ML技术 - 特征选择
1. 决策树中的特征选择
分类决策树是一种描述对实例进行分类的树型结构,决策树学习本质上就是从训练数据集中归纳出一组分类规则,而二叉决策树类似于if-else规则。决策树的构建也是非常的简单,首先依据某种特征选择手段对每一特征对分类的贡献性大小排序,然后从根节点开始依次取出剩下特征中对分类贡献最大的特征,用其作为当前节点的分类准则,进一步构造其叶子结点,然后重复此过程,直到特征用光或满足了预先设定的要求终止决策树的构建。由此可见,特征选择作为决策树构建的核心技术而存在,那么下面我们就来讨论一下决策树中常用的特征选择技术有哪些:
1.1 信息增益与信息增益比
一个特征所包含的信息量可以通过看这个特征对整体稳定性的影响大小来确定。举个例子,
假设我问你:今年冬天会下雪?
你会反问:你说的哪呀?南方和北方会一样么?你说的话一点信息量都没有!
我又问:海南,今年冬天会下雪么?
你会说:那肯定不会下呀,气温都到不了0下!
从这对话中我们看到,就冬天会不会下雪这个问题开始时会有两个等可能的判断,这时候是最让我们摸不着头脑的,如果我们接着为其添加一个地域的约束也就是上面的A,此时我们的问题就一下子明朗起来,可见地域信息为我们这个问题的判断提供了非常大的信息参考。除了地域这个特征,也许还有其他一些信息会影响我们对下雪这个问题的判断,那么在这个问题我们该如何比较中的各个特征的信息量大小呢?没错,就是信息增益。 信息增益衡量的是在得知某一特征A的信息后而使得类Y的不确定性减少的程度,公式如下:

这里,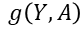 表示特征A对类别Y的信息增益,而随机事件的不确定性可以通过熵来衡量,故
表示特征A对类别Y的信息增益,而随机事件的不确定性可以通过熵来衡量,故 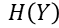 表示类别Y的熵(不确定性),
表示类别Y的熵(不确定性), 表示在得知特征A后类别Y的熵。可见信息增益是基于熵提出的!那么问题来了,熵如何衡量事件不确定性的呢?我们首先从公式说起:
