Python3分析sitemap.xml抓取导出全站链接
最近网站从HTTPS转为HTTP,更换了网址,旧网址做了301重定向,折腾有点大,于是在百度站长平台提交网址,不管是主动推送还是手动提交,前提都是要整理网站的链接,手动添加太麻烦,效率低,于是就想写个脚本直接抓取全站链接并导出,本文就和大家一起分享如何使用python3实现抓取链接导出。
首先网站要有网站地图sitemap.xml文件地址,其次我这里用的是python3版本,如果你的环境是python2,需要对代码进行调整,因为python2和python3很多地方差别还是挺大的。
下面是python 3代码,将里面的链接地址换成你自己的网址即可:
#coding=utf-8
import urllib
import urllib.request import re
url='http://www.ranzhi.org/sitemap.xml'
html=urllib.request.urlopen(url).read()
html=html.decode('utf-8')
r=re.compile(r'(http://www.ranzhi.org.*?\.html)')
big=re.findall(r,html)
for i in big:
print(i)
op_xml_txt=open('xml.txt','a')
op_xml_txt.write('%s\n'%i)
我们能来看一下运行结果:
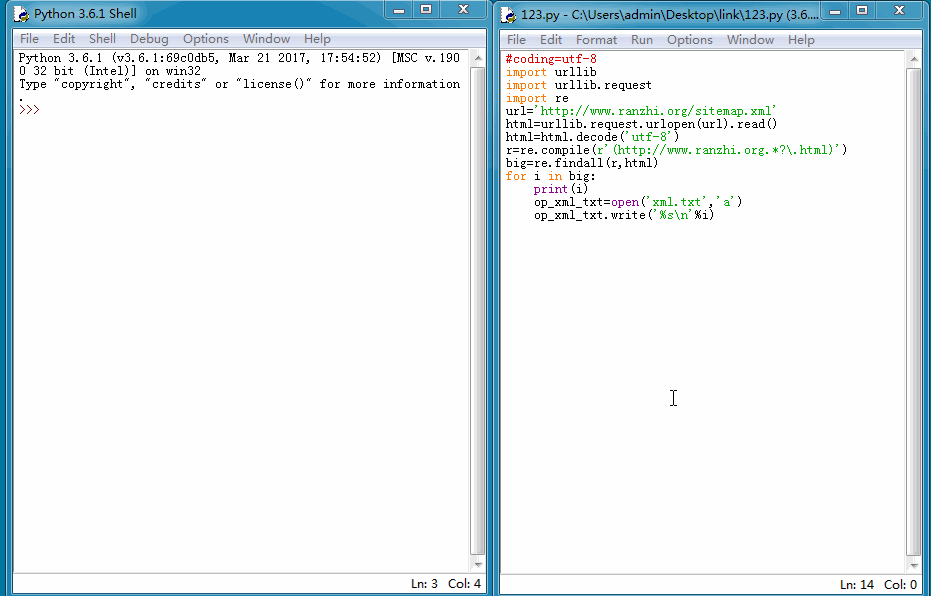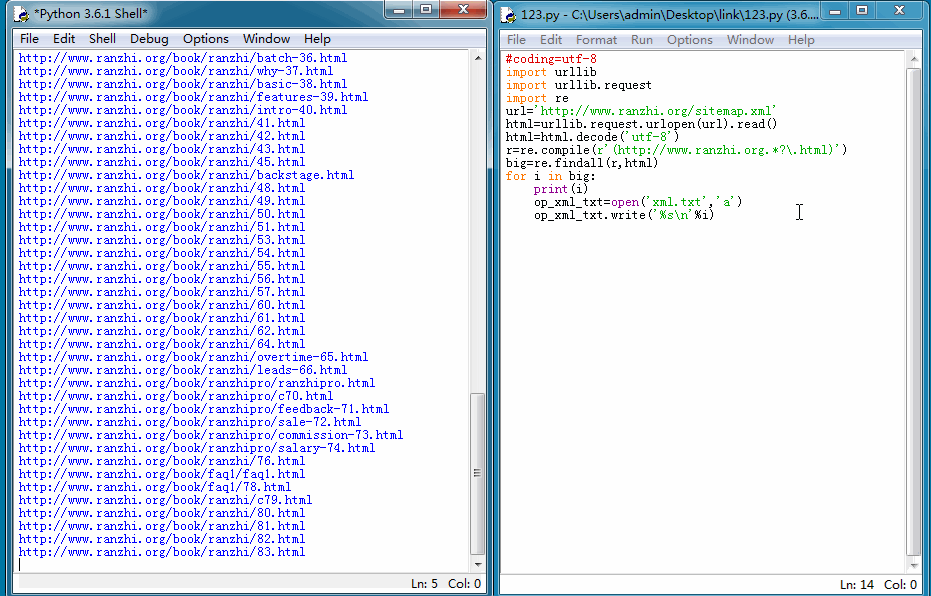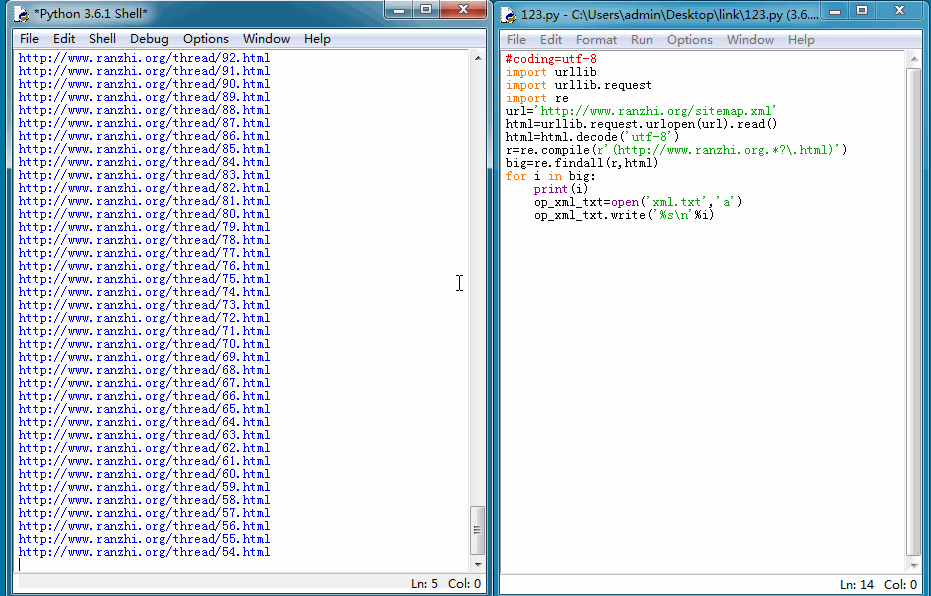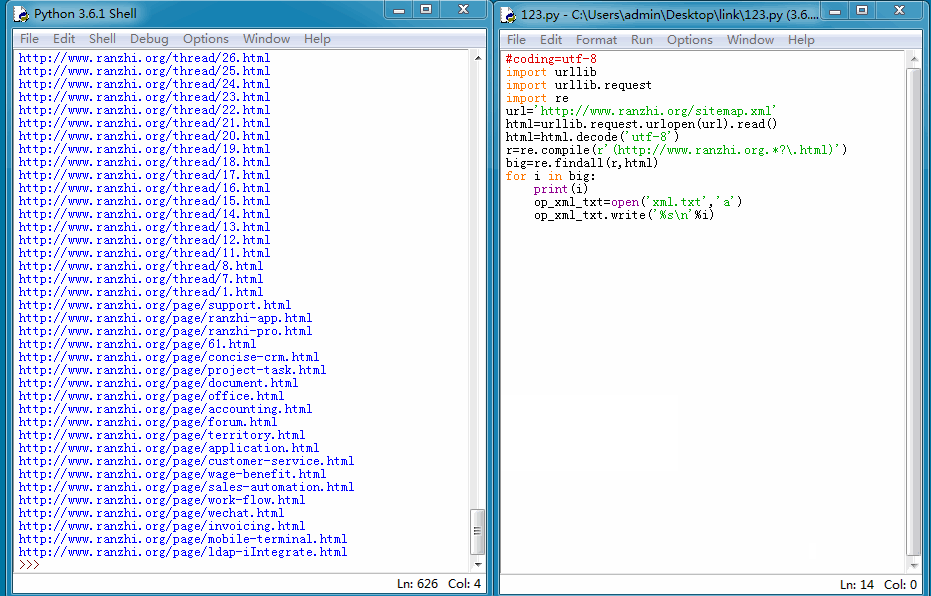
导出TXT格式文件后,再在百度站长平台手动提交就方便的多了。当然我们也可以使用更快的主动推送方式,因为我的然之网站是用PHP+mysql开发的,所以我们这里使用PHP脚本将上面抓取的链接再处理下,然后主动推送给百度,一遍加快爬虫抓取时间。
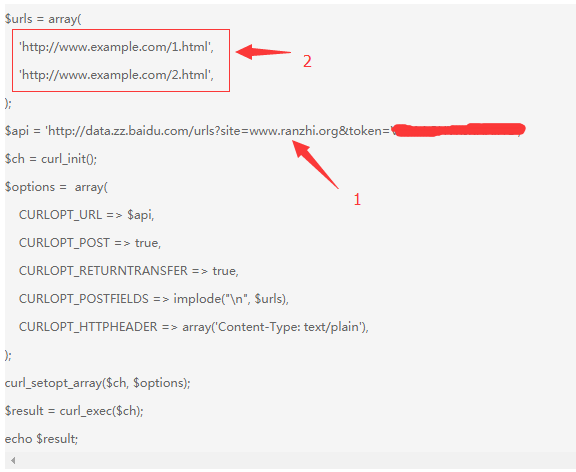
上面1是你的站点的主动推送API,这个可以在百度站长平台获取;2是要主动推送的网站地址,这里就可以用到我们上面抓取的全站链接了。将链接地址整理放到该数组中,运行一下个这个PHP脚本,就可以了。一键提交,及高效便捷,又能缩短爬虫爬去时间,有助于网站页面收录。
我们在平时的SEO或服务器运维工作中,时常会将重复工作自动化,复杂工作间变化,有助于提升效率,如果大家在操作过充中有何问题可以一起分享交流讨论。

Python3分析sitemap.xml抓取导出全站链接的更多相关文章
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
