Centos7完全分布式搭建Hadoop2.7.3
(一)软件准备
1,hadoop-2.7.3.tar.gz(包)
2,三台机器装有cetos7的机子
(二)安装步骤
1,给每台机子配相同的用户
进入root : su root
创建用户s: useradd s
修改用户密码:passwd s
2.关闭防火墙及修改每台机的hosts(root 下)
vim /etc/hosts 如:(三台机子都一样)

vim /etc/hostsname:如修改后参看各自的hostname



关闭防火墙:
systemctl stop firewalld.service
禁用防火墙:systemctl disable firewalld.service
查看防火墙状态firewall-cmd --state
重启 reboot
3,为每台机的用户s配置ssh,以用户s身份登录 (一定要相同的用户,因为ssh通信默认使用相同用户身份访问另一台机子)
1,root 用户下修改: vim /etc/ssh/sshd_config,设置这三项后,执行service sshd restart

2,退出root,在用户s下操作
生成密钥对: ssh-keygen -t dsa(一路回车即可)
转入ssh目录下:cd .ssh
导入公钥: cat id_dsa.pub >> authorized_keys
修改authorized_keys权限:chmod 644
authorized_keys (修改权限,保证自己免密码能登入)
验证 ssh Master (在三台机都执行相同的操作)
3,实现master-slave免密码登录
在master 上执行: cat ~/.ssh/id_dsa.pub | ssh s@Slave1 'cat - >> ~/.ssh/authorized_keys'
cat ~/.ssh/id_dsa.pub | ssh s@Slave2 'cat - >> ~/.ssh/authorized_keys '
验证 :ssh Slave1
(三 )配置Hadoop集群
1,解压hadoop和建立文件
root用户下:tar zxvf /home/hadoop/hadoop-2.7.3.tar.gz -C /usr/
重命名:mv hadoop-2.7.3 hadoop
授权给s: chown -R s /usr/hadoop
2,创建hdfs相关文件(三台机子都需要操作)
创建存储hadoop数据文件的目录: mkdir /home/hadoopdir
存储临时文件,如pid:mkdir /home/hadoopdir/tmp
创建dfs系统使用的dfs系统名称hdfs-site.xml使用:mkdir /home/hadoopdir/dfs/name
创建dfs系统使用的数据文件hdfs-site.xml文件使用:mkdir /home/hadoopdir/dfs/data
授权给s: chown -R s /home/hadoopdir
3,配置环境变量(三台机子都需要操作)
root用户下:vim /etc/profile 添加如图: 保存退出后:source /etc/profile
验证:hadoop version(这里要修改 /usr/hadoop/etc/hadoop/hadoop-env.sh,即export JAVA_HOME=/usr/lib/jvm/jre)

4,配置hadoop文件内容
4.1 修改core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/hadoopdir/tmp/</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>
4.2 修改hdfs-site.xml文件
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:///home/hadoopdir/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:///home/hadoopdir/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
4.3 修改mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
<property>
<name>mapreduce.jobtracker.http.address</name>
<value>Master:50030</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>Master:9001</value>
</property>
</configuration>
4.4 修改 yarn-site.xml
<configuration> <!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>Master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>Master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>Master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>Master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>Master:8088</value>
</property>
</configuration>
4.5,修改 slaves文件

5,搭建集群(普通用户s)
格式hadoop文件:hadoop namenode -format (最后出现“util.ExitUtil: Exiting with status 0”,表示成功)
发送dfs内容给Slave1:scp -r /home/hadoopdir/dfs/* Slave1:/home/hadoopdir/dfs
发给dfs内容给Slave2:scp -r /home/hadoopdir/dfs/* Slave2:/home/hadoopdir/dfs
发送hadoop文件给数据节点:scp -r /usr/hadoop/* Slave1:/usr/hadoop/ scp -r /usr/hadoop/* Slave2:/usr/hadoop/
6,启动集群
./sbin/start-all.sh
1,jps(centos 7 默认没有,可以参照这里安装)查看:Master和Slave中分别出现如下所示:


