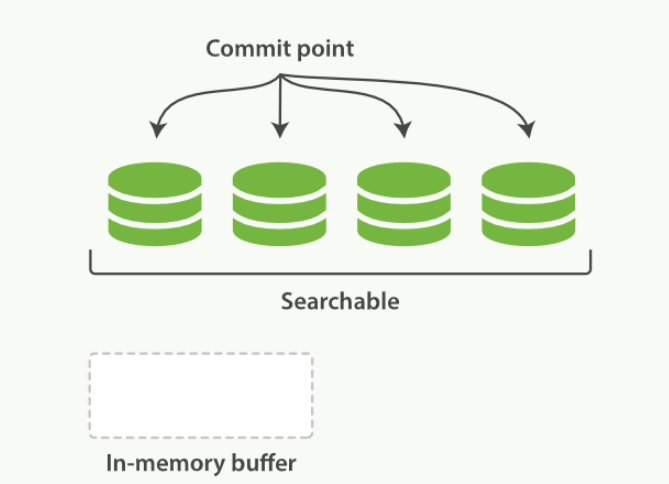
- 删除和更新文档
- 段是不可改变的,每个提交点都会有一个.del文件。在这个文件中能列出这些删除文档的短信息
- 当文档被删除时不是删除,只是在.del文件中被登记
- 文档的更新也是这样的,先将更新的文档标记为删除。然后文档的新版本被索引到一个新的段中
近实时搜索
- 提交(Commiting)一个新的段到磁盘需要一个 fsync 来确保段被物理性地写入磁盘,这样在断电的时候就不会丢失数据。但是每次提交的一个新的段都fsync 这样操作代价过大。可以使用下面这种更轻量的方式
- 在内存缓冲区中包含了新文档的 Lucene 索引
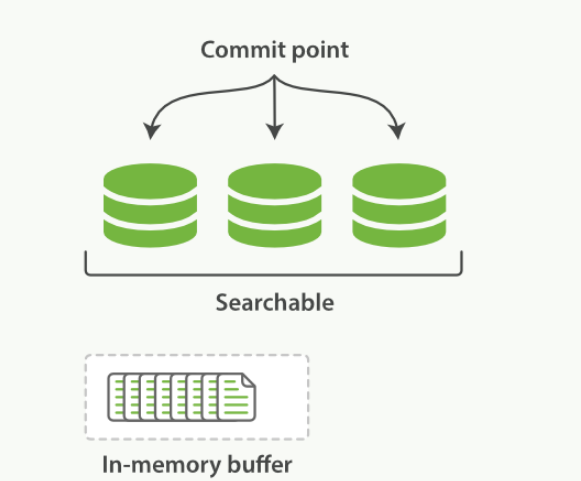
- Lucene 允许新段被写入和打开--使其包含的文档在未进行一次完整提交时便对搜索可见
- 缓冲区的内容已经被写入一个可被搜索的段中,但还没有进行提交
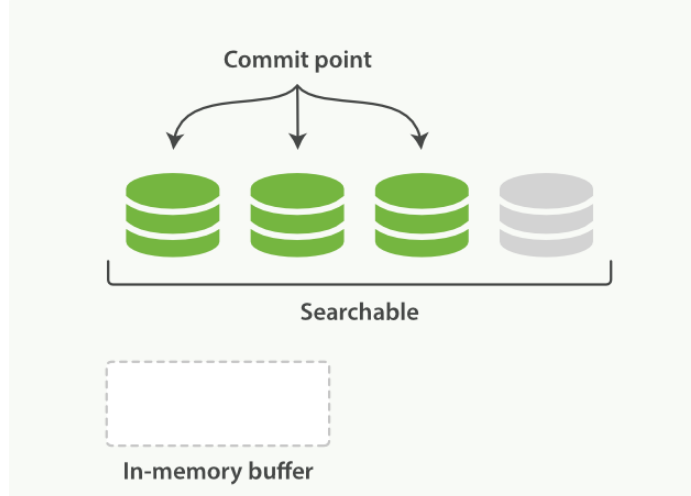
- 这里新段会被先写入到文件系统缓存--这一步代价会比较低,稍后再被刷新到磁盘--这一步代价比较高
- 默认情况下每个分片会每秒自动刷新一次
- 近 实时搜索: 文档的变化并不是立即对搜索可见,但会在一秒之内变为可见
- POST /_refresh // 刷新Refresh 所有的索引
- POST /blogs/_refresh // 只刷新Refresh blogs 索引
可以在settings 设置对定时刷新频率的大小
PUT /my_logs
{
"settings": {
"refresh_interval": "30s" //30秒刷新一次
"refresh_interval": "-1" //关闭自动刷新
"refresh_interval": "1s"//每秒自动刷新
}
}持久化变更
在没有 fsync 把数据从内存刷新到硬盘中,我们不能保证数据在断电或程序退出时之后依然存在
- 即时每秒刷新,也不能实现近实时搜索。我们任然有另外的方法确保从失败中回复数据
- ES 增加一个translog,或者叫做事务日志。在每次操作是均进行日志记录
- 整个流程是如下的操作
一个文档被索引之后,就会被添加到内存缓冲区,并且 追加到了 translog