表示在得知特征A后类别Y的熵。可见信息增益是基于熵提出的!那么问题来了,熵如何衡量事件不确定性的呢?我们首先从公式说起:
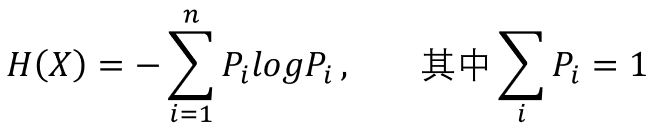
用拉格朗日乘子法,我们可以解得当 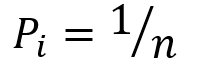 时,熵是最大的(证明过程参见)。对于一次伯努利实验的结果其熵的分布满足:
时,熵是最大的(证明过程参见)。对于一次伯努利实验的结果其熵的分布满足:
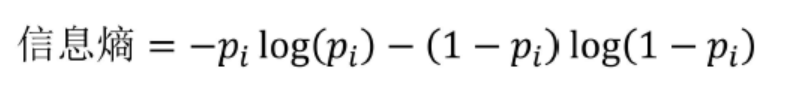
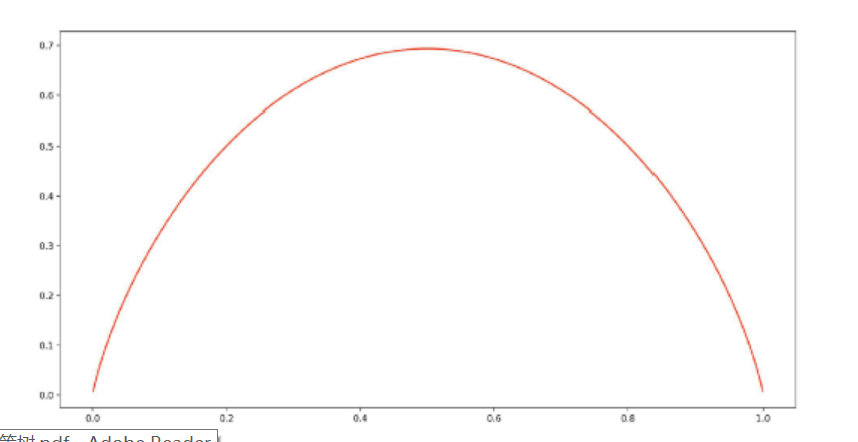
可见,在事件最不确定的时候,其熵值最大,也就是说熵是不确定性的单调递增函数。那么问题又来了,为什么熵的公式是这样的?具体参考可以参见知乎问答。
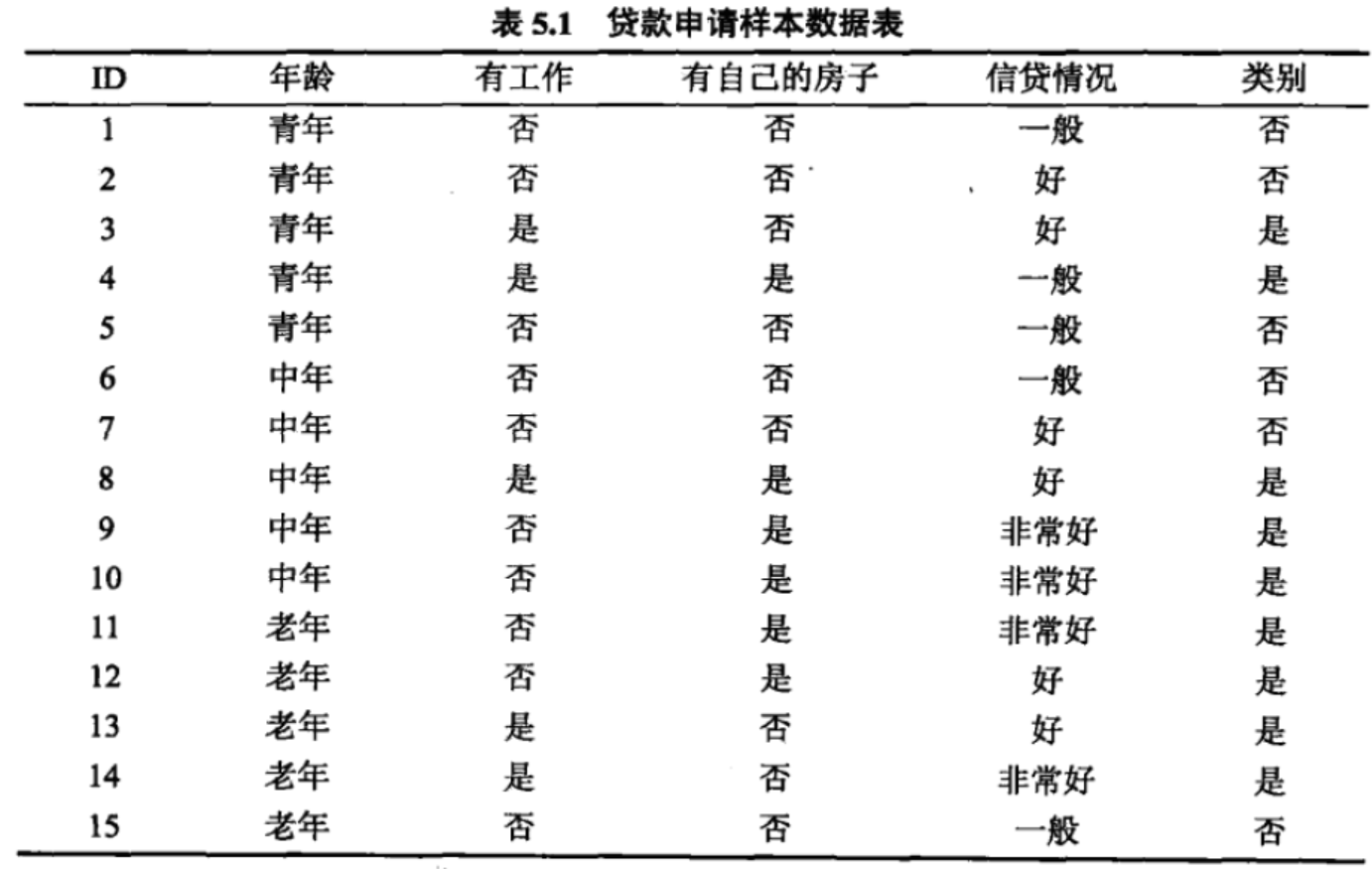
有时候信息增益并不能很好的度量两个特征哪个特征对分类的贡献大。借用一下李航老师统计学习方法中的贷款申请的例子:
类别有6个“否”、9个“是”,那么数据集D的熵为:
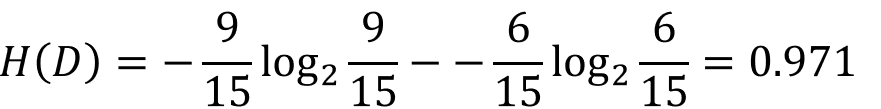
而对于四种特征它们的信息增益分别是:
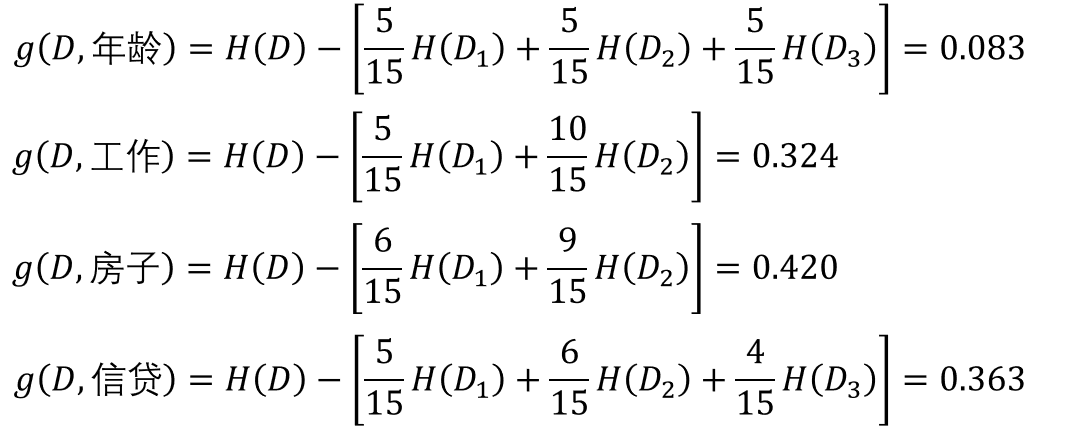
到这里看着似乎没什么问题,那么我们将创造一个问题,把ID也当成一个特征,看看它的信息增益是多少:

到这里我们发现了ID的信息增益最大呀!那ID就是最好的特征么?开玩笑吧!总的来说,信息增益倾向于选择特征取值多的特征,和上面的例子一样,把ID当作最好的特征,是不是很傻。所以为了克服它的这种缺陷,信息增益比就诞生了。信息增益比相当于对每个特征的信息增益加了一个权值,抵消了特征取值数对信息增益的影响,这样就把信息增益归一到同一量级,更加方便比较它们的大小。