python爬虫之分析Ajax请求抓取抓取今日头条街拍美图 一.分析网站 1.进入浏览器,搜索今日头条,在搜索栏搜索街拍,然后选择图集这一栏. 2.按F12打开开发者工具,刷新网页,这时网页回弹到综合 ...
- python爬虫---实现项目(二) 分析Ajax请求抓取数据
这次我们来继续深入爬虫数据,有些网页通过请求的html代码不能直接拿到数据,我们所需的数据是通过ajax渲染到页面上去的,这次我们来看看如何分析ajax 我们这次所使用的网络库还是上一节的Reques ...
- python3 - 通过BeautifulSoup 4抓取百度百科人物相关链接
导入需要的模块 需要安装BeautifulSoup from urllib.request import urlopen, HTTPError, URLError from bs4 import Be ...
- 控制台js常用解决方案,字符串替换和抓取列表页链接
抓取列表页链接 由于测试站没有jquery所以,我用了原生的js var obj = document.getElementsByClassName('class1'); for(let i = 0; ...
- Python3利用BeautifulSoup4批量抓取站点图片的代码
边学边写代码,记录下来.这段代码用于批量抓取主站下所有子网页中符合特定尺寸要求的的图片文件,支持中断. 原理很简单:使用BeautifulSoup4分析网页,获取网页<a/>和<im ...