-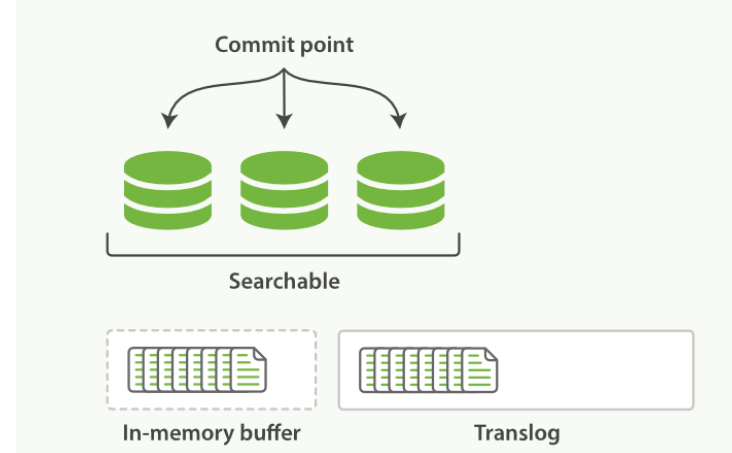
- 刷新(refresh)使分片处于缓存被清空,但是事务日志不会的状态
- 内存缓冲区的文档被写入新的段中,但是没有进行fsync
- 段被打开,且可被搜索到
- 内存缓冲区被清空
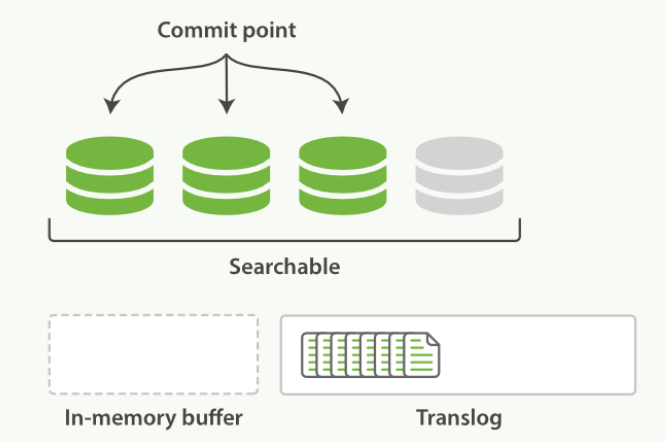
- 进程继续进行,更多的文档被添加到内存缓冲区和追加的事务日志中
每隔一段时间,translog太大 或 索引被刷新。一个新的translog被创建,并且被全量提交
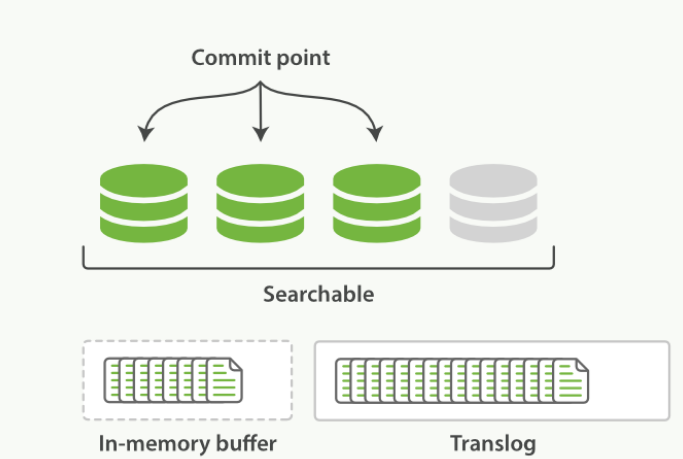
-
- 所有内存缓冲区的文档都被写入一个新的段中
- 缓冲区内清空
- 一个提交点被写入硬盘
- 文件系统缓存通过fsync被刷新
- 老的translog 被删除
- translog 提供所有没有被刷新到磁盘操作的一个持久化记录。当ES启动时,会根据最后一个提交点去恢复已知的段
- translog 也可供用来提供实时的CRUD。但我们进行一些CRUD操作时,它会首先检查translog任何最近的变更。
- flush API 执行一次提交,并截断translog的操作
- 分片默认每30M自动flush一次。translog太大也会自动flush
可通过自己执行flush API操作
POST /blogs/_flush //刷新索引
POST /_flush?wait_for_ongoing //刷新索引并等待所有的刷新结果返回
段合并
- 段合并的时候会将那些旧的已删除的文档从文件系统中删除,被删除或者被更新的文档不会被复制到新的大段中
段合并的流程
-
- 当索引的时候,刷新(refresh)操作会创建新的段
- 合并的时候会选择一部分大小相似的段,并且将其合并到更大的段中
- 段的合并结束,老的段就要被删除

- optimized API 的作用
- optimize API大可看做是 强制合并 API 。
ElasticSearch 学习记录之集群分片内部原理的更多相关文章
- ElasticSearch学习笔记-02集群相关操作_cat参数
_cat参数允许你查看集群的一些相关信息,如集群是否健康,有哪些节点,以及索引的情况等的. 检测集群是否健康 curl localhost:9200/_cat/health?v 说明: curl 是一 ...