特征A对于训练数据集D的信息增益比定义为:
 ,其中n为特征A的取值个数。
,其中n为特征A的取值个数。
1.2 基尼系数
CART分类树中会用到基尼指数作为样本不确定性的度量,同熵代表的含义相同:基尼系数越大,代表了随机变量越不确定,也就是随机变量越随机。分类问题中,假设有K个类,样本属于第k类的概率为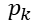 ,那么该概率分布的基尼指数为
,那么该概率分布的基尼指数为

CART构造的是一颗二叉分类树,那么一般我们将一特征集切分成两部分,故得到在特征A给定的条件下,集合D的基尼指数定义为
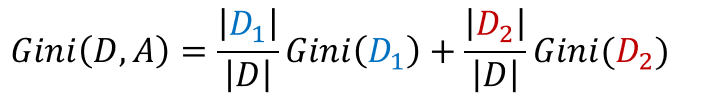
2. Sklearn中的特征选择
特征选择并不只是用于决策树的构建,特征选择也是机器学习中经常用到的一门技术。特征选择技术出现的原因是:我们要知道在一个机器学习任务中,并不是我们获取的所有特征都对模型构建有着积极的影响,即使都有积极的效益,我们可能也要权衡特征项数与建模效率之间的关系。而特征选择可以非常有效的解决这些问题。特征选择技术可以帮助我们筛选出对建模最有用的特征,把可有可无的特征项去除,不仅可以加速我们模型的训练,还可以有效清除噪声特征对模型的影响。下面将简单过一下sklearn中特征选择,然后选一些自己曾经见过的技术,研究一下它的用法:


2.1 基于卡方统计量的特征选择
what is 卡方检验统计量:卡方统计量是用于检验实际分布与理论分布配合程度,也可以说成统计样本的实际观测值与理论推断值之间的偏差程度的统计量。若卡方值越大,说明偏差越大,越不符合实际;而卡方值越小,说明偏差越小,越是符合实际情况;若卡方值为0,说明理论完全符合实际!下面是卡方统计量的公式:

其中,  表示实际观测次数,
表示实际观测次数,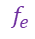 表示理论观测次数。因为卡方检验可以用于检测随机变量之间的依赖关系,因此我们可以用它来清除那些最有可能与类别不想关的特征,来减少噪音特征对分类的影响。