2,离开安全模式(master): hadoop dfsadmin safemode leave
查看结果:hadoop dfsadmin -report,如图
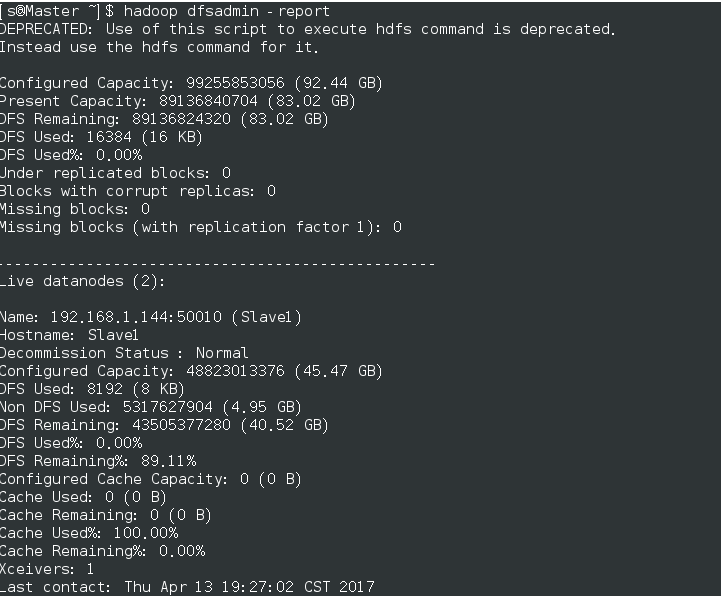
3,登录网页查看:http://Master:50070 (查看live node) 查看yarn环境(http://Master/8088)
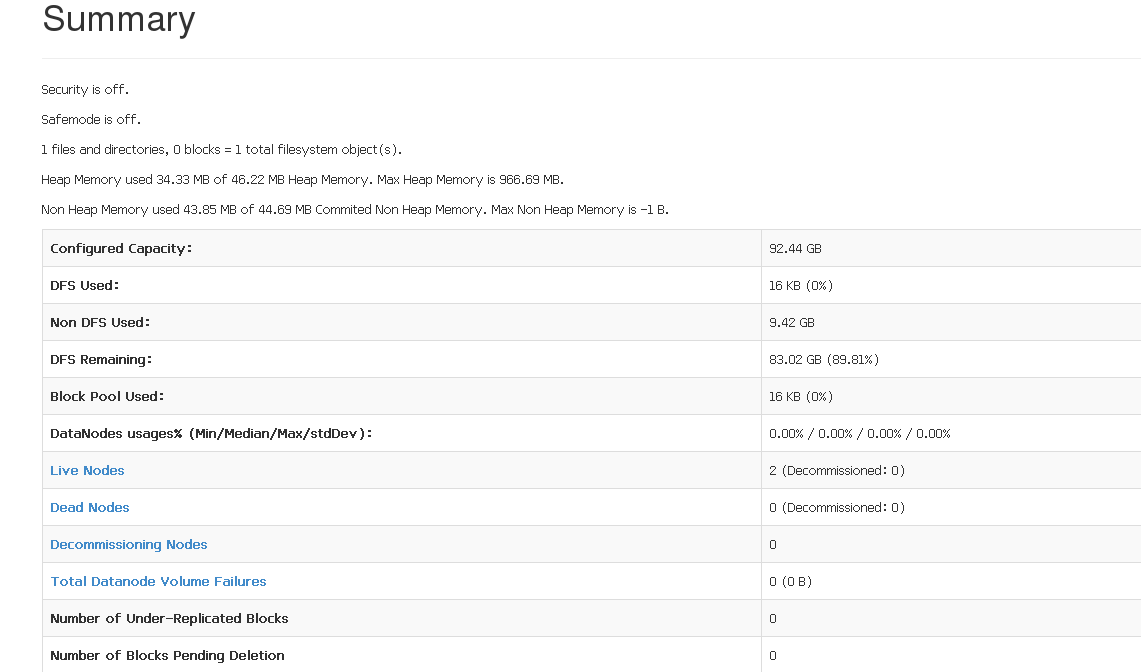
(四) 参考网页:
3,SSH集群搭建
Centos7完全分布式搭建Hadoop2.7.3的更多相关文章
- hbase2.1.9 centos7 完全分布式 搭建随记
hbase2.1.9 centos7 完全分布式 搭建随记 这里是当初在三个ECS节点上搭建hadoop+zookeeper+hbase+solr的主要步骤,文章内容未经过润色,请参考的同学搭配其他博 ...
- zookeeper3.5.5 centos7 完全分布式 搭建随记
zookeeper3.5.5 centos7 完全分布式 搭建随记 这里是当初在三个ECS节点上搭建hadoop+zookeeper+hbase+solr的主要步骤,文章内容未经过润色,请参考的同学搭 ...
- 大数据环境完全分布式搭建 hadoop2.4.1
(如果想要安装视频及相关软件可以博私聊我 qq 731487514) hadoop2.0已经发布了稳定版本了,增加了很多特性,比如HDFS HA.YARN等.最新的hadoop-2.4.1又增加了YA ...
- centos7搭建hadoop2.10完全分布式
本篇介绍在centos7中大家hadoop2.10完全分布式,首先准备4台机器:1台nn(namenode);3台dn(datanode) IP hostname 进程 192.168.30.141 ...
- hadoop2.8 集群 1 (伪分布式搭建)
简介: 关于完整分布式请参考: hadoop2.8 ha 集群搭建 [七台机器的集群] Hadoop:(hadoop2.8) Hadoop是一个由Apache基金会所开发的分布式系统基础架构.用户 ...
- Hadoop2.7.7 centos7 完全分布式 配置与问题随记
Hadoop2.7.7 centos7 完全分布式 配置与问题随记 这里是当初在三个ECS节点上搭建hadoop+zookeeper+hbase+solr的主要步骤,文章内容未经过润色,请参考的同学搭 ...
- Docker中自动化搭建Hadoop2.6完全分布式集群
这一节将在<Dockerfile完成Hadoop2.6的伪分布式搭建>的基础上搭建一个完全分布式的Hadoop集群. 1. 搭建集群中需要用到的文件 [root@centos-docker ...
- Dockerfile完成Hadoop2.6的伪分布式搭建
在 <Docker中搭建Hadoop-2.6单机伪分布式集群>中在容器中操作来搭建伪分布式的Hadoop集群,这一节中将主要通过Dokcerfile 来完成这项工作. 1 获取一个简单的D ...
- 32位Ubuntu12.04搭建Hadoop2.5.1完全分布式环境
