Python3分析sitemap.xml抓取导出全站链接
最近网站从HTTPS转为HTTP,更换了网址,旧网址做了301重定向,折腾有点大,于是在百度站长平台提交网址,不管是主动推送还是手动提交,前提都是要整理网站的链接,手动添加太麻烦,效率低,于是就想写个脚本直接抓取全站链接并导出,本文就和大家一起分享如何使用python3实现抓取链接导出。
首先网站要有网站地图sitemap.xml文件地址,其次我这里用的是python3版本,如果你的环境是python2,需要对代码进行调整,因为python2和python3很多地方差别还是挺大的。
下面是python 3代码,将里面的链接地址换成你自己的网址即可:
#coding=utf-8
import urllib
import urllib.request import re
url='http://www.ranzhi.org/sitemap.xml'
html=urllib.request.urlopen(url).read()
html=html.decode('utf-8')
r=re.compile(r'(http://www.ranzhi.org.*?\.html)')
big=re.findall(r,html)
for i in big:
print(i)
op_xml_txt=open('xml.txt','a')
op_xml_txt.write('%s\n'%i)
我们能来看一下运行结果:
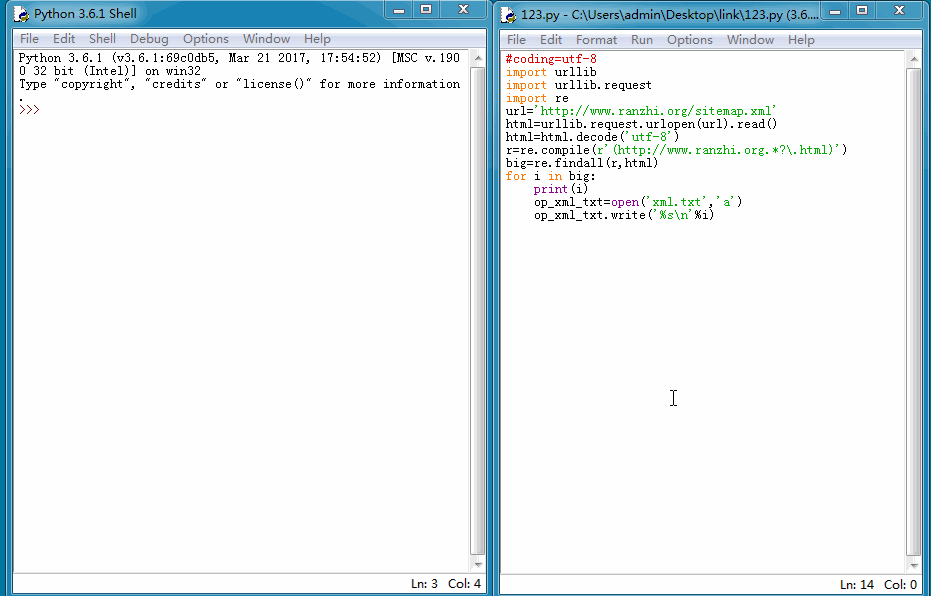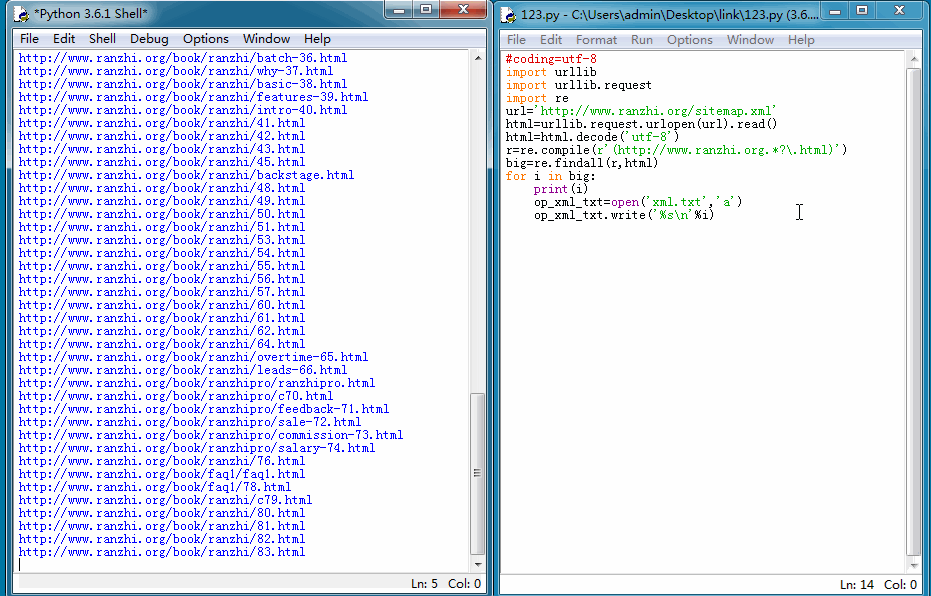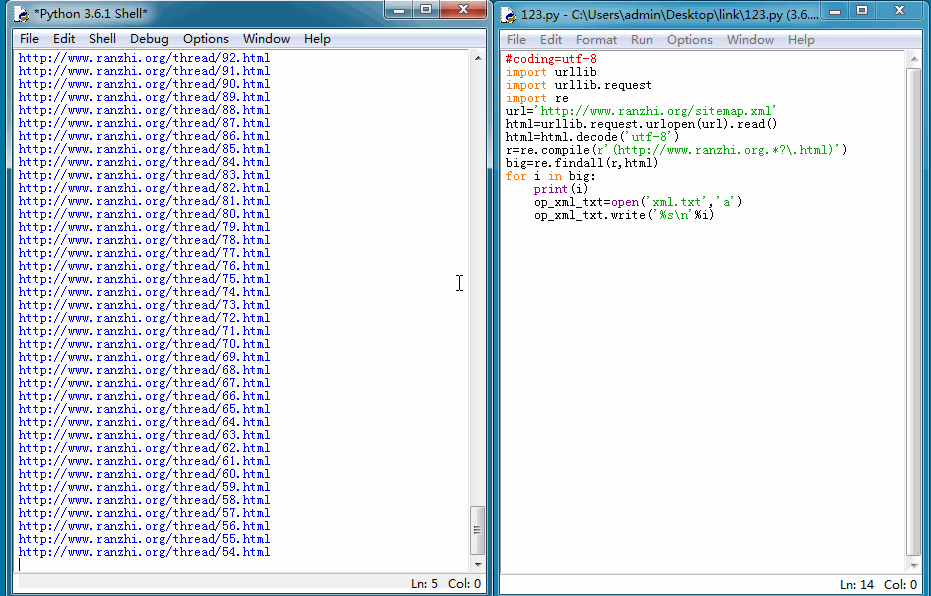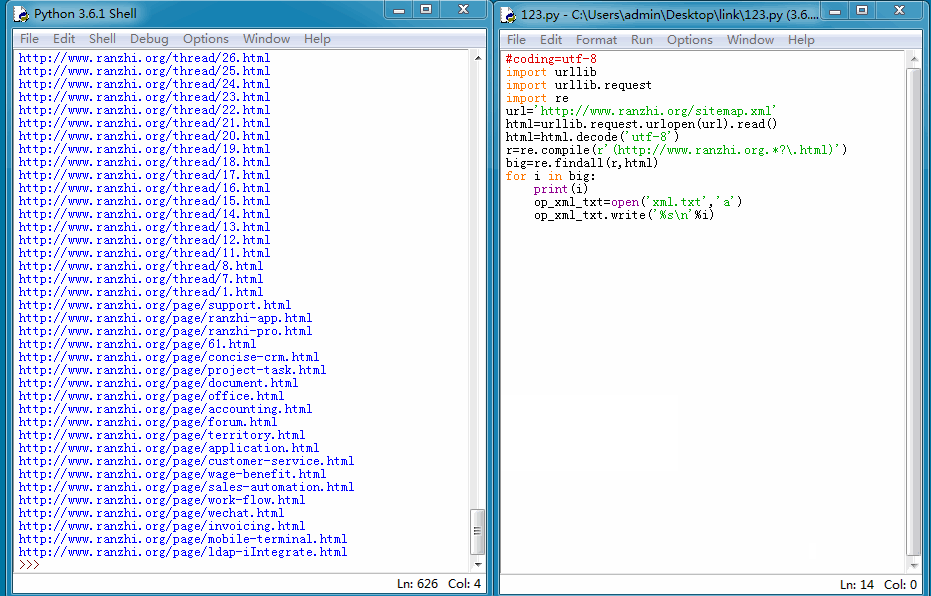
导出TXT格式文件后,再在百度站长平台手动提交就方便的多了。当然我们也可以使用更快的主动推送方式,因为我的然之网站是用PHP+mysql开发的,所以我们这里使用PHP脚本将上面抓取的链接再处理下,然后主动推送给百度,一遍加快爬虫抓取时间。
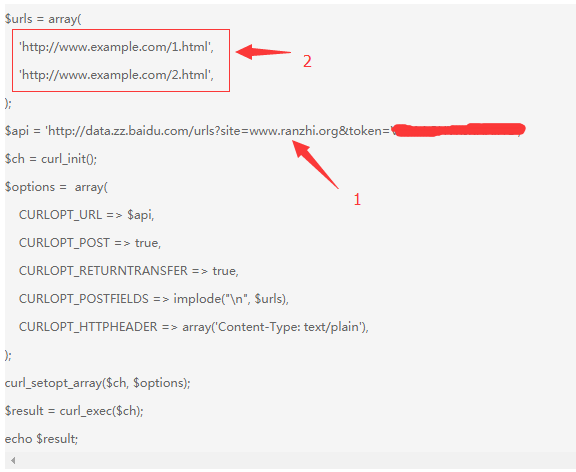
上面1是你的站点的主动推送API,这个可以在百度站长平台获取;2是要主动推送的网站地址,这里就可以用到我们上面抓取的全站链接了。将链接地址整理放到该数组中,运行一下个这个PHP脚本,就可以了。一键提交,及高效便捷,又能缩短爬虫爬去时间,有助于网站页面收录。
我们在平时的SEO或服务器运维工作中,时常会将重复工作自动化,复杂工作间变化,有助于提升效率,如果大家在操作过充中有何问题可以一起分享交流讨论。

Python3分析sitemap.xml抓取导出全站链接的更多相关文章
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- python爬虫---实现项目(二) 分析Ajax请求抓取数据
这次我们来继续深入爬虫数据,有些网页通过请求的html代码不能直接拿到数据,我们所需的数据是通过ajax渲染到页面上去的,这次我们来看看如何分析ajax 我们这次所使用的网络库还是上一节的Reques ...
- python3 - 通过BeautifulSoup 4抓取百度百科人物相关链接
导入需要的模块 需要安装BeautifulSoup from urllib.request import urlopen, HTTPError, URLError from bs4 import Be ...
- 控制台js常用解决方案,字符串替换和抓取列表页链接
抓取列表页链接 由于测试站没有jquery所以,我用了原生的js var obj = document.getElementsByClassName('class1'); for(let i = 0; ...
- Python3利用BeautifulSoup4批量抓取站点图片的代码
边学边写代码,记录下来.这段代码用于批量抓取主站下所有子网页中符合特定尺寸要求的的图片文件,支持中断. 原理很简单:使用BeautifulSoup4分析网页,获取网页<a/>和<im ...