表示理论观测次数。因为卡方检验可以用于检测随机变量之间的依赖关系,因此我们可以用它来清除那些最有可能与类别不想关的特征,来减少噪音特征对分类的影响。
sklearn.feature_selection.chi2(X, y)
"""
参数
---
X: 特征矩阵 (n_samples * n_features_in 维)
y: 标签向量 (n_samples * 1 维) 返回值
---
chi2:每个特征的卡方统计量(n_features * 1 维)
pval :每个特征的p-value (n_features * 1 维) 算法时间复杂度O(n_samples * n_features_in)
"""
2.2 基于方差分析的特征选择
方差是描述随机变量离散程度的统计量,其公式为:

而分差分析基本思想认为不同特征对分类模型的贡献程度之所以不同,主要源自于各个特征在组内与组间离散程度存在差异,于是F-score就出现了:
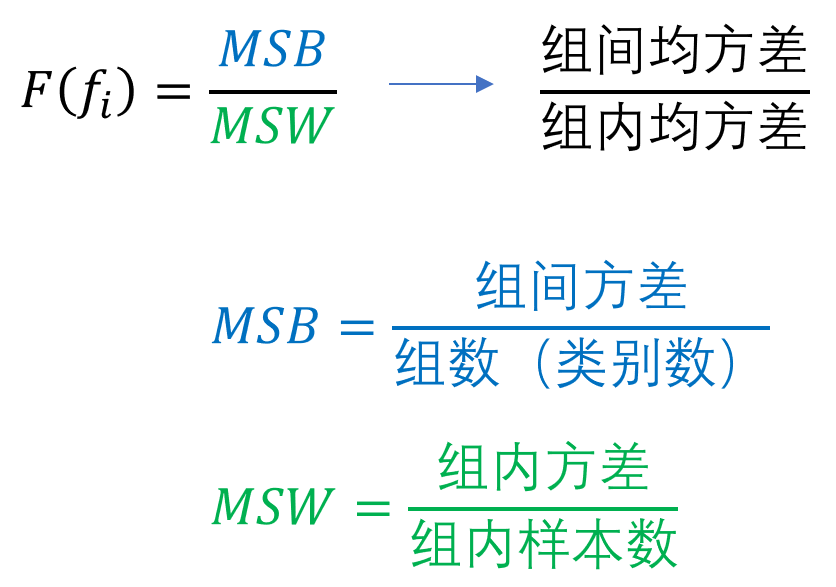
sklearn.feature_selection.f_classif(X, y)
"""
参数
---
X: 特征矩阵 (n_samples * n_features_in 维)
y: 标签向量 (n_samples * 1 维) 返回值
---
F:每个特征的卡方统计量(n_features * 1 维)
pval :每个特征的p-value (n_features * 1 维) 算法时间复杂度O(n_samples * n_features_in)
"""
ML技术 - 特征选择的更多相关文章
- 蒲公英 · JELLY技术周刊 Vol.29: 前端智能化在阿里的那些事
蒲公英 · JELLY技术周刊 Vol.29 前端智能化是指借助于 AI 和机器学习的能力拓展前端,使其拥有一些超出现阶段前端能力的特性,这将是未来前端方向中一场重要的变革.目前各家互联网厂商都有自己 ...