- 我也来学着写写WINDOWS服务-解析xml抓取数据并插入数据库
项目告一段落,快到一年时间开发了两个系统,一个客户已经在试用,一个进入客户测试阶段,中间突然被项目经理(更喜欢叫他W工)分派一个每隔两小时用windows服务去抓取客户提供的外网xml,解析该xml, ...
- 分析ajax请求抓取今日头条关键字美图
# 目标:抓取今日头条关键字美图 # 思路: # 一.分析目标站点 # 二.构造ajax请求,用requests请求到索引页的内容,正则+BeautifulSoup得到索引url # 三.对索引url ...
- Python3的requests类抓取中文页面出现乱码的解决办法
这种乱码现象基本上都是编码造成的,我们要转到我们想要的编码,先po一个知识点,嵩天老师在Python网络爬虫与信息提取说到过的:response.encoding是指从HTTP的header中猜测 ...
- python学习(26)分析ajax请求抓取今日头条cosplay小姐姐图片
分析ajax请求格式,模拟发送http请求,从而获取网页代码,进而分析取出需要的数据和图片.这里分析ajax请求,获取cosplay美女图片. 登陆今日头条,点击搜索,输入cosplay 下面查看浏览 ...
随机推荐
- Linux学习第二步(Java环境安装)
jdk版本:jdk-8u131-linux-x64.rpm 注:以下操作在root用户或具有root权限的用户下操作 一.将 dk-8u131-linux-x64.rpm拷贝到/home目录下 cp ...
- ThinkPHP集成万象优图
项目原因 不告诉你,反正需要把腾讯云的万象优图整合进来. 下载PHP版的万象优图的SDK 下载地址:https://github.com/tencentyun/image-php-sdk git cl ...
- 开涛spring3(6.9) - 对JDBC的支持 之 7.1 概述
7.1 概述 7.1.1 JDBC回顾 传统应用程序开发中,进行JDBC编程是相当痛苦的,如下所示: //cn.javass.spring.chapter7. TraditionalJdbcTes ...
- [转载]OpenStack OVS GRE/VXLAN网络
学习或者使用OpenStack普遍有这样的现象:50%的时间花费在了网络部分:30%的时间花费在了存储方面:20%的时间花费在了计算方面.OpenStack网络是不得不逾越的鸿沟,接下来我们一起尝 ...
- Mysql5.7忘记root密码及修改root密码的方法
Mysql 安装成功后,输入 mysql --version 显示版本如下 mysql Ver 14.14 Distrib 5.7.13-6, for Linux (x86_64) using 6.0 ...
- mysql之 日志体系(错误日志、查询日志、二进制日志、事务日志、中继日志)
一. mysql错误日志:错误日志记录的事件:a).服务器启动关闭过程中的信息b).服务器运行过程中的错误信息c).事件调试器运行一个事件时间生的信息d).在从服务器上启动从服务器进程时产生的信息lo ...
- python爬虫从入门到放弃(六)之 BeautifulSoup库的使用
上一篇文章的正则,其实对很多人来说用起来是不方便的,加上需要记很多规则,所以用起来不是特别熟练,而这节我们提到的beautifulsoup就是一个非常强大的工具,爬虫利器. beautifulSoup ...
- Redis中的数据结构与常用命令
开发系统:Ubuntu 17.04Redis驱动:StackExchange.Redis 1.2.3Redis版本:3.2.1开发平台:.NET Core 对于Redis的介绍这里只写一句:Redis ...
- 网络安全——一图看懂HTTPS建立过程
关于网络安全加密的介绍可以看之前文章: 1. 网络安全--数据的加密与签名,RSA介绍 2. Base64编码.MD5.SHA1-SHA512.HMAC(SHA1-SHA512) 3. When I ...
- SpringBoot学习helloworld
这几天开始学习springBoot记录一下(Hello World) pom.xml <project xmlns="http://maven.apache.org/POM/4.0.0 ...