- 我也来学着写写WINDOWS服务-解析xml抓取数据并插入数据库
项目告一段落,快到一年时间开发了两个系统,一个客户已经在试用,一个进入客户测试阶段,中间突然被项目经理(更喜欢叫他W工)分派一个每隔两小时用windows服务去抓取客户提供的外网xml,解析该xml, ...
- 分析ajax请求抓取今日头条关键字美图
# 目标:抓取今日头条关键字美图 # 思路: # 一.分析目标站点 # 二.构造ajax请求,用requests请求到索引页的内容,正则+BeautifulSoup得到索引url # 三.对索引url ...
- Python3的requests类抓取中文页面出现乱码的解决办法
这种乱码现象基本上都是编码造成的,我们要转到我们想要的编码,先po一个知识点,嵩天老师在Python网络爬虫与信息提取说到过的:response.encoding是指从HTTP的header中猜测 ...
- python学习(26)分析ajax请求抓取今日头条cosplay小姐姐图片
分析ajax请求格式,模拟发送http请求,从而获取网页代码,进而分析取出需要的数据和图片.这里分析ajax请求,获取cosplay美女图片. 登陆今日头条,点击搜索,输入cosplay 下面查看浏览 ...
随机推荐
- MyBatis之级联——鉴别器
鉴别器(discriminator)是MyBatis为我们提供的第三个级联也是最后一个.基于之前两篇级联中的场景,现增加学生们去体检,但男女体检项目不一样,我们把男女体检表做成两张表,当然我想也可以设 ...
- HTML5 02. 多媒体控件、拖拽事件、历史记录、web存储、应用程序缓存、地理定位、网络状态
多媒体 video:是行内块(text-align: center; 对行内块适用) <figure></figure>: 多媒体标签 : <figcaption> ...
- 用CSS3伪类实现书签效果
前两天想给博客上添个书签效果,类似于下面这样: 在网上搜索一番后,发现一篇纯css书签导航按钮用三个div实现了这个效果.但是博客园可没有给我这么多div,所以试着用伪类实现了一下. before,a ...
- swift pod第三方OC库使用use_frameworks!导致#import提示无法找到头文件
以MBProgressHUD为例子 swift中Podfile文件一般都会加上use_frameworks! 这样就可以直接通过import MBProgressHUD来访问MBProgressHUD ...
- 细说C#中的系列化与反系列化的基本原理和过程
虽然我们平时都使用第三方库来进行系列化和反系列化,用起来也很方便,但至少得明白系列化与反系列化的基本原理. 注意:从.NET Framework 2.0 开始,系列化格式化器类SoapFormatte ...
- WannaflyUnion每日一题
---恢复内容开始--- 1. http://www.spoj.com/problems/KAOS/ 题意:给定n个字符串,统计字符串(s1, s2)的对数,使得s1的字典序比s2的字典序要大,s1反 ...
- ES6核心内容精讲--快速实践ES6(一)
前言 本文大量参考了阮一峰老师的开源教程ECMAScript6入门,适合新手入门或者对ES6常用知识点进行全面回顾,目标是以较少的篇幅涵盖ES6及部分ES7在实践中的绝大多数使用场景.更全面.更深入的 ...
- SmartCoder每日站立会议02
1.站立会议内容 经过昨天一天的学习,大家了解到了很多新的知识,在各自任务实现方面也遇到了问题,比如首页的css样式实现.API接口的连接和地图接入的样式,经过今日站立会议,大家在一起讨论了各自出现的 ...
- C#控制台或应用程序中两个多个Main()方法的可行性方案
大多数初级程序员或学生都认为在C#控制台或应用程序中只能有一个Main()方法.但是事实上是可以有多个Main()方法的. 在C#控制台或应用程序中,在多个类中,且每个类里最多只能存在一个Main() ...
- jmeter跨线程组传值
在测试过程中,有时候需要jmeter跨线程组传值,jmeter本身又不具备此功能,那么,又该如何实现呢? 其实,我们可以通过BeanShell去实现. 实现过程如下: 1.线程组A中,使用正则表达式提 ...