准备工作 1.准备安装环境: 4台PC,均安装32位Ubuntu12.04操作系统,统一用户名和密码 交换机1台 网线5根,4根分别用于PC与交换机相连,1根网线连接交换机和实验室网口 2.使用ifc ...
随机推荐
- Bootstrap学习-排版
1.标题 <h1>~<h6>,所有标题的行高都是1.1(也就是font-size的1.1倍). 2.副标题 <small>,行高都是1,灰色(#999) <h ...
- Jmeter接口压力测试
SOAP百科:Soap简单对象访问协议,是交换数据的一种协议规范,是一种轻量的.简单的.基于XML(标准通用标记语言下的一个子集)的协议,它被设计成在WEB上交换结构化的和固化的信息.webServi ...
- Vue学习之路---No.6(分享心得,欢迎批评指正)
我们还是先回顾一下上一次的重点: 1.事件绑定,我们可以对分别用方法和js表达式对事件进行处理 2.当方法名带括号的时候,在方法中一定要传参:而不带括号的时候,vm会自动配置默认event 3.各类事 ...
- 【微信公众平台SDK(链式调用)】经过半个月的迭代,今天抽空写了个Demo
这个项目是在实际开发中逐渐完善的,开发过程基于ASP.Net Core 1.1,实际生成会兼容Net4.5. 写有完善的代码提示,怎么用就不多做解释了,引用好实例中的命名空间基本上就可以通过智能提示了 ...
- NSTimer的精确度
1.iOS中一般UI上面常用两种定时器 NSTimer和CADisplayLink,那么它们分别的精确度是如何呢? CADisplayLink 是用于帧刷新定时器,也就是和界面的刷新率保持一致,理想情 ...
- eclipse中以debug方式启动tomcat报错
在eclipse中debug Tomcat报错,错误如下: FATAL ERROR in native method: JDWP No transports initialized, jvmtiEr ...
- Codeforces Gym 100269E Energy Tycoon 贪心
题目链接:http://codeforces.com/gym/100269/attachments 题意: 有长度为n个格子,你有两种操作,1是放一个长度为1的东西上去,2是放一个长度为2的东西上去 ...
- MySQL入门(下)
1. 课程回顾(很清晰明了) mysql基础 1)mysql存储结构: 数据库 -> 表 -> 数据 sql语句 2)管理数据库: 增加: create database 数据库 de ...
- C++标准库之vector(各函数及其使用全)
原创作品,转载请注明出处:http://www.cnblogs.com/shrimp-can/p/5280566.html iterator类型: iterator:到value_type的访问,va ...
- GitHub中最强大的iOS Notifications和AlertView框架,没有之一!
FFToast是一个非常强大的iOS message notifications和AlertView扩展.它可以很容易实现从屏幕顶部.屏幕底部和屏幕中间弹出一个通知.你可以很容易的自定义弹出的View ...