- ElasticSearch 学习记录之ES几种常见的聚合操作
ES几种常见的聚合操作 普通聚合 POST /product/_search { "size": 0, "aggs": { "agg_city&quo ...
- ElasticSearch 学习记录之ES短语匹配基本用法
短语匹配 短语匹配故名思意就是对分词后的短语就是匹配,而不是仅仅对单独的单词进行匹配 下面就是根据下面的脚本例子来看整个短语匹配的有哪些作用和优点 GET /my_index/my_type/_sea ...
- ElasticSearch 学习记录之 分布式文档存储往ES中存数据和取数据的原理
分布式文档存储 ES分布式特性 屏蔽了分布式系统的复杂性 集群内的原理 垂直扩容和水平扩容 真正的扩容能力是来自于水平扩容–为集群添加更多的节点,并且将负载压力和稳定性分散到这些节点中 ES集群特点 ...
- ElasticSearch 学习记录之如任何设计可扩容的索引结构
扩容设计 扩容的单元 一个分片即一个 Lucene 索引 ,一个 Elasticsearch 索引即一系列分片的集合 一个分片即为 扩容的单元 . 一个最小的索引拥有一个分片. 一个只有一个分片的索引 ...
- ElasticSearch 学习记录之ES高亮搜索
高亮搜索 ES 通过在查询的时候可以在查询之后的字段数据加上html 标签字段,使文档在在web 界面上显示的时候是由颜色或者字体格式的 GET /product/_search { "si ...
- ElasticSearch 学习记录之ES查询添加排序字段和使用missing或existing字段查询
ES添加排序 在默认的情况下,ES 是根据文档的得分score来进行文档额排序的.但是自己可以根据自己的针对一些字段进行排序.就像下面的查询脚本一样.下面的这个查询是根据productid这个值进行排 ...
- ElasticSearch 学习记录之父子结构的查询
父子结构 父亲type属性查询子type 的类型 父子结构的查询,可以通过父亲类型的字段,查询出子类型的索引信息 POST /product/_search { "query": ...
- ElasticSearch 学习记录之Text keyword 两种基本类型区别
ElasticSearch 系列文章 1 ES 入门之一 安装ElasticSearcha 2 ES 记录之如何创建一个索引映射 3 ElasticSearch 学习记录之Text keyword 两 ...
随机推荐
- Air Raid
Air Raid Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Subm ...
- 取得 iframe 容器的 URL
检测所在窗口是否为最外层的窗口,若不是则跳脱包含它的框架 if( window !== window.top ) { window.top.location = location; } top ...
- bash脚本条件测试总结
一.if语句的结构 分为以下三种:单分支.双分支.多分支 单分支if语句 if CONDITION is True: then 分支 fi 双分支if语句 if CONDITION is True: ...
- linux环境手动编译安装Nginx实践过程 附异常解决
1.下载nginx源码包并解压 可在http://nginx.org/en/download.html下载.tar.gz的源码包,如(nginx-1.4.7.tar.gz) 或者使用云盘下载 ht ...
- Problem J: 求个最大值
Problem J: 求个最大值 Time Limit: 1 Sec Memory Limit: 128 MBSubmit: 871 Solved: 663[Submit][Status][Web ...
- 使用jquery ajaxForm提交表单
一.首先引用Jquery <script src="~/Scripts/jquery-1.9.1.min.js"></script> <script ...
- 分页查询时,使用cookie保存上次的查询条件。jQuery实现方法以及中间遇到的坑
今天做分页查询时需要在跳转页面时保存上次查询的条件,如下: 实现的大致思路就是用cookie本地保存. 其中需要用到jQuery.Cookie插件. 使用方法很简单: 存数据:$.cookie(“ke ...
- Container With Most Water 容器最大水容量
描述 Given n non-negative integers a1, a2, ..., an, where each represents a point at coordinate (i, ai ...
- Java中Date日期字符串格式的各种转换
public class DateParserT { /** * Date 与 String.long 的相互转换 * @param args ...
- C#实现设置完整虚拟路径
){ mHttpUrl.Append(":"); mHttpUrl.Append(port);}string mServerName = "~/AppModu ...