- Deep learning_CNN_Review:A Survey of the Recent Architectures of Deep Convolutional Neural Networks——2019
CNN综述文章 的翻译 [2019 CVPR] A Survey of the Recent Architectures of Deep Convolutional Neural Networks 翻 ...
- 2019 GOALS
ANNUAL GOAL 生活 1. 养成早睡早起的习惯 2. 体重:43kg 总体来讲希望自己有一个健康的生活方式,良好的饮食.运动习惯. 2019-04-17 18:47:14 UPDATE 3. ...
- A Survey of Machine Learning Techniques Applied to Software Defined Networking (SDN): Research Issues and Challenges
将机器学习用到SDN中的综述:研究的问题和挑战 从流量分类.路由优化.服务质量(Qos)/体验质量(QoE)预测.资源管理和安全性的角度,回顾了机器学习算法如何应用于SDN领域. 相关知识 在SDN中 ...
- Estimating the number of receiving nodes in 802.11 networks via machine learning
来源:IEEE International Conference on Communications 作者:Matteo Maria 年份:2016 摘要: 现如今很多移动设备都配有多个无线接口,比如 ...
- 2019-2020年值得关注的9个AR发展趋势
作者Andrew Makarov,由计算机视觉life编辑:乔媛媛编译 更好的阅读体验请看首发原文链接 2019-2020年值得关注的9个AR发展趋势 增强现实技术在2019年实现了创纪录的发展.微软 ...
- 【E2EL5】A Year in Computer Vision中关于图像增强系列部分
http://www.themtank.org/a-year-in-computer-vision 部分中文翻译汇总:https://blog.csdn.net/chengyq116/article/ ...
- Learning to Rank:pointwise, pairwise, listwise 总结
值得看: 刘铁岩老师的<Learning to Rank for Information Retrieval>和李航老师的<Learning to rank for informat ...
- 推荐排序---Learning to Rank:从 pointwise 和 pairwise 到 listwise,经典模型与优缺点
转载:https://blog.csdn.net/lipengcn/article/details/80373744 Ranking 是信息检索领域的基本问题,也是搜索引擎背后的重要组成模块. 本文将 ...
随机推荐
- vue学习之指令简写以及事件笔记
1.v-bind:××× 可简写为 :××× 2.v-on:××× 可简写为 @××× 例: v-on:click 可简写为 @click (官网文档介绍) 3.vue处理事件 <!-- 阻止单 ...
- 在CentOS 7 上安装docker
Docker CE Install yum-utils, which provides the yum-config-manager utility: $ sudo yum install -y yu ...
- 屏蔽掉Google Chrome 浏览器 textarea 单词拼写检测
可以使用html5的spellcheck属性来关闭对元素内容进行拼写检查. <!-以下两种书写方法正确--> <textarea spellcheck="true" ...
- Jquery字符串,数组(拷贝、删选、合并等),each循环,阻止冒泡,ajax出错,$.grep筛选,$.param序列化,$.when
<!DOCTYPE HTML PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...
- 使用Entify Framework 6.x的事务操作
public void TransactionsTest() { using (var context = new testContext()) { //使用EF事务 在vs2013中先升级Entit ...
- c# Socket通讯中关于粘包,半包的处理,加分割符
using System; using System.Collections.Generic; using System.Text; using System.Net.Sockets; using S ...
- CVPixelBuffer的创建 数据填充 以及数据读取
CVPixelBuffer的创建数据填充以及数据读取 CVPixelBuffer 在音视频编解码以及图像处理过程中应用广泛,有时需要读取内部数据,很少的时候需要自行创建并填充数据,下面简单叙述. 创建 ...
- 关于Page_Load事件发生情况
Page_Load事件会在第一次加载页面时发生和将该页面回发到服务器时发生 第一种情况Page.IsPostBack返回false,第二种返回True. 若在Page_Load事件中有一些对控件的操作 ...
- poi入门之读写excel
Apache POI 是用Java编写的免费开源的跨平台的 Java API,Apache POI提供API给Java程式对Microsoft Office格式档案读和写的功能.该篇是介绍poi基本的 ...
- Windows下swoole扩展的编译安装部署
1. 到cygwin官网下载cygwin. 官网地址:https://www.cygwin.com/ 2. 打开下载好的cygwin安装包,开始安装cygwin. 选择cygwin的安装目录(这个同时 ...